automate tech post
1.0.0
El propósito de este repositorio es demostrar cómo puede aprovechar dos técnicas al resumir y transformar contenido de blogs de código abierto para generar publicaciones en las redes sociales.
Puede encontrar el código relevante para este enfoque bajo llm-automation/blog_to_post.py y llm-automation/utils.py
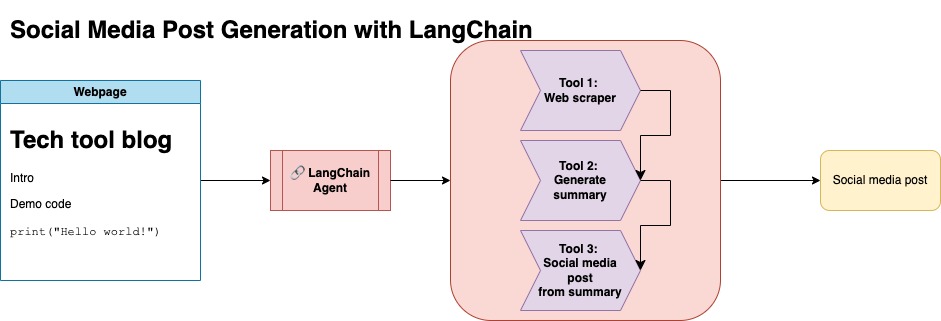
Este enfoque supone que tiene una clave API de OpenAI. El código en este repositorio usa GPT-4, pero puede modificarlo para usar otros modelos OpenAI. Este script genera datos sintéticos que consisten en resúmenes para publicaciones de blog que se encuentran en Jupyterbook de Numpy, junto con el enlace correspondiente y una publicación de redes sociales sugeridas.
Rapé datos de Jupyterbook de Numpy y usé Langchain y OpenAI API para generar un conjunto de datos sintético que consiste en el resumen del blog, junto con una publicación de redes sociales sugerida.
A continuación se muestra una entrada de datos de muestra:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Este conjunto de datos se subió a la cara abrazada. Puede encontrarlo a través de la tarjeta modelo LGFunderBurk/Numpy-Docs
Este enfoque supone que tiene una cuenta de cara abrazada, así como tokens de acceso de lectura y escritura. El ajuste fino requerirá GPU y un alto uso de RAM.
Este enfoque está utilizando los datos sintéticos generados en el paso 1.
Puede encontrar el código relevante para este enfoque en notebooks/bloom_tuning.ipynb .
Los pasos son los siguientes:
Descargue BOOMZ-3B de Hugging Face a través de su tarjeta modelo bigscience/bloomz-3b . Este es Tokenizer para todos los modelos Bloom.
Luego aplicamos el procesamiento posterior al modelo de 8 bits para permitir el entrenamiento, congelar capas y lanzar la norma de capa en Float32 para su estabilidad. Elegamos la salida de la última capa en Float32.
Cargue un modelo de ajuste fino eficiente (PEFT) de parámetros y aplique adaptadores de bajo rango (LORA).
Datos sintéticos de preprocesamiento a través de un aviso
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Los datos se pueden asignar
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer de la biblioteca transformers en los datos mapeados. 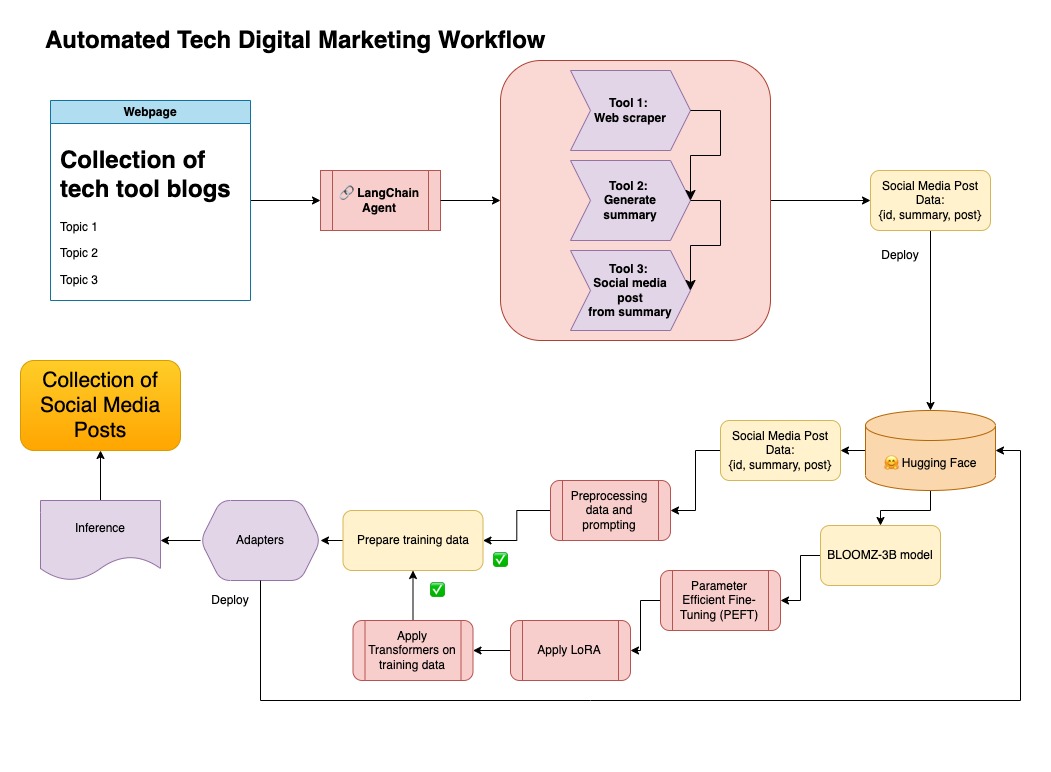
En este repositorio combiné ambos enfoques para curar primero los datos sintéticos con la tubería Langchain, y utilicé el conjunto de datos resultante junto con las técnicas mencionadas para ajustar un modelo.
