huozi
Release huozi 3.5
| bab | menjelaskan |
|---|---|
| ?? ♂ Daftar Sumber Terbuka | Daftar proyek open source di gudang ini |
| Model Pendahuluan | Pengantar Singkat untuk Struktur dan Proses Pelatihan Model Jenis Bergerak |
| ? Download model | Tautan Unduh Model Jenis Movable |
| Penalaran model | Contoh inferensi model tipe bergerak, termasuk proses penggunaan kerangka kerja inferensi seperti VLLM, llama.cpp, dan ollama. |
| ? Kinerja model | Kinerja model tipe bergerak pada tugas evaluasi arus utama |
| ? Menghasilkan sampel | Contoh efek generasi aktual dari model tipe bergerak |

Model Bahasa Skala Besar (LLM) telah membuat kemajuan yang signifikan dalam bidang pemrosesan bahasa alami dan telah menunjukkan potensi yang kuat dalam berbagai skenario aplikasi. Teknologi ini tidak hanya menarik perhatian luas dari komunitas akademik, tetapi juga menjadi topik hangat di industri ini. Terhadap latar belakang ini, Pusat Komputasi Sosial dan Pengambilan Informasi dari Harbin Institute of Technology (HIT -SIR) baru -baru ini meluncurkan pencapaian terbaru - Movable Type 3.5 , berkomitmen untuk memberikan lebih banyak kemungkinan dan pilihan untuk penelitian dan aplikasi praktis pemrosesan bahasa alami.
Movable Type 3.5 adalah model yang diperoleh dengan peningkatan kinerja lebih lanjut berdasarkan Movable Type 3.0 dan China-Mixtral-8x7b. Movable Type 3.5 mendukung konteks panjang 32k , mewarisi kemampuan komprehensif yang kuat dari Movable Tipe 3.0, dan mencapai peningkatan kinerja dalam banyak aspek seperti pengetahuan Cina dan Inggris , penalaran matematika , pembuatan kode , kemampuan kepatuhan instruksi , keamanan konten, dll.
Penting
Model Seri Tipe Movable mungkin masih menghasilkan balasan yang menyesatkan yang mengandung kesalahan faktual atau konten berbahaya yang mengandung bias/diskriminasi. Harap berhati -hati untuk mengidentifikasi dan menggunakan konten yang dihasilkan dan jangan menyebarkan konten berbahaya yang dihasilkan ke Internet.
Silakan lihat dokumentasi untuk Movable Type 1.0 dan Movable Type 2.0 di sini. Silakan lihat di sini untuk dokumentasi di Movable Type 3.0 dan Mt-Bench Mt.
Movable Type 3.5 adalah model ahli hibrida yang jarang (SMOE), setiap lapisan ahli berisi 8 ffns, dan setiap perhitungan maju jarang diaktifkan oleh Top-2. Pindah Tipe 3.5 memiliki total parameter 46.7b. Berkat karakteristik aktivasi yang jarang, hanya parameter 13B yang perlu diaktifkan selama penalaran aktual, yang secara efektif meningkatkan efisiensi komputasi dan kecepatan pemrosesan.
