Open3D ML
v0.18 release
Instalasi | Mulai | Struktur | Tugas & Algoritma | Model Zoo | Dataset | Bagaimana-ke-pos | Menyumbang
Open3D-ML adalah perpanjangan dari Open3D untuk tugas pembelajaran mesin 3D. Ini dibangun di atas Perpustakaan Inti Open3D dan memperluasnya dengan alat pembelajaran mesin untuk pemrosesan data 3D. Repo ini berfokus pada aplikasi seperti segmentasi cloud titik semantik dan menyediakan model pretrained yang dapat diterapkan pada tugas umum serta jaringan pipa untuk pelatihan.
Open3D-ML bekerja dengan TensorFlow dan Pytorch untuk mengintegrasikan dengan mudah ke dalam proyek yang ada dan juga menyediakan fungsionalitas umum terlepas dari kerangka kerja ML seperti visualisasi data.
Open3D-ML terintegrasi dalam distribusi Open3D V0.11+ Python dan kompatibel dengan versi-versi kerangka kerja ML berikut.
GNU/Linux x86_64 , opsional)Anda dapat menginstal Open3D dengan
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dUntuk menginstal versi Pytorch atau TensorFlow yang kompatibel, Anda dapat menggunakan file persyaratan masing -masing:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtUntuk menguji penggunaan instalasi
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Jika Anda perlu menggunakan versi berbeda dari kerangka kerja ML atau CUDA, kami sarankan untuk membangun Open3D dari sumber atau membangun Open3D di Docker.
Dari V0.18 dan seterusnya di Linux, roda PYPI Open3D tidak memiliki dukungan asli untuk TensorFlow karena membangun ketidakcocokan antara Pytorch dan TensorFlow [lihat Python 3.11 Dukungan PR] untuk detailnya. Jika Anda ingin menggunakan Open3D dengan TensorFlow di Linux, Anda dapat membangun roda Open3D dari sumber di Docker dengan dukungan untuk TensorFlow (tetapi bukan Pytorch) sebagai:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
./docker_build.sh cuda_wheel_py310Dataset namespace berisi kelas untuk membaca set data umum. Di sini kita membaca dataset Semantickitti dan memvisualisasikannya.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))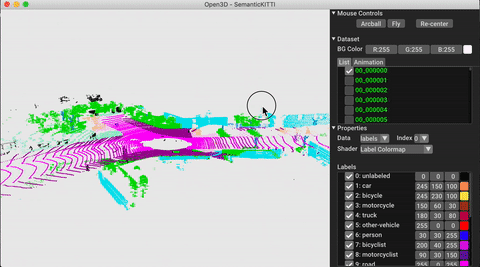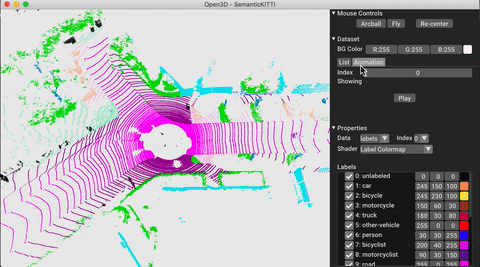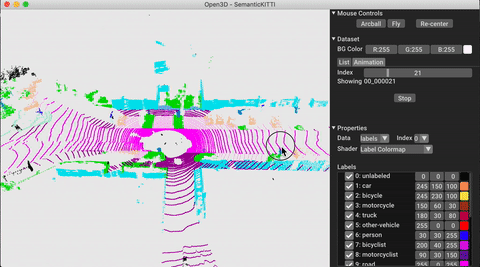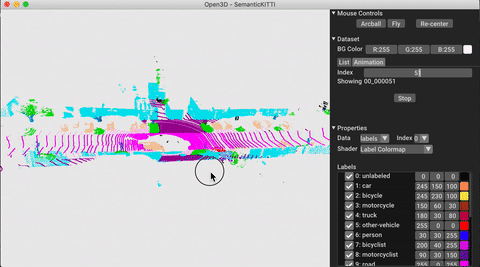
Konfigurasi model, kumpulan data, dan pipa disimpan dalam ml3d/configs . Pengguna juga dapat membuat file YAML mereka sendiri untuk mencatat konfigurasi yang disesuaikan. Berikut adalah contoh membaca file konfigurasi dan membangun modul darinya.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )Membangun pada contoh sebelumnya kita dapat membuat saluran pipa dengan model pretrained untuk segmentasi semantik dan menjalankannya pada awan titik dataset kita. Lihat Model Zoo untuk mendapatkan bobot model pretrained.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Pengguna juga dapat menggunakan skrip yang telah ditentukan untuk memuat bobot pretrained dan menjalankan pengujian.
