GPT2
Pretrained Korean GPT2
언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다
이 프로젝트는 OpenAI GPT-2 모델의 Pytorch 구현입니다. 모델 교육, 문장 생성 및 메트릭 시각화를 제공합니다. 이해할 수 있고 최적화 된 것으로 간주됩니다. 우리는 코드를 이해할 수 있도록 설계했습니다. 또한 성능을 향상시키기 위해 몇 가지 기술을 사용합니다.
GPT-2 모델을 교육하기 전에 Corpus 데이터 세트를 준비해야합니다. Expanda를 사용하여 자신의 코퍼스를 구축하는 것이 좋습니다. 대신 교육 모듈에는 어휘 파일을 사용하여 토큰 화 된 교육 및 평가 데이터 세트가 필요합니다.
데이터 세트를 준비한 후에는 다음과 같이 사용하여 GPT-2를 훈련시킬 수 있습니다.
$ python -m gpt2 train --train_corpus build/corpus.train.txt
--eval_corpus build/corpus.test.txt
--vocab_path build/vocab.txt
--save_checkpoint_path ckpt-gpt2.pth
--save_model_path gpt2-pretrained.pth
--batch_train 128
--batch_eval 128
--seq_len 64
--total_steps 1000000
--eval_steps 500
--save_steps 5000
마지막 체크 포인트 파일에서 교육을 재개하려면 --from_checkpoint [last checkpoint file] 옵션을 사용하십시오. 여러 GPU로 GPT-2를 훈련 시키려면 --gpus [number of gpus] 옵션을 사용하십시오.
명령 줄 사용의 세부 사항은 다음과 같습니다.
usage: gpt2 train [-h] --train_corpus TRAIN_CORPUS --eval_corpus EVAL_CORPUS
--vocab_path VOCAB_PATH [--seq_len SEQ_LEN]
[--layers LAYERS] [--heads HEADS] [--dims DIMS]
[--rate RATE] [--dropout DROPOUT]
[--batch_train BATCH_TRAIN] [--batch_eval BATCH_EVAL]
[--base_lr BASE_LR] [--wd_rate WD_RATE]
[--total_steps TOTAL_STEPS] [--eval_steps EVAL_STEPS]
[--save_steps SAVE_STEPS]
[--save_model_path SAVE_MODEL_PATH]
[--save_checkpoint_path SAVE_CHECKPOINT_PATH]
[--from_checkpoint FROM_CHECKPOINT]
[--from_pretrained FROM_PRETRAINED] [--use_amp]
[--use_grad_ckpt] [--gpus GPUS]
optional arguments:
-h, --help show this help message and exit
Corpus and vocabulary:
--train_corpus TRAIN_CORPUS
training corpus file path
--eval_corpus EVAL_CORPUS
evaluation corpus file path
--vocab_path VOCAB_PATH
vocabulary file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
--dropout DROPOUT probability that each element is dropped
Training and evaluation:
--batch_train BATCH_TRAIN
number of training batch size
--batch_eval BATCH_EVAL
number of evaluation batch size
--base_lr BASE_LR default learning rate
--wd_rate WD_RATE weight decay rate
--total_steps TOTAL_STEPS
number of total training steps
--eval_steps EVAL_STEPS
period to evaluate model and record metrics
--save_steps SAVE_STEPS
period to save training state to checkpoint
Saving and restoring:
--save_model_path SAVE_MODEL_PATH
save trained model weights to the file
--save_checkpoint_path SAVE_CHECKPOINT_PATH
save training state to the checkpoint file
--from_checkpoint FROM_CHECKPOINT
load last training state from checkpoint file
--from_pretrained FROM_PRETRAINED
initialize parameters from pretrained model
Extensions:
--use_amp use automatic mixed-precision in training
--use_grad_ckpt use gradient checkpointing in transformer layers
--gpus GPUS number of gpu devices to use in training
GPT-2를 훈련 한 후에는 대화 형 모드에서 훈련 된 모델로 문장을 생성 할 수 있습니다.
$ python -m gpt2 generate --vocab_path build/vocab.txt
--model_path model.pth
--seq_len 64
--nucleus_prob 0.8
명령 줄 사용의 세부 사항은 다음과 같습니다.
usage: gpt2 generate [-h] --vocab_path VOCAB_PATH --model MODEL
[--seq_len SEQ_LEN] [--layers LAYERS] [--heads HEADS]
[--dims DIMS] [--rate RATE] [--top_p TOP_P] [--use_gpu]
optional arguments:
-h, --help show this help message and exit
--vocab_path VOCAB_PATH
vocabulary file path
--model_path MODEL_PATH
trained GPT-2 model file path
Model configurations:
--seq_len SEQ_LEN maximum sequence length
--layers LAYERS number of transformer layers
--heads HEADS number of multi-heads in attention layer
--dims DIMS dimension of representation in each layer
--rate RATE increase rate of dimensionality in bottleneck
Generating options:
--nucleus_prob NUCLEUS_PROB
probability threshold for nucleus sampling
--use_gpu use gpu device in inferencing
훈련 된 모델의 성능을 추정하는 한 가지 방법은 훈련 단계에서 사용되지 않는 평가 데이터 세트로 목표 지표를 계산하는 것입니다.
