Open3D ML
v0.18 release
التثبيت | ابدأ | هيكل | المهام والخوارزميات | موديل حديقة الحيوان | مجموعات البيانات | كيف tos | يساهم
Open3D-ML هو امتداد لـ Open3D لمهام التعلم الآلي ثلاثية الأبعاد. إنه يبني فوق مكتبة Open3D الأساسية ويمتدها مع أدوات التعلم الآلي لمعالجة البيانات ثلاثية الأبعاد. يركز هذا الريبو على التطبيقات مثل تجزئة Cloud Point Semantic ويوفر نماذج مسبقة يمكن تطبيقها على المهام الشائعة وكذلك خطوط الأنابيب للتدريب.
يعمل Open3D-ML مع TensorFlow و Pytorch للدمج بسهولة في المشاريع الحالية ويوفر أيضًا وظائف عامة مستقلة عن أطر عمل ML مثل تصور البيانات.
تم دمج Open3D-ML في توزيع Open3D V0.11+ Python وهو متوافق مع الإصدارات التالية من أطر ML.
GNU/Linux x86_64 ، اختياري)يمكنك تثبيت Open3D مع
# make sure you have the latest pip version
pip install --upgrade pip
# install open3d
pip install open3dلتثبيت إصدار متوافق من Pytorch أو TensorFlow ، يمكنك استخدام ملفات المتطلبات المعنية:
# To install a compatible version of TensorFlow
pip install -r requirements-tensorflow.txt
# To install a compatible version of PyTorch
pip install -r requirements-torch.txt
# To install a compatible version of PyTorch with CUDA on Linux
pip install -r requirements-torch-cuda.txtلاختبار استخدام التثبيت
# with PyTorch
$ python -c " import open3d.ml.torch as ml3d "
# or with TensorFlow
$ python -c " import open3d.ml.tf as ml3d "إذا كنت بحاجة إلى استخدام إصدارات مختلفة من أطر ML أو CUDA ، فإننا نوصي ببناء Open3D من Source أو Build Open3D في Docker.
من V0.18 فصاعدًا على Linux ، لا تملك عجلة PYPI Open3D دعمًا أصليًا لـ Tensorflow بسبب عدم توافق البناء بين Pytorch و TensorFlow [انظر Python 3.11 Prems Pr] للحصول على التفاصيل. إذا كنت ترغب في استخدام Open3D مع TensorFlow على Linux ، فيمكنك إنشاء عجلة Open3D من المصدر في Docker بدعم من TensorFlow (ولكن ليس Pytorch) على النحو التالي:
