automate tech post
1.0.0
Цель этого хранилища состоит в том, чтобы продемонстрировать, как вы можете использовать две методы при суммировании и преобразовании контента из блогов с открытым исходным кодом для создания сообщений в социальных сетях.
Вы можете найти соответствующий код для этого подхода в рамках llm-automation/blog_to_post.py и llm-automation/utils.py
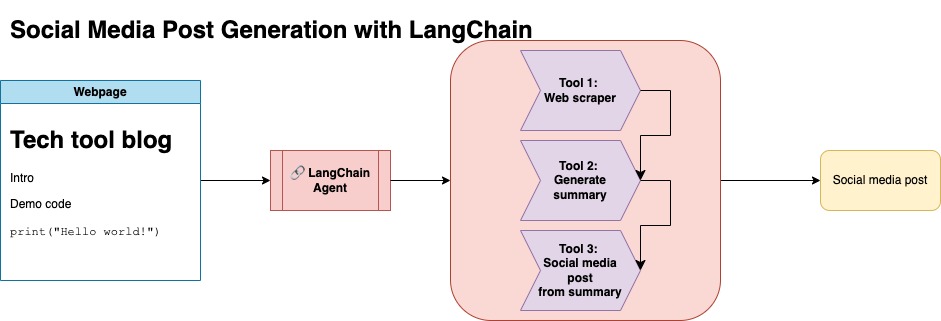
Этот подход предполагает, что у вас есть ключ API OpenAI. Код в этом репозитории использует GPT-4, но вы можете изменить его для использования других моделей OpenAI. Этот скрипт генерирует синтетические данные, состоящие из резюме для сообщений в блоге, найденных в Numpy's Jupyterbook, наряду с соответствующей ссылкой и предлагаемым сообщением в социальных сетях.
Я скрещивал данные из Numpy's Jupyterbook и использовал API Langchain и Openai для создания синтетического набора данных, состоящего из сводки блога, наряду с предлагаемым сообщением в социальных сетях.
Ниже приведен пример ввода данных:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Этот набор данных был затем загружен на обнимающееся лицо. Вы можете найти его через модельную карту lgfunderburk/numpy-docs
Этот подход предполагает, что у вас есть учетная запись об объятиях, а также читать и записать токены доступа. Точная настройка потребует GPU и высокого использования RAM.
Этот подход использует синтетические данные, генерируемые на шаге 1.
Вы можете найти соответствующий код для этого подхода в разделе notebooks/bloom_tuning.ipynb .
Шаги следующие:
Скачать Bloomz-3b с обнимающегося лица через его модельную карту bigscience/bloomz-3b . Это токенизатор для всех моделей Bloom.
Затем мы применяем пост-обработку на 8-битной модели, чтобы обеспечить обучение, заморозить слои и отбрасывать норм слоя в Float32 для стабильности. Мы бросаем выход последнего слоя в Float32.
Загрузите модель эффективной точной настройки параметра (PEFT) и примените адаптеры с низким уровнем ранга (LORA).
Предварительные синтетические данные с помощью приглашения
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Данные могут быть нанесены на карту
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer из библиотеки transformers на сопоставленных данных. 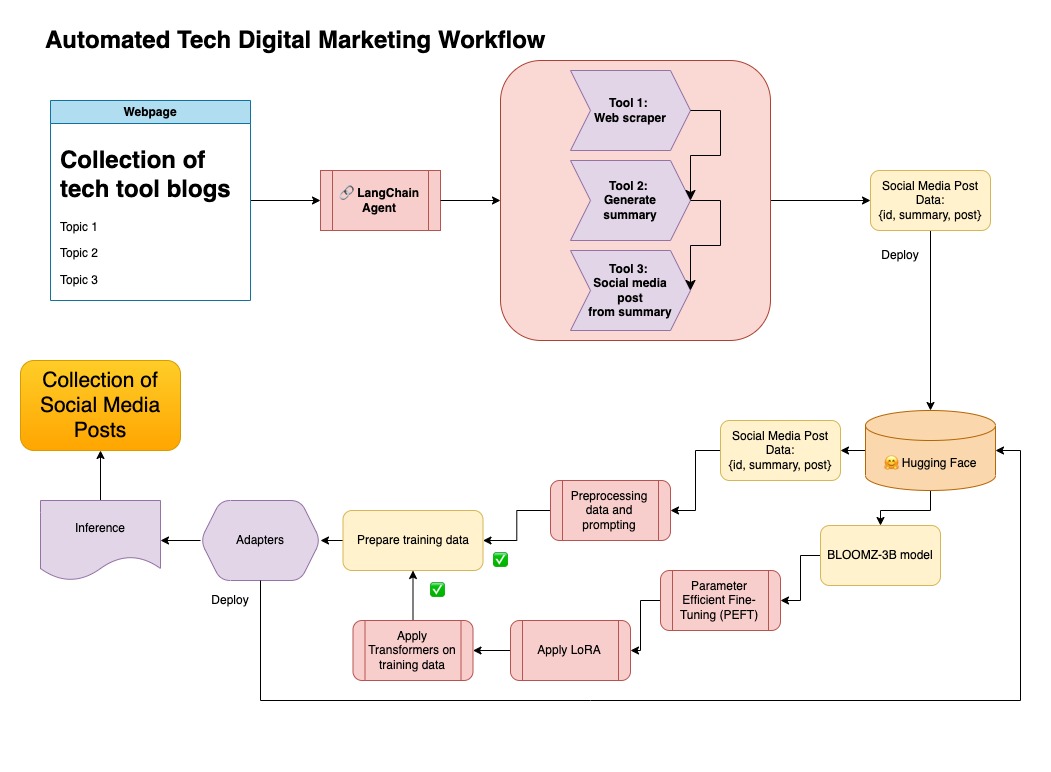
В этом репозитории я объединил оба подхода к сначала с помощью синтетических данных с трубопроводом Langchain и использовал полученный набор данных вместе с методами, упомянутыми для точной настройки модели.
