Open3D ML
v0.18 release
Installation | Fangen Sie an | Struktur | Aufgaben & Algorithmen | Modellzoo | Datensätze | How-tos | Beitragen
Open3D-ML ist eine Erweiterung von Open3D für 3D-Aufgaben für maschinelles Lernen. Es baut auf der Open3D -Kernbibliothek auf und erweitert es mit Tools für maschinelles Lernen für die 3D -Datenverarbeitung. Dieses Repo konzentriert sich auf Anwendungen wie Semantic Point Cloud -Segmentierung und bietet vorbereitete Modelle, die auf gemeinsame Aufgaben sowie auf Pipelines für das Training angewendet werden können.
Open3D-ML arbeitet mit TensorFlow und Pytorch zusammen, um sich problemlos in vorhandene Projekte zu integrieren, und bietet auch allgemeine Funktionen, die unabhängig von ML-Frameworks wie der Datenvisualisierung sind.
Open3D-ML ist in die Open3D V0.11+ Python-Verteilung integriert und ist mit den folgenden Versionen von ML-Frameworks kompatibel.
GNU/Linux x86_64 , optional)Sie können Open3D mit installieren
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dUm eine kompatible Version von Pytorch oder TensorFlow zu installieren, können Sie die jeweiligen Anforderungen Dateien verwenden:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtUm die Installation zu testen
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Wenn Sie verschiedene Versionen der ML -Frameworks oder CUDA verwenden müssen, empfehlen wir, Open3D aus Source zu erstellen oder Open3D in Docker zu erstellen.
Ab V0.18 unter Linux bietet das PYPI Open3D -Rad keine native Unterstützung für Tensorflow, da in Inkompatibilitäten zwischen Pytorch und Tensorflow [siehe Python 3.11 -Support PR] für Einzelheiten aufgebaut werden. Wenn Sie Open3D mit TensorFlow auf Linux verwenden möchten, können Sie Open3D Wheel von Source in Docker mit Unterstützung für TensorFlow (aber nicht pytorch) erstellen wie:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
./docker_build.sh cuda_wheel_py310Der Dataset -Namespace enthält Klassen zum Lesen gemeinsamer Datensätze. Hier lesen wir den Semantickitti -Datensatz und visualisieren ihn.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))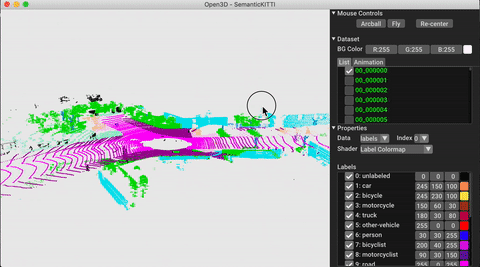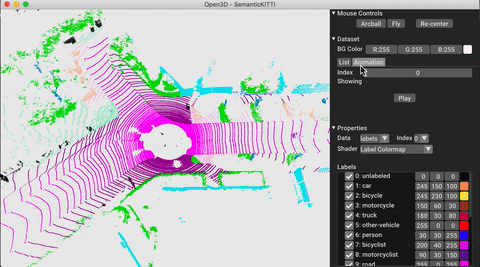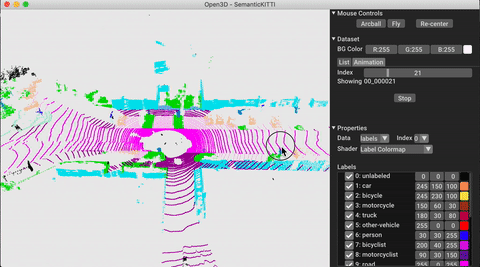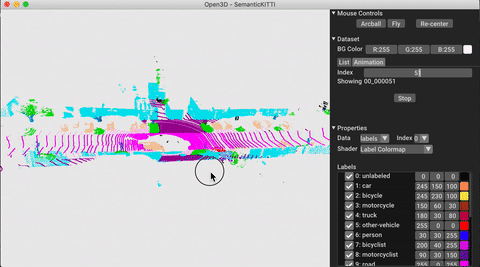
Konfigurationen von Modellen, Datensätzen und Pipelines werden in ml3d/configs gespeichert. Benutzer können auch ihre eigenen YAML -Dateien erstellen, um ihre angepassten Konfigurationen aufzuzeichnen. Hier ist ein Beispiel für das Lesen einer Konfigurationsdatei und das Erstellen von Modulen daraus.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )Aufbauend auf dem vorherigen Beispiel können wir eine Pipeline mit einem vorbereiteten Modell für die semantische Segmentierung instanziieren und in einer Punktwolke unseres Datensatzes ausführen. Siehe den Modellzoo, um die Gewichte des vorbereiteten Modells zu erhalten.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Benutzer können auch vordefinierte Skripte verwenden, um vorgezogene Gewichte zu laden und Tests auszuführen.
