pia
1.5.5
PIA เป็นกล่องเครื่องมือสำหรับการอนุมานโปรตีนที่ใช้ MS และการวิเคราะห์การระบุตัวตน
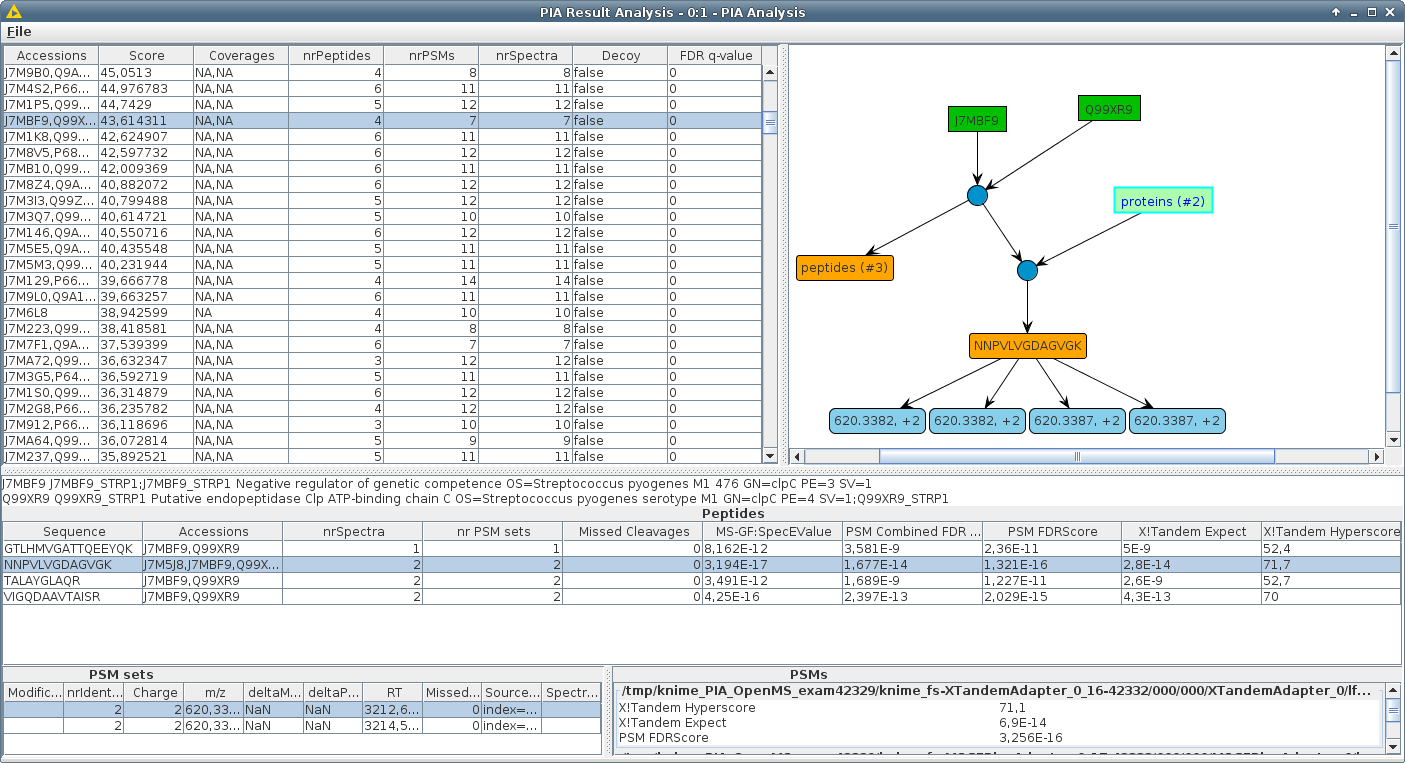
PIA ช่วยให้คุณตรวจสอบผลลัพธ์ของเครื่องมือค้นหาการระบุสเปกตรัมโปรตีนทั่วไปรวมกันอย่างราบรื่นและดำเนินการวิเคราะห์ทางสถิติ จุดสนใจหลักของ PIA วางอยู่บนอัลกอริทึมการอนุมานแบบบูรณาการเช่นการสรุปโปรตีนจากชุดสเปกตรัมที่ระบุ แต่มันยังช่วยให้คุณตรวจสอบการจับคู่สเปกตรัมเปปไทด์ของคุณคำนวณค่า FDR ในผลลัพธ์ของเครื่องมือค้นหาที่แตกต่างกันและเห็นภาพการติดต่อระหว่าง PSM, เปปไทด์และโปรตีน

เครื่องมือค้นหาส่วนใหญ่สำหรับการระบุโปรตีนในการทดลอง MS/MS ส่งคืนรายการโปรตีนแม้ว่าการค้นหาจริงจะให้ชุดของการจับคู่สเปกตรัมเปปไทด์ (PSMs) ขั้นตอนจาก PSMs ถึงโปรตีนเรียกว่า "การอนุมานโปรตีน" หากชุดของ PSM ที่ระบุสนับสนุนการตรวจจับโปรตีนมากกว่าหนึ่งตัวในฐานข้อมูลที่ค้นหา ("ความกำกวมโปรตีน") มักจะรายงานการเข้าร่วมตัวแทนเพียงคนเดียว ตัวแทนเหล่านี้อาจแตกต่างกันไปตามเครื่องมือค้นหาและการตั้งค่าที่ใช้แล้ว ดังนั้นรายการโปรตีนของเครื่องมือค้นหาที่แตกต่างกันโดยทั่วไปจึงไม่สามารถเปรียบเทียบกันได้ PSMS ของเครื่องมือค้นหาเสริมมักจะถูกรวมเข้าด้วยกันเพื่อเพิ่มจำนวนโปรตีนที่รายงานหรือเพื่อตรวจสอบหลักฐานของเปปไทด์ซึ่งได้รับการปรับปรุงโดยการตรวจจับด้วยอัลกอริทึมที่แตกต่างกัน
เราพัฒนาชุดอัลกอริทึมที่เขียนใน Java รวมถึงโหนด Knime Parametrisable อย่างสมบูรณ์ซึ่งรวม PSMs จากการทดลองและ/หรือเครื่องมือค้นหาที่แตกต่างกันและรายงานผลลัพธ์ที่สอดคล้องกันและเปรียบเทียบได้ ไม่มีพารามิเตอร์ใด ๆ เช่นการกรองหรือให้คะแนนได้รับการแก้ไขในแนวทางก่อนหน้า แต่มีความยืดหยุ่นมากที่สุดเท่าที่จะเป็นไปได้เพื่อให้การปรับเปลี่ยนใด ๆ ที่ผู้ใช้ต้องการ
