Open3D ML
v0.18 release
Instalação | Comece | Estrutura | Tarefas e algoritmos | Modelo ZOO | Conjuntos de dados | Como-tos | Contribuir
Open3D-ML é uma extensão do Open3D para tarefas de aprendizado de máquina 3D. Ele se baseia na parte superior da Biblioteca Core Open3D e a estende com ferramentas de aprendizado de máquina para o processamento de dados 3D. Esse repositório se concentra em aplicativos como a segmentação semântica de nuvem de pontos e fornece modelos pré -ridicularizados que podem ser aplicados a tarefas comuns, bem como a pipelines para treinamento.
O Open3D-ML funciona com o TensorFlow e o Pytorch para integrar-se facilmente aos projetos existentes e também fornece funcionalidade geral independente de estruturas de ML, como a visualização de dados.
O Open3D-ML é integrado na distribuição Open3D V0.11+ Python e é compatível com as seguintes versões do ML Frameworks.
GNU/Linux x86_64 , opcional)Você pode instalar o Open3D com
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dPara instalar uma versão compatível de Pytorch ou TensorFlow, você pode usar os respectivos arquivos de requisitos:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtPara testar o uso da instalação
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Se você precisar usar versões diferentes das estruturas ML ou CUDA, recomendamos criar o Open3D a partir da fonte ou criar o Open3D no Docker.