Ähnlich wie bei Inferenz bieten Pipelines eine Schnittstelle für das Training eines Modells auf einem Datensatz.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train () Weitere Beispiele finden Sie examples/ und die scripts/ Verzeichnisse. Sie können auch das Speichern von Trainingszusammenfassungen in der Konfigurationsdatei ermöglichen und die Grundwahrheit und die Ergebnisse mit Tensorboard visualisieren. Weitere Informationen finden Sie in diesem Tutorial.
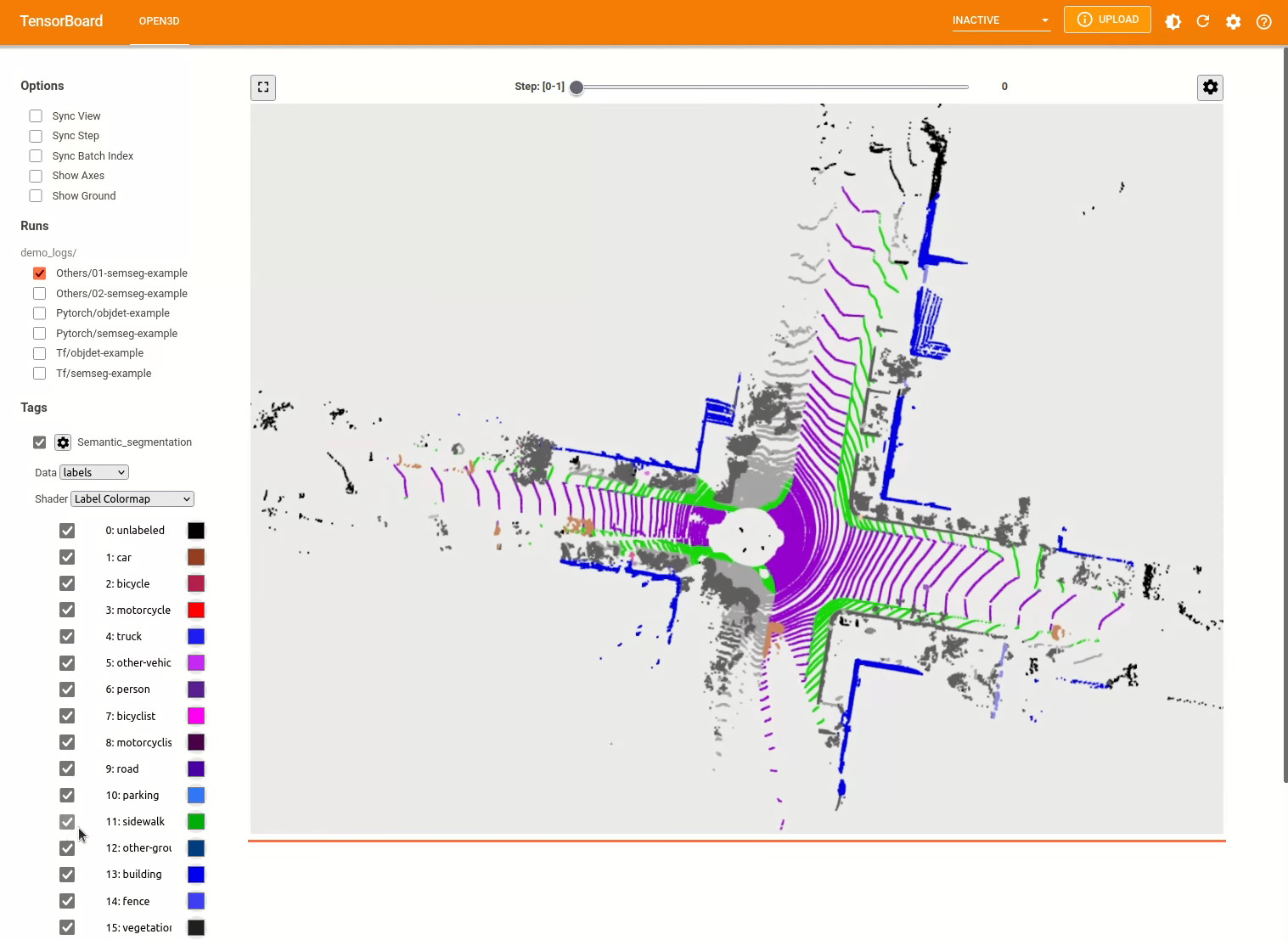
Das 3D -Objekterkennungsmodell ähnelt einem semantischen Segmentierungsmodell. Wir können eine Pipeline mit einem vorgezogenen Modell zur Objekterkennung instanziieren und in einer Punktwolke unseres Datensatzes ausführen. Siehe den Modellzoo, um die Gewichte des vorbereiteten Modells zu erhalten.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Benutzer können auch vordefinierte Skripte verwenden, um vorgezogene Gewichte zu laden und Tests auszuführen.