Создать виртуальную среду
conda create --name postenv python==3.10
Активировать
conda activate postenv
Клонировать репо и установить зависимости
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Создайте файл .env , где вы можете сохранить свой ключ API OpenAI. Установите свой ключ в файле .env следующим образом:
OPENAI_API_KEY = <your-keyy>
Вы можете выполнить трубопровод следующим образом:
python llm-automation/blog_to_post.py
Если вы предпочитаете не использовать API OpenAI и вместо этого настраивать модель, вы можете использовать следующую ноутбук Colab.
Обучение модели требует графических процессоров и высокой оперативной памяти. Если ваша локальная машина не поддерживает это, вы можете использовать Colab Pro со следующими характеристиками:
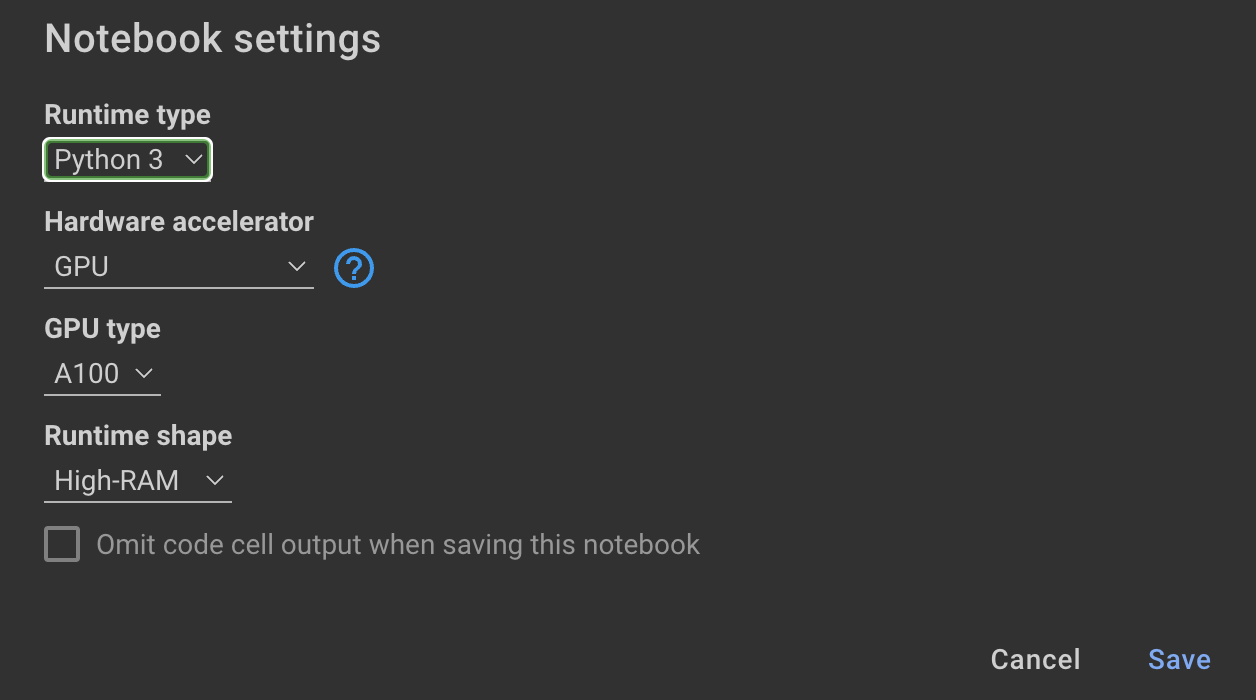
Следующая ноутбука в этом репозитории проводит вас через шаги: notebooks/bloom_tuning.ipynb .
Если вы просто хотите использовать модель, которую я точно настроил с помощью синтетического набора данных, вы можете открыть ноутбук
noebooks/use_fine_tuned_model.ipynb
Тема может быть указана следующим образом:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
Функция make_inference будет затем использовать эту тему для создания образца пост в социальных сетях.