A partir da v0.18 em diante no Linux, a roda PYPI Open3D não possui suporte nativo ao Tensorflow devido à construção de incompatibilidades entre Pytorch e Tensorflow [consulte o Python 3.11 Suporte PR] para obter detalhes. Se você deseja usar o Open3D com o TensorFlow no Linux, poderá criar roda aberta a partir da fonte no Docker com suporte para Tensorflow (mas não Pytorch) como:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
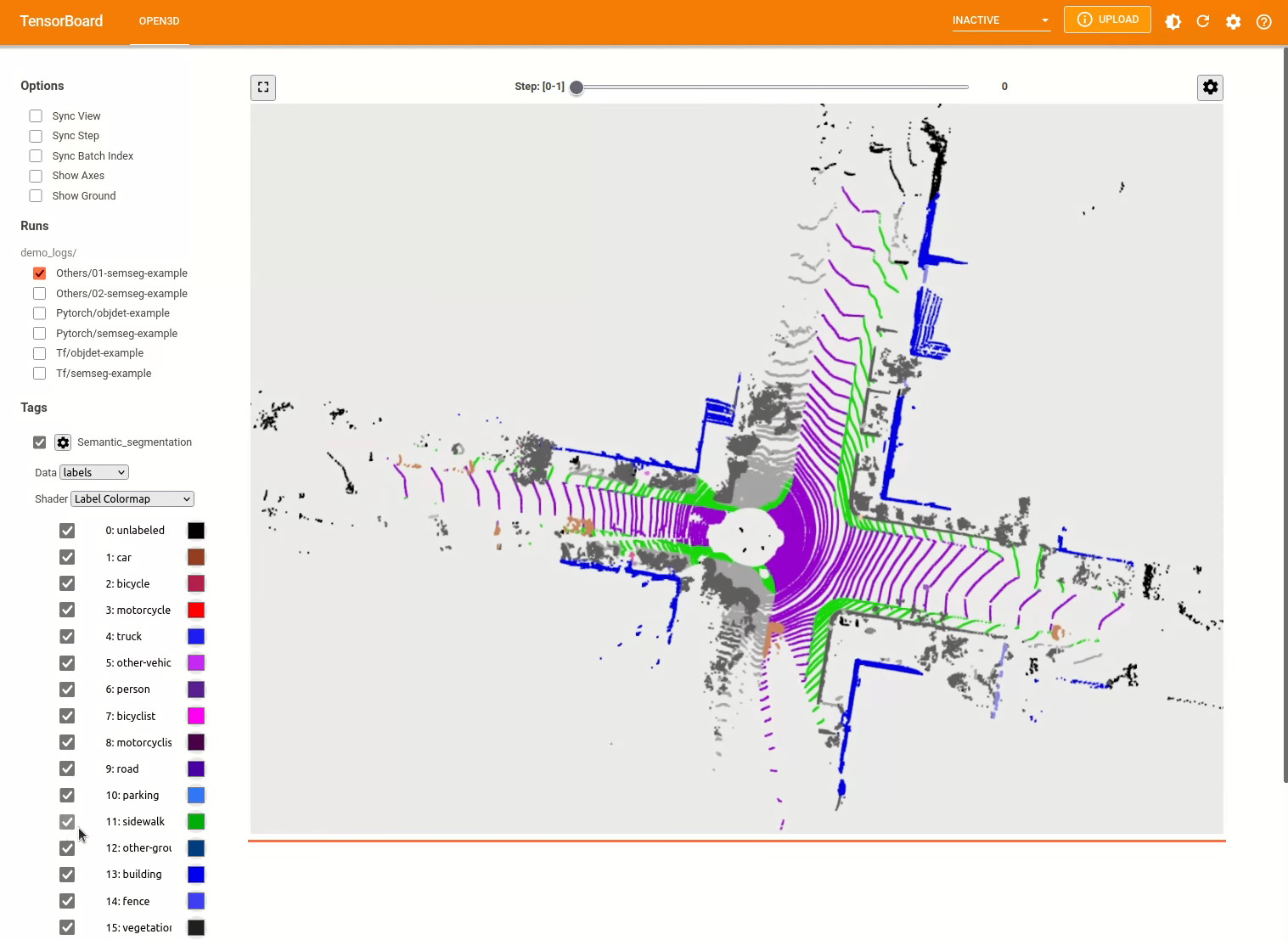
./docker_build.sh cuda_wheel_py310O espaço para nome do conjunto de dados contém classes para ler conjuntos de dados comuns. Aqui lemos o conjunto de dados semantickitti e o visualizamos.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))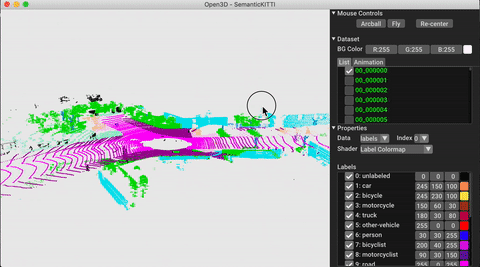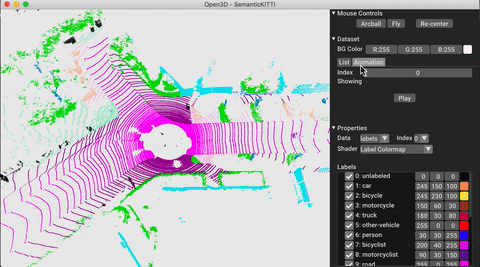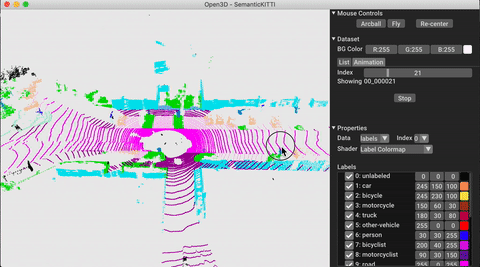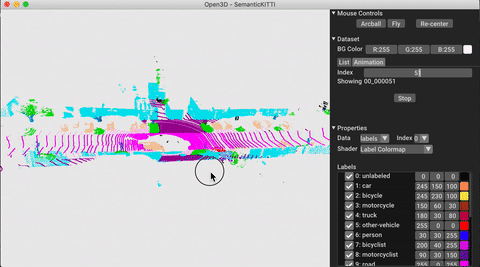
As configurações de modelos, conjuntos de dados e pipelines são armazenados em ml3d/configs . Os usuários também podem construir seus próprios arquivos YAML para manter o registro de suas configurações personalizadas. Aqui está um exemplo de leitura de um arquivo de configuração e construção de módulos a partir dele.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )Com base no exemplo anterior, podemos instanciar um oleoduto com um modelo pré -treinado para segmentação semântica e executá -lo em uma nuvem de pontos do nosso conjunto de dados. Consulte o zoológico do modelo para obter os pesos do modelo pré -treinado.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Os usuários também podem usar scripts predefinidos para carregar pesos pré -gravados e executar testes.