Mirip dengan inferensi, jaringan pipa menyediakan antarmuka untuk melatih model pada dataset.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train () Untuk lebih banyak contoh, lihat examples/ dan scripts/ direktori. Anda juga dapat mengaktifkan ringkasan pelatihan menyimpan dalam file konfigurasi dan memvisualisasikan kebenaran ground dan hasil dengan Tensorboard. Lihat tutorial ini untuk detailnya.
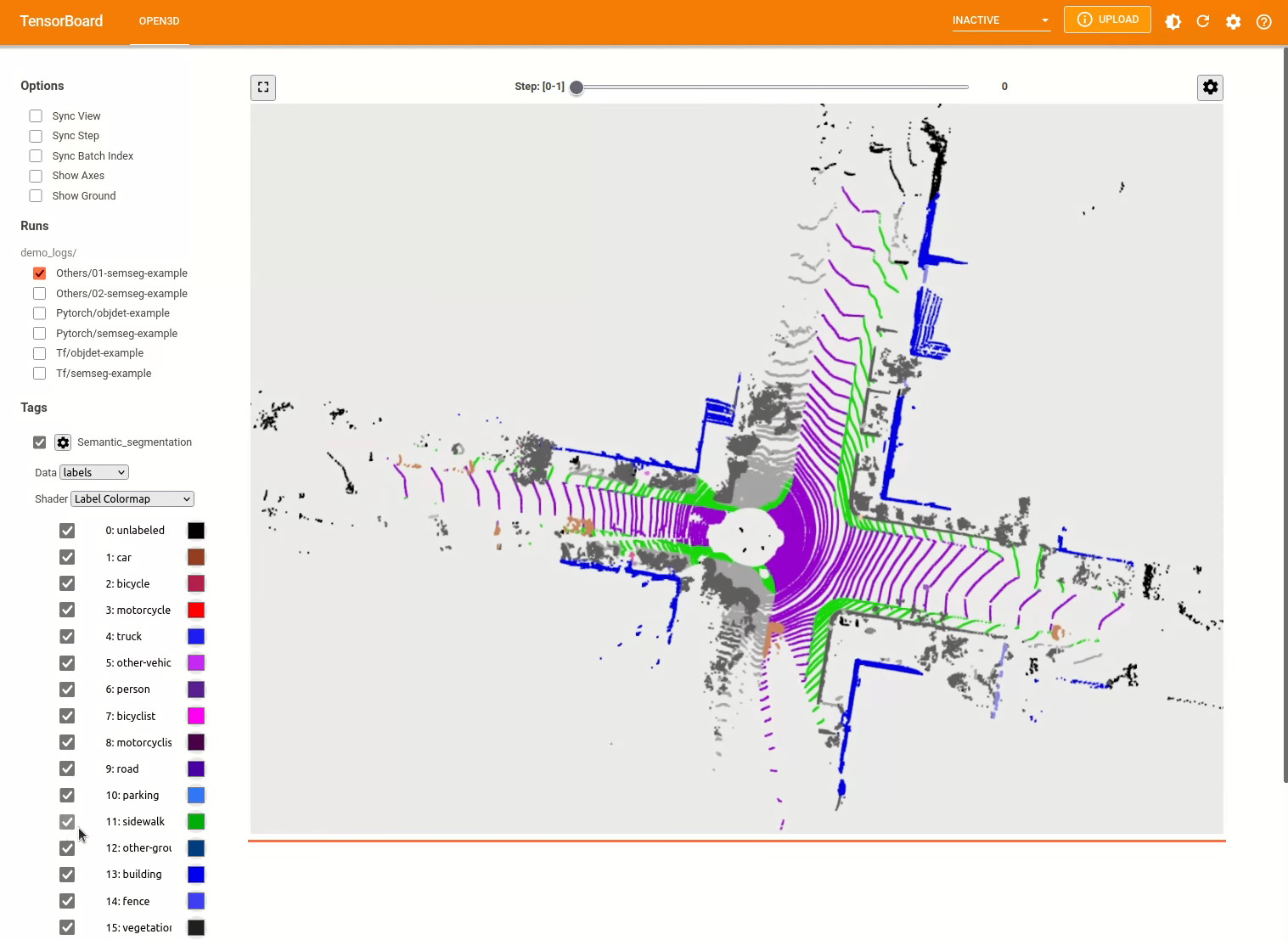
Model deteksi objek 3D mirip dengan model segmentasi semantik. Kami dapat membuat instantiasi pipa dengan model pretrained untuk deteksi objek dan menjalankannya pada awan titik dataset kami. Lihat Model Zoo untuk mendapatkan bobot model pretrained.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Pengguna juga dapat menggunakan skrip yang telah ditentukan untuk memuat bobot pretrained dan menjalankan pengujian.
