Open3D ML
v0.18 release
Installation | Commencez | Structure | Tâches et algorithmes | Modèle Zoo | Ensembles de données | How-tos | Contribuer
Open3D-ML est une extension d'Open3D pour les tâches d'apprentissage automatique 3D. Il s'appuie sur la bibliothèque Open3D Core et l'étend avec des outils d'apprentissage automatique pour le traitement des données 3D. Ce repo se concentre sur des applications telles que la segmentation sémantique des nuages de points et fournit des modèles pré-entraînés qui peuvent être appliqués aux tâches courantes ainsi qu'aux pipelines pour la formation.
Open3D-ML fonctionne avec TensorFlow et Pytorch pour s'intégrer facilement dans les projets existants et fournit également des fonctionnalités générales indépendantes des cadres ML tels que la visualisation des données.
Open3D-ML est intégré dans la distribution Open3D V0.11 + Python et est compatible avec les versions suivantes des cadres ML.
GNU/Linux x86_64 , facultatif)Vous pouvez installer Open3D avec
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dPour installer une version compatible de Pytorch ou TensorFlow, vous pouvez utiliser les fichiers d'exigences respectifs:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtPour tester l'utilisation de l'installation
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "Si vous avez besoin d'utiliser différentes versions des frameworks ML ou CUDA, nous vous recommandons de construire Open3D à partir de Source ou de construire Open3D dans Docker.
À partir de V0.18 sur Linux, la roue PYPI Open3D n'a pas de prise en charge native pour TensorFlow en raison de la création d'incompatibilités entre Pytorch et TensorFlow [voir Python 3.11 Support Pr] pour plus de détails. Si vous souhaitez utiliser Open3D avec TensorFlow sur Linux, vous pouvez créer une roue Open3D à partir de Source dans Docker avec la prise en charge de TensorFlow (mais pas Pytorch) comme:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
./docker_build.sh cuda_wheel_py310L'espace de noms de données contient des classes pour lire des ensembles de données communs. Ici, nous lisons l'ensemble de données Semantictickitti et le visualisons.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))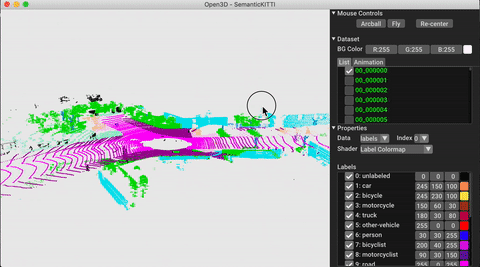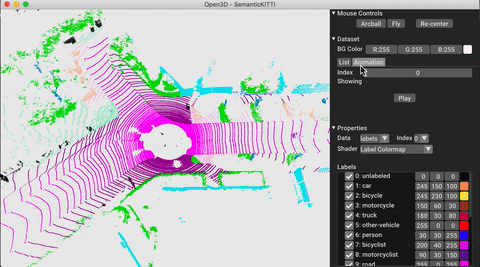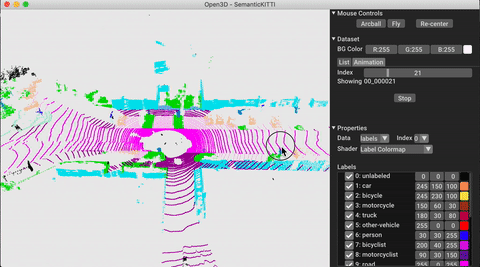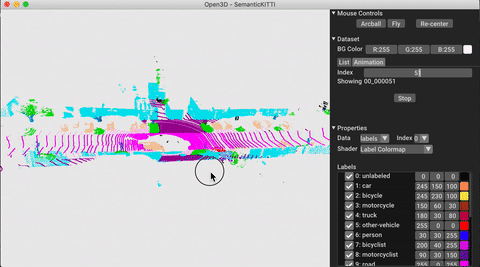
Les configurations des modèles, des ensembles de données et des pipelines sont stockées dans ml3d/configs . Les utilisateurs peuvent également construire leurs propres fichiers YAML pour garder les enregistrements de leurs configurations personnalisées. Voici un exemple de lecture d'un fichier de configuration et de construction de modules à partir de celui-ci.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )S'appuyant sur l'exemple précédent, nous pouvons instancier un pipeline avec un modèle pré-entraîné pour la segmentation sémantique et l'exécuter sur un nuage de points de notre ensemble de données. Voir le modèle Zoo pour obtenir les poids du modèle pré-entraîné.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Les utilisateurs peuvent également utiliser des scripts prédéfinis pour charger des poids pré-entraînés et exécuter des tests.
