GPT2
Pretrained Korean GPT2
Model bahasa adalah pelajar multitask tanpa pengawasan
Proyek ini adalah implementasi Pytorch dari model OpenAI GPT-2. Ini memberikan pelatihan model, generasi kalimat, dan visualisasi metrik. Itu dianggap dapat dimengerti dan dioptimalkan. Kami merancang kode agar dapat dipahami. Kami juga menggunakan beberapa teknik untuk meningkatkan kinerja.
Sebelum melatih model GPT-2, dataset corpus harus disiapkan. Kami merekomendasikan untuk membangun corpus Anda sendiri dengan menggunakan Expanda. Sebagai gantinya, modul pelatihan membutuhkan kumpulan data pelatihan dan evaluasi tokenisasi dengan file kosa kata mereka.
Setelah menyiapkan dataset, Anda dapat melatih GPT-2 dengan menggunakan sebagai berikut:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Untuk melanjutkan pelatihan dari file pos pemeriksaan terakhir, gunakan opsi --from_checkpoint [last checkpoint file] . Jika Anda ingin melatih GPT-2 dengan beberapa GPU, gunakan opsi --gpus [number of gpus] .
Detail penggunaan baris perintah adalah sebagai berikut:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
Setelah pelatihan GPT-2, Anda dapat menghasilkan kalimat dengan model terlatih Anda dalam mode interaktif.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
Detail penggunaan baris perintah adalah sebagai berikut:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Salah satu cara untuk memperkirakan kinerja model terlatih adalah dengan menghitung metrik objektif dengan dataset evaluasi, yang tidak digunakan selama fase pelatihan.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
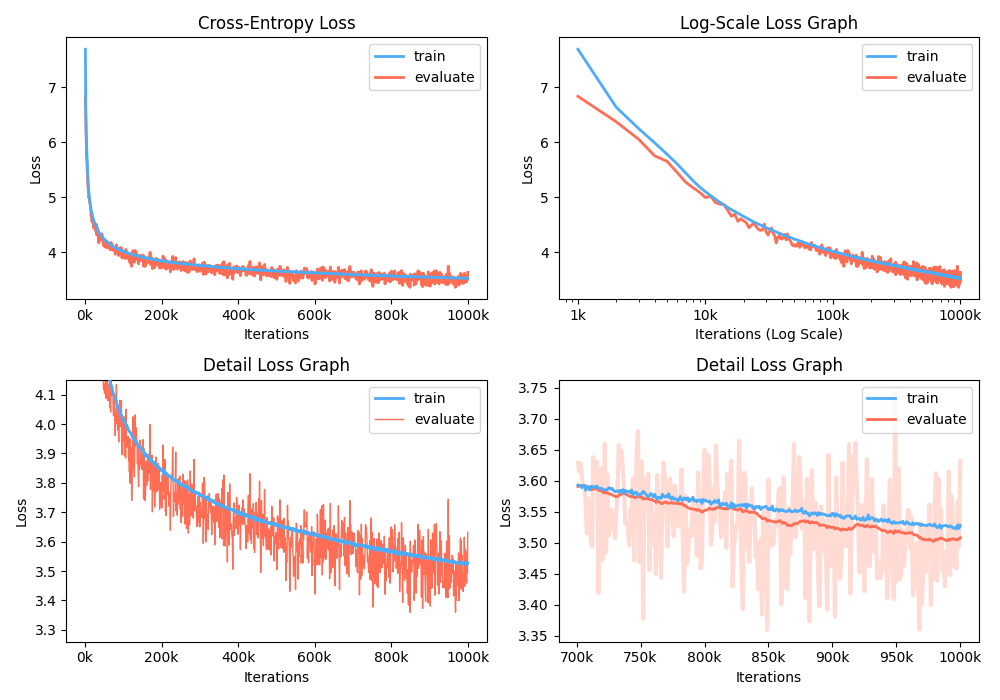
Selain itu, Anda juga dapat menganalisis grafik kehilangan pelatihan dengan memvisualisasikan metrik yang direkam.
$ python -m gpt2 visualize --model_path model.pth --interactive
Contoh angka adalah di bawah:
Saat berlatih, Anda dapat menggunakan NVIDIA APEX untuk menggunakan lapisan CUDA yang menyatu dan optimasi presisi campuran. Opsi --use_amp memungkinkan presisi campuran otomatis dalam pelatihan. Sebelum menggunakan peningkatan kinerja ini, Anda harus menginstal Perpustakaan NVIDIA APEX dengan mengikuti repositori, atau jalankan BELOWS:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Jika Anda tidak dapat menginstal perpustakaan atau perangkat GPU Anda tidak mendukung pelatihan presisi campuran cepat (tepatnya, GPU harus mendukung akselerasi presisi campuran melalui inti tensor), Anda dapat melatih model dalam mode presisi tunggal. Pelatihan presisi campuran adalah pilihan. Dalam hal ini, Anda masih dapat menggunakan lapisan CUDA yang menyatu seperti Adam Optimizer dan Normalisasi Lapisan dalam Pelatihan.
Anda dapat memainkan model GPT2 terlatih di Google Colab! Notebook di atas berisi evaluasi pembuatan teks dan metrik. Anda perlu mengunggah model terlatih, file kosa kata dan dataset evaluasi ke Google Cloud Storage.
Bagi orang-orang yang tertarik dengan versi Korea-GPT2, kami menulis ulang notebook di atas untuk memberikan kasus model gpt2-ko-302M khususnya, yang dilatih dengan sekitar 5,04B token dari dokumen Korea. Anda dapat memainkan demo di buku catatan ini.
Proyek ini berlisensi APACHE-2.0.