Mirip dengan inferensi, jaringan pipa menyediakan antarmuka untuk melatih model pada dataset.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
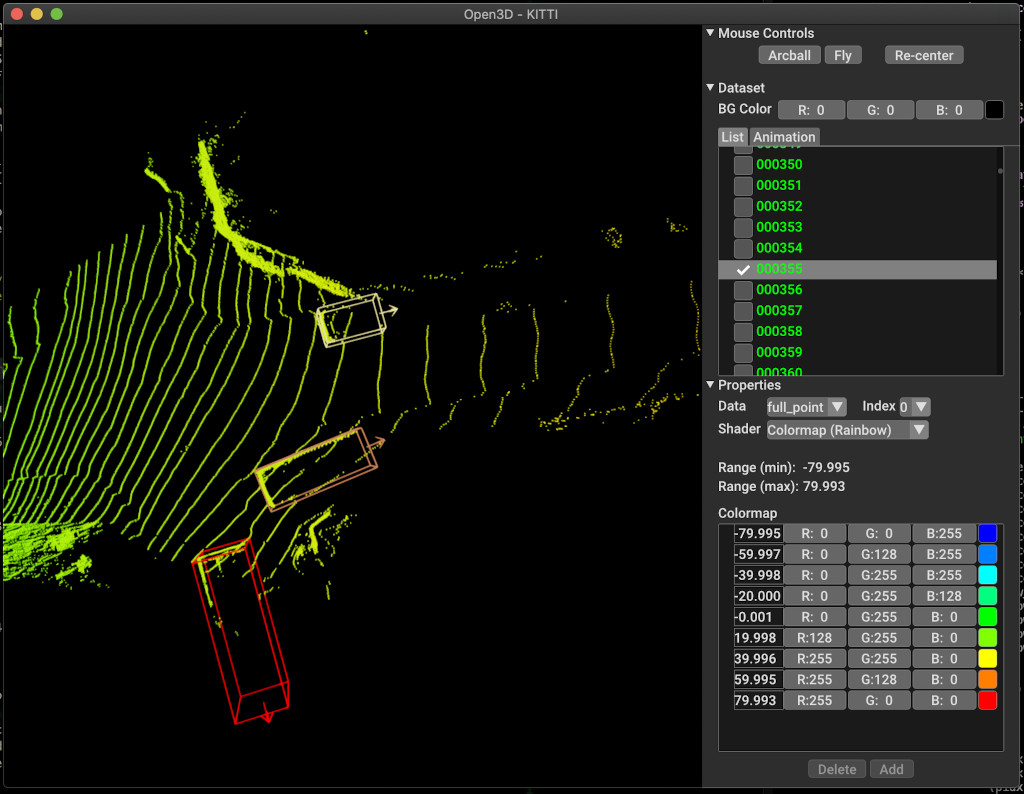
pipeline . run_train ()Di bawah ini adalah contoh visualisasi menggunakan kitti. Contohnya menunjukkan penggunaan kotak pembatas untuk dataset kitti.
Untuk lebih banyak contoh, lihat examples/ dan scripts/ direktori. Anda juga dapat mengaktifkan ringkasan pelatihan menyimpan dalam file konfigurasi dan memvisualisasikan kebenaran ground dan hasil dengan Tensorboard. Lihat tutorial ini untuk detailnya.