Semblable à l'inférence, les pipelines fournissent une interface pour la formation d'un modèle sur un ensemble de données.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
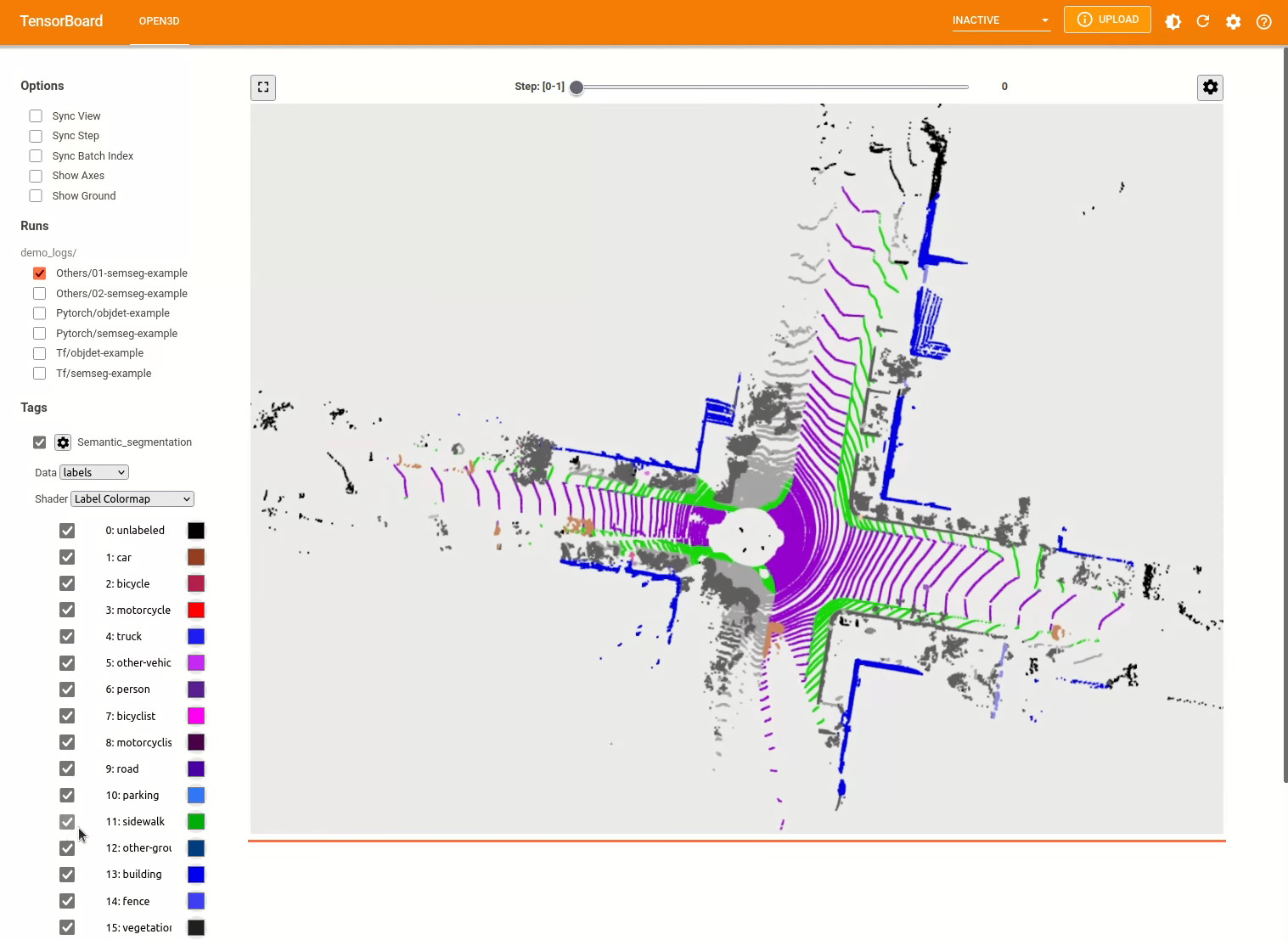
pipeline . run_train () Pour plus d'exemples, voir examples/ et les scripts/ répertoires. Vous pouvez également activer les résumés de formation dans le fichier de configuration et visualiser la vérité au sol et les résultats avec Tensorboard. Voir ce tutoriel pour plus de détails.
