huozi
Release huozi 3.5
| chapitre | illustrer |
|---|---|
| ?? Liste open source | Liste des projets open source dans cet entrepôt |
| Introduction du modèle | Bref introduction à la structure et au processus de formation du modèle de type mobile |
| ? Téléchargement du modèle | Lien de téléchargement de modèle de type mobile |
| Raisonnement modèle | Exemples d'inférence du modèle de type mobile, y compris le processus d'utilisation des cadres d'inférence tels que Vllm, Llama.Cpp et Olllama. |
| ? Performance du modèle | Performance du modèle de type mobile sur les tâches d'évaluation traditionnelles |
| ? Générer un échantillon | Exemples d'effet de génération réel du modèle de type mobile |

Le modèle de langue à grande échelle (LLM) a fait des progrès significatifs dans le domaine du traitement du langage naturel et a démontré son fort potentiel dans un large éventail de scénarios d'application. Cette technologie a non seulement attiré une grande attention de la communauté universitaire, mais est également devenue un sujet brûlant dans l'industrie. Dans ce contexte, le Center for Social Computing and Information Retrieval of Harbin Institute of Technology (HIT-SCIR) a récemment lancé le dernier réalisation - Type 3.5 mobile , déterminé à fournir plus de possibilités et de choix pour la recherche et l'application pratique du traitement du langage naturel.
Le type 3.5 mobile est un modèle obtenu par une amélioration des performances supplémentaire basée sur le type 3.0 mobile et le chinois-mixtral-8x7b. Le type 3.5 mobile prend en charge un contexte de 32k de long , hérite des puissantes capacités complètes du type 3.0 mobile et réalise les améliorations des performances dans de nombreux aspects tels que les connaissances chinoises et anglais , le raisonnement mathématique , la génération de code , les capacités de conformité des instructions , la sécurité du contenu, etc.
Important
Le modèle de série de types mobiles peut encore générer des réponses trompeuses contenant des erreurs factuelles ou un contenu nuisible qui contient un biais / discrimination. Veuillez veiller à identifier et à utiliser le contenu généré et ne pas répartir le contenu nocif généré sur Internet.
Veuillez consulter la documentation pour le type mobile 1.0 et le type mobile 2.0 ici. Veuillez consulter ici pour la documentation sur le type 3.0 mobile et le banc MT chinois.
Le type 3.5 mobile est un modèle expert hybride clairsemé (SMOE), chaque couche experte contient 8 FFN et chaque calcul vers l'avant est peu activé par le top-2. Le type mobile 3.5 a un total de 46,7B paramètres. Grâce à ses caractéristiques d'activation clairsemées, seuls les paramètres 13B doivent être activés pendant le raisonnement réel, ce qui améliore efficacement l'efficacité informatique et la vitesse de traitement.
Le type 3.5 mobile a subi plusieurs étapes de formation, comme le montre la figure ci-dessous:
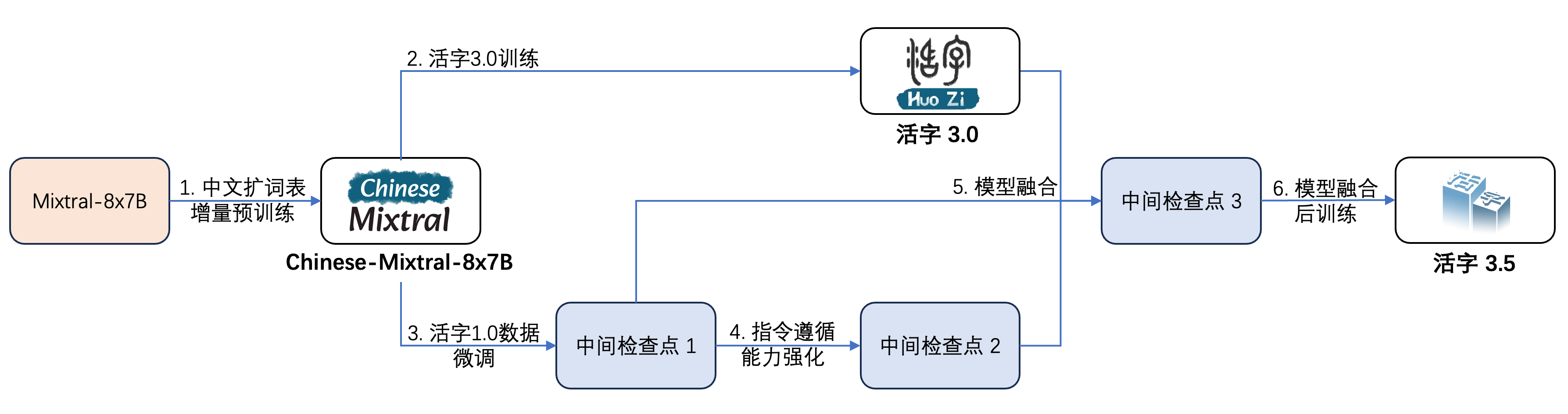
Le processus de formation est:
| Nom du modèle | Taille de fichier | Adresse de téléchargement | Remarque |
|---|---|---|---|
| huozi3.5 | 88 Go | ? Huggingface Modelcope | Type mobile 3.5 Modèle complet |
| huozi3.5-ckpt-1 | 88 Go | ? Huggingface Modelcope | Type mobile 3.5 Point de contrôle intermédiaire 1 |
| huozi3.5-ckpt-2 | 88 Go | ? Huggingface Modelcope | Type mobile 3.5 Point de contrôle intermédiaire 2 |
| huozi3.5-ckpt-3 | 88 Go | ? Huggingface Modelcope | Type mobile 3.5 Point de contrôle intermédiaire 3 |
