pia
1.5.5
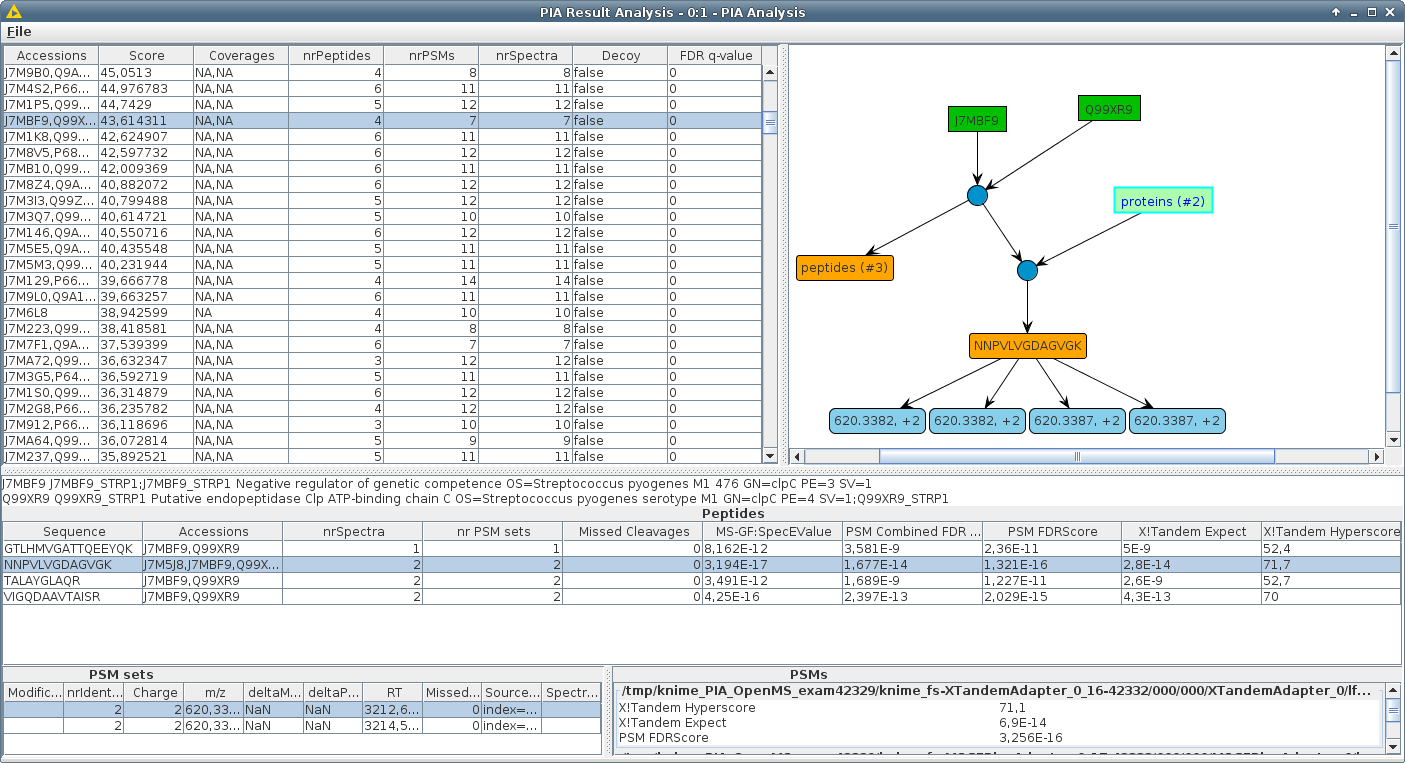
PIA adalah kotak alat untuk inferensi protein dan analisis identifikasi berbasis MS.