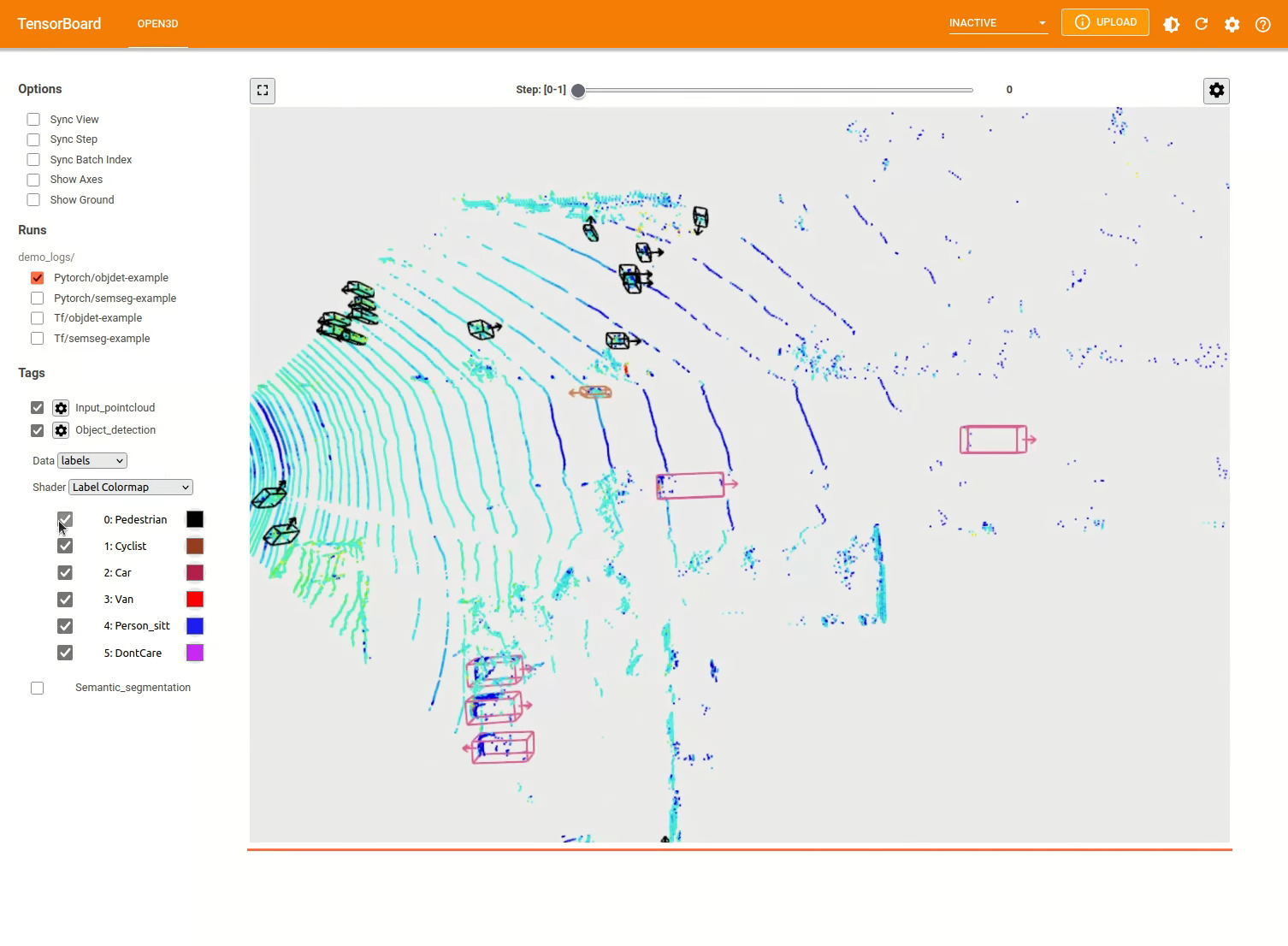
scripts/run_pipeline.py menyediakan antarmuka yang mudah untuk pelatihan dan mengevaluasi model pada dataset. Ini menghemat kesulitan mendefinisikan model spesifik dan memberikan konfigurasi yang tepat.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Anda dapat menggunakan skrip untuk segmentasi semantik dan deteksi objek. Anda harus menentukan baik semantik atau obyekteksi di parameter pipeline . Perhatikan bahwa extra args akan diprioritaskan daripada parameter yang sama yang ada dalam file konfigurasi. Jadi, alih -alih mengubah param dalam file konfigurasi, Anda dapat melewati hal yang sama dengan argumen baris perintah saat meluncurkan skrip.
Untuk misalnya.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Untuk bantuan lebih lanjut, jalankan python scripts/run_pipeline.py --help .
