automate tech post
1.0.0
O objetivo deste repositório é demonstrar como você pode aproveitar duas técnicas ao resumir e transformar o conteúdo de blogs de código aberto para gerar postagens de mídia social.
Você pode encontrar o código relevante para essa abordagem em llm-automation/blog_to_post.py e llm-automation/utils.py
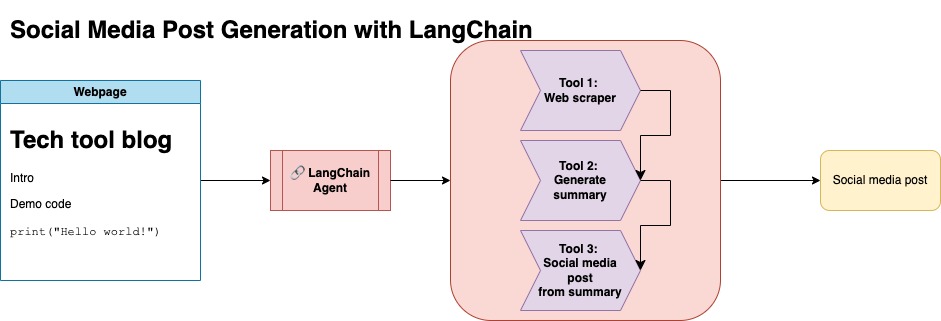
Essa abordagem pressupõe que você tenha uma chave de API OpenAI. O código deste repositório usa o GPT-4, mas você pode modificar isso para usar outros modelos OpenAI. Esse script gera dados sintéticos que consistem em resumos para postagens de blog encontradas no JupyterBook de Numpy, juntamente com o link correspondente e uma postagem de mídia social sugerida.
Recusei dados do JupyterBook de Numpy e usei a API Langchain e Openai para gerar um conjunto de dados sintéticos que consiste no resumo do blog, juntamente com um post sugerido de mídia social.
Abaixo está uma amostra de entrada de dados:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Este conjunto de dados foi enviado para abraçar o rosto. Você pode encontrá-lo através do modelo de cartão LGFUNDBURK/Numpy-Docs
Essa abordagem pressupõe que você tenha uma conta de rosto abraçada, além de ler e gravar tokens de acesso. O ajuste fino exigirá GPU e alto uso de RAM.
Essa abordagem está usando os dados sintéticos gerados na etapa 1.
Você pode encontrar o código relevante para essa abordagem em notebooks/bloom_tuning.ipynb .
As etapas são as seguintes:
Faça o download da Bloomz-3b de abraçar o rosto por meio de seu cartão de modelo bigscience/bloomz-3b . Este é o Tokenizer para todos os modelos Bloom.
Em seguida, aplicamos pós-processamento no modelo de 8 bits para permitir o treinamento, congelar camadas e lançar a norma de camada no float32 para estabilidade. Nós lançamos a saída da última camada no float32.
Carregue um modelo de ajuste fino (PEFT) eficiente em parâmetro e aplique adaptadores de baixo rank (LORA).
Dados sintéticos pré -processados por meio de um prompt
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Os dados podem ser mapeados
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer na biblioteca transformers nos dados mapeados. 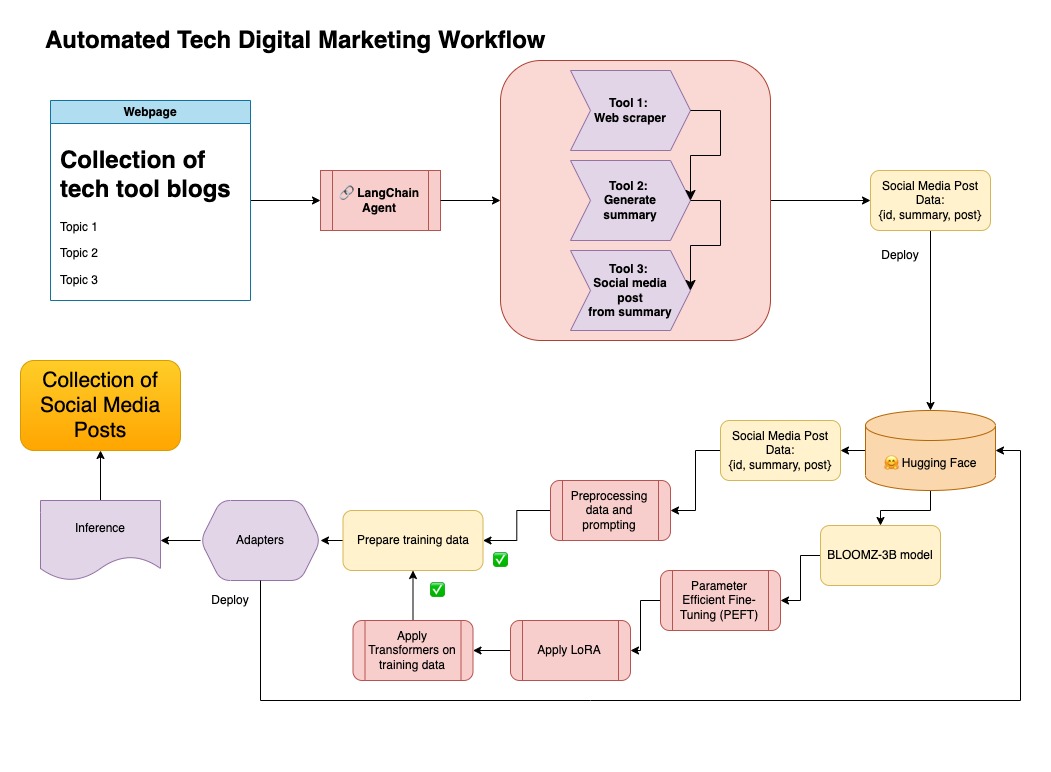
Neste repositório, combinei ambas as abordagens para primeiro curar dados sintéticos com o pipeline de Langchain e usei o conjunto de dados resultante junto com as técnicas mencionadas para ajustar um modelo.
