automate tech post
1.0.0
Der Zweck dieses Repositorys besteht darin, zu demonstrieren, wie Sie zwei Techniken nutzen können, wenn Sie Inhalte aus Open -Source -Blogs zusammenfassen und umgestalten, um Social -Media -Beiträge zu generieren.
Sie finden den relevanten Code für diesen Ansatz unter llm-automation/blog_to_post.py und llm-automation/utils.py
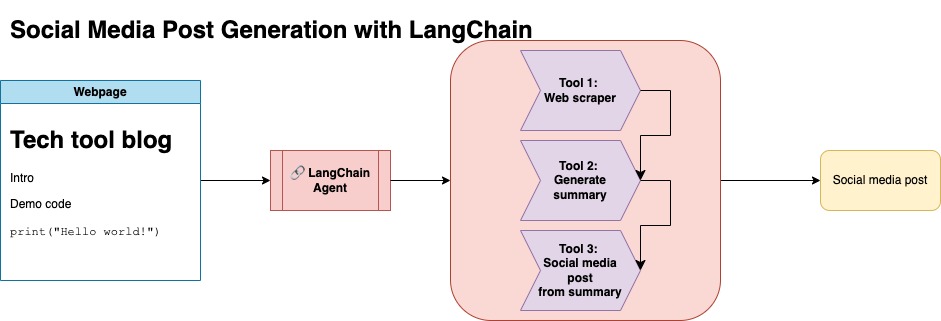
In diesem Ansatz geht davon aus, dass Sie einen OpenAI -API -Schlüssel haben. Der Code in diesem Repository verwendet GPT-4, Sie können dies jedoch so ändern, dass andere OpenAI-Modelle verwendet werden. Dieses Skript generiert synthetische Daten, die aus Zusammenfassungen für Blog -Beiträge, die unter Numpys Jupyterbook gefunden wurden, zusammen mit dem entsprechenden Link und einem vorgeschlagenen Social -Media -Beitrag bestehen.
Ich habe Daten aus Numpys Jupyterbook gekratzt und Langchain und OpenAI -API verwendet, um einen synthetischen Datensatz zu generieren, der aus der Zusammenfassung des Blogs besteht, zusammen mit einem vorgeschlagenen Social -Media -Beitrag.
Unten finden Sie eine Beispieldateneingabe:
{
"id": 1,
"link": "https://numpy.org/numpy-tutorials/content/tutorial-air-quality-analysis.html",
"summary": "Summary: Learn to perform air quality analysis using Python and NumPy in this tutorial! Discover how to import necessary libraries, build and process a dataset, calculate Air Quality Index (AQI), and perform paired Student's t-test on AQIs. We'll focus on the change in Delhi's air quality before and during the lockdown from March to June 2020.",
"social_media_post": "?? Do you know how the lockdown affected Delhi's air quality? ?️? Dive into our latest tutorial exploring air quality analysis using Python ? and NumPy ?! Master the art of importing libraries , building and processing datasets , calculating the Air Quality Index (AQI) ?, and performing the notorious Student's t-test on the AQIs ?. Let's discover the effects of lockdown on Delhi's air quality from March to June 2020 ?. Unravel the truth, and #BreatheEasy! ? #Python #NumPy #AirQuality #DataScience #Tutorial #AQI #Delhi #Lockdown #EnvironmentalAwareness ?"
}
Dieser Datensatz wurde dann in das Umarmungsgesicht hochgeladen. Sie finden es über die Modellkarte lgfunderburk/numpy-docs
In diesem Ansatz geht davon aus, dass Sie über ein umarmendes Gesichtskonto verfügen und auf Tokens zu lesen und zu schreiben. Die Feinabstimmung erfordert eine GPU und einen hohen RAM-Gebrauch.
Dieser Ansatz verwendet die in Schritt 1 generierten synthetischen Daten.
Sie finden den relevanten Code für diesen Ansatz unter notebooks/bloom_tuning.ipynb .
Die Schritte sind wie folgt:
Laden Sie Bloomz-3b von der Modellkarte bigscience/bloomz-3b herunter. Dies ist Tokenizer für alle Bloom -Modelle.
Anschließend wenden wir nach der Verarbeitung des 8-Bit-Modells an, um Schulungen zu ermöglichen, Schichten einzufrieren und den Schichtnorm in Float32 für die Stabilität zu gaben. Wir gaben die Ausgabe der letzten Schicht in Float32.