Bagian inti dari Open3D-ML tinggal di subfolder ml3d , yang diintegrasikan ke dalam Open3D di ml Namespace. Selain bagian inti, examples dan scripts direktori menyediakan skrip pendukung untuk memulai dengan menyiapkan pipa pelatihan atau menjalankan jaringan pada dataset.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Untuk tugas segmentasi semantik, kami mengukur kinerja berbagai metode menggunakan rata-rata persimpangan-over-union (MIOU) di semua kelas. Tabel menunjukkan model dan set data yang tersedia untuk tugas segmentasi dan skor masing -masing. Setiap tautan skor ke file berat masing -masing.
| Model / dataset | Semantickitti | Toronto 3d | S3dis | Semantik3d | Paris-lille3d | Scannet |
|---|---|---|---|---|---|---|
| Randla-net (TF) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0* | - |
| Randla-net (obor) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0* | - |
| KPCONV (TF) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| Kpconv (obor) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| SPARSECONVUNET (Torch) | - | - | - | - | - | 68 |
| SPARSECONVUNET (TF) | - | - | - | - | - | 68.2 |
| PointTransformer (obor) | - | - | 69.2 | - | - | - |
| PointTransformer (TF) | - | - | 69.2 | - | - | - |
(*) Menggunakan bobot dari penulis asli.
Untuk tugas deteksi objek, kami mengukur kinerja metode yang berbeda menggunakan presisi rata -rata rata -rata (MAP) untuk Bird's Eye View (BEV) dan 3D. Tabel menunjukkan model dan set data yang tersedia untuk tugas deteksi objek dan skor masing -masing. Setiap tautan skor ke file berat masing -masing. Untuk evaluasi, model dievaluasi menggunakan subset validasi, menurut kriteria validasi Kitti. Model dilatih untuk tiga kelas (mobil, pejalan kaki dan pengendara sepeda). Nilai yang dihitung adalah nilai rata -rata di atas peta semua kelas untuk semua tingkat kesulitan. Untuk dataset Waymo, model dilatih di tiga kelas (pejalan kaki, kendaraan, pengendara sepeda).
| Model / dataset | Kitti [bev / 3d] @ 0.70 | Waymo (Bev / 3d) @ 0.50 |
|---|---|---|
| Pointpillars (TF) | 61.6 / 55.2 | - |
| Pointpillars (obor) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | Terbaik: 61.47 / 57.55 [^WPP-Train] |
| Pointrcnn (TF) | 78.2 / 65.9 | - |
| Pointrcnn (obor) | 78.2 / 65.9 | - |
[^WPP-Train]: AVG. Metrik adalah rata -rata tiga set pelatihan berjalan dengan 4, 8, 16 dan 32 GPU. Pelatihan untuk dihentikan setelah 30 zaman. Model Checkpoint tersedia untuk menjalankan pelatihan terbaik.
Untuk menggunakan augmentasi data pengambilan sampel kebenaran ground untuk pelatihan, kami dapat menghasilkan database kebenaran tanah sebagai berikut:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Ini akan menghasilkan database yang terdiri dari objek dari split kereta. Disarankan untuk menggunakan augmentasi ini untuk dataset seperti kitti di mana objek jarang.
Dua tahap pointrcnn dilatih secara terpisah. Untuk melatih tahap generasi proposal pointrcnn dengan pytorch, jalankan perintah berikut:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
Setelah mendapatkan jaringan RPN yang terlatih dengan baik, kami dapat melatih jaringan RCNN dengan bobot RPN beku.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Untuk daftar lengkap semua file berat, lihat model_weights.txt dan file md5 checksum model_weights.md5.
Berikut ini adalah daftar set data yang kami berikan kelas pembaca dataset.
Untuk mengunduh kumpulan data ini, kunjungi halaman web masing -masing dan lihat skrip dalam scripts/download_datasets .
Ada banyak cara untuk berkontribusi pada proyek ini. Anda bisa:
Tolong, buat permintaan tarik Anda ke cabang dev . Open3D adalah upaya komunitas. Kami menyambut dan merayakan kontribusi dari komunitas!
Jika Anda ingin berbagi bobot untuk model yang Anda latih, silakan lampirkan atau tautkan file bobot dalam permintaan tarik. Untuk bug dan masalah, buka masalah. Harap lihat juga saluran komunikasi kami untuk menghubungi komunitas.
Harap kutip pekerjaan kami (PDF) jika Anda menggunakan Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

