Open3D ML
v0.18 release
Установка | Начните | Структура | Задачи и алгоритмы | Модельный зоопарк | Наборы данных | How-tos | Способствовать
Open3D-ML-это расширение Open3D для задач 3D машинного обучения. Он строится на вершине библиотеки Open3D Core и расширяет ее инструментами машинного обучения для обработки трехмерных данных. Этот репо фокусируется на таких приложениях, как сегментация облака семантических точек, и предоставляет предварительные модели, которые могут применяться для общих задач, а также трубопровода для обучения.
Open3D-ML работает с TensorFlow и Pytorch , чтобы легко интегрироваться в существующие проекты, а также предоставляет общую функциональность, независимую от структуры ML, таких как визуализация данных.
Open3D-ML интегрируется в распределение Open3D V0.11+ Python и совместим со следующими версиями ML Frameworks.
GNU/Linux x86_64 , необязательно)Вы можете установить Open3d с
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dЧтобы установить совместимую версию Pytorch или Tensorflow, вы можете использовать соответствующие файлы требований:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtЧтобы проверить использование установки
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Если вам нужно использовать разные версии ML -фреймворков или CUDA, мы рекомендуем построить Open3D из Source или построить Open3D в Docker.
Начиная с V0.18 на Linux, колесо PYPI Open3D не имеет нативной поддержки TensorFlow из -за несовместимости между Pytorch и TensorFlow [см. Python 3.11 Поддержка PR] для получения подробной информации. Если вы хотите использовать Open3D с TensorFlow на Linux, вы можете построить Open3D -колесо из источника в Docker с поддержкой TensorFlow (но не Pytorch) как:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