Le modèle de détection d'objet 3D est similaire à un modèle de segmentation sémantique. Nous pouvons instancier un pipeline avec un modèle pré-entraîné pour la détection d'objets et l'exécuter sur un nuage de points de notre ensemble de données. Voir le modèle Zoo pour obtenir les poids du modèle pré-entraîné.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()Les utilisateurs peuvent également utiliser des scripts prédéfinis pour charger des poids pré-entraînés et exécuter des tests.
Semblable à l'inférence, les pipelines fournissent une interface pour la formation d'un modèle sur un ensemble de données.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
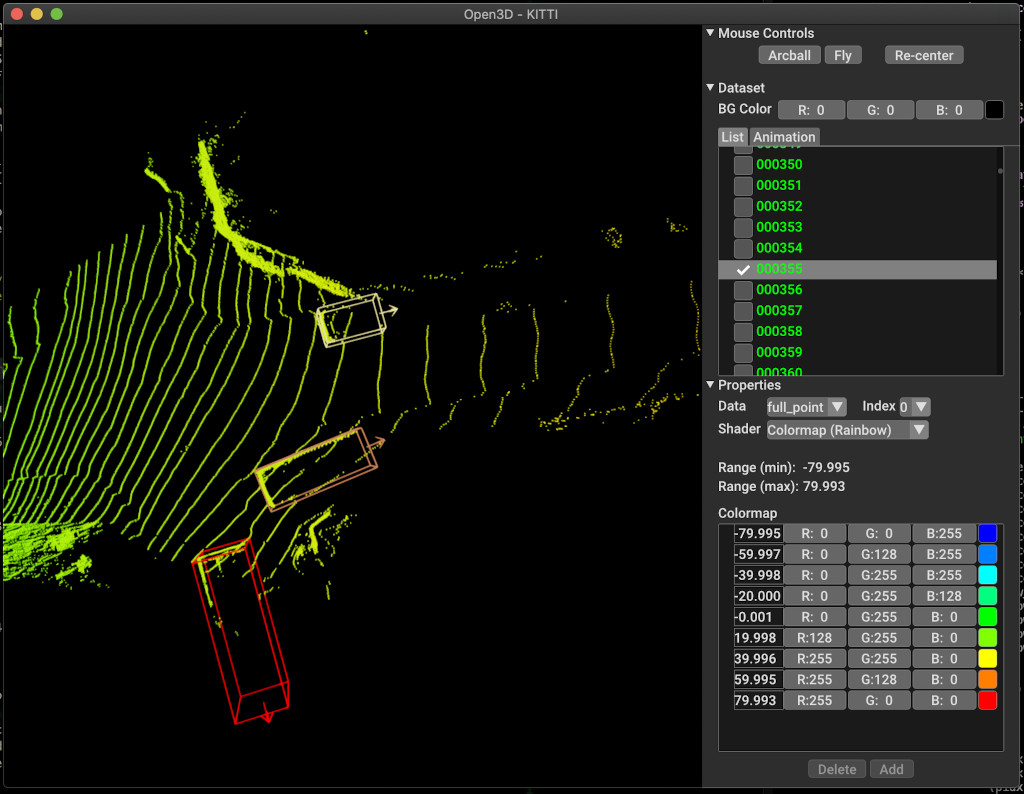
pipeline . run_train ()Vous trouverez ci-dessous un exemple de visualisation à l'aide de Kitti. L'exemple montre l'utilisation de boîtes de délimitation pour l'ensemble de données Kitti.