Ähnlich wie bei Inferenz bieten Pipelines eine Schnittstelle für das Training eines Modells auf einem Datensatz.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train ()Nachfolgend finden Sie ein Beispiel für die Visualisierung mit Kitti. Das Beispiel zeigt die Verwendung von Begrenzungsboxen für den Kitti -Datensatz.
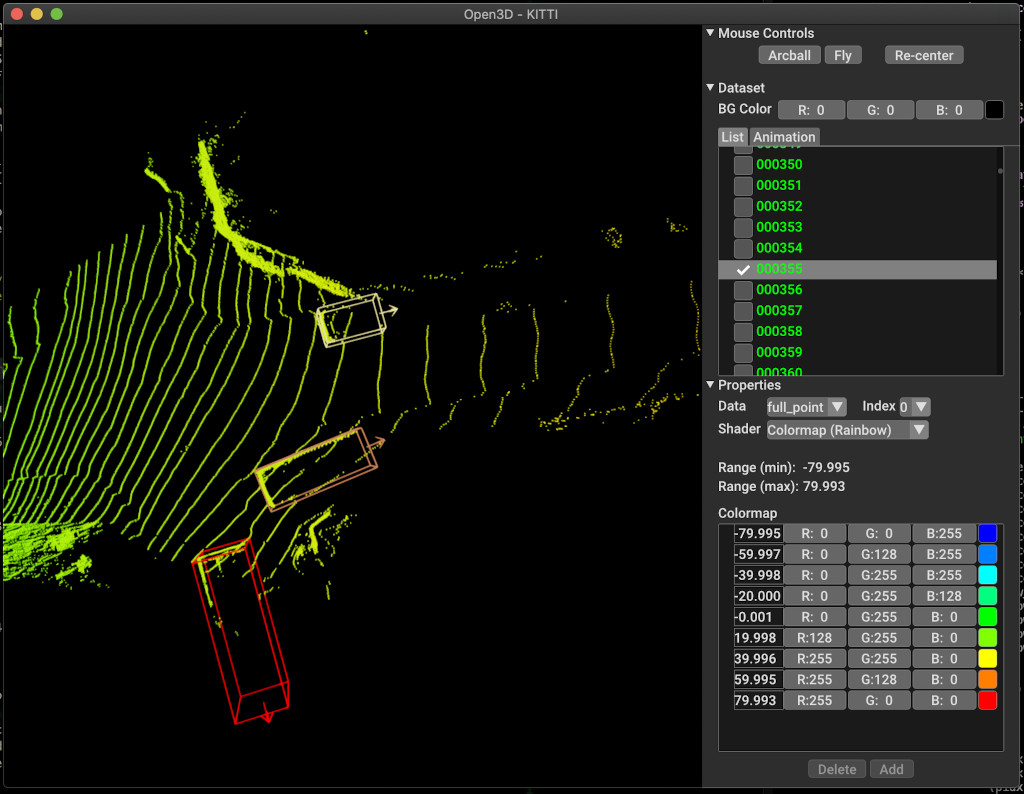
Weitere Beispiele finden Sie examples/ und die scripts/ Verzeichnisse. Sie können auch das Speichern von Trainingszusammenfassungen in der Konfigurationsdatei ermöglichen und die Grundwahrheit und die Ergebnisse mit Tensorboard visualisieren. Weitere Informationen finden Sie in diesem Tutorial.
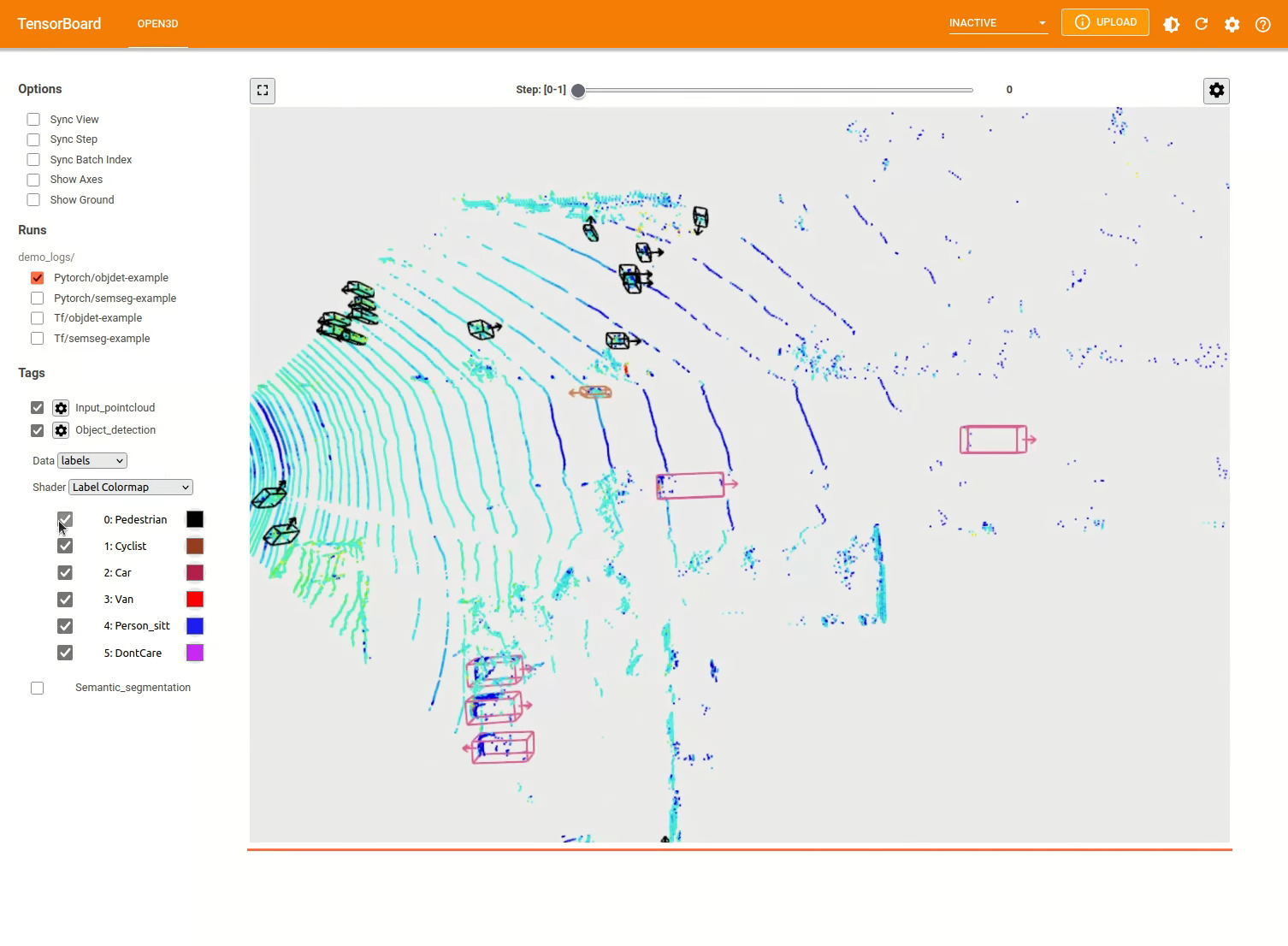
scripts/run_pipeline.py bietet eine einfache Schnittstelle für das Training und die Bewertung eines Modells auf einem Datensatz. Es speichert die Mühe, ein spezifisches Modell zu definieren und die genaue Konfiguration zu übergeben.