GPT2
Pretrained Korean GPT2
نماذج اللغة متعلمين متعددة المهام غير خاضعة للإشراف
هذا المشروع هو تطبيق Pytorch لنموذج Openai GPT-2. ويوفر التدريب النموذجي ، وتوليد الجملة ، وتصور المقاييس. يعتبر مفهومة ومحسّنة. لقد صممنا الرموز لتكون مفهومة. كما نستخدم بعض التقنيات لتحسين الأداء.
قبل تدريب نموذج GPT-2 ، يجب إعداد مجموعة بيانات Corpus. نوصي ببناء مجموعة خاصة بك باستخدام Exploya. بدلاً من ذلك ، تتطلب وحدة التدريب مجموعات بيانات التدريب والتقييم المميز مع ملف المفردات.
بعد إعداد مجموعات البيانات ، يمكنك تدريب GPT-2 باستخدام ما يلي:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
لاستئناف التدريب من ملف نقطة التفتيش الأخيرة ، استخدم -من خيار --from_checkpoint [last checkpoint file] . إذا كنت ترغب في تدريب GPT-2 مع وحدات معالجة الرسومات المتعددة ، فاستخدم- --gpus [number of gpus] .
تفاصيل استخدام سطر الأوامر هي كما يلي:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
بعد تدريب GPT-2 ، يمكنك إنشاء جمل باستخدام نموذجك المدرب في الوضع التفاعلي.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
تفاصيل استخدام سطر الأوامر هي كما يلي:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
تتمثل إحدى طرق تقدير أداء النموذج المدربين في حساب المقاييس الموضوعية مع مجموعة بيانات التقييم ، والتي لا تستخدم خلال مرحلة التدريب.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
علاوة على ذلك ، يمكنك أيضًا تحليل الرسم البياني لفقدان التدريب من خلال تصور المقاييس المسجلة.
$ python -m gpt2 visualize --model_path model.pth --interactive
الشكل المثالي هو مشرب:
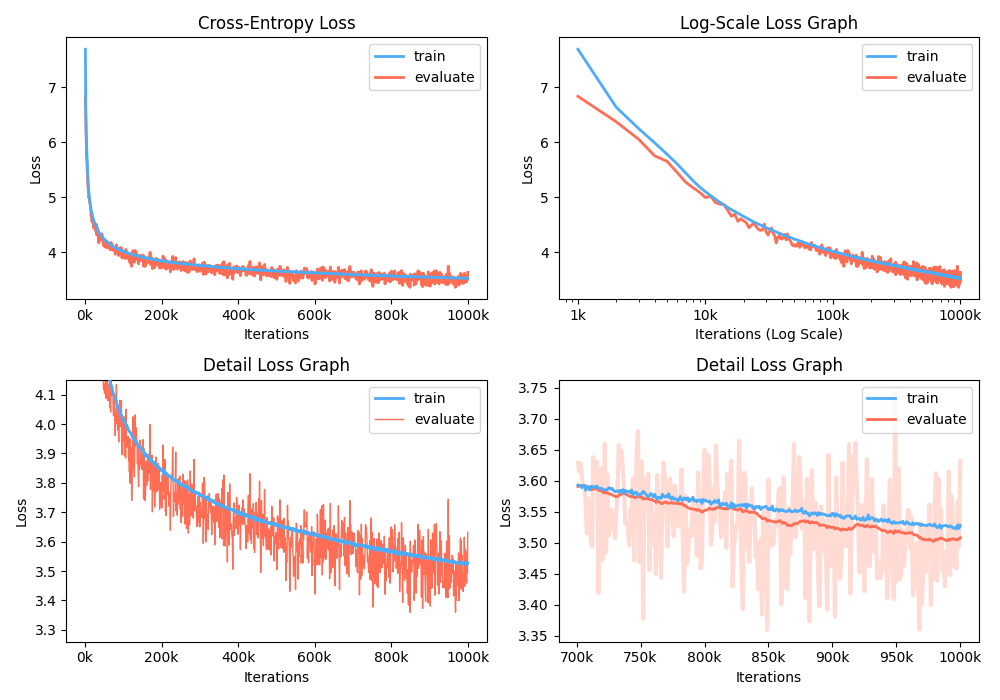
أثناء التدريب ، يمكنك استخدام Nvidia Apex لاستخدام طبقات CUDA المنصهرة والتحسين المختلط. الخيار --use_amp يتيح الدقة المختلطة التلقائية في التدريب. قبل استخدام تعزيز الأداء هذه ، يجب عليك تثبيت مكتبة Nvidia Apex باتباع المستودع ، أو تشغيل Belows:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
إذا لم تتمكن من تثبيت المكتبة أو لا يدعم جهاز GPU الخاص بك التدريب السريع المختلط (على وجه التحديد ، يجب أن تدعم GPU تسارعًا مختلطًا من خلال توتر النوى) ، يمكنك تدريب النموذج في وضع الدقة الواحدة. التدريب المختلط هو خيار. في هذه الحالة ، لا يزال بإمكانك استخدام طبقات CUDA المنصهرة مثل Adam Optimizer وتطبيع الطبقة في التدريب.
يمكنك لعب نموذج GPT2 المدربين في Google Colab! يحتوي دفتر الملاحظات أعلاه على توليد النص وتقييم المقاييس. تحتاج إلى تحميل مجموعة بيانات المفردات المدربة وملف المفردات ومجموعة بيانات التقييم إلى Google Cloud Storage.
بالنسبة للأشخاص المهتمين بالنسف الكوري لـ GPT2 ، نعيد كتابة دفتر الملاحظات أعلاه لتوفير قضية نموذج gpt2-ko-302M وخاصة ، والذي يتم تدريبه بحوالي 5.04B الرموز من الوثائق الكورية. يمكنك تشغيل العرض التوضيحي في هذا الكمبيوتر الدفتري.
هذا المشروع مرخص Apache-2.0.