cd docker
# Build open3d and open3d-cpu wheels for Python 3.10 with Tensorflow support
export BUILD_PYTORCH_OPS=OFF BUILD_TENSORFLOW_OPS=ON
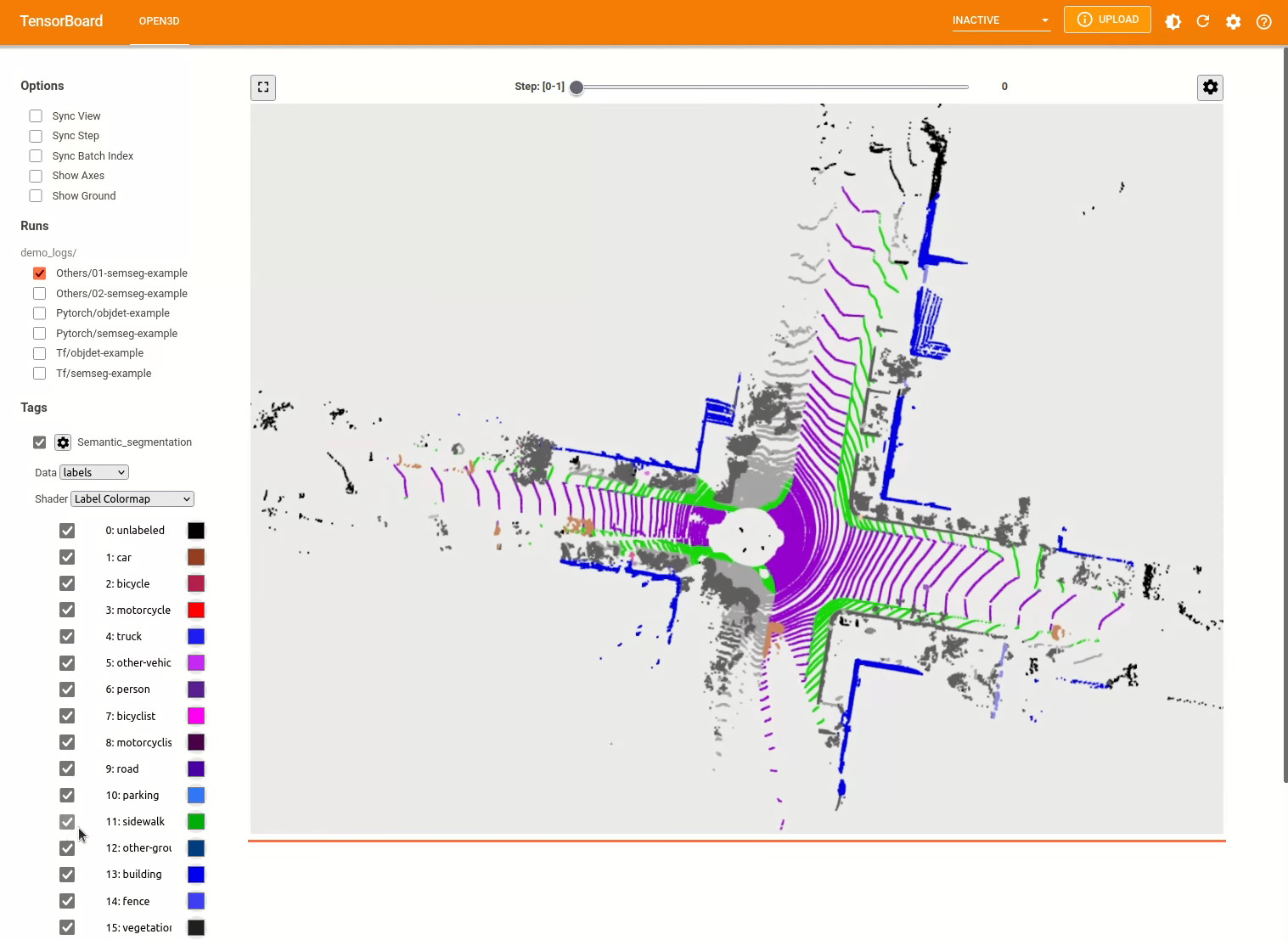
./docker_build.sh cuda_wheel_py310تحتوي مساحة اسم مجموعة البيانات على فصول لقراءة مجموعات البيانات الشائعة. هنا نقرأ مجموعة بيانات semantickitti وتصورها.
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' )
# get the 'all' split that combines training, validation and test set
all_split = dataset . get_split ( 'all' )
# print the attributes of the first datum
print ( all_split . get_attr ( 0 ))
# print the shape of the first point cloud
print ( all_split . get_data ( 0 )[ 'point' ]. shape )
# show the first 100 frames using the visualizer
vis = ml3d . vis . Visualizer ()
vis . visualize_dataset ( dataset , 'all' , indices = range ( 100 ))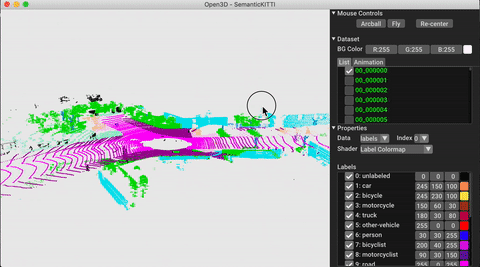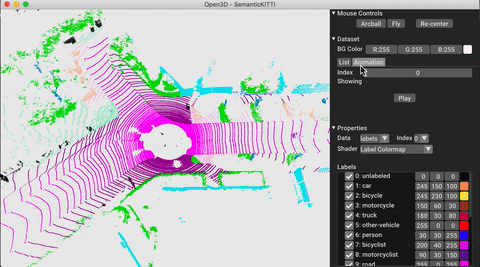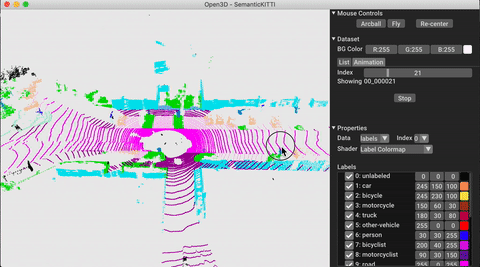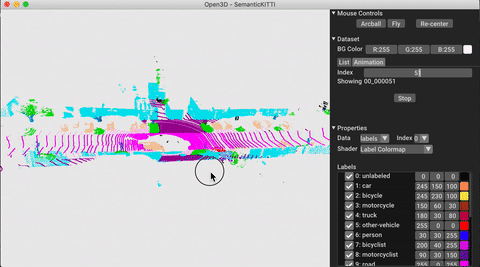
يتم تخزين تكوينات النماذج ومجموعات البيانات وخطوط الأنابيب في ml3d/configs . يمكن للمستخدمين أيضًا إنشاء ملفات YAML الخاصة بهم للحفاظ على سجل تكويناتهم المخصصة. فيما يلي مثال على قراءة ملف التكوين وبناء وحدات منه.
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d # or open3d.ml.tf as ml3d
framework = "torch" # or tf
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
# fetch the classes by the name
Pipeline = _ml3d . utils . get_module ( "pipeline" , cfg . pipeline . name , framework )
Model = _ml3d . utils . get_module ( "model" , cfg . model . name , framework )
Dataset = _ml3d . utils . get_module ( "dataset" , cfg . dataset . name )
