GPT2
Pretrained Korean GPT2
Les modèles de langage sont des apprenants multitâches non sortis
Ce projet est une implémentation Pytorch du modèle Openai GPT-2. Il offre une formation modèle, une génération de phrases et une visualisation des métriques. Il est considéré comme à la fois compréhensible et optimisé. Nous avons conçu les codes pour être compréhensibles. Nous utilisons également certaines techniques pour améliorer les performances.
Avant d'entraîner le modèle GPT-2, l'ensemble de données du corpus doit être préparé. Nous vous recommandons de construire votre propre corpus en utilisant Expanda. Au lieu de cela, le module de formation nécessite des ensembles de données de formation et d'évaluation tokenisés avec leur fichier de vocabulaire.
Après avoir préparé des ensembles de données, vous pouvez entraîner GPT-2 en utilisant comme suit:
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
Pour reprendre la formation du dernier fichier de point de contrôle, utilisez --from_checkpoint [last checkpoint file] . Si vous souhaitez former GPT-2 avec plusieurs GPU, utilisez l'option --gpus [number of gpus] .
Le détail de l'utilisation de la ligne de commande est le suivant:
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
Après avoir entraîné le GPT-2, vous pouvez générer des phrases avec votre modèle formé en mode interactif.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
Le détail de l'utilisation de la ligne de commande est le suivant:
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
Une façon d'estimer les performances du modèle formé est de calculer les mesures objectives avec un ensemble de données d'évaluation, qui n'est pas utilisée pendant la phase de formation.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
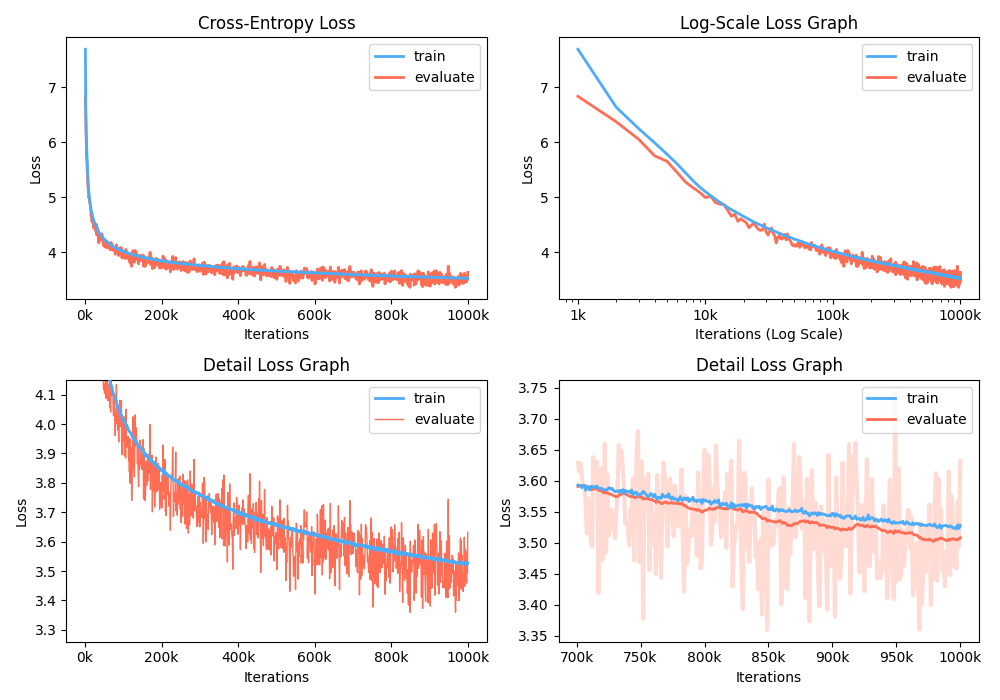
De plus, vous pouvez également analyser le graphique de perte de formation en visualisant les mesures enregistrées.
$ python -m gpt2 visualize --model_path model.pth --interactive
La figure d'exemple est aussi ci-dessous:
Pendant la formation, vous pouvez utiliser Nvidia Apex pour utiliser les couches CUDA fusionnées et l'optimisation de précision mixte. L'option --use_amp permet une précision mixte automatique en formation. Avant d'utiliser ce renforcement des performances, vous devez installer la bibliothèque Nvidia Apex en suivant le référentiel, ou exécuter des velours:
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Si vous ne pouvez pas installer la bibliothèque ou si votre appareil GPU ne prend pas en charge une formation rapide à précision mixte (précisément, GPU devrait prendre en charge l'accélération de précision mixte via les noyaux du tenseur), vous pouvez former le modèle en mode unique. La formation de précision mixte est une option. Dans ce cas, vous pouvez toujours utiliser des couches CUDA fusionnées telles que Adam Optimizer et la normalisation des couches en formation.
Vous pouvez jouer au modèle GPT2 formé dans Google Colab! Le cahier ci-dessus contient la génération de texte et l'évaluation des métriques. Vous devez télécharger le modèle formé, le fichier de vocabulaire et l'ensemble de données d'évaluation sur Google Cloud Storage.
Pour les personnes qui s'intéressent à la version coréenne de GPT2, nous réécrivons le cahier ci-dessus pour fournir le cas du modèle gpt2-ko-302M en particulier, qui est formé avec environ 5,04b des jetons à partir de documents coréens. Vous pouvez jouer à la démo dans ce cahier.
Ce projet est licencié Apache-2.0.