PIA สามารถเรียกได้ผ่านบรรทัดคำสั่ง (เช่นในคอนเทนเนอร์ Docker) หรือในสภาพแวดล้อมของเวิร์กโฟลว์ Knime ซึ่งช่วยให้การรวมเข้ากับเวิร์กโฟลว์ OpenMS ได้อย่างราบรื่น
สำหรับบรรทัดคำสั่งคุณสามารถดาวน์โหลดเวอร์ชันล่าสุดที่ปล่อยออกมาโดยใช้ Conda (ตามลำดับ Bioconda) หรือดาวน์โหลดบิลด์ได้ที่นี่
PIA ยังรวมอยู่ใน Knime คุณสามารถติดตั้งได้อย่างง่ายดายจากพื้นที่เก็บข้อมูลการมีส่วนร่วมของชุมชนที่เชื่อถือได้ซึ่งมีอยู่ใน Knime รุ่นใหม่ทั้งหมด โปรดใช้ Knime เวอร์ชันใหม่ล่าสุดเสมอก่อนที่จะส่งข้อบกพร่องหรือปัญหาใด ๆ ข้อมูลเพิ่มเติมเกี่ยวกับวิธีการติดตั้งและเรียกใช้ PIA ภายใน Knime สามารถพบได้ในวิกิเกี่ยวกับ PIA ใน Knime
สามารถดาวน์โหลดได้ที่ PDF ที่นี่ข้อมูลที่ต้องการมีอยู่ที่นี่และเวิร์กโฟลว์ที่นี่ (ข้อมูลทั้งหมดมีอยู่ในที่เก็บการสอนที่ https://github.com/mpc-bioinformatics/pia-tutorial/)
สำหรับเอกสารเพิ่มเติมโปรดดูที่ wiki (https://github.com/medbioinf/pia/wiki) บน GitHub
หากคุณมีปัญหาใด ๆ กับ PIA หรือค้นหาข้อบกพร่องและปัญหาอื่น ๆ โปรดใช้ตัวติดตามปัญหาของ GitHub (https://github.com/medbioinf/pia/issues)
หากคุณพบว่า PIA มีประโยชน์สำหรับงานของคุณโปรดอ้างอิงสิ่งพิมพ์ต่อไปนี้:
https://www.ncbi.nlm.nih.gov/pubmed/25938255
https://www.ncbi.nlm.nih.gov/pubmed/30474983
การพัฒนา PIA ได้รับทุนจาก Elixir / de.NBI ซึ่งเป็นเครือข่ายภาษาเยอรมันสำหรับโครงสร้างพื้นฐานทางชีวสารสนเทศศาสตร์
งานเขียนโปรแกรมเกี่ยวกับ PIA ดำเนินการโดย Julian Uszkoreit (Ruhr University Bochum, ชีวสารสนเทศศาสตร์ทางการแพทย์) และ Yasset Perez-Riverol (สถาบันชีวสารสนเทศศาสตร์ยุโรป (EMBL-EBI), Cambridge)