# use the arguments in the config file to construct the instances
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = Dataset ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
model = Model ( ** cfg . model )
pipeline = Pipeline ( model , dataset , ** cfg . pipeline )بناءً على المثال السابق ، يمكننا إنشاء إنشاء خط أنابيب مع نموذج مسبق للتجزئة الدلالية وتشغيله على سحابة نقطة من مجموعة البيانات الخاصة بنا. شاهد حديقة الحيوان النموذجية للحصول على أوزان النموذج المسبق.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/randlanet_semantickitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . RandLANet ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . SemanticKITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . SemanticSegmentation ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "randlanet_semantickitti_202201071330utc.pth"
randlanet_url = "https://storage.googleapis.com/open3d-releases/model-zoo/randlanet_semantickitti_202201071330utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( randlanet_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()يمكن للمستخدمين أيضًا استخدام البرامج النصية المحددة مسبقًا لتحميل الأوزان المسبقة وتشغيل الاختبار.
على غرار الاستدلال ، توفر خطوط الأنابيب واجهة لتدريب نموذج على مجموعة البيانات.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . SemanticKITTI ( dataset_path = '/path/to/SemanticKITTI/' , use_cache = True )
# create the model with random initialization.
model = RandLANet ()
pipeline = SemanticSegmentation ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
pipeline . run_train () لمزيد من الأمثلة ، انظر examples/ والبرامج scripts/ الدلائل. يمكنك أيضًا تمكين توفير ملخصات التدريب في ملف التكوين وتصور الحقيقة والنتائج مع Tensorboard. انظر هذا البرنامج التعليمي للحصول على التفاصيل.