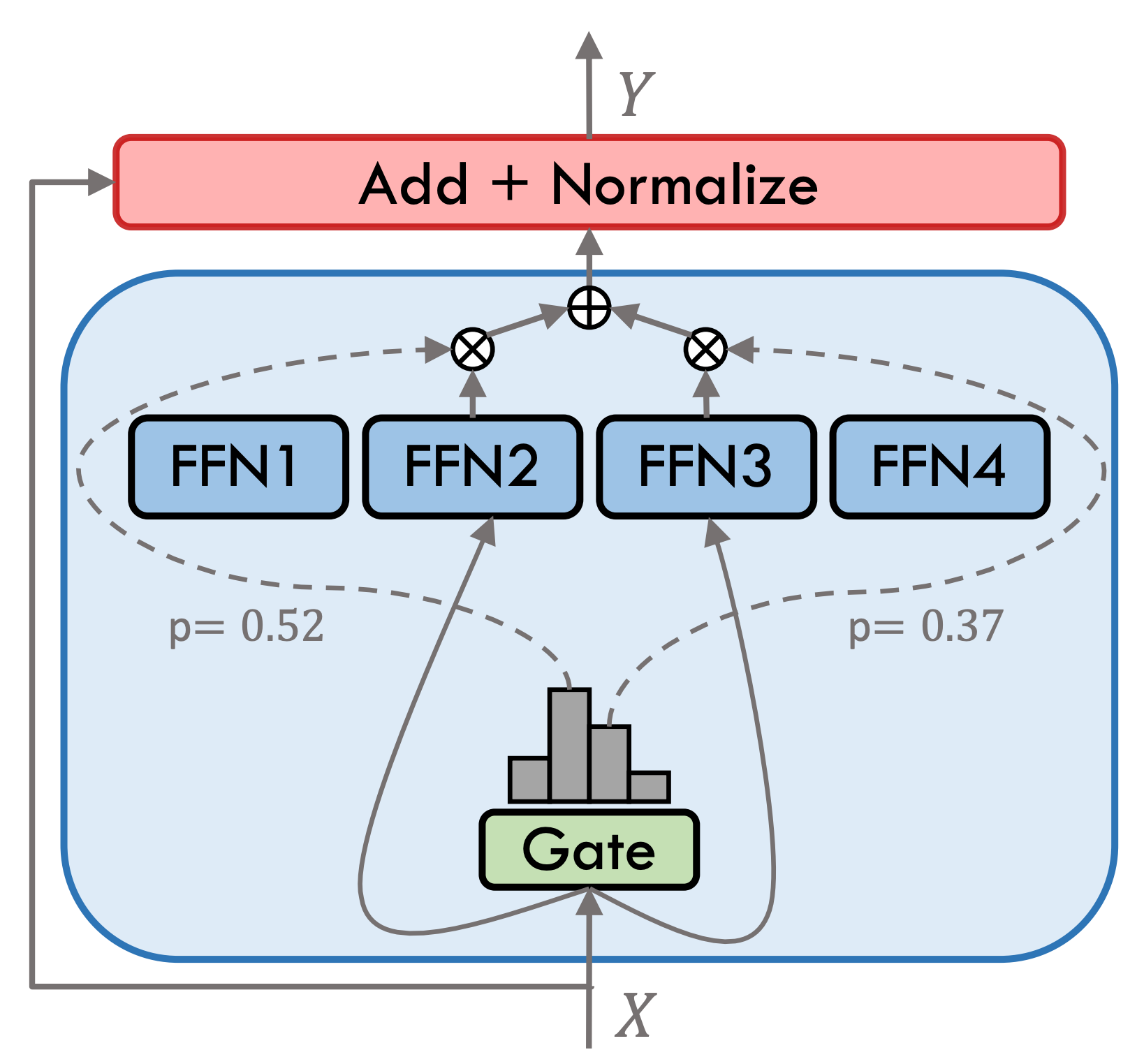
Movable Type 3.5 telah mengalami beberapa langkah pelatihan, seperti yang ditunjukkan pada gambar di bawah ini:
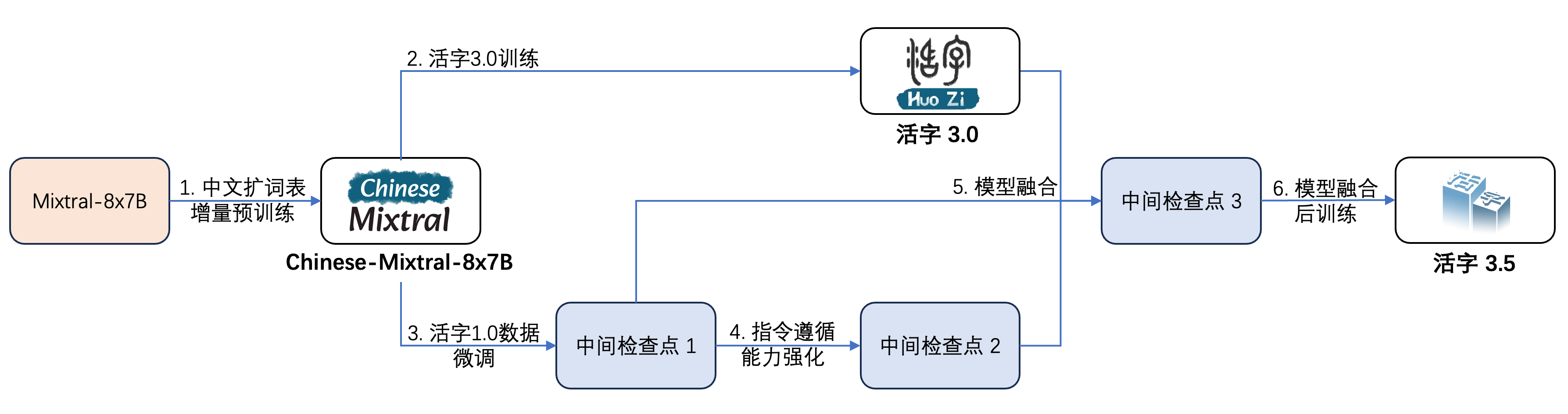
Proses pelatihannya adalah:
| Nama model | Ukuran file | Alamat unduhan | Komentar |
|---|---|---|---|
| huozi3.5 | 88GB | ? Huggingface Modelscope | MODEL TYPE 3.5 MOVABLE Lengkap |
| huozi3.5-ckpt-1 | 88GB | ? Huggingface Modelscope | Tipe Movable 3.5 Pemeriksaan Menengah 1 |
| huozi3.5-ckpt-2 | 88GB | ? Huggingface Modelscope | Tipe Movable 3.5 Checkpoint Intermediate 2 |
| huozi3.5-ckpt-3 | 88GB | ? Huggingface Modelscope | Tipe Movable 3.5 Pemeriksaan Menengah 3 |
Jika Anda ingin menyempurnakan Tipe 3.5 atau China-Mixtral-8x7b, silakan merujuk ke kode pelatihan di sini.
Tipe Movable 3.5 Menggunakan Template Propt Format ChatML, formatnya adalah:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
Kode contoh untuk penalaran menggunakan Movable Type 3.5 adalah sebagai berikut:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5 mendukung semua ekosistem model mixtral, termasuk Transformers, VLLM, Llama.cpp, Ollama, Web Generasi Teks UI dan kerangka kerja lainnya.
Jika Anda memiliki masalah jaringan saat mengunduh model Anda, Anda dapat menggunakan pos pemeriksaan yang kami sediakan di Modelscope.
Transformers mendukung menambahkan templat obrolan untuk tokenizer dan mendukung generasi streaming. Kode sampel adalah sebagai berikut:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)Antarmuka Modelscope sangat mirip dengan Transformers, cukup ganti Transformers dengan Model Lingkup:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Variabel Tipe 3.5 mendukung implementasi akselerasi inferensi melalui VLLM, dan kode sampel adalah sebagai berikut:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Variety Type 3.5 dapat digunakan sebagai layanan yang mendukung protokol API OpenAI, yang memungkinkan Variety Type 3.5 dipanggil langsung melalui API OpenAI.