PIA memungkinkan Anda untuk memeriksa hasil mesin pencari identifikasi spektrum proteomik umum, menggabungkannya dengan mulus dan melakukan analisis statistik. Fokus utama PIA terletak pada algoritma inferensi terintegrasi, yaitu menyimpulkan protein dari serangkaian spektrum yang diidentifikasi. Tetapi juga memungkinkan Anda untuk memeriksa spektrum peptida Anda cocok, menghitung nilai FDR di berbagai hasil mesin pencari dan memvisualisasikan korespondensi antara PSM, peptida dan protein.

Sebagian besar mesin pencari untuk identifikasi protein dalam eksperimen MS/MS mengembalikan daftar protein, meskipun pencarian yang sebenarnya menghasilkan satu set spektrum peptida yang cocok (PSM). Langkah dari PSM ke protein disebut "inferensi protein". Jika satu set PSM yang diidentifikasi mendukung deteksi lebih dari satu protein dalam database yang dicari ("ambiguitas protein"), biasanya hanya satu aksesi representatif yang dilaporkan. Perwakilan ini mungkin berbeda menurut mesin pencari dan pengaturan yang digunakan. Dengan demikian daftar protein dari mesin pencari yang berbeda umumnya tidak dapat dibandingkan satu sama lain. PSM mesin pencari komplementer sering digabungkan untuk meningkatkan jumlah protein yang dilaporkan atau untuk memverifikasi bukti peptida, yang ditingkatkan dengan deteksi dengan algoritma yang berbeda.
Kami mengembangkan suite algoritma yang ditulis dalam Java, termasuk node KNIME yang sepenuhnya terpelajar, yang menggabungkan PSM dari berbagai percobaan dan/atau mesin pencari, dan laporan yang konsisten dan dengan demikian hasil yang sebanding. Tidak ada parameter, seperti penyaringan atau penilaian, yang diperbaiki seperti pada pendekatan sebelumnya, tetapi dianggap sefleksibel mungkin, untuk memungkinkan penyesuaian yang dibutuhkan oleh pengguna.
PIA dapat dipanggil melalui baris perintah (juga dalam wadah Docker) atau di lingkungan alur kerja Knime, yang memungkinkan integrasi yang mulus ke dalam alur kerja OpenMS.
Untuk baris perintah, Anda dapat mengunduh versi terbaru yang dirilis menggunakan Conda (masing -masing Bioconda) atau mengunduh build di sini.
PIA juga diintegrasikan ke dalam Knime. Anda dapat dengan mudah menginstalnya dari repositori kontribusi komunitas tepercaya, yang tersedia di semua versi Knime yang lebih baru. Harap gunakan selalu versi knime terbaru sebelum mengirimkan bug atau masalah. Informasi lebih lanjut tentang cara menginstal dan menjalankan PIA di dalam Knime dapat ditemukan di wiki tentang PIA di Knime.
Tutorial sebagai PDF dapat diunduh di sini, data yang diperlukan tersedia di sini dan alur kerja di sini (semua data juga tersedia di repositori tutorial di https://github.com/mpc-bioinformatics/pia-tutorial/).
Untuk dokumentasi lebih lanjut, silakan merujuk ke wiki (https://github.com/medbioinf/pia/wiki) di github.
Jika Anda memiliki masalah dengan PIA atau menemukan bug dan masalah lainnya, silakan gunakan pelacak masalah GitHub (https://github.com/medbioinf/pia/issues).
Jika Anda menemukan PIA berguna untuk pekerjaan Anda, silakan kutip publikasi berikut:
https://www.ncbi.nlm.nih.gov/pubmed/25938255
https://www.ncbi.nlm.nih.gov/pubmed/30474983
Pengembangan PIA didanai oleh Elixir / DE.NBI, Jaringan Jerman untuk Infrastruktur Bioinformatika.
Pekerjaan pemrograman pada PIA dilakukan oleh Julian Uszkoreit (Ruhr University Bochum, Medical Bioinformatics), dan Yasset Perez-Riverol (European Bioinformatics Institute (EMBL-EBI), Cambridge)