Crie um ambiente virtual
conda create --name postenv python==3.10
Ativar
conda activate postenv
Clone repositório e instalar dependências
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Crie um arquivo .env onde você pode armazenar sua chave de API do OpenAI. A chave definida no arquivo .env da seguinte forma:
OPENAI_API_KEY = <your-keyy>
Você pode executar o oleoduto da seguinte forma:
python llm-automation/blog_to_post.py
Se você preferir não usar a API OpenAI e ajustar um modelo, pode usar o seguinte notebook Colab.
Treinamento O modelo requer GPUs e alto RAM. Se sua máquina local não suportar isso, você poderá usar o Colab Pro com as seguintes especificações:
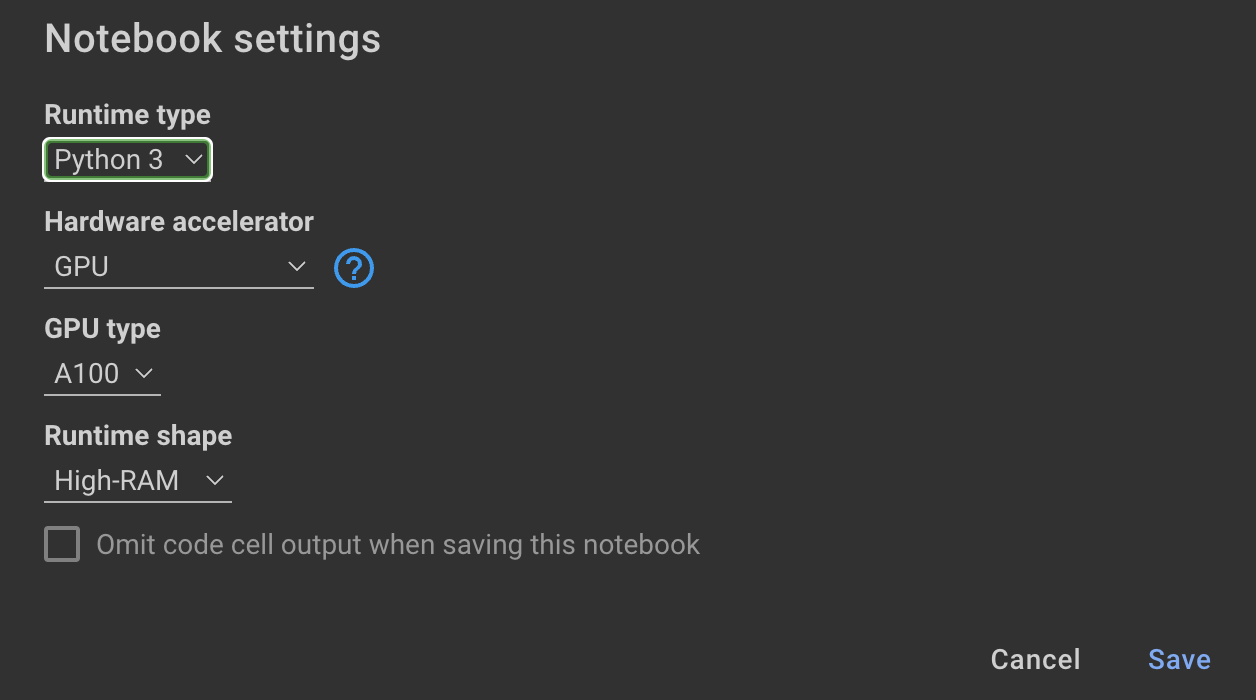
O caderno a seguir neste repositório o guia através das etapas: notebooks/bloom_tuning.ipynb .
Se você simplesmente deseja usar o modelo que eu ajustei com o conjunto de dados sintéticos, você pode abrir o caderno
noebooks/use_fine_tuned_model.ipynb
O tópico pode ser especificado da seguinte forma:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
A função make_inference usará este tópico para gerar uma amostra de postagem de mídia social.