Semelhante ao inferência, os pipelines fornecem uma interface para treinar um modelo em um conjunto de dados.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train () Para mais exemplos, consulte examples/ e os scripts/ diretórios. Você também pode permitir a economia de resumos de treinamento no arquivo de configuração e visualize a verdade e os resultados do Tensorboard. Veja este tutorial para obter detalhes.
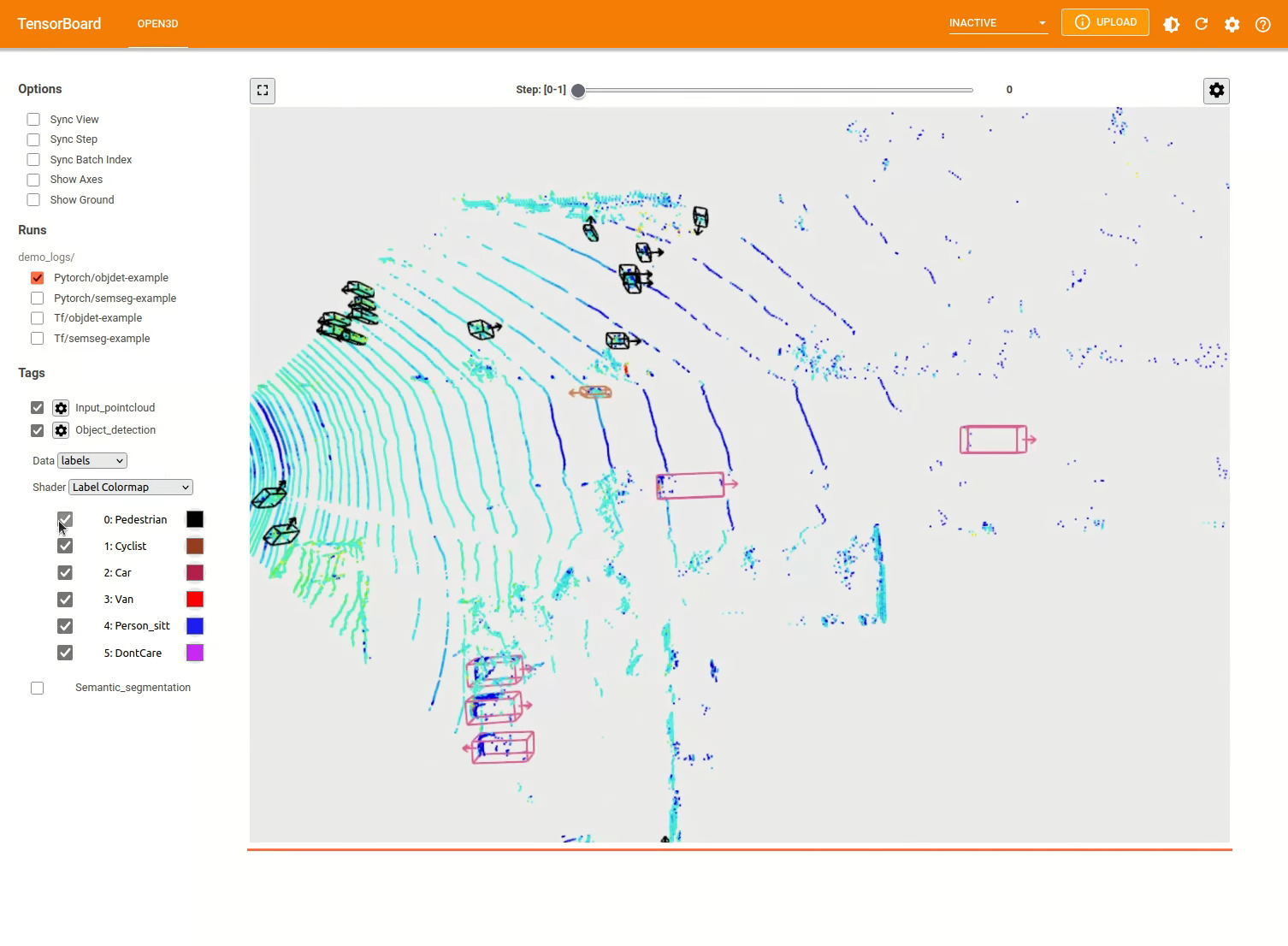
O modelo de detecção de objetos 3D é semelhante a um modelo de segmentação semântica. Podemos instanciar um pipeline com um modelo pré -traido para detecção de objetos e executá -lo em uma nuvem de pontos do nosso conjunto de dados. Consulte o zoológico do modelo para obter os pesos do modelo pré -treinado.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Os usuários também podem usar scripts predefinidos para carregar pesos pré -gravados e executar testes.