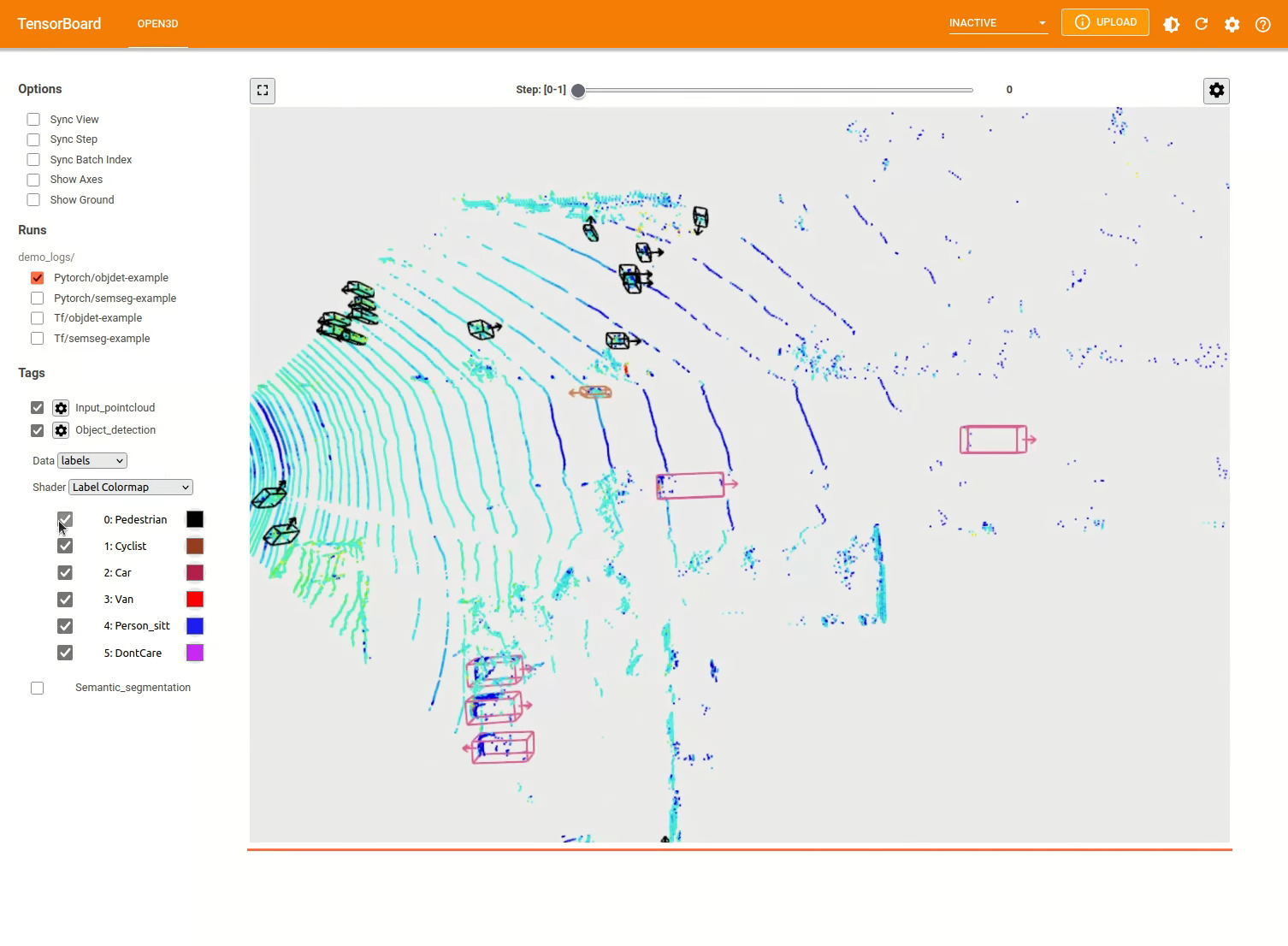
Pour plus d'exemples, voir examples/ et les scripts/ répertoires. Vous pouvez également activer les résumés de formation dans le fichier de configuration et visualiser la vérité au sol et les résultats avec Tensorboard. Voir ce tutoriel pour plus de détails.
scripts/run_pipeline.py fournit une interface facile pour la formation et l'évaluation d'un modèle sur un ensemble de données. Il évite de définir un modèle spécifique et de passer la configuration exacte.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
Vous pouvez utiliser le script pour la segmentation sémantique et la détection d'objets. Vous devez spécifier soit SemanticSegmentation ou ObjectDetection dans le paramètre pipeline . Notez que extra args seront prioritaires sur le même paramètre présent dans le fichier de configuration. Ainsi, au lieu de modifier Param dans le fichier de configuration, vous pouvez passer la même chose qu'un argument de ligne de commande lors du lancement du script.
Pour par exemple.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
Pour plus d'aide, exécutez python scripts/run_pipeline.py --help .
