automate tech post
1.0.0
Le but de ce référentiel est de démontrer comment vous pouvez tirer parti de deux techniques lors de la résumé et de la transformation du contenu à partir de blogs open source pour générer des publications sur les réseaux sociaux.
Vous pouvez trouver le code pertinent pour cette approche sous llm-automation/blog_to_post.py et llm-automation/utils.py
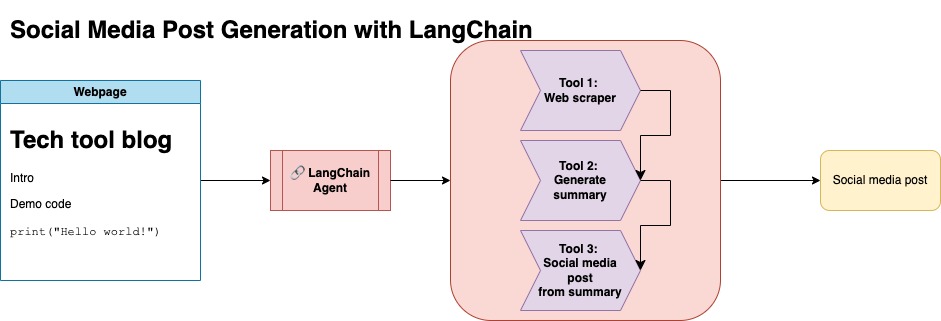
Cette approche suppose que vous avez une clé API OpenAI. Le code de ce référentiel utilise GPT-4, mais vous pouvez le modifier pour utiliser d'autres modèles OpenAI. Ce script génère des données synthétiques composées de résumés pour les articles de blog trouvés sous JupyterBook de Numpy, ainsi que le lien correspondant et une publication de médias sociaux suggérée.
J'ai gratté les données de Jupyterbook de Numpy et utilisé l'API Langchain et Openai pour générer un ensemble de données synthétique composé du résumé du blog, ainsi qu'une publication de médias sociaux suggérée.
Vous trouverez ci-dessous un exemple de saisie de données:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Cet ensemble de données a ensuite été téléchargé sur un visage étreint. Vous pouvez le trouver via la carte modèle lgfunderburk / numpy-docs
Cette approche suppose que vous avez un compte de visage étreint, ainsi que des jetons d'accès à lire et à écrire. Le réglage fin nécessitera un GPU et une utilisation élevée de la RAM.
Cette approche utilise les données synthétiques générées à l'étape 1.
Vous pouvez trouver le code pertinent pour cette approche sous notebooks/bloom_tuning.ipynb .
Les étapes sont les suivantes:
Téléchargez Bloomz-3b de Hugging Face via sa carte modèle bigscience/bloomz-3b . Il s'agit d'un jetons pour tous les modèles de floraison.
Nous appliquons ensuite le post-traitement sur le modèle 8 bits pour permettre la formation, geler les couches et lancer la couche de couche dans Float32 pour la stabilité. Nous jetons la sortie de la dernière couche dans Float32.
Chargez un modèle de réglage fin efficace par les paramètres (PEFT) et appliquez des adaptateurs de bas rang (LORA).
Données synthétiques prétraitées via une invite
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Les données peuvent ensuite être mappées
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer à partir de la bibliothèque transformers sur les données mappées. 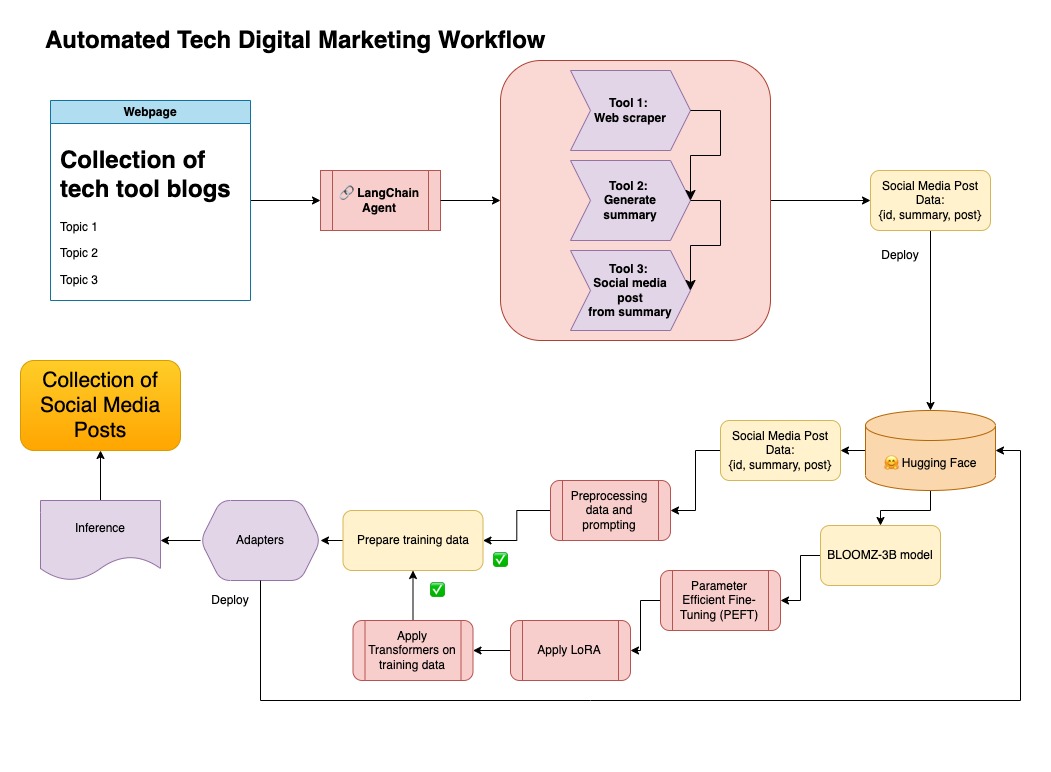
Dans ce référentiel, j'ai combiné les deux approches des données synthétiques de premier organisme avec le pipeline de Langchain, et j'ai utilisé l'ensemble de données résultant avec les techniques mentionnées pour affiner un modèle.