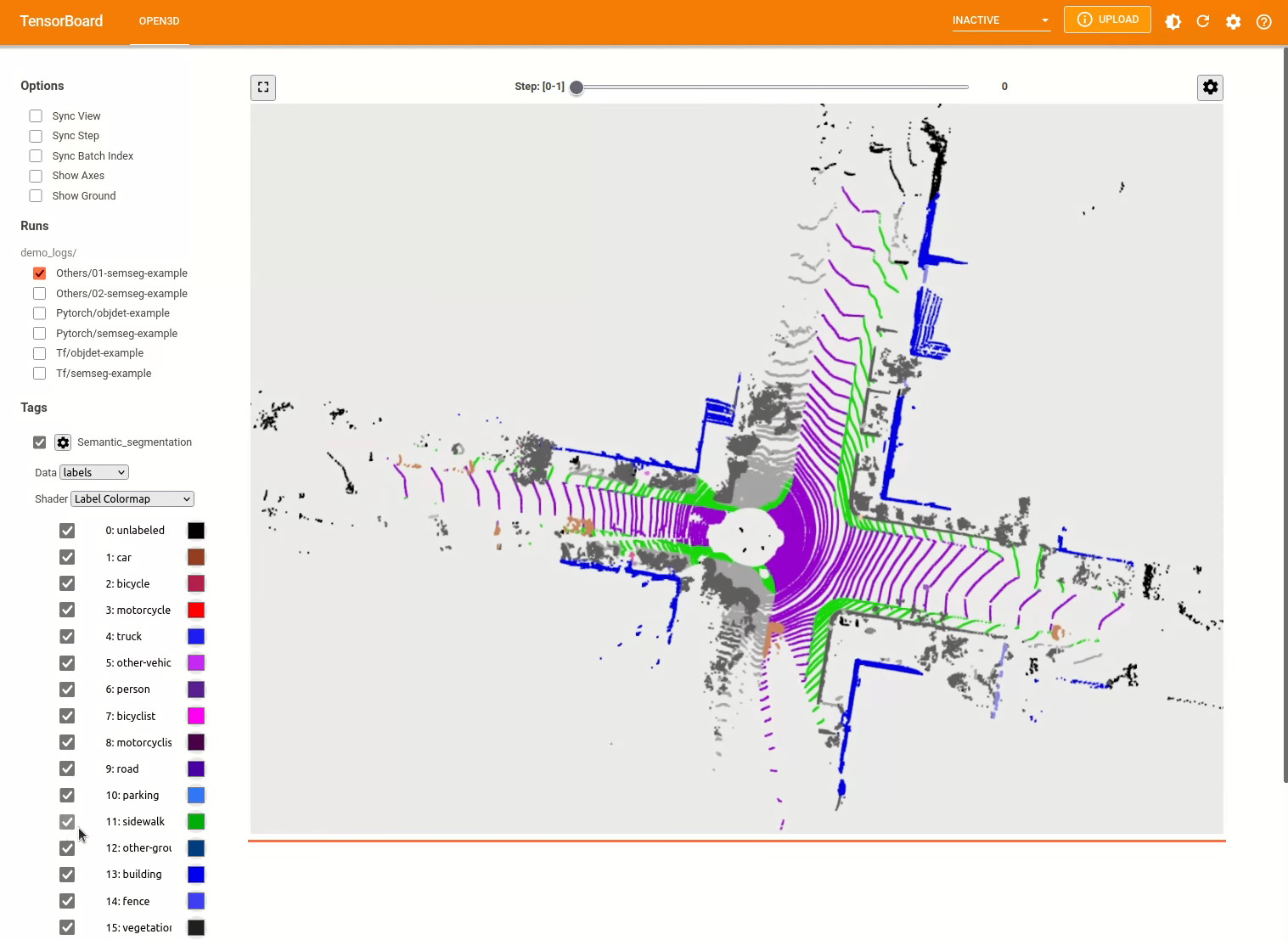
./docker_build.sh cuda_wheel_py310Пространство имен набора данных содержит классы для чтения общих наборов данных. Здесь мы читаем набор данных Semantickitti и визуализируем его.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))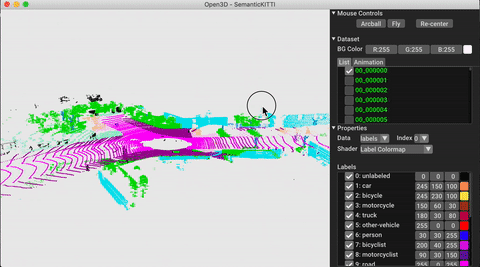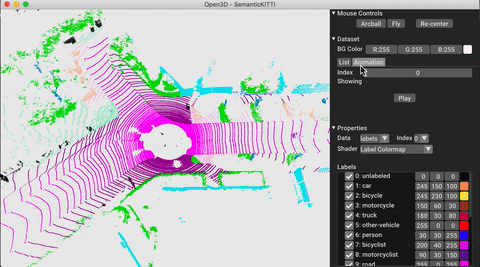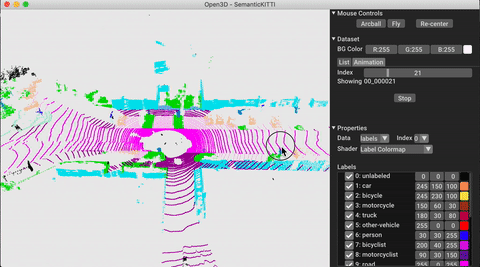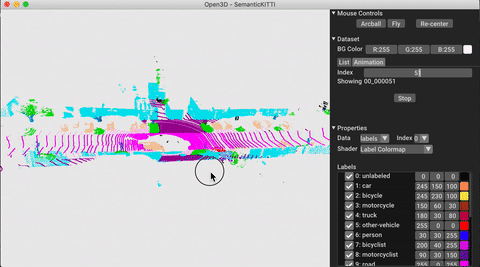
Конфигурации моделей, наборов данных и трубопроводов хранятся в ml3d/configs . Пользователи также могут построить свои собственные файлы YAML, чтобы вести записи своих настроенных конфигураций. Вот пример чтения файла конфигурации и построения модулей из него.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )Опираясь на предыдущий пример, мы можем создать создание трубопровода с предварительной моделью для семантической сегментации и запустить его в облаке точек нашего набора данных. См. Модель зоопарка для получения весов предварительно проведенной модели.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Пользователи также могут использовать предопределенные сценарии для загрузки предварительных весов и запуска тестирования.
Подобно выводу, трубопроводы предоставляют интерфейс для обучения модели на наборе данных.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train () Для получения дополнительных примеров см examples/ и scripts/ каталоги. Вы также можете включить сохранение учебных резюме в файле конфигурации и визуализировать наземную правду и результаты с помощью Tensorboard. Смотрите этот урок для деталей.
