Open3D ML
v0.18 release
Instalación | Empiece | Estructura | Tareas y algoritmos | Zoológico modelo | Conjuntos de datos | Cómo-Tos | Contribuir
Open3D-ML es una extensión de Open3D para tareas de aprendizaje automático 3D. Se basa en la parte superior de la biblioteca Core Open3D y la extiende con herramientas de aprendizaje automático para el procesamiento de datos 3D. Este repositorio se centra en aplicaciones como la segmentación de la nube de puntos semánticos y proporciona modelos previos a la aparición que pueden aplicarse a tareas comunes, así como tuberías para la capacitación.
Open3D-ML funciona con TensorFlow y Pytorch para integrarse fácilmente en los proyectos existentes y también proporciona una funcionalidad general independiente de los marcos ML, como la visualización de datos.
Open3D-ML está integrado en la distribución Open3D V0.11+ Python y es compatible con las siguientes versiones de los marcos ML.
GNU/Linux x86_64 , opcional)Puede instalar Open3D con
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dPara instalar una versión compatible de Pytorch o TensorFlow, puede usar los archivos de requisitos respectivos:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtPara probar el uso de la instalación
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Si necesita utilizar diferentes versiones de los marcos ML o CUDA, recomendamos construir Open3D desde la fuente o construir Open3D en Docker.
Desde V0.18 en adelante en Linux, la rueda PYPI Open3D no tiene soporte nativo para el flujo de tensor debido a incompatibilidades de construcción entre Pytorch y TensorFlow [ver Python 3.11 Support PR] para más detalles. Si desea usar Open3D con TensorFlow en Linux, puede construir la rueda Open3D desde la fuente en Docker con soporte para TensorFlow (pero no Pytorch) como:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
./docker_build.sh cuda_wheel_py310El espacio de nombres del conjunto de datos contiene clases para leer conjuntos de datos comunes. Aquí leemos el conjunto de datos Semantickitti y lo visualizamos.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))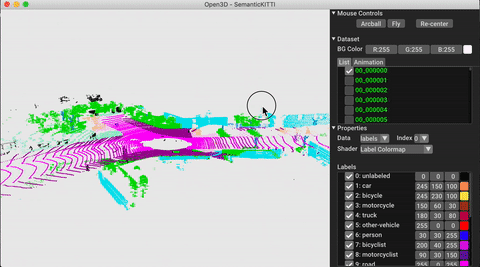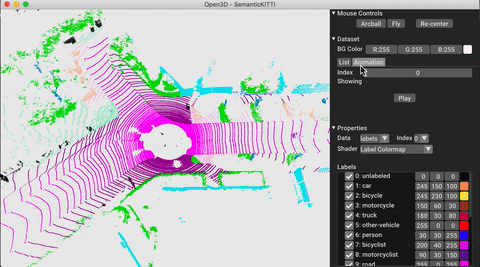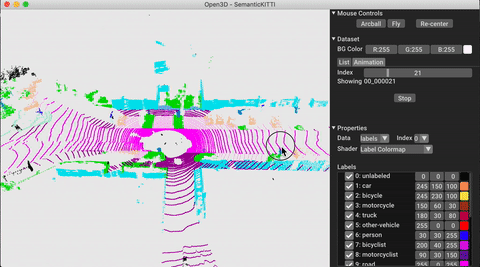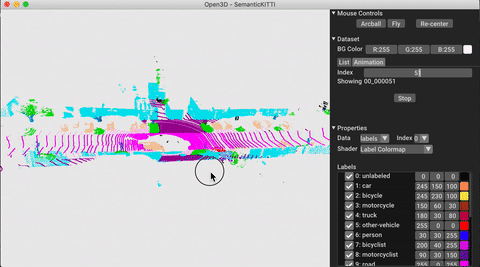
Las configuraciones de modelos, conjuntos de datos y tuberías se almacenan en ml3d/configs . Los usuarios también pueden construir sus propios archivos YAML para mantener el registro de sus configuraciones personalizadas. Aquí hay un ejemplo de leer un archivo de configuración y construir módulos a partir de él.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )Sobre la base del ejemplo anterior, podemos instanciar una tubería con un modelo previo a la segmentación semántica y ejecutarla en una nube de puntos de nuestro conjunto de datos. Consulte el zoológico del modelo para obtener los pesos del modelo previo a la aparición.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Los usuarios también pueden usar scripts predefinidos para cargar pesos previos a la aparición y ejecutar pruebas.
