GPT2
Pretrained Korean GPT2
Sprachmodelle sind unbeaufsichtigte Multitasking -Lernende
Dieses Projekt ist eine Pytorch-Implementierung des OpenAI-GPT-2-Modells. Es bietet Modelltraining, Satzgenerierung und Visualisierung von Metriken. Es wird sowohl verständlich als auch optimiert angesehen. Wir haben die Codes so gestaltet, dass sie verständlich sind. Außerdem verwenden wir einige Techniken, um die Leistung zu verbessern.
Vor dem Training des GPT-2-Modells sollte der Corpus-Datensatz erstellt werden. Wir empfehlen, Ihren eigenen Korpus zu bauen, indem Sie EXPEDA verwenden. Stattdessen erfordert das Schulungsmodul tokenisierte Schulungs- und Bewertungsdatensätze mit ihrer Vokabulardatei.
Nach der Vorbereitung von Datensätzen können Sie GPT-2 ausbilden, indem Sie wie folgt verwenden:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Verwenden Sie --from_checkpoint [last checkpoint file] , um das Training von der letzten Checkpoint -Datei wieder aufzunehmen. Wenn Sie GPT-2 mit mehreren GPUs trainieren möchten, verwenden Sie die Option --gpus [number of gpus] .
Das Detail der Befehlszeilennutzung lautet wie folgt:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
Nach dem Training von GPT-2 können Sie Sätze mit Ihrem geschulten Modell im interaktiven Modus generieren.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
Das Detail der Befehlszeilennutzung lautet wie folgt:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Eine Möglichkeit, die Leistung des geschulten Modells zu schätzen, besteht darin, die objektiven Metriken mit dem Bewertungsdatensatz zu berechnen, der während der Trainingsphase nicht verwendet wird.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
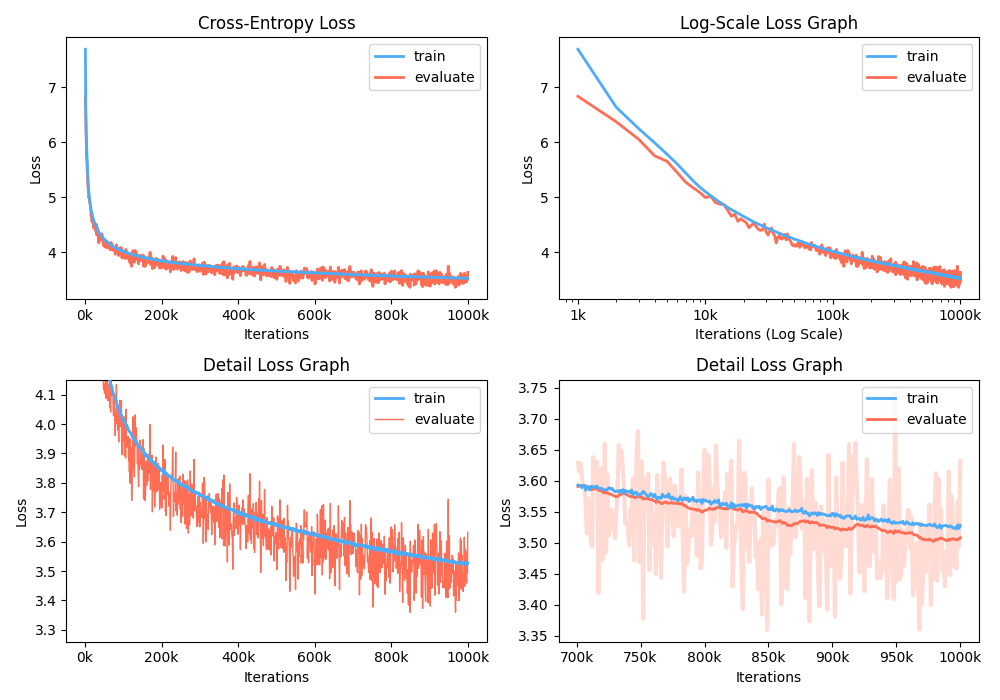
Darüber hinaus können Sie auch das Trainingsverlust -Diagramm analysieren, indem Sie aufgezeichnete Metriken visualisieren.
$ python -m gpt2 visualize --model_path model.pth --interactive
Die Beispielfigur ist wie unten:
Während des Trainings können Sie NVIDIA Apex verwenden, um fusionierte CUDA-Schichten und Optimierung mit gemischter Vorbereitung zu verwenden. Die Option --use_amp ermöglicht eine automatische gemischte Präzision im Training. Bevor Sie diese Leistungssteigerung verwenden, sollten Sie die NVIDIA Apex Library installieren, indem Sie dem Repository folgen oder Belows ausführen:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Wenn Sie die Bibliothek nicht installieren können, oder Ihr GPU-Gerät unterstützt das Training mit schnellem Vorbereitung nicht (genau sollte die GPU die Beschleunigung der gemischten Präzision durch Tensorkerne unterstützen), können Sie das Modell im Einzelprezisionsmodus trainieren. Das Training mit gemischtem Präzision ist eine Option. In diesem Fall können Sie noch fusionierte CUDA -Schichten wie Adam Optimizer und Layer -Normalisierung im Training verwenden.
Sie können in Google Colab trainiertes GPT2 -Modell spielen! Das obige Notizbuch enthält die Bewertung der Textgenerierung und Metriken. Sie müssen das geschulte Modell, das Vokabulardatei und das Bewertungsdatensatz in Google Cloud -Speicher hochladen.
Für die Menschen, die sich für koreanische Version von GPT2 interessieren, schreiben wir das obige Notizbuch um, um den Fall von gpt2-ko-302M -Modell anzubieten, das mit etwa 5,04B- Token aus koreanischen Dokumenten ausgebildet ist. Sie können in diesem Notebook Demo spielen.
Dieses Projekt ist apache-2.0 lizenziert.