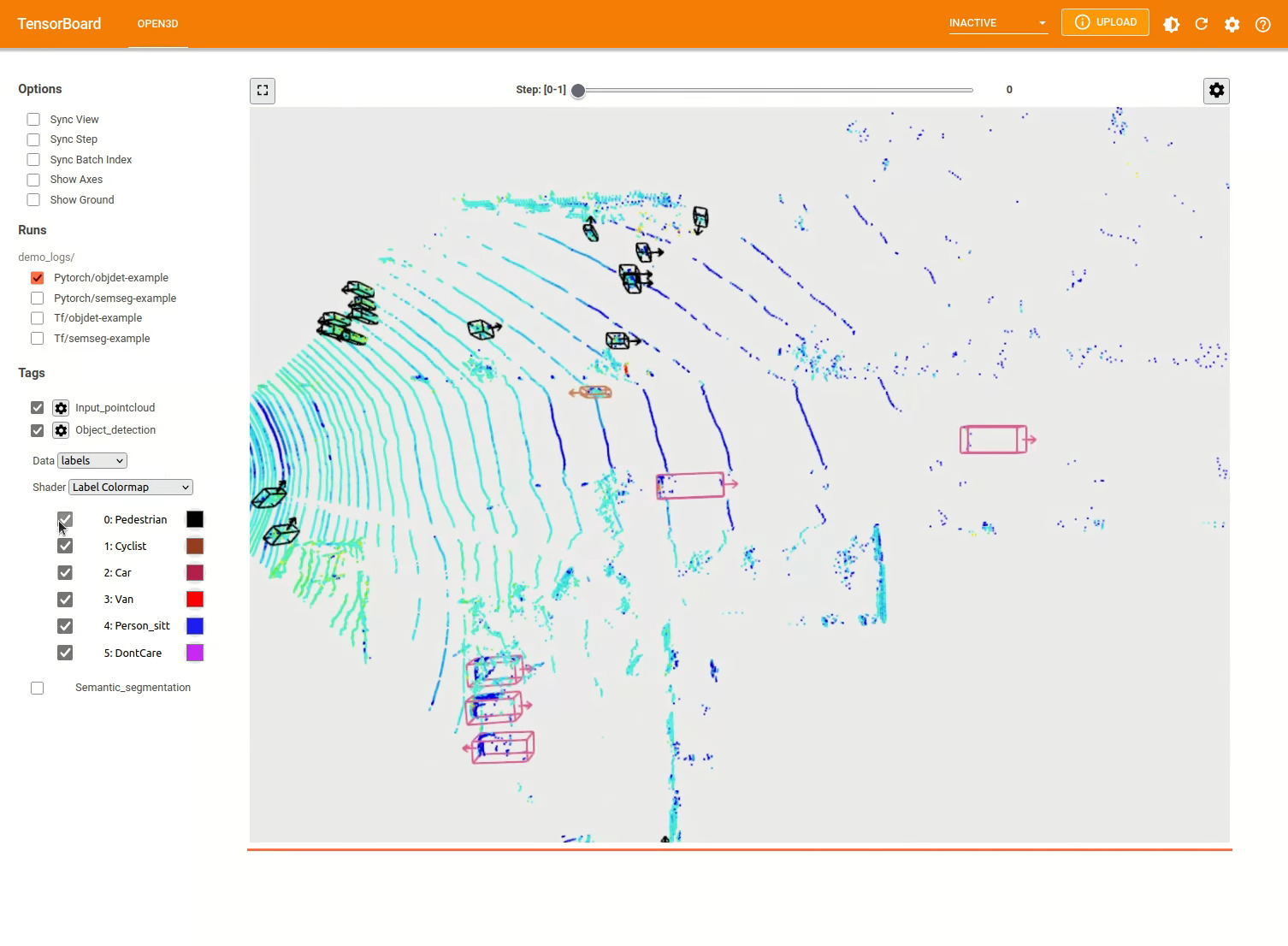
يشبه نموذج الكشف عن الكائنات ثلاثية الأبعاد نموذج تجزئة الدلالي. يمكننا إنشاء إنشاء خط أنابيب مع نموذج مسبق للكشف عن الكائنات وتشغيله على سحابة نقطة من مجموعة البيانات الخاصة بنا. شاهد حديقة الحيوان النموذجية للحصول على أوزان النموذج المسبق.