Persiapan Lingkungan:
$ pip install vllm openaiMulai Layanan:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Kirim Permintaan Menggunakan API OpenAI:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Berikut adalah kode sampel yang menggunakan OpenAI API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()Format GGUF dirancang untuk memuat dan menyimpan model dengan cepat. Ini diluncurkan oleh tim Llama.cpp dan cocok untuk kerangka kerja seperti llama.cpp, ollama, dll. Anda dapat secara manual mengonversi tipe 3.5 yang dapat dipindahkan dalam format Huggingface ke format GGUF.
Pertama, Anda perlu mengunduh kode sumber llama.cpp. Kami menyediakan submodule llama.cpp di repositori. Versi llama.cpp ini telah diuji dan dapat berhasil menyimpulkan:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppAnda juga dapat mengunduh kode sumber LLAMA.CPP versi terbaru:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppMaka itu perlu dikompilasi. Ada perbedaan halus dalam perintah kompilasi tergantung pada platform perangkat keras Anda:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 Perintah berikut harus berada di llama.cpp/ Directory:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 Perintah berikut harus berada di llama.cpp/ Directory:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Parameter -ngl menunjukkan jumlah lapisan offload ke GPU. Mengurangi nilai ini dapat mengurangi tekanan memori video GPU. Setelah tes kami yang sebenarnya, model Q2_K Quantized memiliki 16-lapis, dan penggunaan memori dapat dikurangi menjadi 9.6GB, yang dapat menjalankan model pada GPU konsumen:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Untuk lebih banyak parameter main , Anda dapat merujuk pada dokumentasi resmi llama.cpp.