Si vous souhaitez affiner le type mobile 3.5 ou le chinois-mixtral-8x7b, veuillez vous référer au code de formation ici.
Le type mobile 3.5 utilise le modèle de propt de format Chatml, le format est:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
L'exemple de code pour le raisonnement utilisant le type mobile 3.5 est le suivant:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Le type MOBable 3.5 prend en charge tous les écosystèmes de modèle mixtral, y compris les transformateurs, vllm, llama.cpp, olllama, ui web de génération de texte et autres frameworks.
Si vous avez des problèmes de réseau lors du téléchargement de votre modèle, vous pouvez utiliser les points de contrôle que nous fournissons sur Modelscope.
Les transformateurs prennent en charge l'ajout de modèles de chat pour le tokenzer et prennent en charge la génération de streaming. L'exemple de code est le suivant:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)L'interface de Modelcope est très similaire aux transformateurs, remplacez simplement les transformateurs par la portée du modèle:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Le type de variable 3.5 prend en charge l'implémentation de l'accélération d'inférence via VLLM, et l'exemple de code est le suivant:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Le type de variété 3.5 peut être déployé en tant que service qui prend en charge le protocole API OpenAI, qui permet à la variété du type 3.5 d'être appelé directement via l'API OpenAI.
Préparation environnementale:
$ pip install vllm openaiDémarrer le service:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Envoyer des demandes à l'aide de l'API OpenAI:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Voici un exemple de code qui utilise Openai API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()Le format GGUF est conçu pour charger et enregistrer rapidement les modèles. Il est lancé par l'équipe LLAMA.CPP et convient à des cadres tels que LLAMA.CPP, OLLAMA, etc. Vous pouvez convertir manuellement le type 3.5 mobile au format HuggingFace au format GGUF.
Tout d'abord, vous devez télécharger le code source de lama.cpp. Nous fournissons le sous-module de Llama.cpp dans le référentiel. Cette version de Llama.cpp a été testée et peut déduire avec succès:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppVous pouvez également télécharger la dernière version de Llama.cpp Code source:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppEnsuite, il doit être compilé. Il existe des différences subtiles dans les commandes de compilation en fonction de votre plate-forme matérielle:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 La commande suivante doit être dans llama.cpp/ :
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 La commande suivante doit être dans llama.cpp/ :
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Le paramètre -ngl indique le nombre de couches de déchargement au GPU. La réduction de cette valeur peut atténuer la pression de mémoire vidéo GPU. Après notre test réel, le modèle quantifié Q2_K a un déchargement de 16 couches, et l'utilisation de la mémoire peut être réduite à 9,6 Go, qui peut exécuter le modèle sur les GPU de consommation:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Pour plus de paramètres de main , vous pouvez vous référer à la documentation officielle de Llama.cpp.