import os
import open3d . ml as _ml3d
import open3d . ml . torch as ml3d
cfg_file = "ml3d/configs/pointpillars_kitti.yml"
cfg = _ml3d . utils . Config . load_from_file ( cfg_file )
model = ml3d . models . PointPillars ( ** cfg . model )
cfg . dataset [ 'dataset_path' ] = "/path/to/your/dataset"
dataset = ml3d . datasets . KITTI ( cfg . dataset . pop ( 'dataset_path' , None ), ** cfg . dataset )
pipeline = ml3d . pipelines . ObjectDetection ( model , dataset = dataset , device = "gpu" , ** cfg . pipeline )
# download the weights.
ckpt_folder = "./logs/"
os . makedirs ( ckpt_folder , exist_ok = True )
ckpt_path = ckpt_folder + "pointpillars_kitti_202012221652utc.pth"
pointpillar_url = "https://storage.googleapis.com/open3d-releases/model-zoo/pointpillars_kitti_202012221652utc.pth"
if not os . path . exists ( ckpt_path ):
cmd = "wget {} -O {}" . format ( pointpillar_url , ckpt_path )
os . system ( cmd )
# load the parameters.
pipeline . load_ckpt ( ckpt_path = ckpt_path )
test_split = dataset . get_split ( "test" )
data = test_split . get_data ( 0 )
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline . run_inference ( data )
# evaluate performance on the test set; this will write logs to './logs'.
pipeline . run_test ()يمكن للمستخدمين أيضًا استخدام البرامج النصية المحددة مسبقًا لتحميل الأوزان المسبقة وتشغيل الاختبار.
على غرار الاستدلال ، توفر خطوط الأنابيب واجهة لتدريب نموذج على مجموعة البيانات.
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d . datasets . KITTI ( dataset_path = '/path/to/KITTI/' , use_cache = True )
# create the model with random initialization.
model = PointPillars ()
pipeline = ObjectDetection ( model = model , dataset = dataset , max_epoch = 100 )
# prints training progress in the console.
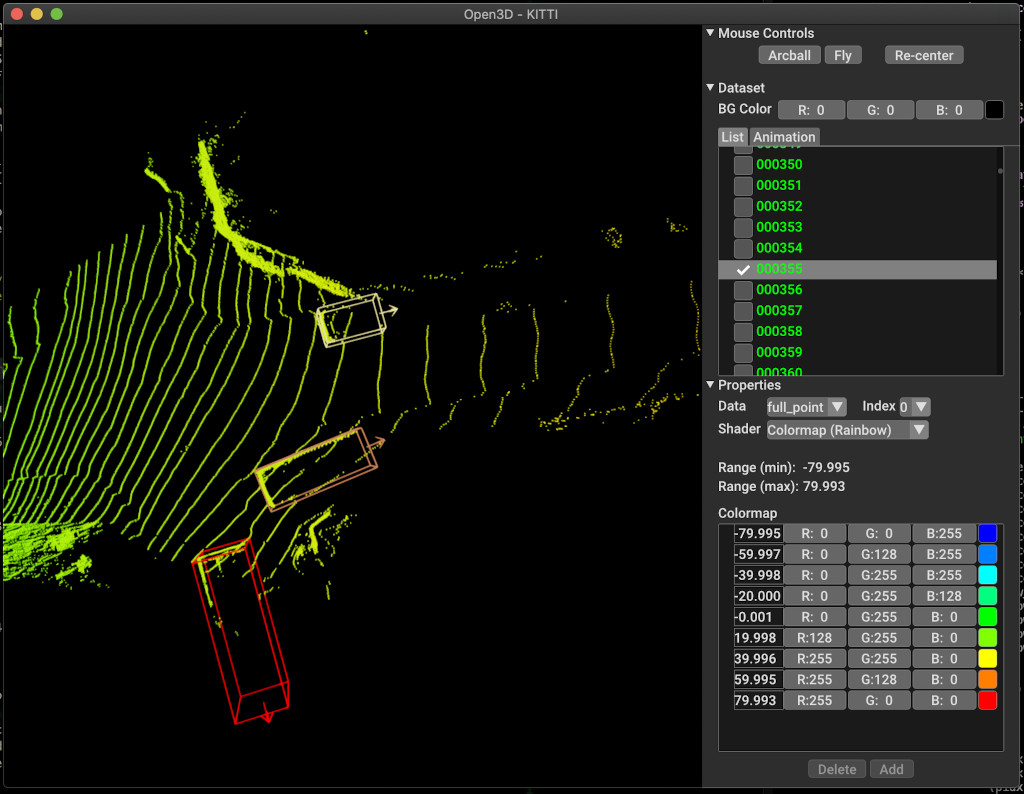
pipeline . run_train ()فيما يلي مثال على التصور باستخدام Kitti. يوضح المثال استخدام المربعات المحيطة بمجموعة بيانات Kitti.