Semelhante ao inferência, os pipelines fornecem uma interface para treinar um modelo em um conjunto de dados.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
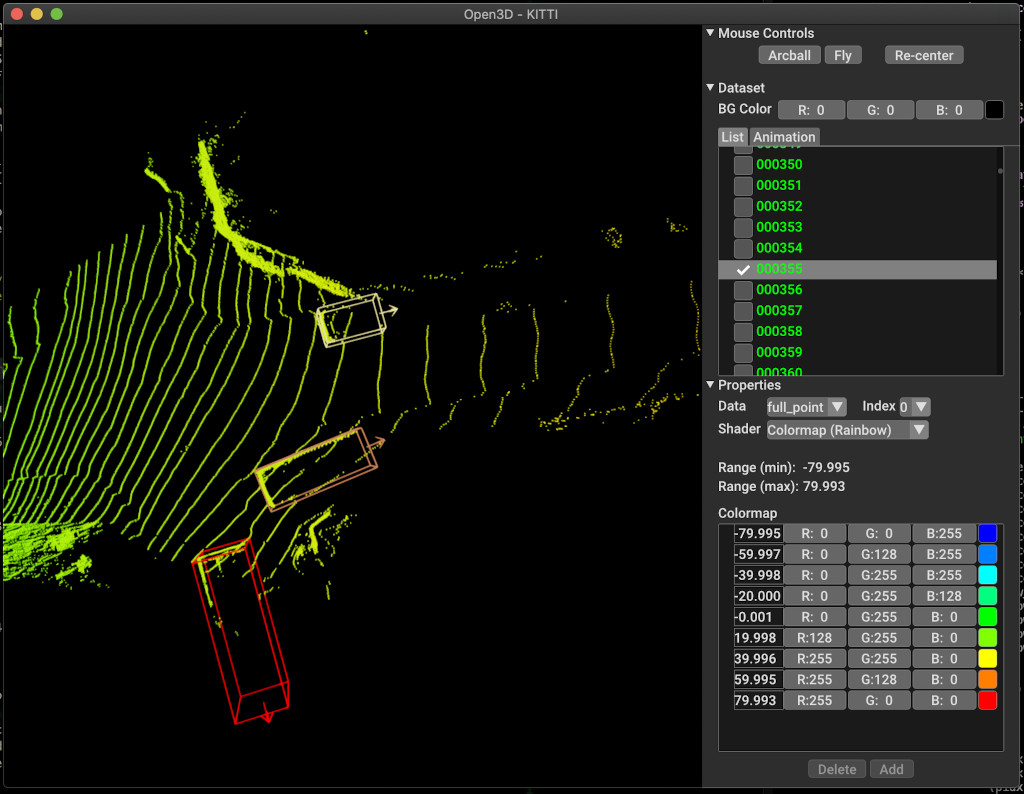
pipeline . run_train ()Abaixo está um exemplo de visualização usando Kitti. O exemplo mostra o uso de caixas delimitadoras para o conjunto de dados Kitti.
Para mais exemplos, consulte examples/ e os scripts/ diretórios. Você também pode permitir a economia de resumos de treinamento no arquivo de configuração e visualize a verdade e os resultados do Tensorboard. Veja este tutorial para obter detalhes.
scripts/run_pipeline.py fornece uma interface fácil para treinamento e avaliação de um modelo em um conjunto de dados. Ele economiza o problema de definir o modelo específico e passar a configuração exata.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Você pode usar o script para segmentação semântica e detecção de objetos. Você deve especificar semanticação ou detecção de objeto no parâmetro pipeline . Observe que o extra args será priorizado sobre o mesmo parâmetro presente no arquivo de configuração. Portanto, em vez de alterar o param no arquivo de configuração, você pode passar o mesmo que um argumento da linha de comando ao iniciar o script.
Para por exemplo.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Para obter mais ajuda, execute python scripts/run_pipeline.py --help .