Laden Sie ein Parameter effizienter Feinabstimmungsmodell (PEFT) und wenden Sie Low-Rank-Adapter (LORA) an.
Synthetische Daten vorzubereiten über eine Eingabeaufforderung
def generate_prompt(summary: str, social_media_post: str) -> str:
prompt = f"### INSTRUCTIONnBelow is a summary of a post
and its corresponding social media post, please
write social media post for this blog.
nn### Summary:n{summary}n### Post:n{social_media_post}n"
return prompt
Die Daten können dann zugeordnet werden
mapped_dataset = dataset.map(lambda samples: tokenizer(generate_prompt(samples['summary'], samples['social_media_post'])))
.Trainer -Methode aus der transformers Library auf den zugeordneten Daten. 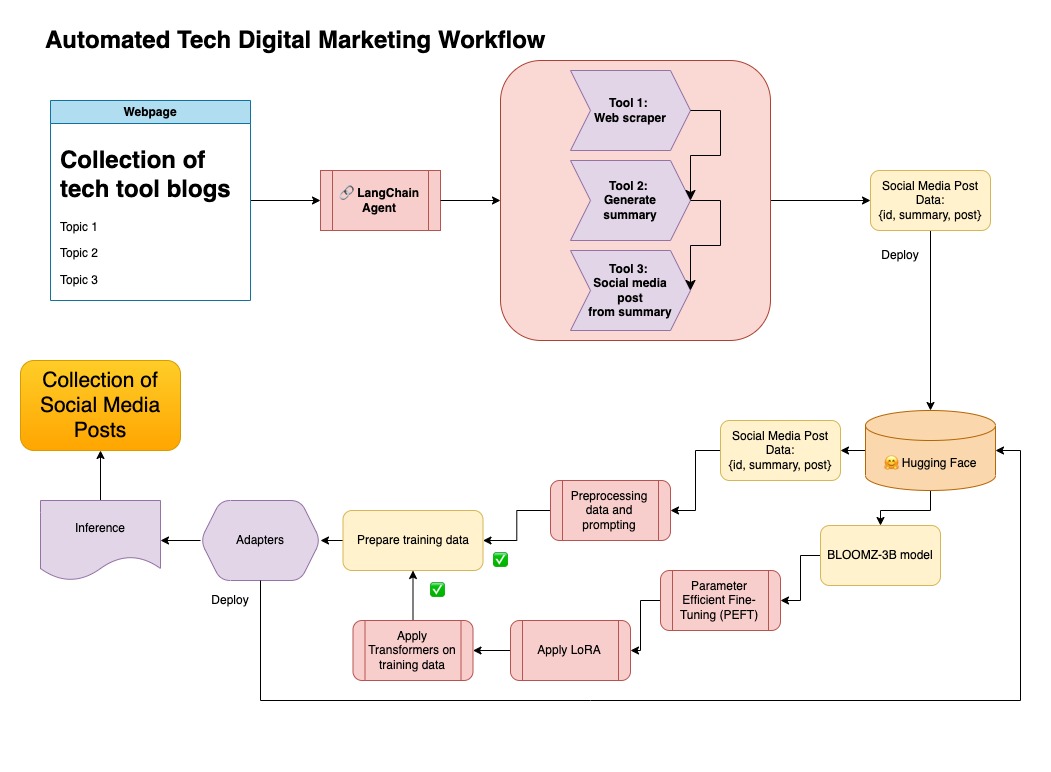
In diesem Repository kombinierte ich beide Ansätze zum ersten Kurat-synthetischen Daten mit der Langchain-Pipeline und verwendete den resultierenden Datensatz zusammen mit den genannten Techniken, um ein Modell zu optimieren.
Erstellen Sie eine virtuelle Umgebung
conda create --name postenv python==3.10
Aktivieren
conda activate postenv
Klonen repo und installieren Abhängigkeiten
git clone https://github.com/lfunderburk/automate-tech-post.git
cd automate-tech-post/
pip install -r requirements.txt
Erstellen Sie eine .env -Datei, in der Sie Ihre OpenAI -API -Schlüssel speichern können. Der Setzen Sie Ihren Schlüssel in der .env -Datei wie folgt fest:
OPENAI_API_KEY = <your-keyy>
Sie können die Pipeline wie folgt ausführen:
python llm-automation/blog_to_post.py
Wenn Sie es vorziehen möchten, OpenAI-API nicht zu verwenden und ein Modell zu optimieren, können Sie das folgende Colab-Notizbuch verwenden.