Similar a la inferencia, las tuberías proporcionan una interfaz para capacitar a un modelo en un conjunto de datos.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
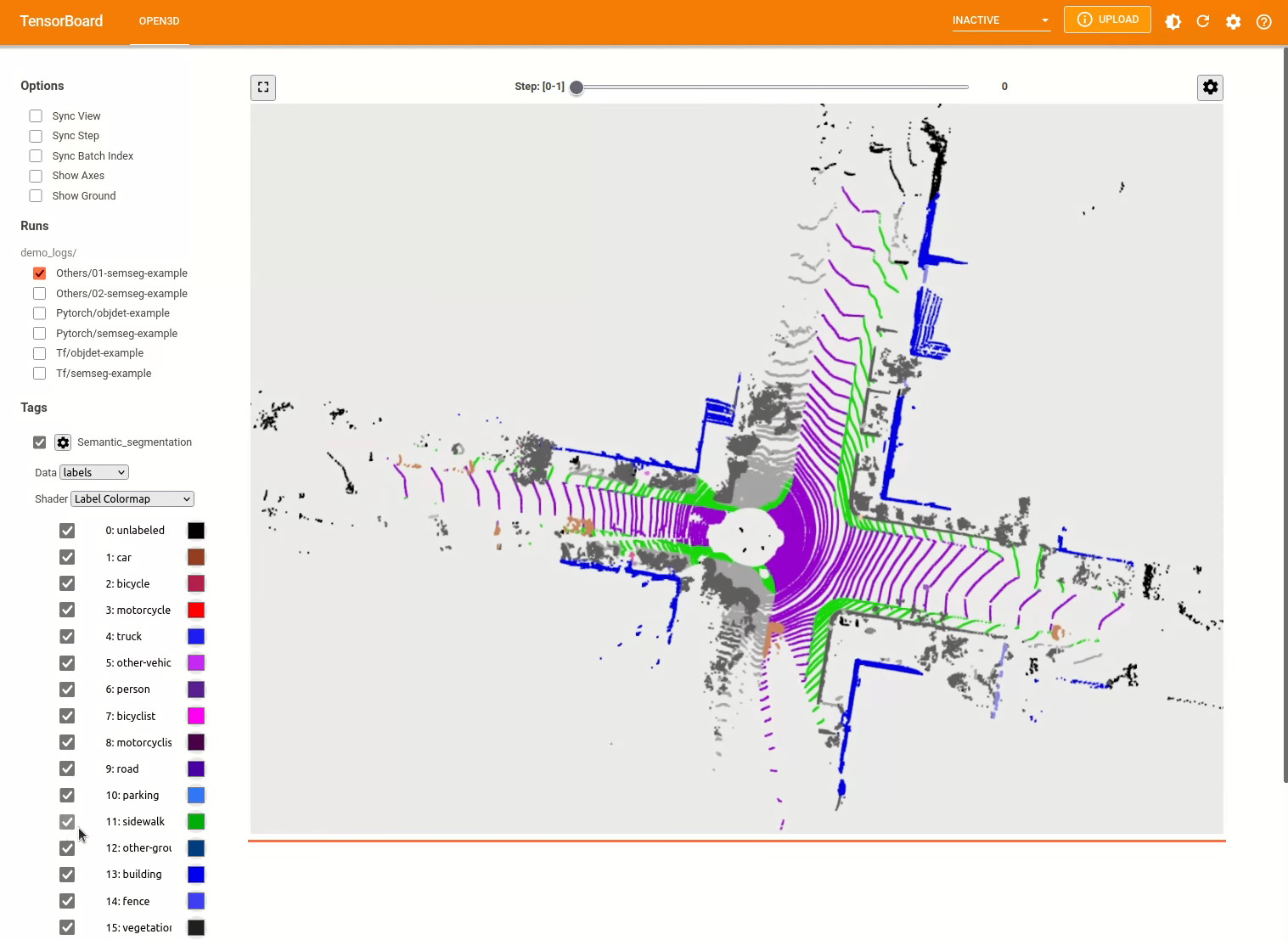
pipeline . run_train () Para más ejemplos, consulte examples/ y los scripts/ directorios. También puede habilitar los resúmenes de capacitación para guardar en el archivo de configuración y visualizar la verdad y los resultados de la tierra con TensorBoard. Vea este tutorial para más detalles.