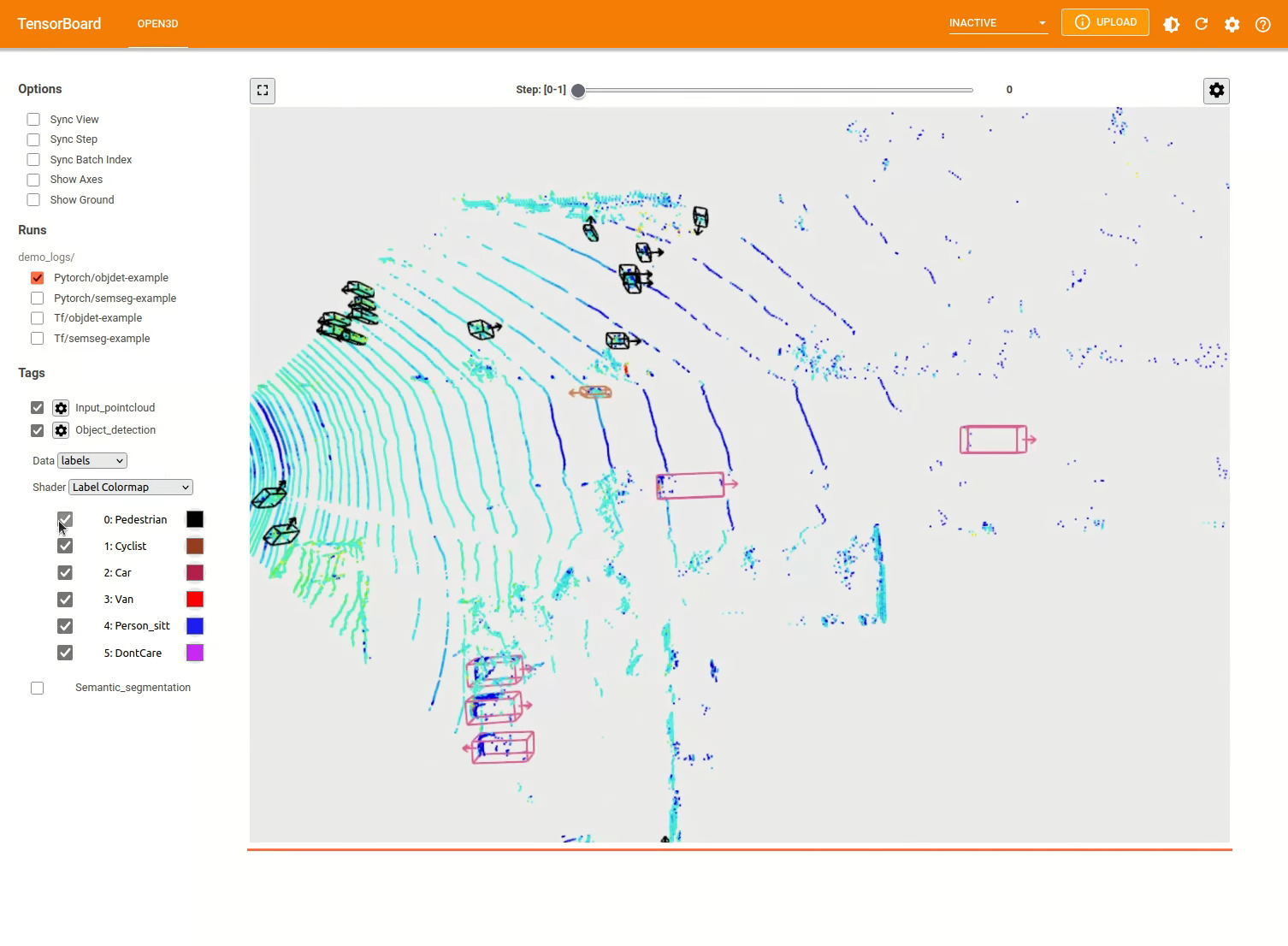
Модель обнаружения 3D объекта аналогична семантической сегментации модели. Мы можем создать создание трубопровода с предварительной моделью для обнаружения объектов и запустить его в облаке точек нашего набора данных. См. Модель зоопарка для получения весов предварительно проведенной модели.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Пользователи также могут использовать предопределенные сценарии для загрузки предварительных весов и запуска тестирования.
