GPT2
Pretrained Korean GPT2
Modelos de idiomas são aprendizes multitarefa sem supervisão
Este projeto é uma implementação Pytorch do modelo OpenAI GPT-2. Ele fornece treinamento modelo, geração de frases e visualização de métricas. É considerado compreensível e otimizado. Projetamos os códigos para ser compreensível. Também usamos algumas técnicas para melhorar o desempenho.
Antes de treinar o modelo GPT-2, o conjunto de dados corpus deve ser preparado. Recomendamos construir seu próprio corpus usando o Expanda. Em vez disso, o módulo de treinamento requer conjuntos de dados de treinamento e avaliação tokenizados com seu arquivo de vocabulário.
Depois de preparar conjuntos de dados, você pode treinar o GPT-2 usando o seguinte:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Para retomar o treinamento do último arquivo do ponto de verificação, use --from_checkpoint [last checkpoint file] . Se você deseja treinar GPT-2 com várias GPUs, use --gpus [number of gpus] .
O detalhe do uso da linha de comando é o seguinte:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
Após o treinamento do GPT-2, você pode gerar frases com seu modelo treinado no modo interativo.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
O detalhe do uso da linha de comando é o seguinte:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Uma maneira de estimar o desempenho do modelo treinado é calcular as métricas objetivas com o conjunto de dados de avaliação, que não é usado durante a fase de treinamento.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
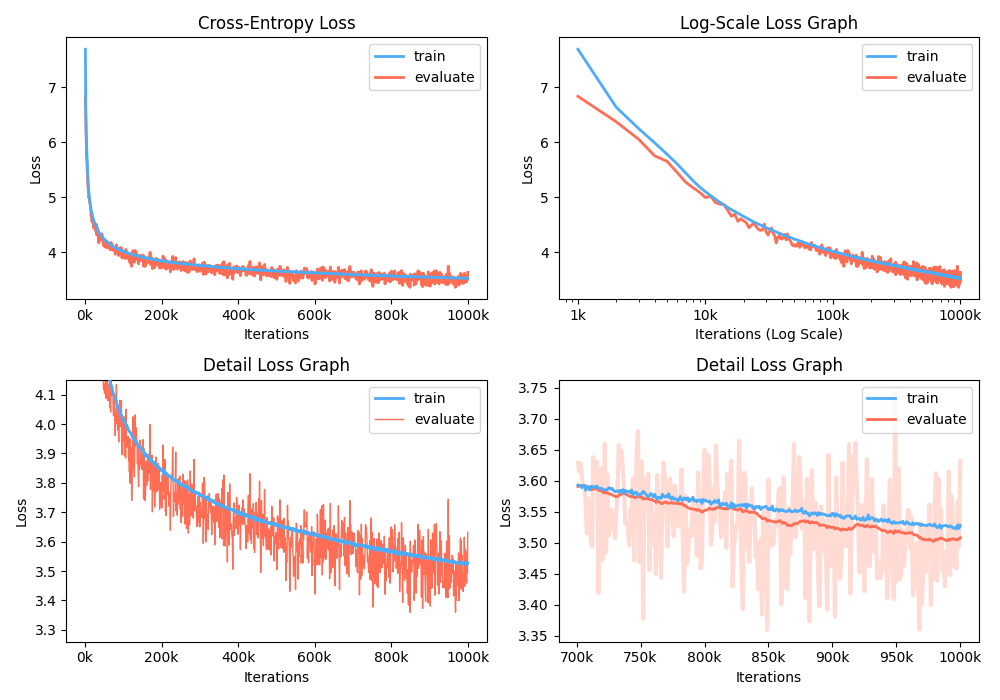
Além disso, você também pode analisar o gráfico de perda de treinamento visualizando métricas gravadas.
$ python -m gpt2 visualize --model_path model.pth --interactive
A figura de exemplo é tão abaixo:
Durante o treinamento, você pode usar o Nvidia Apex para usar camadas de CUDA fundidas e otimização de precisão mista. A opção --use_amp permite precisão mista automática no treinamento. Antes de usar esse impulso de desempenho, você deve instalar a biblioteca NVIDIA APEX seguindo o repositório ou executado:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Se você não puder instalar a biblioteca ou o seu dispositivo GPU não suporta treinamento rápido de precisão mista (precisamente, a GPU deve suportar a aceleração de precisão mista através de núcleos tensores), poderá treinar o modelo no modo de precisão única. O treinamento de precisão mista é uma opção. Nesse caso, você ainda pode usar camadas de CUDA fundidas, como Adam Optimizer e normalização de camadas no treinamento.
Você pode jogar modelo GPT2 treinado no Google Colab! O caderno acima contém geração de texto e avaliação de métricas. Você precisa fazer upload do modelo treinado, arquivo de vocabulário e conjunto de dados de avaliação para o Google Cloud Storage.
Para as pessoas interessadas em versões coreanas do GPT2, reescrevemos o notebook acima para fornecer o caso do modelo gpt2-ko-302M especialmente, que é treinado com cerca de 5,04b de documentos coreanos. Você pode jogar demonstração neste caderno.
Este projeto é licenciado Apache-2.0.