$ python -m gpt2 evaluate --model_path model.pth --eval_corpus corpus.test.txt --vocab_path vocab.txt
또한 기록 된 메트릭을 시각화하여 교육 손실 그래프를 분석 할 수도 있습니다.
$ python -m gpt2 visualize --model_path model.pth --interactive
예제는 벨로우즈입니다.
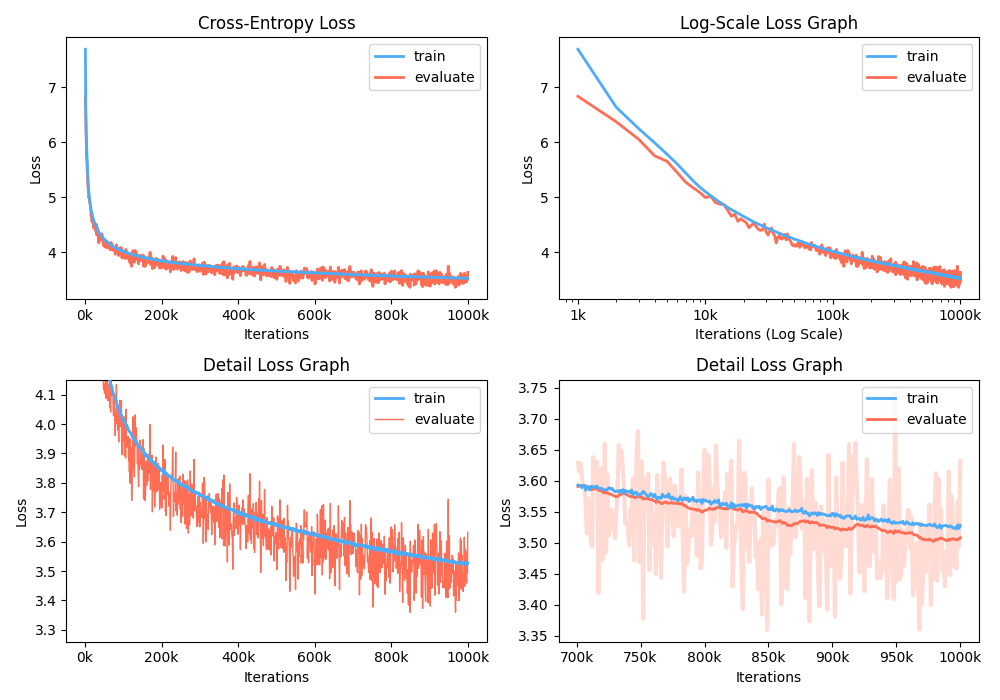
훈련하는 동안 NVIDIA APEX를 사용하여 퓨즈 CUDA 층과 혼합 정제 최적화를 사용할 수 있습니다. 옵션 --use_amp 는 교육에서 자동 혼합 정밀도를 활성화합니다. 이러한 성능 향상을 사용하기 전에 저장소를 따라 NVIDIA APEX 라이브러리를 설치하거나 벨리즈를 실행해야합니다.
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
라이브러리를 설치할 수 없거나 GPU 장치가 빠른 혼합 정밀 교육을 지원하지 않는 경우 (정확하게, GPU는 텐서 코어를 통한 혼합 정제 가속도를 지원해야 함) 단일 정밀 모드로 모델을 교육 할 수 있습니다. 혼합 정제 교육은 옵션입니다. 이 경우 훈련에서 Adam Optimizer 및 Layer Normalization과 같은 퓨즈 CUDA 층을 사용할 수 있습니다.
Google Colab에서 숙련 된 GPT2 모델을 재생할 수 있습니다! 위의 노트에는 텍스트 생성 및 메트릭 평가가 포함되어 있습니다. 훈련 된 모델, 어휘 파일 및 평가 데이터 세트를 Google Cloud Storage에 업로드해야합니다.
GPT2의 한국 버전에 관심이있는 사람들을 위해, 우리는 위의 노트북을 다시 작성하여 특히 gpt2-ko-302M 모델의 사례를 제공하며, 이는 한국 문서의 약 5.04B 토큰으로 훈련됩니다. 이 노트북에서 데모를 재생할 수 있습니다.
이 프로젝트는 Apache-2.0 라이센스입니다.