Подобно выводу, трубопроводы предоставляют интерфейс для обучения модели на наборе данных.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
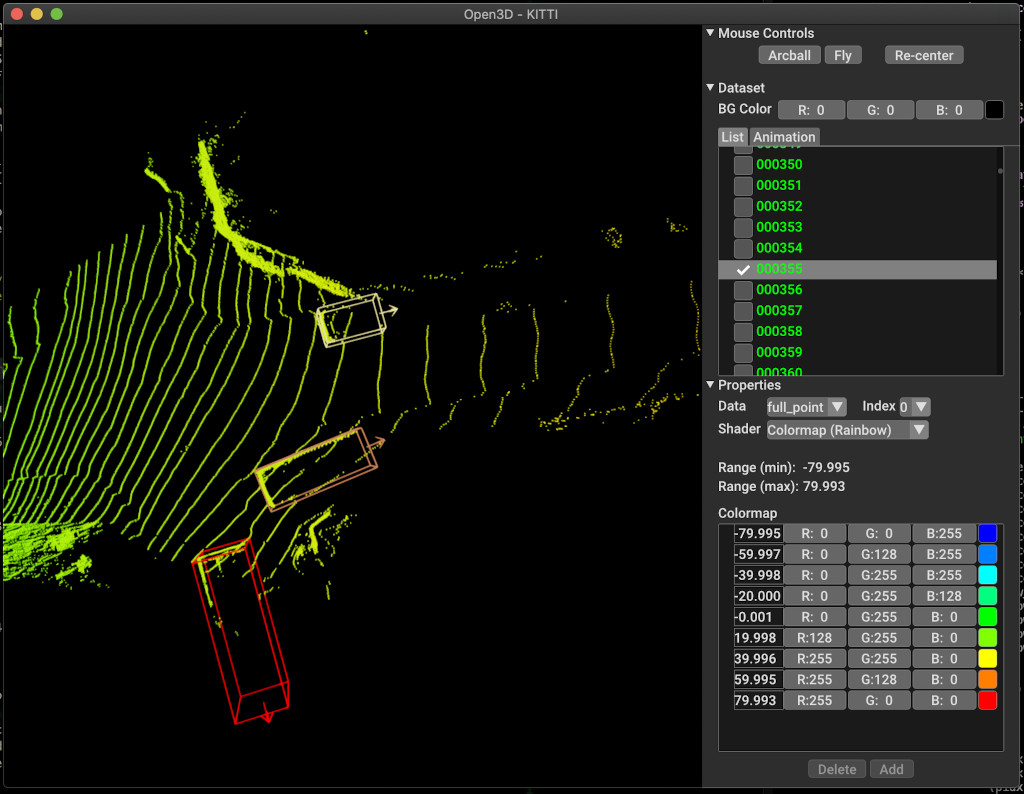
pipeline . run_train ()Ниже приведен пример визуализации с использованием Kitti. В примере показано использование ограничительных ящиков для набора данных Kitti.
Для получения дополнительных примеров см examples/ и scripts/ каталоги. Вы также можете включить сохранение учебных резюме в файле конфигурации и визуализировать наземную правду и результаты с помощью Tensorboard. Смотрите этот урок для деталей.
scripts/run_pipeline.py предоставляет простой интерфейс для обучения и оценки модели на наборе данных. Это сохраняет проблемы с определением конкретной модели и прохождения точной конфигурации.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Вы можете использовать скрипт как для семантической сегментации, так и для обнаружения объектов. Вы должны указать либо семантическую сегментацию, либо объектную передачу в параметре pipeline . Обратите внимание, что extra args будут приоритетными в том же параметре, присутствовавшем в файле конфигурации. Таким образом, вместо изменения параметра в файле конфигурации вы можете передать так же, как аргумент командной строки при запуске сценария.
Например.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Для получения дополнительной помощи запустите python scripts/run_pipeline.py --help .
