GPT2
Pretrained Korean GPT2
Los modelos de idiomas son alumnos multitarea no supervisados
Este proyecto es una implementación de Pytorch del modelo Operai GPT-2. Proporciona capacitación modelo, generación de oraciones y visualización de métricas. Se considera que es comprensible y optimizado. Diseñamos los códigos para ser comprensibles. También utilizamos algunas técnicas para mejorar el rendimiento.
Antes de entrenar al modelo GPT-2, se debe preparar el conjunto de datos de Corpus. Recomendamos construir su propio corpus utilizando la expansión. En cambio, el módulo de entrenamiento requiere conjuntos de datos de capacitación y evaluación tokenizados con su archivo de vocabulario.
Después de preparar conjuntos de datos, puede entrenar a GPT-2 usando lo siguiente:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Para reanudar la capacitación desde el último archivo de punto de control, use la opción --from_checkpoint [last checkpoint file] . Si desea entrenar GPT-2 con múltiples GPU, use la opción --gpus [number of gpus] .
El detalle del uso de la línea de comandos es el siguiente:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
Después de entrenar GPT-2, puede generar oraciones con su modelo entrenado en modo interactivo.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
El detalle del uso de la línea de comandos es el siguiente:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Una forma de estimar el rendimiento del modelo capacitado es calcular las métricas objetivas con el conjunto de datos de evaluación, que no se usa durante la fase de entrenamiento.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
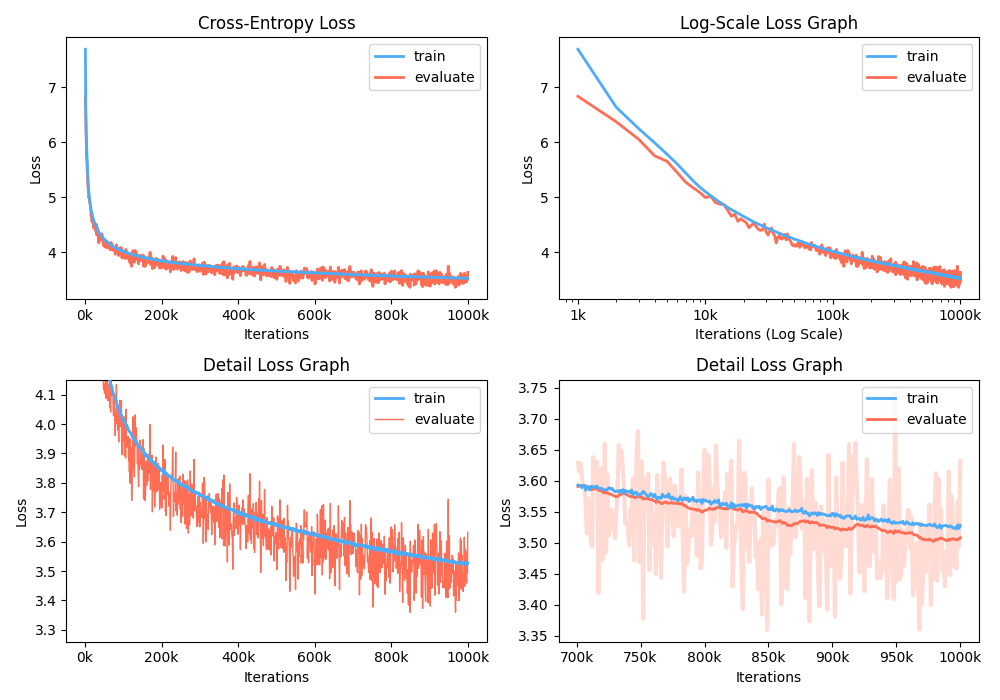
Además, también puede analizar el gráfico de pérdida de entrenamiento visualizando métricas grabadas.
$ python -m gpt2 visualize --model_path model.pth --interactive
La figura de ejemplo es tan a continuación:
Mientras está entrenando, puede usar Nvidia Apex para usar capas CUDA fusionadas y optimización de precisión mixta. La opción --use_amp habilita la precisión mixta automática en el entrenamiento. Antes de usar este aumento de rendimiento, debe instalar la biblioteca NVIDIA APEX siguiendo el repositorio o ejecutar belows:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Si no puede instalar la biblioteca o su dispositivo GPU no admite un entrenamiento de precisión mixta rápida (precisamente, GPU debe admitir la aceleración de precisión mixta a través de núcleos de tensor), puede entrenar el modelo en modo de precisión única. El entrenamiento de precisión mixta es una opción. En ese caso, aún puede usar capas CUDA fusionadas como Adam Optimizer y la normalización de la capa en el entrenamiento.
¡Puedes jugar al modelo GPT2 entrenado en Google Colab! El cuaderno anterior contiene la evaluación de la generación de texto y las métricas. Debe cargar el modelo capacitado, el archivo de vocabulario y el conjunto de datos de evaluación en Google Cloud Storage.
Para las personas interesadas en la versión coreana de GPT2, reescribimos el cuaderno anterior para proporcionar el caso del modelo gpt2-ko-302M especialmente, que está capacitado con tokens de aproximadamente 5.04B de documentos coreanos. Puedes jugar una demostración en este cuaderno.
Este proyecto tiene licencia apache-2.0.