Utilisez le framework Olllama pour le raisonnement, vous pouvez vous référer aux instructions ReadME d'Olllama.
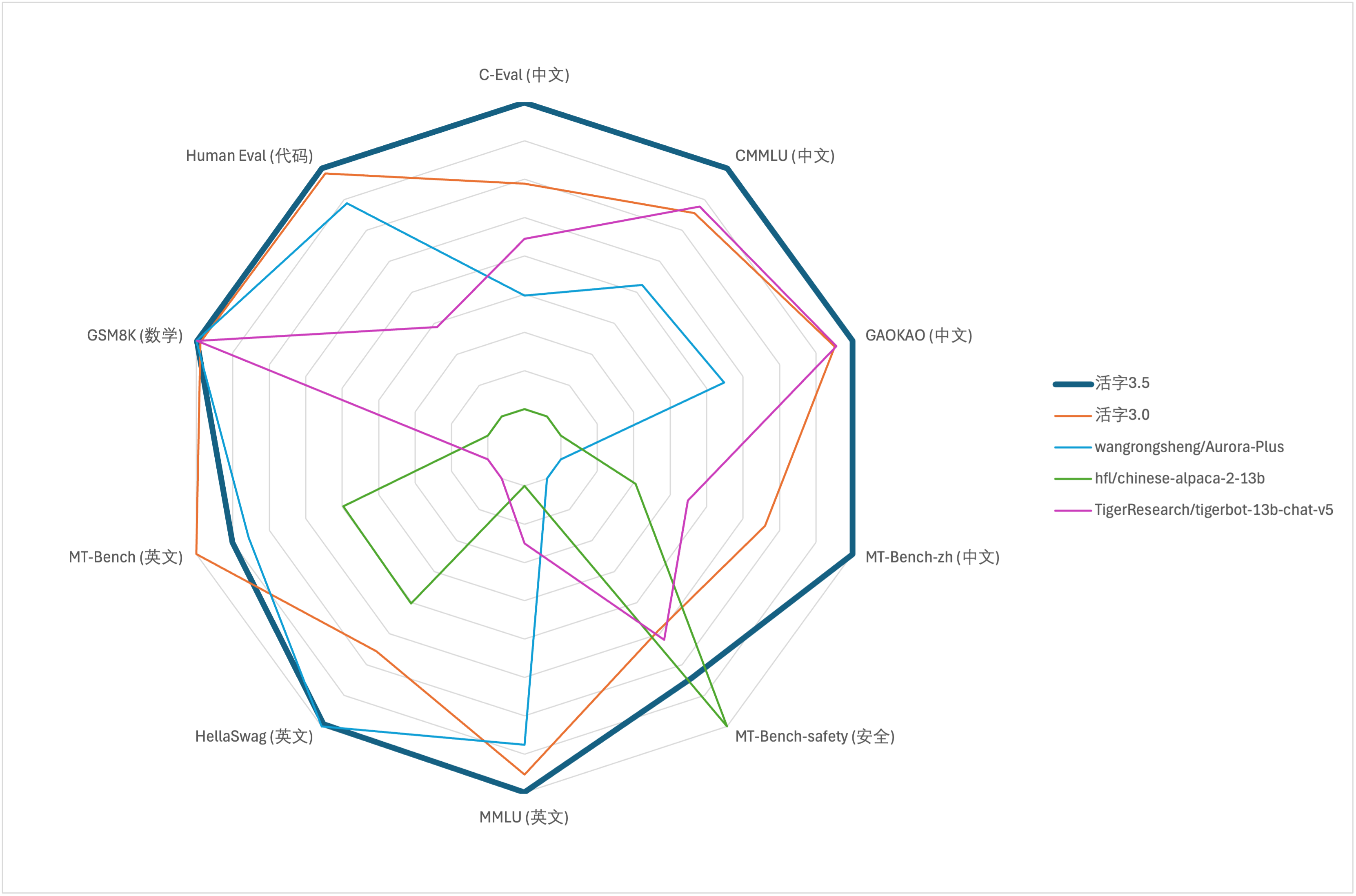
Pour l'évaluation complète de la capacité des grands modèles, nous avons utilisé l'ensemble de données d'évaluation suivant pour évaluer respectivement le type 3.5 mobile:
Le type mobile 3.5 active uniquement les paramètres 13B lors de l'inférence. Le tableau suivant montre les résultats des modèles chinois de type 3.5 et autres échelles 13B et l'ancienne version de type mobile sur chaque ensemble de données d'évaluation:
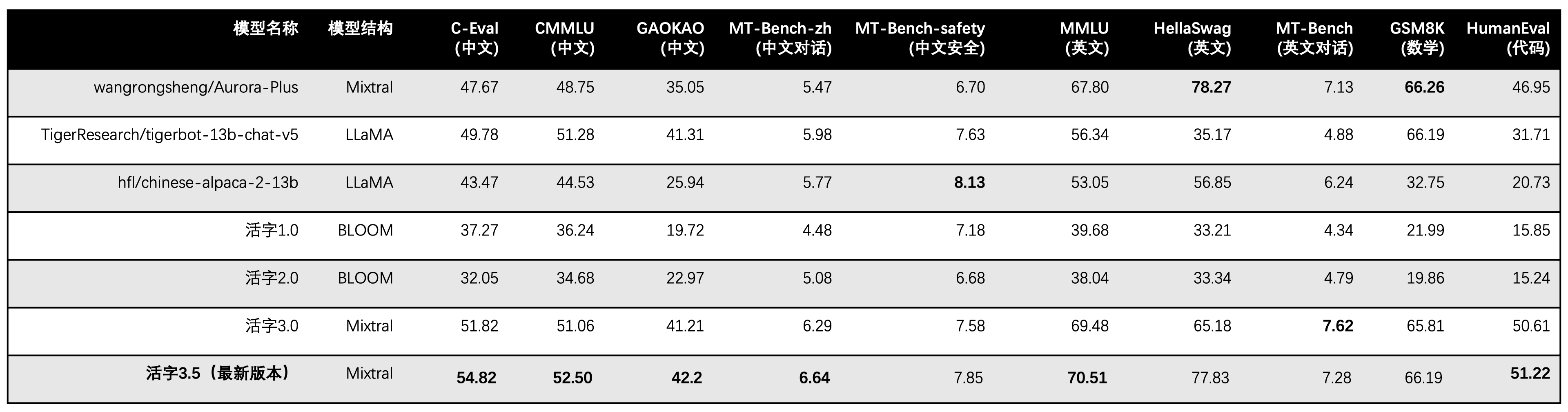
Nous utilisons le 5-Shot dans C-Eval, CMMLU et MMLU, GSM8K utilise 4-Shot, Hellaswag et Humaneval Use 0-Shot, et Humaneval utilise Pass @ 1 indicateur. Tous les tests étaient une stratégie gourmande.
Nous utilisons OpenCompass comme cadre d'évaluation et le hachage de validation est 4C87E77. Le code d'examen est situé ici.
Dans l'évaluation des performances du type 3.0 mobile, nous avons utilisé la méthode d'évaluation du modèle de base dans HumaneVal de manière incorrecte, et les résultats d'évaluation corrects ont été mis à jour dans le tableau ci-dessus.
Selon les résultats des tests dans le tableau ci-dessus, le type 3.5 mobile a atteint une amélioration des performances relativement stable par rapport au type 3.0 mobile et les connaissances chinoises et en anglais , le raisonnement mathématique , la génération de code , la capacité de conformité des instructions chinoises et la sécurité du contenu chinois du type 3.5 mobile ont été renforcés.