Основная часть Open3D-ML живет в подпапке ml3d , которая интегрирована в Open3D в пространстве имен ml . В дополнение к основной части, examples каталогов и scripts предоставляют вспомогательные сценарии для начала работы с настройкой обучающего конвейера или запуска сети в наборе данных.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Для задачи семантической сегментации мы измеряем производительность различных методов с использованием среднего интерсекционного союза (MIO) по всем классам. В таблице показаны доступные модели и наборы данных для задачи сегментации и соответствующих результатов. Каждый счет ссылается на соответствующий веса.
| Модель / набор данных | Semantickitti | Торонто 3d | S3DIS | Semantic3d | Paris-Lille3d | Сканат |
|---|---|---|---|---|---|---|
| Randla-Net (TF) | 53,7 | 73,7 | 70,9 | 76.0 | 70,0* | - |
| Рандла-сеть (факел) | 52,8 | 74.0 | 70,9 | 76.0 | 70,0* | - |
| Kpconv (tf) | 58.7 | 65,6 | 65,0 | - | 76.7 | - |
| Kpconv (факел) | 58.0 | 65,6 | 60.0 | - | 76.7 | - |
| Sparseconvunet (факел) | - | - | - | - | - | 68 |
| Sparseconvunet (tf) | - | - | - | - | - | 68.2 |
| PointTransformer (Torch) | - | - | 69,2 | - | - | - |
| PointTransformer (TF) | - | - | 69,2 | - | - | - |
(*) Использование весов от оригинального автора.
Для задачи обнаружения объектов мы измеряем производительность различных методов, используя среднюю среднюю точность (MAP) для взгляда птичьего глаза (BEV) и 3D. В таблице показаны доступные модели и наборы данных для задачи обнаружения объекта и соответствующих результатов. Каждый счет ссылается на соответствующий веса. Для оценки модели были оценены с использованием подмножества валидации в соответствии с критериями проверки Китти. Модели были обучены для трех классов (автомобиль, пешеход и велосипедист). Расчетные значения являются средним значением по карте всех классов для всех уровней сложности. Для набора данных Waymo модели обучались трем классам (пешеход, транспортное средство, велосипедист).
| Модель / набор данных | Kitti [bev / 3d] @ 0,70 | Waymo (bev / 3d) @ 0,50 |
|---|---|---|
| Pointpillars (TF) | 61,6 / 55,2 | - |
| Pointpillars (факел) | 61.2 / 52,8 | AVG: 61.01 / 48.30 | Лучший: 61,47 / 57,55 [^WPP-Train] |
| Pointrcnn (tf) | 78,2 / 65,9 | - |
| Pointrcnn (torch) | 78,2 / 65,9 | - |
[^WPP-Train]: AVG. Метрики представляют собой среднее из трех наборов тренировочных прогонов с 4, 8, 16 и 32 графическими процессорами. Обучение было остановлено после 30 эпох. Контрольная точка модели доступна для лучшего обучения.
Чтобы использовать основную истинную выборку, чтобы увеличить данные для обучения, мы можем генерировать основную базу данных истины следующим образом:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Это генерирует базу данных, состоящую из объектов из разделения поезда. Рекомендуется использовать это увеличение для набора данных, такого как Kitti, где объекты редки.
Два этапа Pointrcnn обучаются отдельно. Чтобы обучить стадию генерации предложений Pointrcnn с Pytorch, запустите следующую команду:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
После получения хорошо обученной сети RPN мы можем обучить сеть RCNN с замороженными весами RPN.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Полный список всех файлов веса см. Model_weights.txt и файл контрольной системы MD5 Model_weights.md5.
Ниже приведен список наборов данных, для которых мы предоставляем классы считывателей наборов данных.
Для загрузки этих наборов данных посетите соответствующие веб -страницы и посмотрите на сценарии в scripts/download_datasets .
Есть много способов внести свой вклад в этот проект. Ты можешь:
Пожалуйста, сделайте свои запросы на привлечение в филиал Dev . Open3D - это усилия сообщества. Мы приветствуем и празднуем вклад сообщества!
Если вы хотите поделиться весами для обученной модели, прикрепите или свяжите файл веса в запросе. Для ошибок и проблем, откройте проблему. Пожалуйста, также ознакомьтесь с нашими каналами связи, чтобы связаться с сообществом.
Пожалуйста, цитируйте нашу работу (PDF), если вы используете Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

