automate tech post
1.0.0
الغرض من هذا المستودع هو توضيح كيف يمكنك الاستفادة من تقنيتين عند تلخيص وتحويل المحتوى من المدونات المفتوحة المصدر لإنشاء منشورات الوسائط الاجتماعية.
يمكنك العثور على الكود ذي الصلة لهذا النهج ضمن llm-automation/blog_to_post.py و llm-automation/utils.py
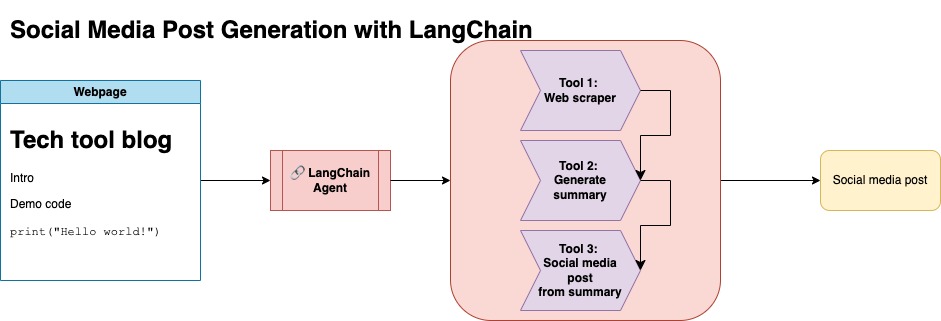
يفترض هذا النهج أن لديك مفتاح Openai API. يستخدم الرمز في هذا المستودع GPT-4 ، ولكن يمكنك تعديل هذا لاستخدام نماذج OpenAI الأخرى. يقوم هذا البرنامج النصي بإنشاء بيانات اصطناعية تتكون من ملخصات لمشاركات المدونة الموجودة في Numpy's Jupyterbook ، إلى جانب الرابط المقابل ومنشور الوسائط الاجتماعية المقترحة.
لقد قمت بتخليص البيانات من Numpy's Jupyterbook واستخدمت Langchain و Openai API لإنشاء مجموعة بيانات اصطناعية تتكون من ملخص المدونة ، إلى جانب منشور على وسائل التواصل الاجتماعي المقترحة.
فيما يلي إدخال بيانات عينة:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
ثم تم تحميل مجموعة البيانات هذه إلى معانقة الوجه. يمكنك العثور عليها عبر بطاقة النموذج LGFunderburk/Numpy-Docs
يفترض هذا النهج أن لديك حساب الوجه المعانقة ، وكذلك قراءة رموز الوصول وكتابة. سيتطلب الضبط الدقيق استخدام وحدة معالجة الرسومات وذاكرة الوصول العشوائي العالية.
هذا النهج يستخدم البيانات الاصطناعية التي تم إنشاؤها في الخطوة 1.
يمكنك العثور على الكود ذي الصلة لهذا النهج ضمن notebooks/bloom_tuning.ipynb .
الخطوات كما يلي:
قم بتنزيل Bloomz-3B من Hugging Face عبر بطاقة الطراز bigscience/bloomz-3b . هذا هو الرمز المميز لجميع نماذج بلوم.
نطبق بعد ذلك معالجة ما بعد المعالجة على طراز 8 بت لتمكين التدريب ، وتجميد الطبقات ، ونلقي بطبقة الطبقات في Float32 للاستقرار. نلقي الإخراج من الطبقة الأخيرة في Float32.
قم بتحميل نموذج الصقل الدقيق (PEFT) فعال المعلمة وقم بتطبيق محولات منخفضة الرتبة (LORA).
البيانات الاصطناعية قبل المعالجة عبر موجه
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
يمكن بعد ذلك تعيين البيانات
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer من مكتبة transformers على البيانات المعينة. 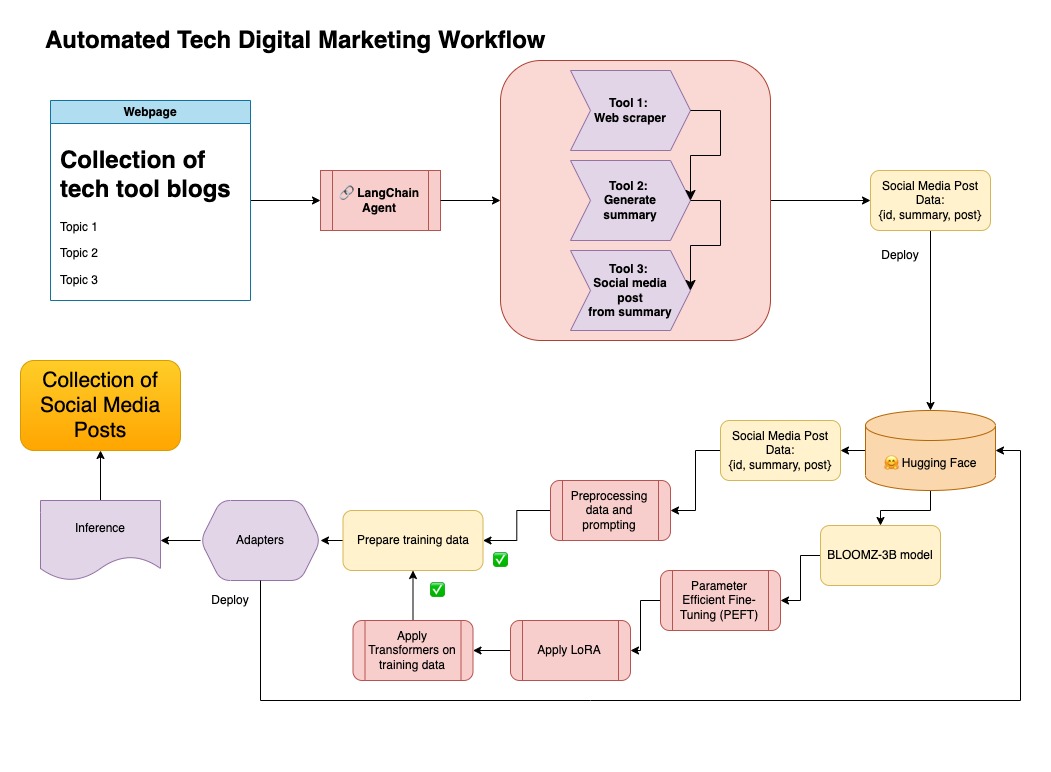
في هذا المستودع ، قمت بدمج كلا النهجين لتنظيم البيانات الاصطناعية الأولى مع خط أنابيب Langchain ، واستخدمت مجموعة البيانات الناتجة إلى جانب التقنيات المذكورة لضبط النموذج.