لمزيد من الأمثلة ، انظر examples/ والبرامج scripts/ الدلائل. يمكنك أيضًا تمكين توفير ملخصات التدريب في ملف التكوين وتصور الحقيقة والنتائج مع Tensorboard. انظر هذا البرنامج التعليمي للحصول على التفاصيل.
يوفر scripts/run_pipeline.py واجهة سهلة للتدريب وتقييم نموذج على مجموعة بيانات. إنه يحفظ مشكلة تحديد النموذج المحدد وتمرير التكوين الدقيق.
python scripts/run_pipeline.py {tf/torch} -c <path-to-config> --pipeline {SemanticSegmentation/ObjectDetection} --<extra args>
يمكنك استخدام البرنامج النصي لكل من التجزئة الدلالية واكتشاف الكائنات. يجب عليك تحديد إما semanticsegression أو كائن في معلمة pipeline . لاحظ أنه سيتم إعطاء الأولوية extra args عبر نفس المعلمة الموجودة في ملف التكوين. لذا بدلاً من تغيير Param في ملف التكوين ، يمكنك تمرير نفس وسيطة سطر الأوامر أثناء تشغيل البرنامج النصي.
على سبيل المثال.
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --pipeline SemanticSegmentation --dataset.use_cache True
# Launch testing for PointPillars on KITTI with torch.
python scripts/run_pipeline.py torch -c ml3d/configs/pointpillars_kitti.yml --split test --dataset.dataset_path <path-to-dataset> --pipeline ObjectDetection --dataset.use_cache True
لمزيد من المساعدة ، قم بتشغيل python scripts/run_pipeline.py --help .
يعيش الجزء الأساسي من Open3D-ML في المجلد الفرعي ml3d ، والذي تم دمجه في Open3D في مساحة اسم ml . بالإضافة إلى الجزء الأساسي ، توفر examples الدلائل والبرامج scripts البرامج النصية الداعمة للبدء في إعداد خط أنابيب تدريب أو تشغيل شبكة على مجموعة بيانات.
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ metrics # Metrics available for evaluating ML models
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ utils # Utilities for <>
├─ scripts # Demo scripts for training and dataset download scripts
لمهمة التجزئة الدلالية ، نقيس أداء الأساليب المختلفة باستخدام متوسط التقاطع بين الوحدة (MIOU) على جميع الفئات. يوضح الجدول النماذج ومجموعات البيانات المتاحة لمهمة التجزئة والعشرات المعنية. كل نقاط تصل إلى ملف الوزن المعني.
| نموذج / مجموعة البيانات | semantickitti | تورونتو 3D | S3dis | Semantic3d | Paris-Lille3d | سفن |
|---|---|---|---|---|---|---|
| راندا-نيت (TF) | 53.7 | 73.7 | 70.9 | 76.0 | 70.0* | - |
| راندا نيت (الشعلة) | 52.8 | 74.0 | 70.9 | 76.0 | 70.0* | - |
| KPConv (TF) | 58.7 | 65.6 | 65.0 | - | 76.7 | - |
| KPConv (الشعلة) | 58.0 | 65.6 | 60.0 | - | 76.7 | - |
| Sparseconvunet (الشعلة) | - | - | - | - | - | 68 |
| Sparseconvunet (TF) | - | - | - | - | - | 68.2 |
| النقل الناقص (الشعلة) | - | - | 69.2 | - | - | - |
| نقل النقطة (TF) | - | - | 69.2 | - | - | - |
(*) استخدام الأوزان من المؤلف الأصلي.