Ce qui suit est l'effet de génération du type MOBable 3.5 sur l'ensemble d'évaluation MT-Bench-ZH:
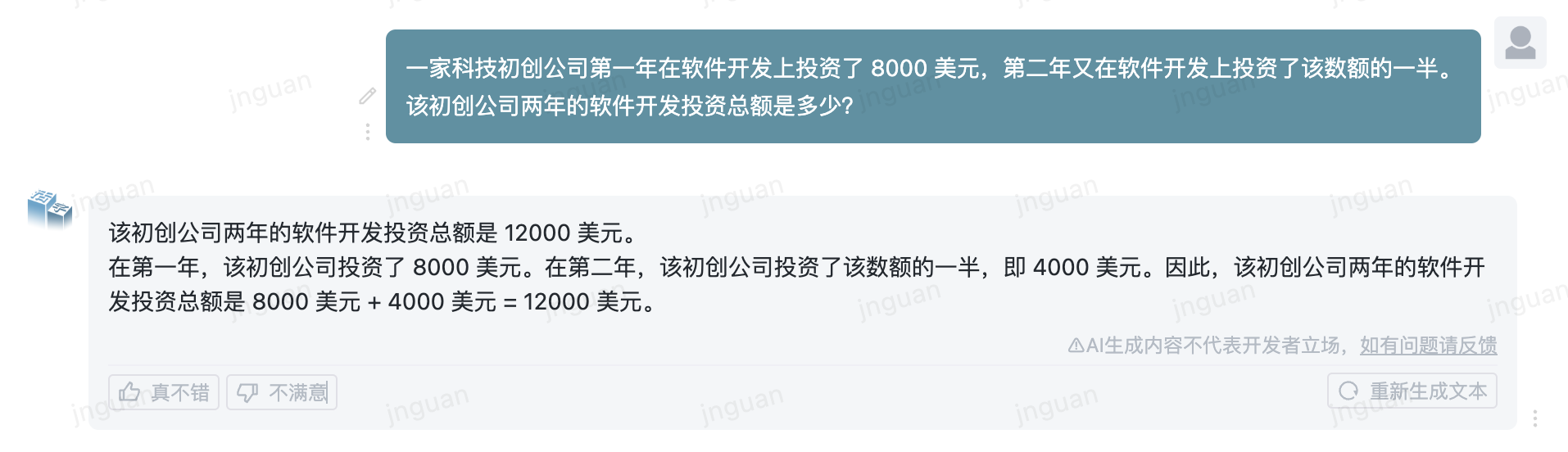



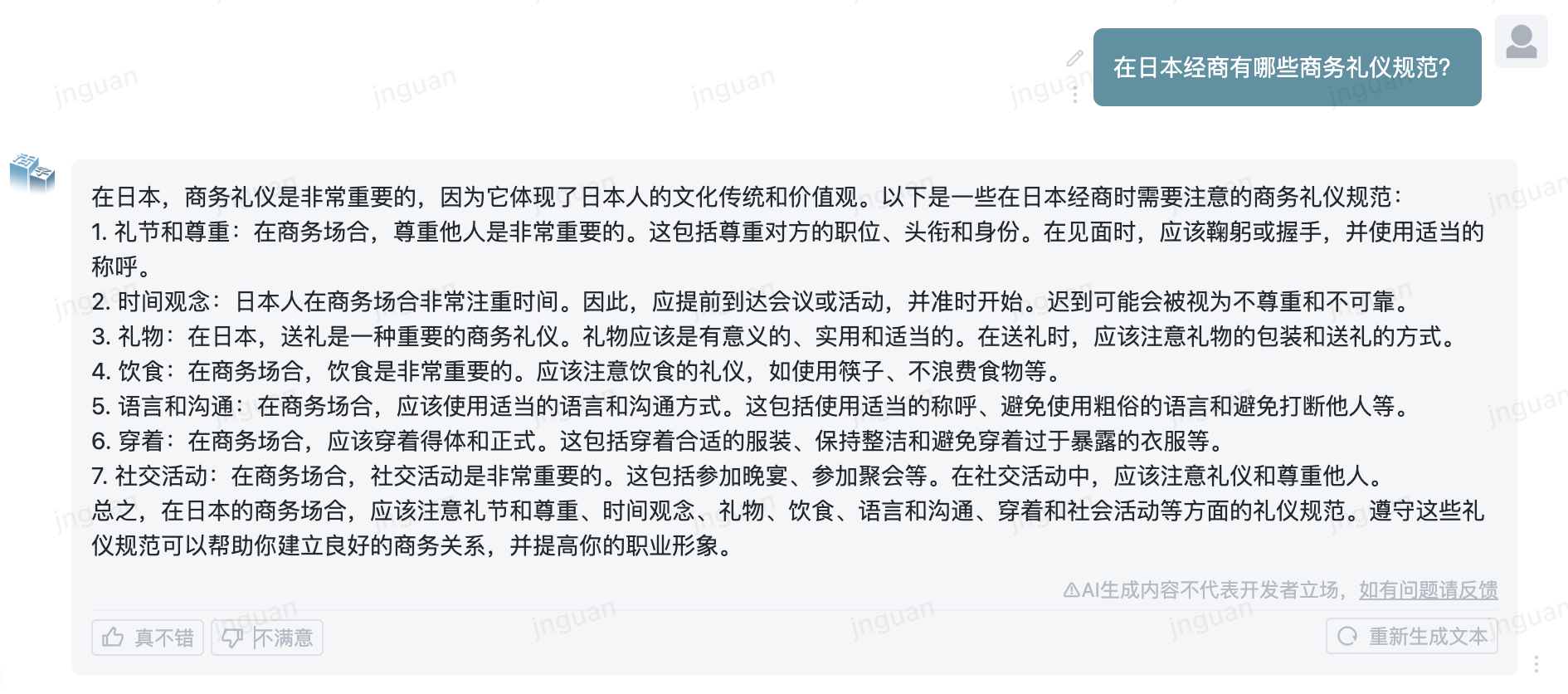
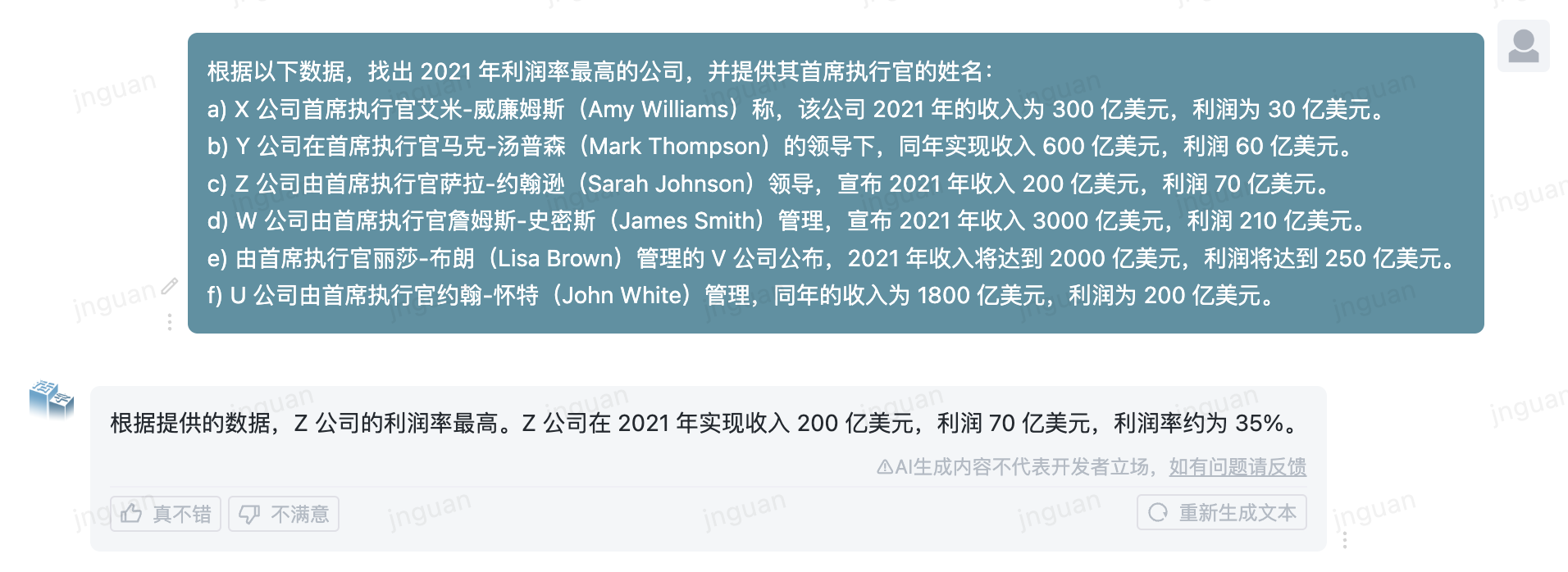
L'utilisation de ce code source de référentiel est soumise au contrat de licence open source Apache 2.0.
Le type mobile est disponible dans le commerce. Si vous utilisez le modèle de type mobile ou ses dérivés à des fins commerciales, veuillez contacter le concédant comme suit pour vous inscrire et demander l'autorisation écrite du concédant: Contacter Courriel: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