Gunakan kerangka kerja Ollama untuk penalaran, Anda dapat merujuk pada instruksi ReadMe Ollama.
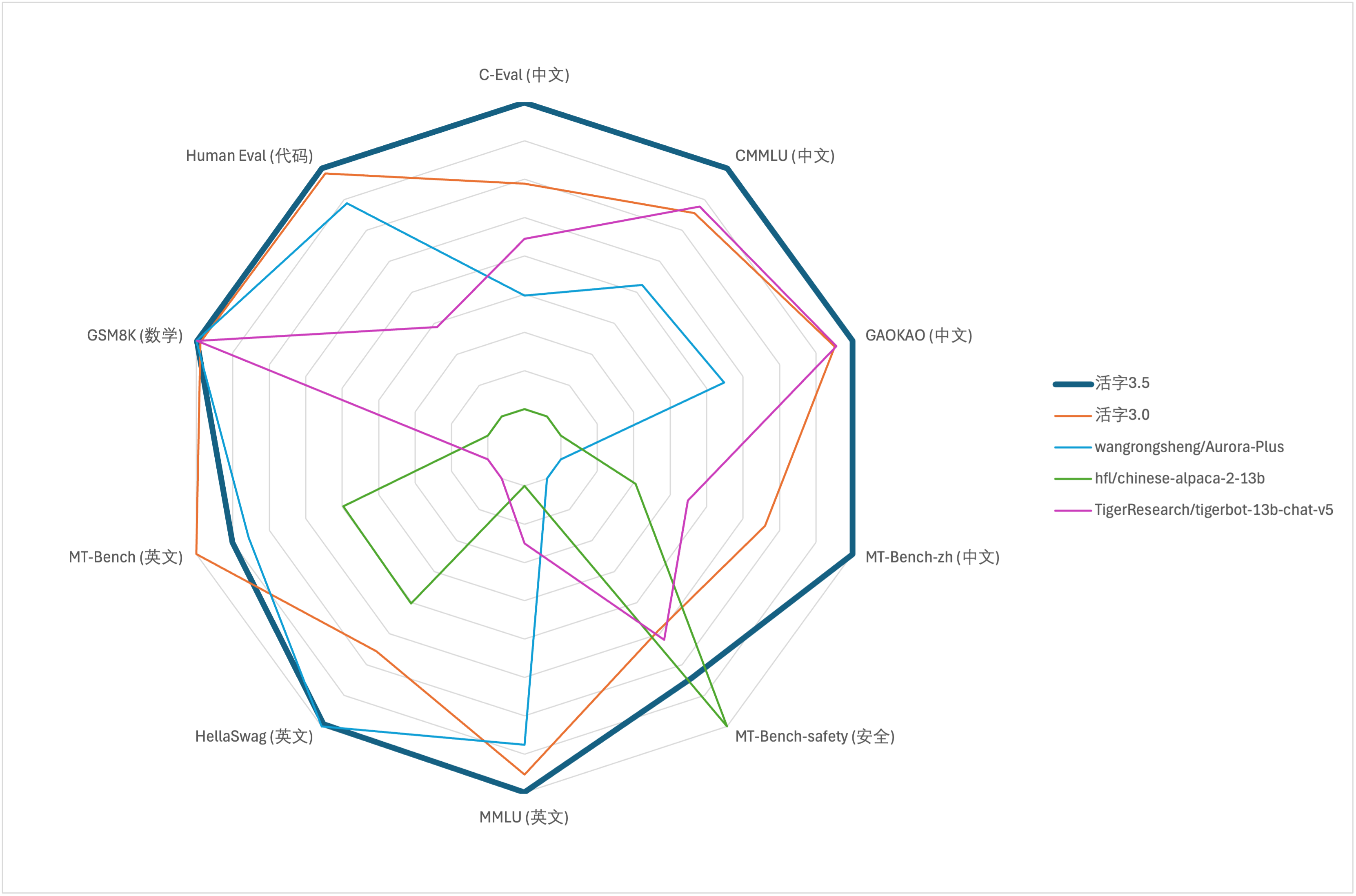
Untuk evaluasi kemampuan komprehensif model besar, kami menggunakan dataset evaluasi berikut untuk mengevaluasi masing -masing Tipe 3.5 yang dapat dipindahkan:
Movable Type 3.5 hanya mengaktifkan parameter 13B saat inferensi. Tabel berikut menunjukkan hasil model Cina dari Movable Tipe 3.5 dan skala 13B lainnya dan versi lama dari tipe bergerak pada setiap dataset evaluasi:
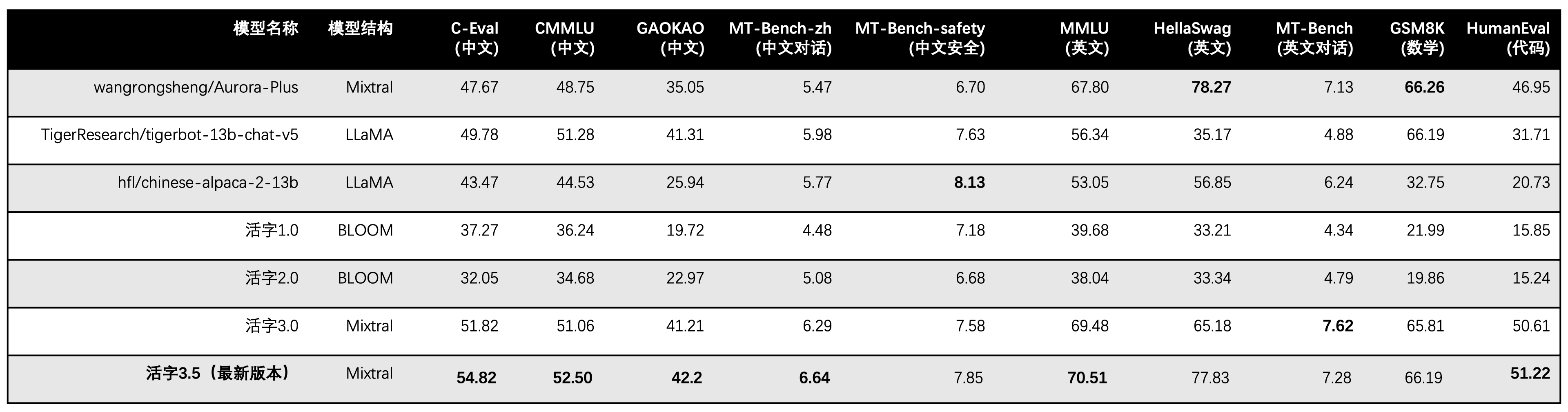
Kami menggunakan 5-shot dalam C-Eval, CMMLU, dan MMLU, GSM8K menggunakan 4-shot, Hellaswag dan Humaneval menggunakan 0-shot, dan Humaneval menggunakan indikator pass@1. Semua tes adalah strategi serakah.
Kami menggunakan OpenCompass sebagai kerangka evaluasi dan commit hash adalah 4C87E77. Kode ulasan terletak di sini.
Dalam evaluasi kinerja Tipe 3.0 Movable, kami menggunakan metode evaluasi model dasar secara tidak benar, dan hasil evaluasi yang benar telah diperbarui dalam tabel di atas.
Menurut hasil tes dalam tabel di atas, Movable Type 3.5 telah mencapai peningkatan kinerja yang relatif stabil dibandingkan dengan Movable Tipe 3.0, dan pengetahuan Cina dan Inggris , penalaran matematika , pembuatan kode , kemampuan kepatuhan instruksi Cina , dan keamanan konten Cina dari Movable Type 3.5 telah diperkuat.