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Sie können Skript sowohl für die semantische Segmentierung als auch für die Objekterkennung verwenden. Sie müssen entweder eine Semantik- oder Objektdetektion im pipeline -Parameter angeben. Beachten Sie, dass extra args über denselben Parameter priorisiert werden, der in der Konfigurationsdatei vorhanden ist. Anstatt den Param in der Konfigurationsdatei zu ändern, können Sie beim Starten des Skripts das gleiche wie ein Befehlszeilenargument übergeben.
Für zB.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Für weitere Hilfe führen Sie python scripts/run_pipeline.py --help .
Der Kernteil von Open3D-ML lebt im ml3d Unterordner, der in Open3D im ml Namespace integriert ist. Zusätzlich zum Kernteil bieten examples und scripts für Verzeichnisse unterstützende Skripte für die Einrichtung einer Trainingspipeline oder zum Ausführen eines Netzwerks in einem Datensatz.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Für die Aufgabe der semantischen Segmentierung messen wir die Leistung verschiedener Methoden mithilfe des mittleren Schnittpunkts-Over-Union (Miou) über alle Klassen. Die Tabelle zeigt die verfügbaren Modelle und Datensätze für die Segmentierungsaufgabe und die jeweiligen Bewertungen. Jede Punktzahl verlinkt zu der jeweiligen Gewichtsdatei.
| Modell / Datensatz | Semantickitti | Toronto 3d | S3dis | Semantic3d | Paris-lille3d | Scannet |
|---|---|---|---|---|---|---|
| Randla-net (TF) | 53.7 | 73.7 | 70,9 | 76.0 | 70.0* | - - |
| Randla-net (Taschenlampe) | 52,8 | 74,0 | 70,9 | 76.0 | 70.0* | - - |
| KPCONV (TF) | 58,7 | 65.6 | 65.0 | - - | 76,7 | - - |
| KPCONV (Taschenlampe) | 58.0 | 65.6 | 60.0 | - - | 76,7 | - - |
| SparseConvunet (Fackel) | - - | - - | - - | - - | - - | 68 |
| SparseConvunet (TF) | - - | - - | - - | - - | - - | 68,2 |
| Pointtransformer (Taschenlampe) | - - | - - | 69.2 | - - | - - | - - |
| Pointtransformer (TF) | - - | - - | 69.2 | - - | - - | - - |
(*) Verwenden von Gewichten vom ursprünglichen Autor.
