automate tech post
1.0.0
Tujuan dari repositori ini adalah untuk menunjukkan bagaimana Anda dapat memanfaatkan dua teknik ketika merangkum dan mengubah konten dari blog open source untuk menghasilkan posting media sosial.
Anda dapat menemukan kode yang relevan untuk pendekatan ini di bawah llm-automation/blog_to_post.py dan llm-automation/utils.py
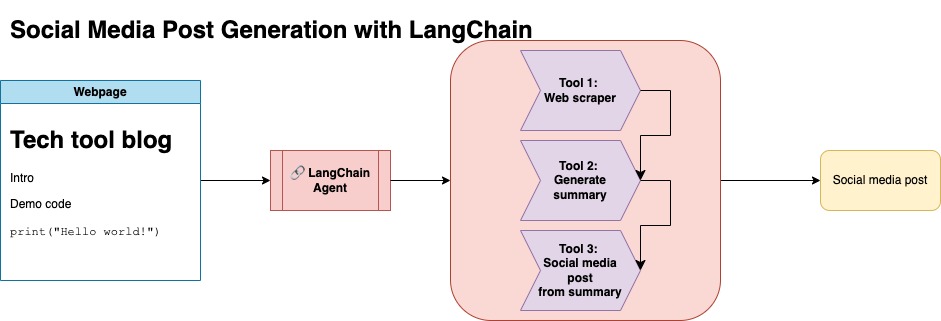
Pendekatan ini mengasumsikan Anda memiliki kunci API openai. Kode dalam repositori ini menggunakan GPT-4, tetapi Anda dapat memodifikasi ini untuk menggunakan model OpenAI lainnya. Skrip ini menghasilkan data sintetis yang terdiri dari ringkasan untuk posting blog yang ditemukan di bawah jupyterbook Numpy, bersama dengan tautan yang sesuai dan posting media sosial yang disarankan.
Saya mengikis data dari Jupyterbook Numpy dan menggunakan Langchain dan Openai API untuk menghasilkan dataset sintetis yang terdiri dari ringkasan blog, bersama dengan posting media sosial yang disarankan.
Di bawah ini adalah entri data sampel:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Dataset ini kemudian diunggah untuk memeluk wajah. Anda dapat menemukannya melalui kartu model lgfunderburk/numpy-docs
Pendekatan ini mengasumsikan Anda memiliki akun yang memeluk, serta membaca dan menulis token akses. Fine-tuning akan membutuhkan GPU dan penggunaan RAM tinggi.
Pendekatan ini menggunakan data sintetis yang dihasilkan pada langkah 1.
Anda dapat menemukan kode yang relevan untuk pendekatan ini di bawah notebooks/bloom_tuning.ipynb .
Langkah -langkahnya adalah sebagai berikut:
Unduh Bloomz-3b dari Face Hugging melalui kartu model bigscience/bloomz-3b . Ini adalah tokenizer untuk semua model Bloom.
Kami kemudian menerapkan pemrosesan pos pada model 8-bit untuk memungkinkan pelatihan, membekukan lapisan, dan melemparkan norma lapisan di float32 untuk stabilitas. Kami melemparkan output dari lapisan terakhir di float32.
Muat model parameter efisien fine-tuning (PEFT) dan terapkan adaptor peringkat rendah (LORA).
Data sintetis preprocess melalui prompt
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Data kemudian dapat dipetakan
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer dari pustaka transformers pada data yang dipetakan. 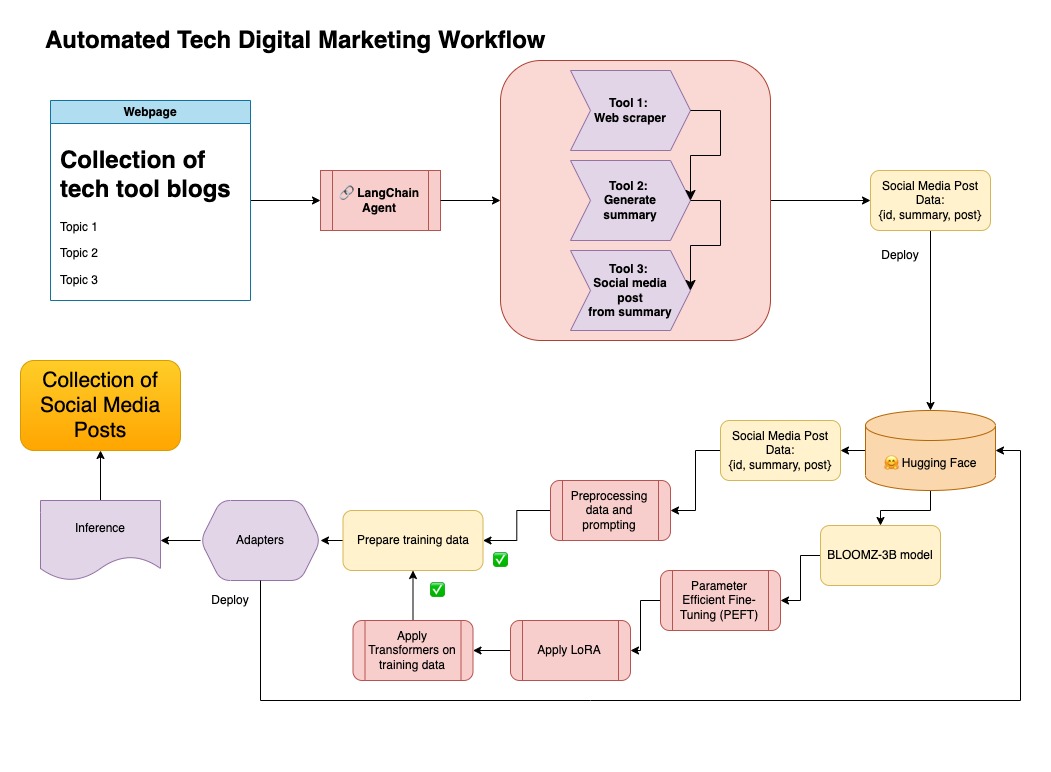
Dalam repositori ini saya menggabungkan kedua pendekatan untuk membuat data sintetis pertama dengan pipa Langchain, dan menggunakan dataset yang dihasilkan bersama dengan teknik yang disebutkan untuk menyempurnakan model.