بالنسبة لمهمة اكتشاف الكائنات ، نقيس أداء الأساليب المختلفة باستخدام متوسط الدقة (MAP) لعرض عين الطيور (BEV) و 3D. يوضح الجدول النماذج ومجموعات البيانات المتاحة لمهمة اكتشاف الكائنات والنتائج المعنية. كل نقاط تصل إلى ملف الوزن المعني. للتقييم ، تم تقييم النماذج باستخدام مجموعة التحقق من الصحة ، وفقًا لمعايير التحقق من صحة Kitti. تم تدريب النماذج لثلاث فصول (السيارة والمشاة والدراج). القيم المحسوبة هي القيمة المتوسطة على خريطة جميع الفئات لجميع مستويات الصعوبة. بالنسبة لمجموعة بيانات Waymo ، تم تدريب النماذج على ثلاث فئات (المشاة ، مركبة ، راكب الدراجات).
| نموذج / مجموعة البيانات | Kitti [bev / 3d] @ 0.70 | Waymo (BEV / 3D) @ 0.50 |
|---|---|---|
| PointPillars (TF) | 61.6 / 55.2 | - |
| PointPillars (الشعلة) | 61.2 / 52.8 | AVG: 61.01 / 48.30 | أفضل: 61.47 / 57.55 [^WPP-Train] |
| Pointrcnn (TF) | 78.2 / 65.9 | - |
| pointrcnn (الشعلة) | 78.2 / 65.9 | - |
[^WPP-Train]: The Avg. المقاييس هي متوسط ثلاث مجموعات من التدريب مع 4 و 8 و 16 و 32 وحدات معالجة الرسومات. كان التدريب لوقف بعد 30 عصر. نقطة تفتيش النموذج متاحة لأفضل تشغيل تدريب.
لاستخدام زيادة بيانات أخذ عينات الحقيقة للتدريب ، يمكننا إنشاء قاعدة بيانات الحقيقة الأساسية على النحو التالي:
python scripts/collect_bboxes.py --dataset_path <path_to_data_root>
سيؤدي ذلك إلى إنشاء قاعدة بيانات تتكون من كائنات من تقسيم القطار. يوصى باستخدام هذا التعزيز لمجموعة البيانات مثل Kitti حيث تكون الكائنات متفرقًا.
يتم تدريب مرحلتين من pointrcnn بشكل منفصل. لتدريب مرحلة توليد الاقتراحات من pointrcnn مع pytorch ، قم بتشغيل الأمر التالي:
# Train RPN for 100 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RPN --epochs 100
بعد الحصول على شبكة RPN المدربة بشكل جيد ، يمكننا تدريب شبكة RCNN مع أوزان RPN المجمدة.
# Train RCNN for 70 epochs.
python scripts/run_pipeline.py torch -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <path-to-dataset> --mode RCNN --model.ckpt_path <path_to_checkpoint> --epochs 100
للحصول على قائمة كاملة بجميع ملفات الوزن ، انظر Model_weights.txt و MD5 Checksum File Model_weights.md5.
فيما يلي قائمة بمجموعات البيانات التي نقدمها فئات قارئ مجموعات البيانات.
لتنزيل مجموعات البيانات هذه ، تفضل بزيارة صفحات الويب المعنية وإلقاء نظرة على البرامج النصية في scripts/download_datasets .
هناك العديد من الطرق للمساهمة في هذا المشروع. أنت تستطيع:
من فضلك ، قم بتقديم طلبات السحب إلى فرع DEV . Open3D هو جهد مجتمعي. نرحب ونحتفل بالمساهمات من المجتمع!
إذا كنت ترغب في مشاركة الأوزان لنموذج قمت بتدريبه ، فيرجى إرفاق أو ربط ملف الأوزان في طلب السحب. للحشرات والمشاكل ، افتح مشكلة. يرجى أيضًا التحقق من قنوات الاتصال الخاصة بنا للاتصال بالمجتمع.
يرجى الاستشهاد بعملنا (PDF) إذا كنت تستخدم Open3D.
@article { Zhou2018 ,
author = { Qian-Yi Zhou and Jaesik Park and Vladlen Koltun } ,
title = { {Open3D}: {A} Modern Library for {3D} Data Processing } ,
journal = { arXiv:1801.09847 } ,
year = { 2018 } ,
}