Für die Aufgabe der Objekterkennung messen wir die Leistung verschiedener Methoden mithilfe der mittleren durchschnittlichen Präzision (Karte) für die Vogelperspektive (BEV) und 3D. Die Tabelle zeigt die verfügbaren Modelle und Datensätze für die Objekterkennungsaufgabe und die jeweiligen Ergebnisse. Jede Punktzahl verlinkt zu der jeweiligen Gewichtsdatei. Für die Bewertung wurden die Modelle gemäß den Validierungskriterien von Kitti unter Verwendung der Validierungsuntermenge bewertet. Die Modelle wurden für drei Klassen (Auto, Fußgänger und Radfahrer) ausgebildet. Die berechneten Werte sind der Mittelwert über die Karte aller Klassen für alle Schwierigkeitsstufen. Für den Waymo -Datensatz wurden die Modelle in drei Klassen (Fußgänger, Fahrzeug, Radfahrer) geschult.
| Modell / Datensatz | Kitti [Bev / 3d] @ 0,70 | Waymo (Bev / 3D) @ 0,50 |
|---|---|---|
| Pointpillars (TF) | 61.6 / 55.2 | - - |
| Pointpillars (Fackel) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | Best: 61.47 / 57.55 [^WPP-train] |
| Pointrcnn (tf) | 78,2 / 65.9 | - - |
| Pointrcnn (Torch) | 78,2 / 65.9 | - - |
[^WPP-train]: The Avg. Metriken sind durchschnittlich drei Trainingsläufe mit 4, 8, 16 und 32 GPUs. Das Training war nach 30 Epochen gestoppt. Der Modellkontrollpunkt ist für den besten Trainingslauf verfügbar.
Um die Erhöhung der Datenvergrößerung von Bodenwahrheit zu verwenden, können wir wie folgt die Datenbank für die Bodenwahrheit erstellen:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Dadurch wird eine Datenbank erzeugt, die aus Objekten aus der Zugspaltung besteht. Es wird empfohlen, diese Augmentation für Datensatz wie Kitti zu verwenden, bei denen Objekte spärlich sind.
Die beiden Stufen von Pointrcnn werden separat ausgebildet. Um die Stufe zur Erzeugung von Vorschlägen von Pointrcnn mit Pytorch zu trainieren, führen Sie den folgenden Befehl aus:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
Nachdem wir ein gut ausgebildetes RPN -Netzwerk erhalten haben, können wir das RCNN -Netzwerk mit gefrorenen RPN -Gewichten trainieren.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Eine vollständige Liste aller Gewichtsdateien finden Sie unter Model_Weights.txt und die MD5 -Prüfsummendatei model_weights.md5.
Im Folgenden finden Sie eine Liste der Datensätze, für die wir Datensatzleserklassen angeben.
Besuchen Sie diese Datensätze zum Herunterladen der jeweiligen Webseiten und sehen Sie sich die Skripte in scripts/download_datasets an.
Es gibt viele Möglichkeiten, zu diesem Projekt beizutragen. Du kannst:
Bitte stellen Sie Ihre Anfragen an die Entwicklerzweig . Open3d ist eine Community -Anstrengung. Wir begrüßen und feiern Beiträge aus der Community!
Wenn Sie Gewichte für ein von Ihnen geschultes Modell teilen möchten, fügen Sie die Gewichtsdatei in der Pull -Anfrage bitte bei oder verknüpfen Sie bitte. Für Fehler und Probleme öffnen Sie ein Problem. Bitte lesen Sie auch unsere Kommunikationskanäle, um mit der Community in Kontakt zu treten.
Bitte zitieren Sie unsere Arbeit (PDF), wenn Sie Open3D verwenden.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