La partie principale de Open3D-ML vit dans le sous-dossier ml3d , qui est intégré dans Open3D dans l'espace de noms ml . En plus de la partie principale, les examples et scripts des répertoires fournissent des scripts de support pour commencer à mettre en place un pipeline de formation ou à exécuter un réseau sur un ensemble de données.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
Pour la tâche de la segmentation sémantique, nous mesurons les performances de différentes méthodes en utilisant l'intersection moyenne-Union (MIOU) dans toutes les classes. Le tableau montre les modèles et ensembles de données disponibles pour la tâche de segmentation et les scores respectifs. Chaque score est lié au fichier de poids respectif.
| Modèle / ensemble de données | Semantictickitti | Toronto 3D | S3dis | Sémantique3d | Paris-Lille3d | Scannet |
|---|---|---|---|---|---|---|
| Randla-Net (TF) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0 * | - |
| Randla-net (torche) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0 * | - |
| Kpconv (tf) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| Kpconv (torche) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| SparsEconvunet (torche) | - | - | - | - | - | 68 |
| SparsEconvunet (TF) | - | - | - | - | - | 68.2 |
| PointTransformateur (torche) | - | - | 69.2 | - | - | - |
| PointTransformateur (TF) | - | - | 69.2 | - | - | - |
(*) En utilisant des poids de l'auteur original.
Pour la tâche de détection d'objets, nous mesurons les performances de différentes méthodes en utilisant la précision moyenne moyenne (MAP) pour la vue de l'œil d'oiseau (BEV) et la 3D. Le tableau montre les modèles et ensembles de données disponibles pour la tâche de détection d'objet et les scores respectifs. Chaque score est lié au fichier de poids respectif. Pour l'évaluation, les modèles ont été évalués à l'aide du sous-ensemble de validation, selon les critères de validation de Kitti. Les modèles ont été formés pour trois classes (voiture, piéton et cycliste). Les valeurs calculées sont la valeur moyenne sur la carte de toutes les classes pour tous les niveaux de difficulté. Pour l'ensemble de données Waymo, les modèles ont été formés sur trois classes (piéton, véhicule, cycliste).
| Modèle / ensemble de données | Kitti [bev / 3d] @ 0,70 | Waymo (bev / 3d) @ 0,50 |
|---|---|---|
| PointPillars (TF) | 61.6 / 55.2 | - |
| Pointpillars (torche) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | Meilleur: 61,47 / 57,55 [^ WPP-Train] |
| Pointrcnn (tf) | 78.2 / 65.9 | - |
| Pointrcnn (torche) | 78.2 / 65.9 | - |
[^ WPP-TRAIN]: L'AVG. Les métriques sont la moyenne de trois ensembles de formation avec 4, 8, 16 et 32 GPU. La formation a été interrompue après 30 époques. Le point de contrôle du modèle est disponible pour la meilleure séance d'entraînement.
Pour utiliser l'augmentation des données d'échantillonnage de vérité au sol pour la formation, nous pouvons générer la base de données de vérité au sol comme suit:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
Cela générera une base de données composée d'objets de la fractionnement du train. Il est recommandé d'utiliser cette augmentation pour un ensemble de données comme Kitti où les objets sont rares.
Les deux étapes de Pointrcnn sont formées séparément. Pour entraîner la stade de génération de proposition de Pointrcnn avec Pytorch, exécutez la commande suivante:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
Après avoir obtenu un réseau RPN bien formé, nous pouvons former un réseau RCNN avec des poids RPN surgelés.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
Pour une liste complète de tous les fichiers de poids, voir Model_weights.txt et le fichier MD5 Fichier Model_weights.md5.
Ce qui suit est une liste des ensembles de données pour lesquels nous fournissons des classes de lecteurs de données.
Pour télécharger ces ensembles de données, visitez les pages Web respectives et jetez un œil aux scripts dans scripts/download_datasets .
Il existe de nombreuses façons de contribuer à ce projet. Tu peux:
S'il vous plaît, faites vos demandes de traction à la branche de développement . Open3D est un effort communautaire. Nous accueillons et célébrons les contributions de la communauté!
Si vous souhaitez partager des poids pour un modèle que vous avez formé, veuillez joindre ou lier le fichier de poids dans la demande de traction. Pour les bogues et les problèmes, ouvrez un problème. Veuillez également consulter nos canaux de communication pour entrer en contact avec la communauté.
Veuillez citer notre travail (PDF) si vous utilisez Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

