GPT2
Pretrained Korean GPT2
言語モデルは、教師のないマルチタスク学習者です
このプロジェクトは、OpenAI GPT-2モデルのPytorch実装です。モデルトレーニング、文の生成、およびメトリックの視覚化を提供します。理解しやすく、最適化されていると考えられています。私たちは、理解できるようにコードを設計しました。また、パフォーマンスを改善するためにいくつかのテクニックを使用します。
GPT-2モデルをトレーニングする前に、コーパスデータセットを準備する必要があります。 Expandaを使用して、独自のコーパスを構築することをお勧めします。代わりに、トレーニングモジュールでは、語彙ファイルを使用してトークン化されたトレーニングと評価データセットが必要です。
データセットを準備した後、次のようにGPT-2をトレーニングできます。
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
最後のチェックポイントファイルからトレーニングを再開するには、 --from_checkpoint [last checkpoint file]オプションを使用します。複数のGPUでGPT-2をトレーニングする場合は、 --gpus [number of gpus]オプションを使用します。
コマンドライン使用の詳細は次のとおりです。
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
GPT-2をトレーニングした後、インタラクティブモードでトレーニングされたモデルを使用して文を生成できます。
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
コマンドライン使用の詳細は次のとおりです。
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
トレーニングされたモデルのパフォーマンスを推定する1つの方法は、トレーニングフェーズでは使用されない評価データセットで客観的なメトリックを計算することです。
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
さらに、記録されたメトリックを視覚化することにより、トレーニング損失グラフを分析することもできます。
$ python -m gpt2 visualize --model_path model.pth --interactive
例の数字は次のようになります:
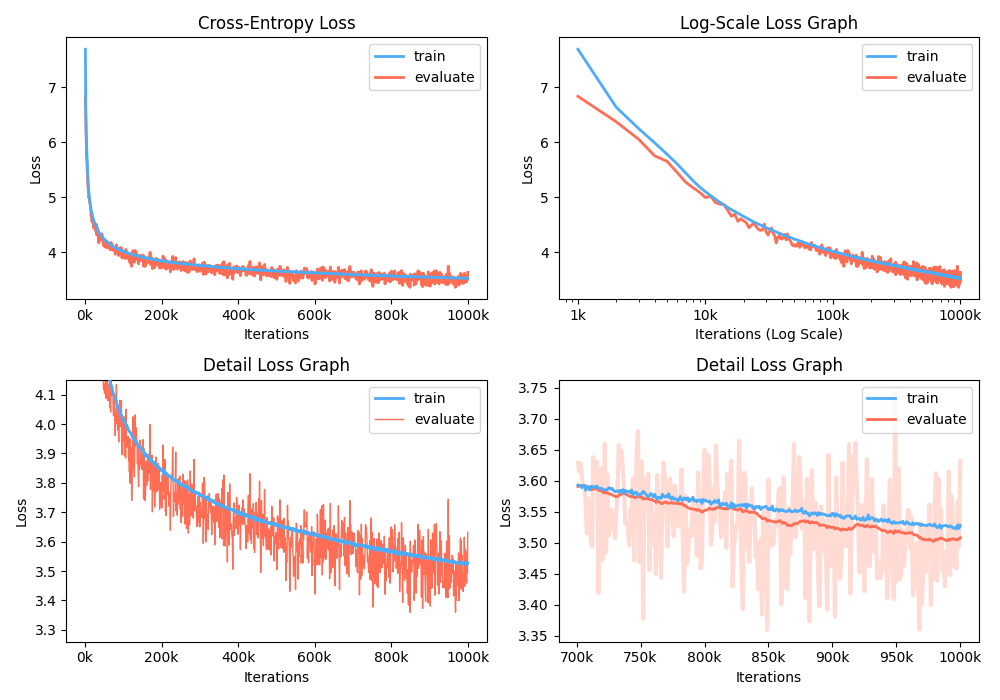
トレーニング中に、 Nvidia Apexを使用して、融合したCUDA層と混合精度の最適化を使用できます。オプション--use_amp 、トレーニングで自動混合精度を有効にします。これらのパフォーマンスブーストを使用する前に、リポジトリを追跡してNvidia Apexライブラリをインストールするか、次を実行する必要があります。
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
ライブラリまたはGPUデバイスをインストールできない場合、高速混合精度トレーニングをサポートしていない場合(正確には、GPUはテンソルコアを介して混合精度の加速をサポートする必要があります)、シングルエシジョンモードでモデルをトレーニングできます。混合精度トレーニングはオプションです。その場合、トレーニングでAdam Optimizerや層の正規化などの融合したCUDA層を使用できます。
Google Colabで訓練されたGPT2モデルをプレイできます!上記のノートには、テキスト生成とメトリックの評価が含まれています。訓練されたモデル、語彙ファイル、評価データセットをGoogle Cloudストレージにアップロードする必要があります。
韓国のGPT2のバージョンに興味がある人々のために、上記のノートブックを書き直して、韓国文書から約5.04bのトークンで訓練されたgpt2-ko-302Mモデルのケースを提供します。このノートブックでデモを再生できます。
このプロジェクトはApache-2.0ライセンスです。


