GPT2
Pretrained Korean GPT2
Языковые модели - это неконтролируемые многозадачные ученики
Этот проект представляет собой реализацию Pytorch модели OpenAI GPT-2. Он обеспечивает модельное обучение, генерацию предложений и визуализацию метрик. Это считается как понятным, так и оптимизированным. Мы разработали коды, чтобы быть понятными. Также мы используем некоторые методы для повышения производительности.
Перед обучением модели GPT-2 следует подготовить набор данных корпуса. Мы рекомендуем создать свой собственный корпус, используя Expanda. Вместо этого обучающий модуль требует токенизированных наборов данных обучения и оценки с их словарным файлом.
После подготовки наборов данных вы можете обучить GPT-2, используя следующее:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Чтобы возобновить обучение из последнего файла контрольной точки, используйте --from_checkpoint [last checkpoint file] . Если вы хотите обучить GPT-2 с несколькими графическими процессорами, используйте опцию --gpus [number of gpus] .
Деталь использования командной строки заключается в следующем:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
После обучения GPT-2 вы можете генерировать предложения с помощью обученной модели в интерактивном режиме.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
Деталь использования командной строки заключается в следующем:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Одним из способов оценки эффективности обученной модели является вычисление объективных метрик с помощью набора данных оценки, который не используется на этапе обучения.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
Кроме того, вы также можете проанализировать график потери тренировок, визуализируя записанные метрики.
$ python -m gpt2 visualize --model_path model.pth --interactive
Пример фигура как реже:
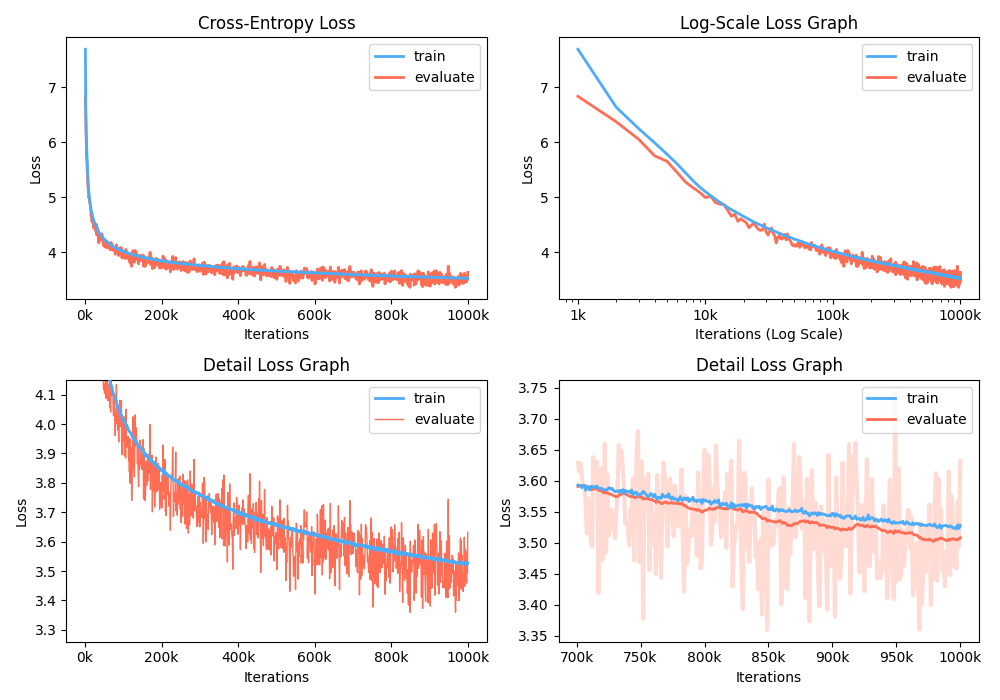
Во время обучения вы можете использовать NVIDIA Apex для использования слитых слоев CUDA и оптимизации смешанного назначения. Опция --use_amp позволяет автоматическая смешанная точность в обучении. Перед использованием этого повышения производительности вы должны установить библиотеку NVIDIA Apex , следуя репозиторию или запустить Belows:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Если вы не можете установить библиотеку, или ваше устройство GPU не поддерживает быстрое обучение смешанного назначения (именно то, что GPU должен поддерживать ускорение смешанного назначения через ядер тензоров), вы можете обучить модель в режиме одноприменения. Обучение смешанного назначения является вариантом. В этом случае вы все еще можете использовать плавленные слои CUDA, такие как Adam Optimizer и нормализация слоя при тренировке.
Вы можете воспроизводить обученную модель GPT2 в Google Colab! Приведенный выше ноутбук содержит генерацию текста и оценку метриков. Вам необходимо загрузить обученную модель, словарную файл и набор данных оценки в Google Cloud Storage.
Для людей, которые заинтересованы в корейской версии GPT2, мы переписываем вышеуказанный ноутбук, чтобы предоставить особенно модель gpt2-ko-302M , которая обучена примерно 5,04B токенам из корейских документов. Вы можете сыграть демонстрацию в этой записной книжке.
Этот проект лицензирован Apache-2.0.