Crear un entorno virtual
conda create --name postenv python==3.10
Activar
conda activate postenv
Dependencias de Repo e Instalación de clones
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Cree un archivo .env donde pueda almacenar su clave API OpenAI. Establecer su tecla dentro del archivo .env de la siguiente manera:
OPENAI_API_KEY = <your-keyy>
Puede ejecutar la tubería de la siguiente manera:
python llm-automation/blog_to_post.py
Si prefiere no usar la API de OpenAI y ajustar un modelo en su lugar, puede usar el siguiente cuaderno de Colab.
Entrenamiento El modelo requiere GPU y RAM alto. Si su máquina local no admite esto, puede usar Colab Pro con las siguientes especificaciones:
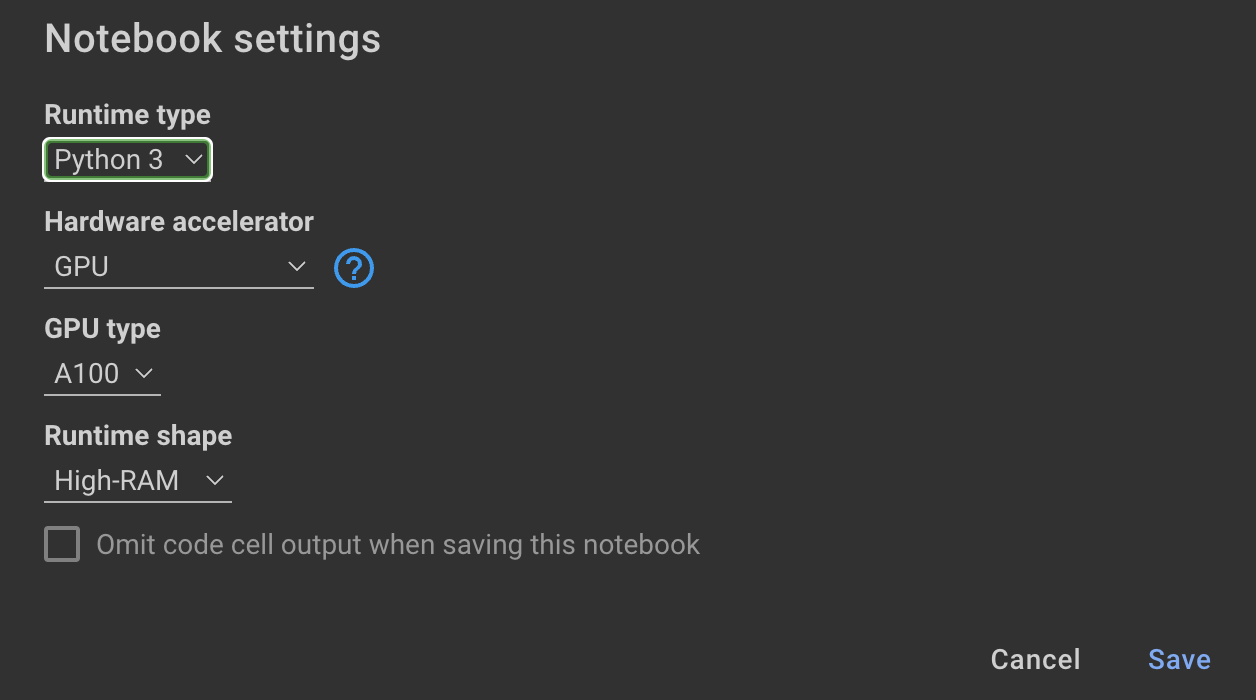
El siguiente cuaderno dentro de este repositorio lo guía a través de los pasos: notebooks/bloom_tuning.ipynb .
Si simplemente desea utilizar el modelo que he ajustado con el conjunto de datos sintético, puede abrir el cuaderno
noebooks/use_fine_tuned_model.ipynb
El tema se puede especificar de la siguiente manera:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
La función make_inference usará este tema para generar una publicación de muestra en las redes sociales.