A parte central do Open3D-ML vive na subpasta ml3d , que é integrada ao Open3D no espaço de nome ml . Além da parte principal, os examples e scripts de diretórios fornecem scripts de suporte para começar a configurar um pipeline de treinamento ou executar uma rede em um conjunto de dados.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Para a tarefa da segmentação semântica, medimos o desempenho de diferentes métodos usando a média de interseção e união (MIOU) em todas as classes. A tabela mostra os modelos e conjuntos de dados disponíveis para a tarefa de segmentação e as respectivas pontuações. Cada pontuação links para o respectivo arquivo de peso.
| Modelo / conjunto de dados | Semantickitti | Toronto 3D | S3dis | Semântico3d | Paris-Lille3d | Scannet |
|---|---|---|---|---|---|---|
| Randla-Net (TF) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0* | - |
| Randla-Net (tocha) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0* | - |
| KPCONV (TF) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| KPConv (tocha) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| SparsEconvunet (tocha) | - | - | - | - | - | 68 |
| SparsEconvunet (TF) | - | - | - | - | - | 68.2 |
| PointTransformer (tocha) | - | - | 69.2 | - | - | - |
| PointTransformer (TF) | - | - | 69.2 | - | - | - |
(*) Usando pesos do autor original.
Para a tarefa de detecção de objetos, medimos o desempenho de diferentes métodos usando a precisão média média (MAP) para a vista para os olhos do pássaro (BEV) e 3D. A tabela mostra os modelos e conjuntos de dados disponíveis para a tarefa de detecção de objetos e as respectivas pontuações. Cada pontuação links para o respectivo arquivo de peso. Para a avaliação, os modelos foram avaliados usando o subconjunto de validação, de acordo com os critérios de validação de Kitti. Os modelos foram treinados para três classes (carro, pedestre e ciclista). Os valores calculados são o valor médio sobre o mapa de todas as classes para todos os níveis de dificuldade. Para o conjunto de dados Waymo, os modelos foram treinados em três classes (pedestres, veículo, ciclista).
| Modelo / conjunto de dados | Kitti [bev / 3d] @ 0,70 | Waymo (bev / 3d) @ 0.50 |
|---|---|---|
| Pointpillars (TF) | 61.6 / 55.2 | - |
| Pointpillars (tocha) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | Melhor: 61.47 / 57.55 [^wpp-train] |
| Pointrcnn (TF) | 78.2 / 65.9 | - |
| Pointrcnn (tocha) | 78.2 / 65.9 | - |
[^wpp-train]: o avg. As métricas são a média de três conjuntos de treinamento com 4, 8, 16 e 32 GPUs. O treinamento foi interrompido após 30 épocas. O ponto de verificação do modelo está disponível para a melhor execução de treinamento.
Para usar o aumento de dados de amostragem da verdade no solo para treinamento, podemos gerar o banco de dados do Ground Truth da seguinte maneira:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Isso gerará um banco de dados que consiste em objetos da divisão do trem. Recomenda -se usar esse aumento no conjunto de dados como Kitti, onde os objetos são escassos.
Os dois estágios do pointrcnn são treinados separadamente. Para treinar o estágio de geração da proposta de Pointrcnn com Pytorch, execute o seguinte comando:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
Depois de obter uma rede RPN bem treinada, podemos treinar a rede RCNN com pesos de RPN congelados.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Para uma lista completa de todos os arquivos de peso, consulte Model_weights.txt e o arquivo de soma de verificação MD5 Model_weights.md5.
A seguir, é apresentada uma lista de conjuntos de dados para os quais fornecemos classes de leitores de conjunto de dados.
Para baixar esses conjuntos de dados, visite as respectivas páginas da web e dê uma olhada nos scripts nos scripts/download_datasets .
Existem muitas maneiras de contribuir para este projeto. Você pode:
Por favor, faça suas solicitações de tração para a filial do Dev . Open3D é um esforço da comunidade. Congratulamo -nos com e celebramos contribuições da comunidade!
Se você deseja compartilhar pesos para um modelo que você treinou, anexe ou vincule o arquivo de pesos na solicitação de tração. Para insetos e problemas, abra um problema. Confira também nossos canais de comunicação para entrar em contato com a comunidade.
Cite nosso trabalho (PDF) se você usar o Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