Berikut ini adalah efek generasi dari Movable Tipe 3.5 pada set evaluasi MT-Bench-ZH:
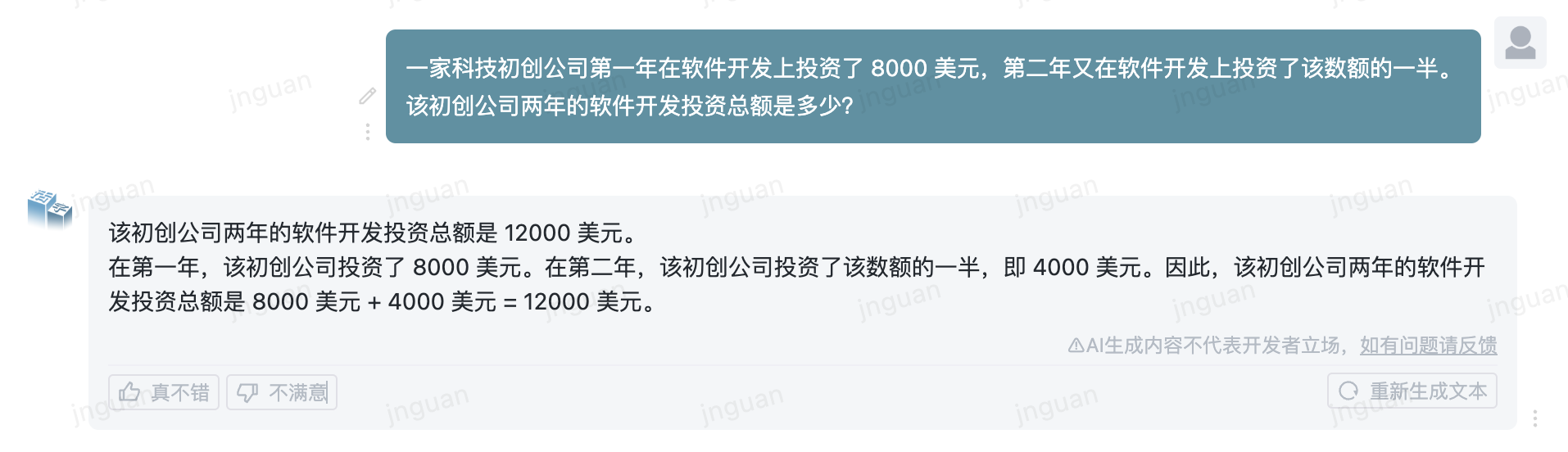



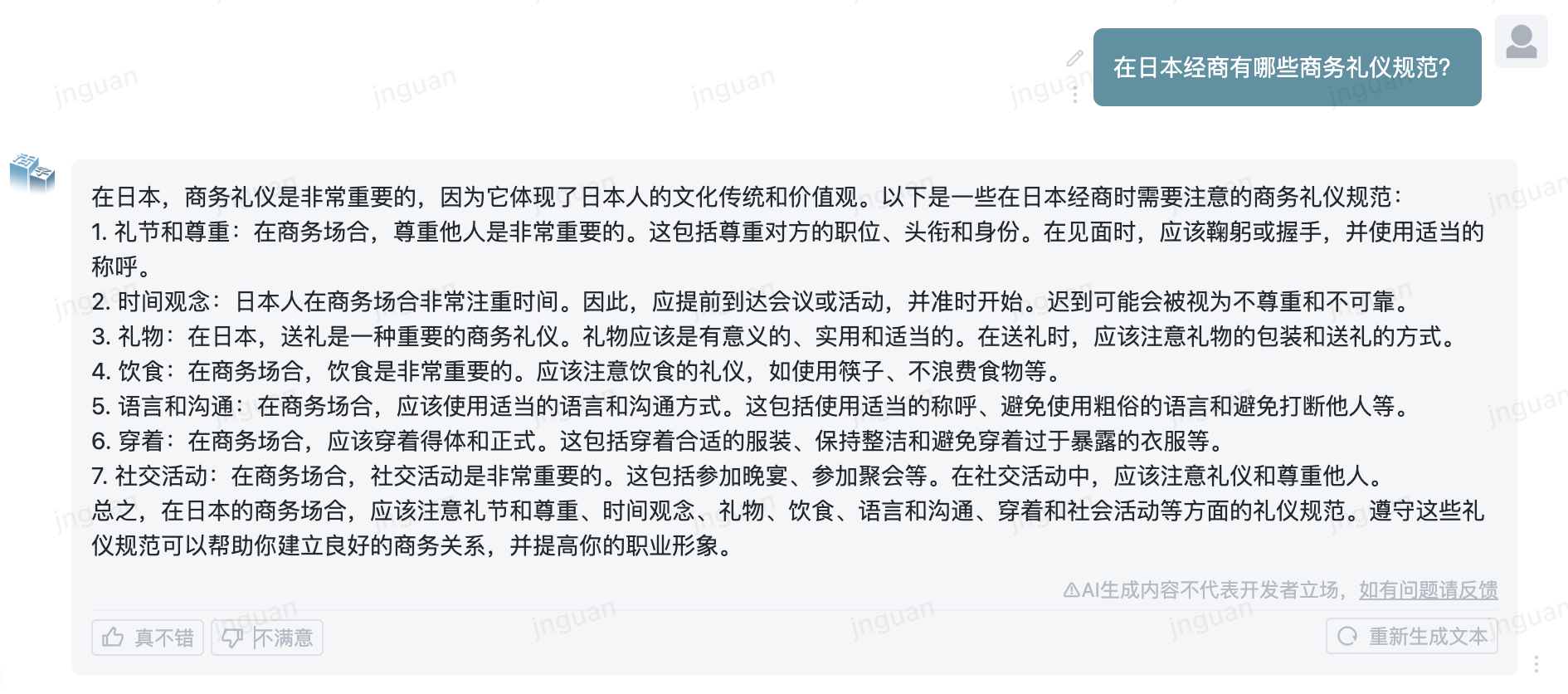
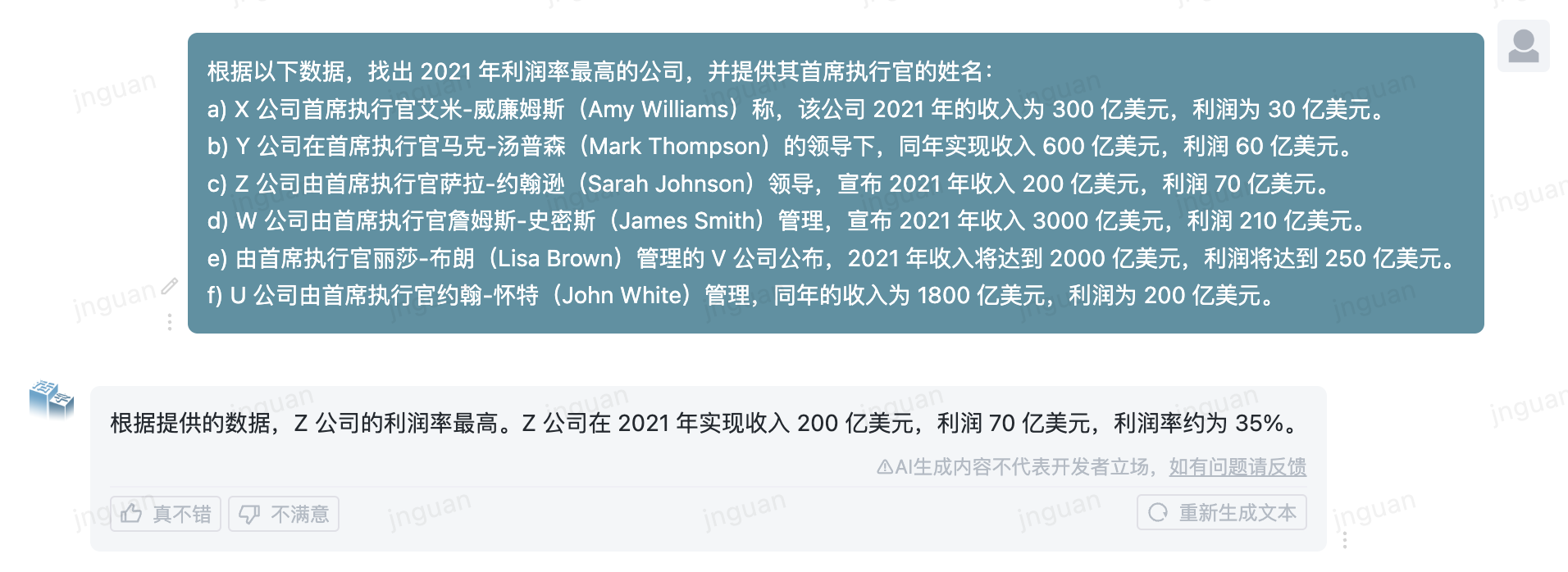
Penggunaan kode sumber repositori ini tunduk pada perjanjian lisensi sumber terbuka Apache 2.0.
Jenis seluler tersedia secara komersial. Jika Anda menggunakan model tipe bergerak atau turunannya untuk tujuan komersial, silakan hubungi pemberi lisensi sebagai berikut untuk mendaftar dan mengajukan permohonan otorisasi tertulis dari pemberi lisensi: Hubungi Email: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