El modelo de detección de objetos 3D es similar a un modelo de segmentación semántica. Podemos instanciar una tubería con un modelo previo a la detección de objetos y ejecutarla en una nube de puntos de nuestro conjunto de datos. Consulte el zoológico del modelo para obtener los pesos del modelo previo a la aparición.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Los usuarios también pueden usar scripts predefinidos para cargar pesos previos a la aparición y ejecutar pruebas.
Similar a la inferencia, las tuberías proporcionan una interfaz para capacitar a un modelo en un conjunto de datos.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
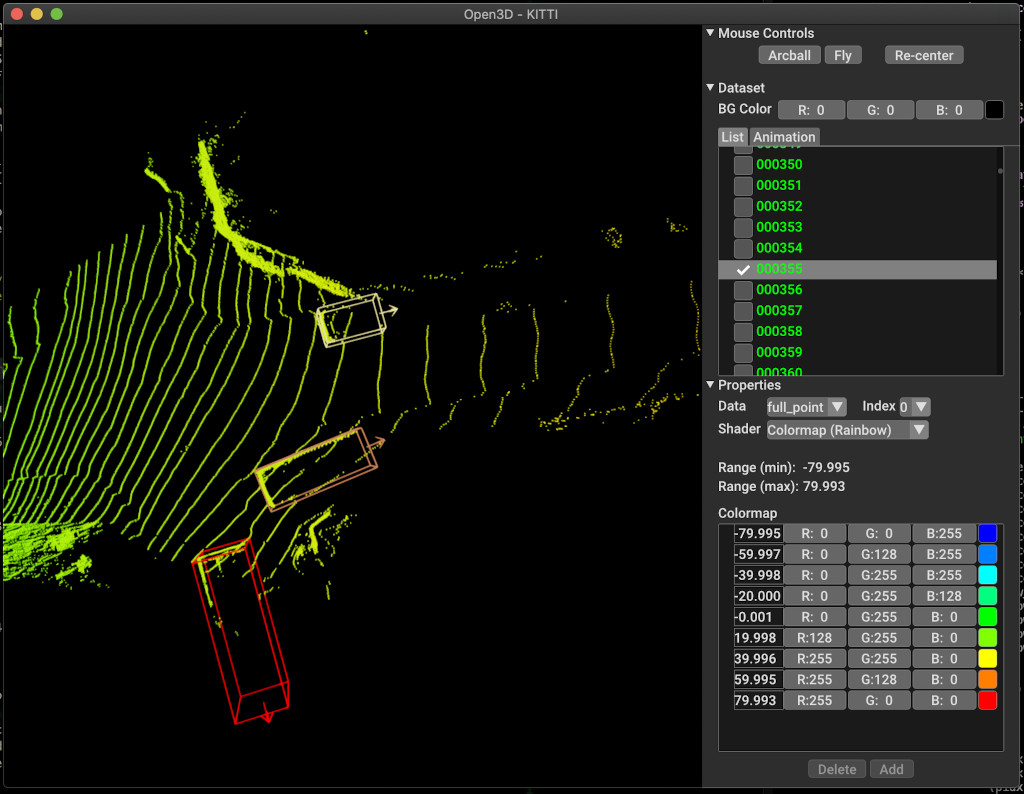
pipeline . run_train ()A continuación se muestra un ejemplo de visualización usando Kitti. El ejemplo muestra el uso de cuadros delimitadores para el conjunto de datos Kitti.