Training Das Modell erfordert GPUs und hohen RAM. Wenn Ihre lokale Maschine dies nicht unterstützt, können Sie Colab Pro mit den folgenden Spezifikationen verwenden:
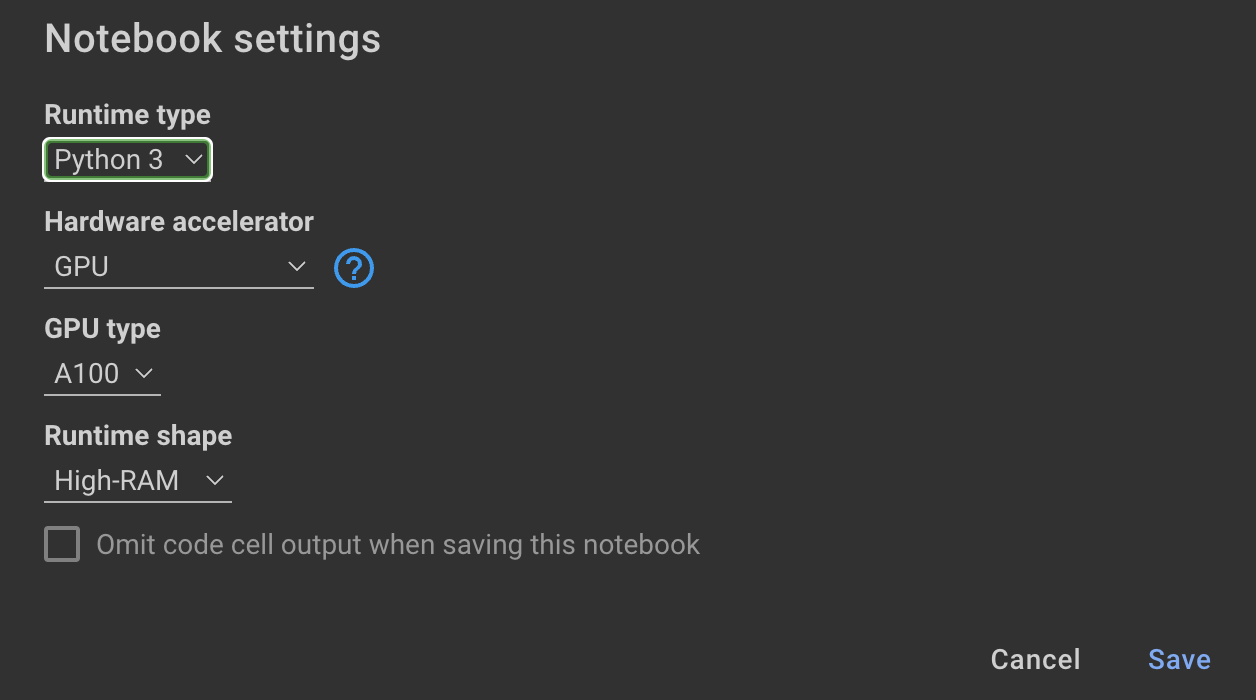
Das folgende Notizbuch in diesem Repository führt Sie durch die Schritte: notebooks/bloom_tuning.ipynb .
Wenn Sie einfach das Modell, das ich mit dem synthetischen Datensatz abgestimmt hat, verwenden möchten, können Sie das Notebook öffnen
noebooks/use_fine_tuned_model.ipynb
Das Thema kann wie folgt angegeben werden:
topic = "This blog post is a tutorial about using NumPy to solve static equilibrium problems in three-dimensional space. Readers will learn how to represent points, vectors, and moments with NumPy, find the normal of vectors, and use NumPy for matrix calculations. The tutorial covers the application of Newton's second law to simple examples of force vectors and introduces more complex cases involving reaction forces and moments. The post also discusses the use of NumPy functions in more varied problems, including kinetic problems and different dimensions."
Die Funktion make_inference verwendet dieses Thema dann, um einen Beispielposten für soziale Medien zu generieren.