Buat lingkungan virtual
conda create --name postenv python==3.10
Mengaktifkan
conda activate postenv
Klon repo dan instal dependensi
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Buat file .env tempat Anda dapat menyimpan kunci API openai Anda. Setel kunci Anda di dalam file .env sebagai berikut:
OPENAI_API_KEY = <your-keyy>
Anda dapat menjalankan pipa sebagai berikut:
python llm-automation/blog_to_post.py
Jika Anda lebih suka untuk tidak menggunakan OpenAI API dan mencari-cari model, Anda dapat menggunakan Colab Notebook berikut.
Melatih model membutuhkan GPU dan RAM tinggi. Jika mesin lokal Anda tidak mendukung ini, Anda dapat menggunakan Colab Pro dengan spesifikasi berikut:
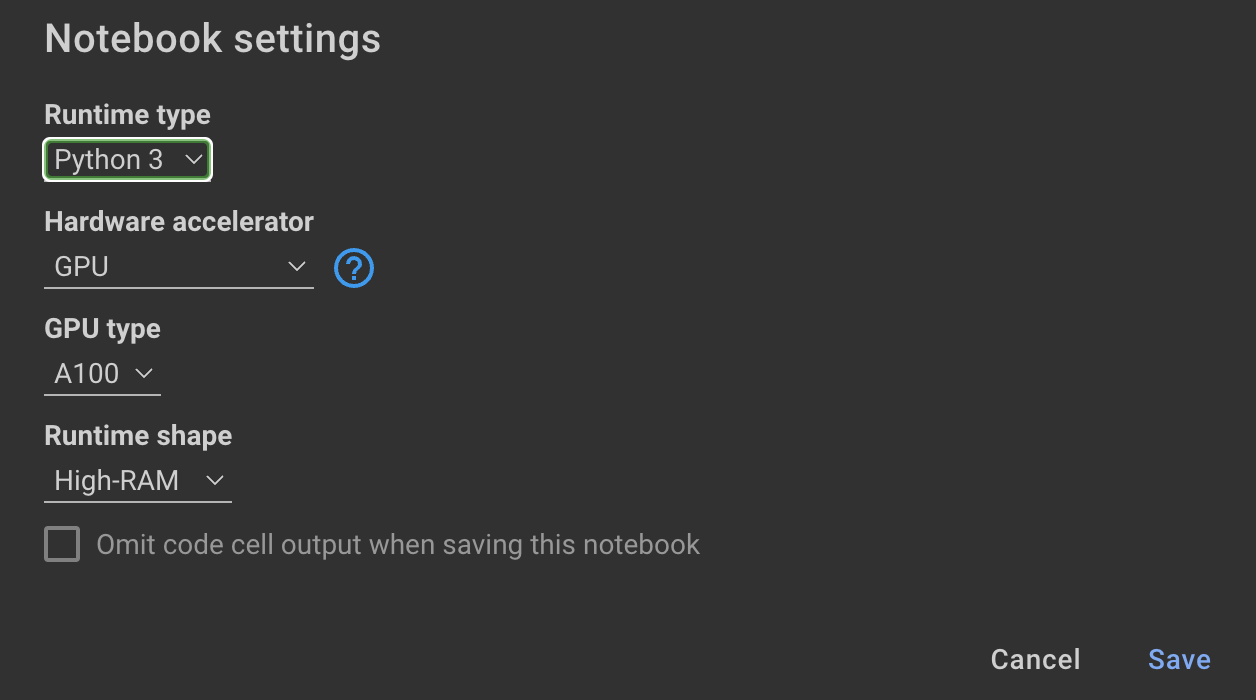
Buku catatan berikut dalam repositori ini memandu Anda melalui langkah -langkah: notebooks/bloom_tuning.ipynb .
Jika Anda hanya ingin menggunakan model yang saya selesaikan dengan dataset sintetis, Anda dapat membuka notebook
noebooks/use_fine_tuned_model.ipynb
Topik dapat ditentukan sebagai berikut:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
Fungsi make_inference kemudian akan menggunakan topik ini untuk menghasilkan posting media sosial sampel.