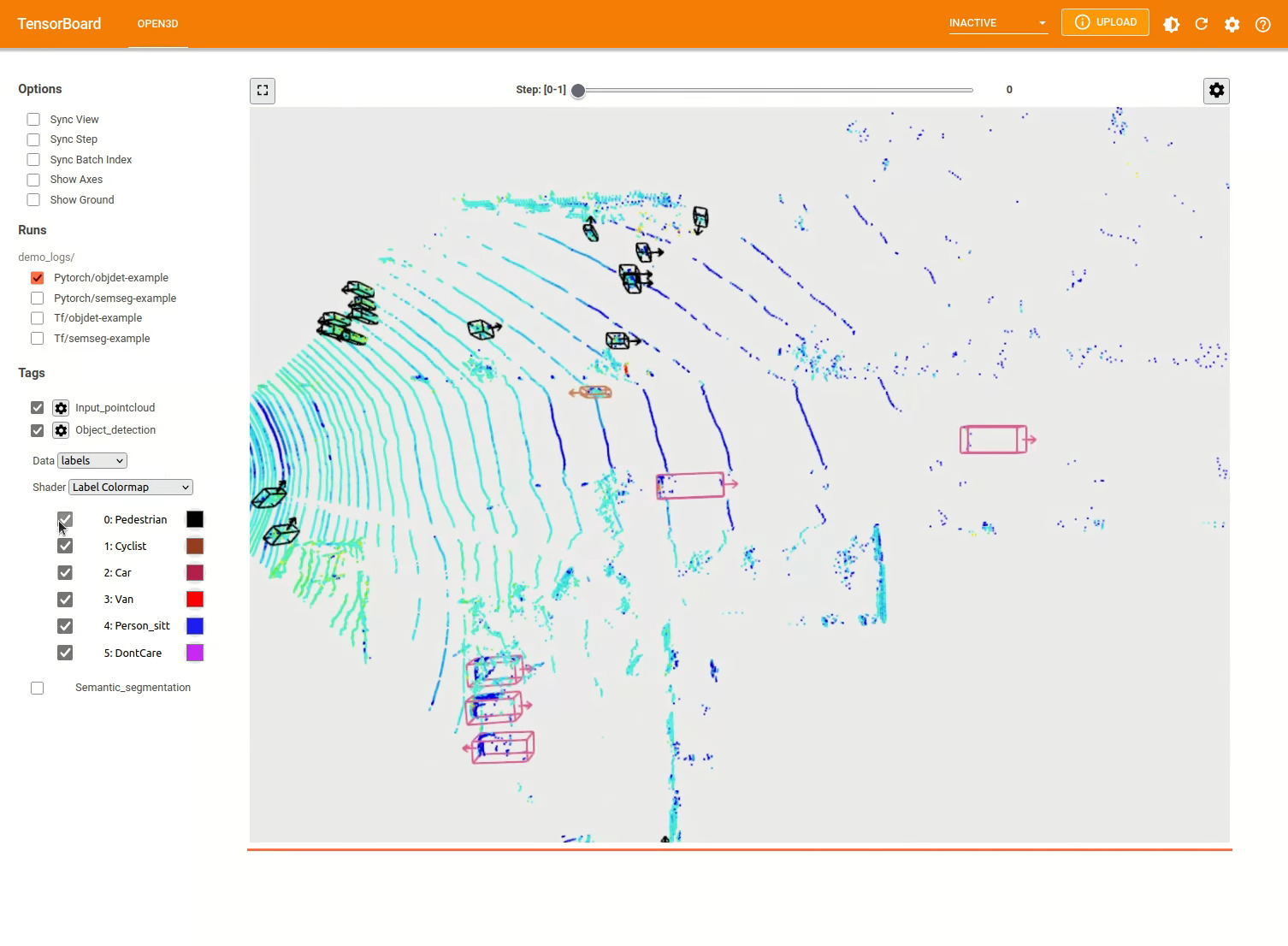
Para más ejemplos, consulte examples/ y los scripts/ directorios. También puede habilitar los resúmenes de capacitación para guardar en el archivo de configuración y visualizar la verdad y los resultados de la tierra con TensorBoard. Vea este tutorial para más detalles.
scripts/run_pipeline.py proporciona una interfaz fácil para capacitar y evaluar un modelo en un conjunto de datos. Guarda el problema de definir un modelo específico y pasar la configuración exacta.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Puede usar script para segmentación semántica y detección de objetos. Debe especificar semántico de Segmation o Object Detection en el parámetro pipeline . Tenga en cuenta que se priorizarán extra args sobre el mismo parámetro presente en el archivo de configuración. Entonces, en lugar de cambiar Param en el archivo de configuración, puede pasar lo mismo que un argumento de línea de comando al iniciar el script.
Para EG.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Para obtener más ayuda, ejecute python scripts/run_pipeline.py --help .