Créer un environnement virtuel
conda create --name postenv python==3.10
Activer
conda activate postenv
Clone Repo and Installer les dépendances
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Créez un fichier .env où vous pouvez stocker votre clé API OpenAI. Définissez votre clé dans le fichier .env comme suit:
OPENAI_API_KEY = <your-keyy>
Vous pouvez exécuter le pipeline comme suit:
python llm-automation/blog_to_post.py
Si vous préférez ne pas utiliser l'API OpenAI et affiner un modèle à la place, vous pouvez utiliser le cahier Colab suivant.
La formation du modèle nécessite des GPU et des RAM élevés. Si votre machine locale ne prend pas en charge cela, vous pouvez utiliser Colab Pro avec les spécifications suivantes:
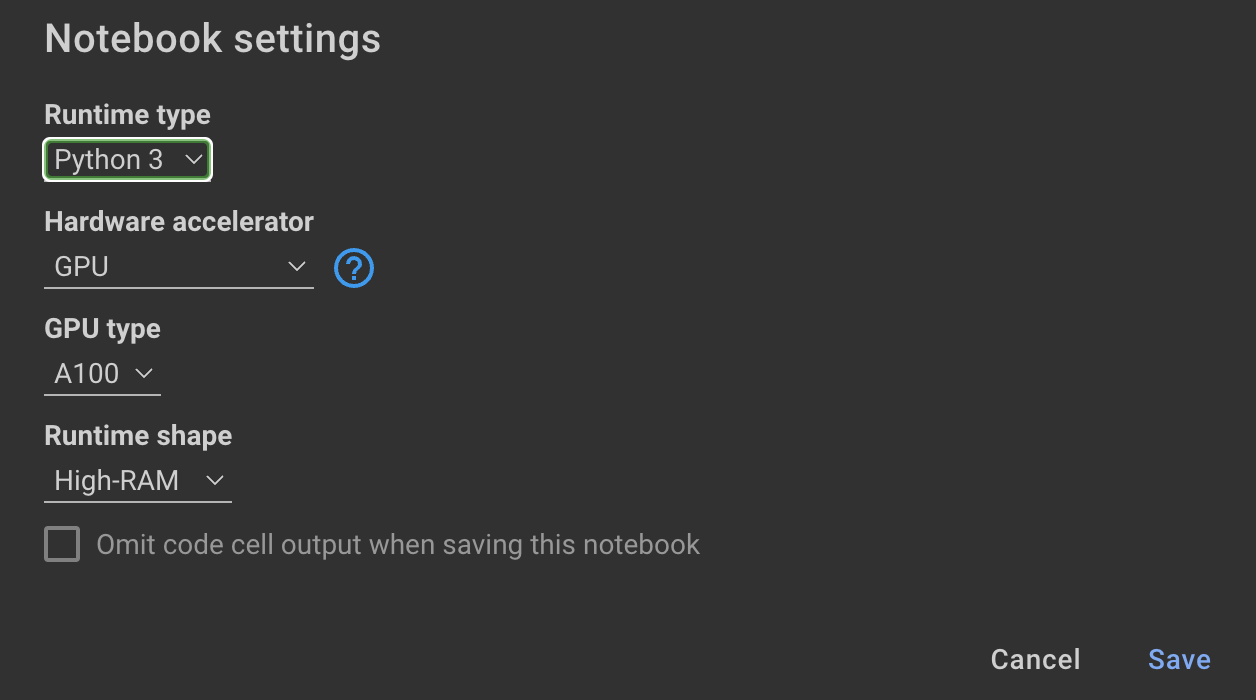
Le cahier suivant dans ce référentiel vous guide à travers les étapes: notebooks/bloom_tuning.ipynb .
Si vous souhaitez simplement utiliser le modèle, j'ai affiné avec l'ensemble de données synthétique, vous pouvez ouvrir le cahier
noebooks/use_fine_tuned_model.ipynb
Le sujet peut être spécifié comme suit:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
La fonction make_inference utilisera ensuite ce sujet pour générer un exemple de publication de médias sociaux.