إنشاء بيئة افتراضية
conda create --name postenv python==3.10
فعل
conda activate postenv
استنساخ إعادة التبعيات وتثبيت التبعيات
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
قم بإنشاء ملف .env حيث يمكنك تخزين مفتاح Openai API الخاص بك. تعيين المفتاح الخاص بك ضمن ملف .env على النحو التالي:
OPENAI_API_KEY = <your-keyy>
يمكنك تنفيذ خط الأنابيب على النحو التالي:
python llm-automation/blog_to_post.py
إذا كنت تفضل عدم استخدام API Openai وضبط نموذج بدلاً من ذلك ، فيمكنك استخدام دفتر Notebook التالي.
يتطلب تدريب النموذج وحدات معالجة الرسومات والذاكرة العالية. إذا لم يدعم جهازك المحلي هذا ، فيمكنك استخدام Colab Pro مع المواصفات التالية:
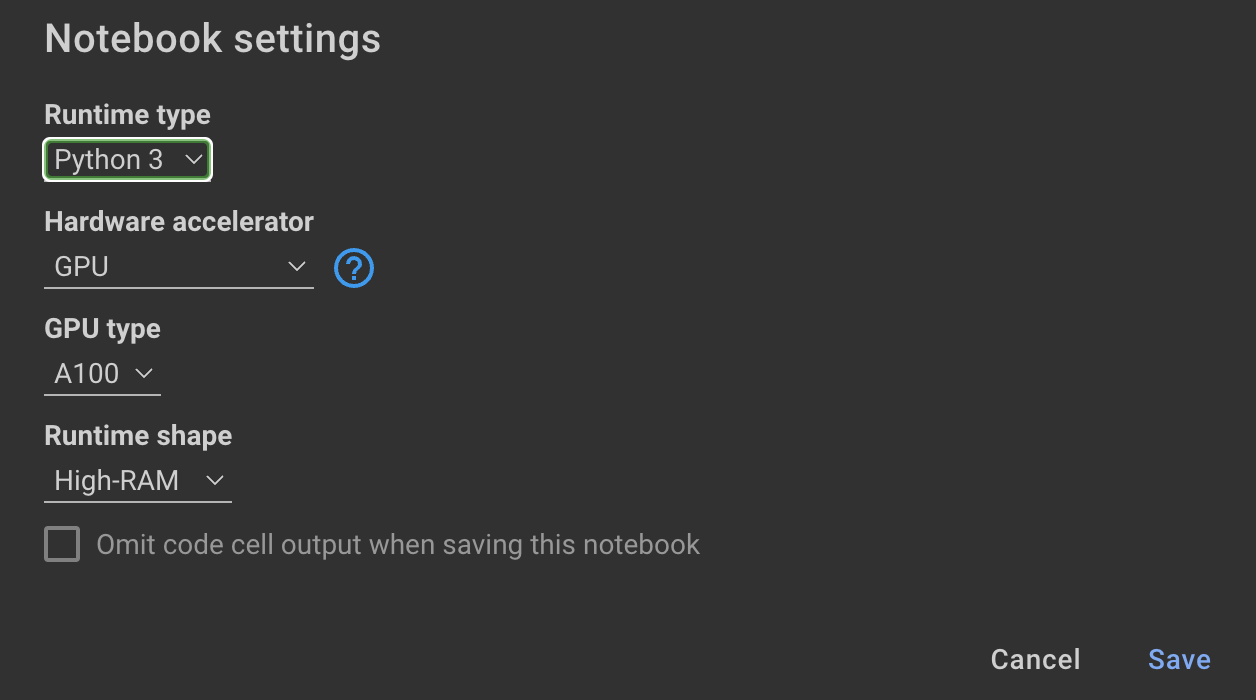
يوجهك دفتر الملاحظات التالي ضمن هذا المستودع من خلال الخطوات: notebooks/bloom_tuning.ipynb .
إذا كنت ترغب ببساطة في استخدام النموذج الذي قمت بضبطه مع مجموعة البيانات الاصطناعية ، فيمكنك فتح دفتر الملاحظات
noebooks/use_fine_tuned_model.ipynb
يمكن تحديد الموضوع على النحو التالي:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
ستستخدم وظيفة make_inference هذا الموضوع بعد ذلك لإنشاء عينة من وسائل التواصل الاجتماعي.