La parte central de Open3D-ML vive en la subcarpeta ml3d , que se integra en Open3D en el espacio de nombres ml . Además de la parte central, los examples de directorios y scripts proporcionan scripts de soporte para comenzar con la configuración de una tubería de capacitación o ejecutar una red en un conjunto de datos.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Para la tarea de segmentación semántica, medimos el rendimiento de diferentes métodos utilizando la intersección media sobre unión (MIOU) en todas las clases. La tabla muestra los modelos y conjuntos de datos disponibles para la tarea de segmentación y los puntajes respectivos. Cada puntaje se enlaza al archivo de peso respectivo.
| Modelo / conjunto | Semantickitti | Toronto 3D | S3dis | Semántico3D | Paris-lille3d | Escaneta |
|---|---|---|---|---|---|---|
| Randla-Net (TF) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0* | - |
| Randla-Net (antorcha) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0* | - |
| KPCONV (TF) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| KPConv (antorcha) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| Sparseconvunet (antorcha) | - | - | - | - | - | 68 |
| Sparseconvunet (TF) | - | - | - | - | - | 68.2 |
| PointTransformer (antorcha) | - | - | 69.2 | - | - | - |
| PointTransformer (TF) | - | - | 69.2 | - | - | - |
(*) Uso de pesas del autor original.
Para la tarea de detección de objetos, medimos el rendimiento de diferentes métodos utilizando la precisión promedio media (MAP) para la vista del ojo de las aves (BEV) y 3D. La tabla muestra los modelos y conjuntos de datos disponibles para la tarea de detección de objetos y los puntajes respectivos. Cada puntaje se enlaza al archivo de peso respectivo. Para la evaluación, los modelos se evaluaron utilizando el subconjunto de validación, de acuerdo con los criterios de validación de Kitti. Los modelos fueron entrenados para tres clases (automóvil, peatón y ciclista). Los valores calculados son el valor medio sobre el mapa de todas las clases para todos los niveles de dificultad. Para el conjunto de datos Waymo, los modelos fueron entrenados en tres clases (peatones, vehículos, ciclista).
| Modelo / conjunto | Kitti [bev / 3d] @ 0.70 | Waymo (bev / 3d) @ 0.50 |
|---|---|---|
| Pointpillars (TF) | 61.6 / 55.2 | - |
| Pointpillars (antorcha) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | Lo mejor: 61.47 / 57.55 [^WPP-Train] |
| Pointrcnn (TF) | 78.2 / 65.9 | - |
| Pointrcnn (antorcha) | 78.2 / 65.9 | - |
[^WPP-Train]: el avg. Las métricas son el promedio de tres conjuntos de carreras de entrenamiento con GPU 4, 8, 16 y 32. El entrenamiento fue detenido después de 30 épocas. El punto de control del modelo está disponible para la mejor ejecución de entrenamiento.
Para usar el aumento de datos de muestreo de la verdad en tierra para la capacitación, podemos generar la base de datos de la verdad de tierra de la siguiente manera:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Esto generará una base de datos que consiste en objetos de la división del tren. Se recomienda utilizar este aumento para un conjunto de datos como Kitti, donde los objetos son escasos.
Las dos etapas de Pointrcnn se entrenan por separado. Para capacitar la etapa de generación de propuestas de Pointrcnn con Pytorch, ejecute el siguiente comando:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
Después de obtener una red RPN bien entrenada, podemos entrenar la red RCNN con pesos RPN congelados.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Para obtener una lista completa de todos los archivos de peso, consulte model_weights.txt y el archivo MD5 CheckSum model_weights.md5.
La siguiente es una lista de conjuntos de datos para los que proporcionamos clases de lectores de conjuntos de datos.
Para descargar estos conjuntos de datos, visite las páginas web respectivas y eche un vistazo a los scripts en scripts/download_datasets .
Hay muchas formas de contribuir a este proyecto. Puede:
Por favor, haga sus solicitudes de extracción a la rama de desarrollo . Open3D es un esfuerzo comunitario. ¡Agradecemos y celebramos las contribuciones de la comunidad!
Si desea compartir pesas para un modelo que entrenó, adjunte o vincule el archivo de pesas en la solicitud de extracción. Para errores y problemas, abra un problema. También consulte nuestros canales de comunicación para ponerse en contacto con la comunidad.
Cite nuestro trabajo (PDF) si usa Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

