functionary
1.0.0

Фунтатор - это языковая модель, которая может интерпретировать и выполнять функции/плагины.
Модель определяет, когда выполнять функции, параллельно или последовательно, и может понять их выходы. Это только запускает функции по мере необходимости. Определения функций приведены как объекты схемы JSON, аналогичные вызовам функций OpenAI GPT.
Документация и больше примеров: funcary.metkai.com
{type: "code_interpreter"} в инструментах)! Функциональный может быть развернут с помощью наших серверов VLLM или SGLANG. Выберите любой из них в зависимости от ваших предпочтений.
vllm
pip install -e .[vllm]Sglang
pip install -e .[sglang] --find-links https://flashinfer.ai/whl/cu121/torch2.4/flashinfer/vllm
python3 server_vllm.py --model " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --max-model-len 8192Sglang
python3 server_sglang.py --model-path " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --context-length 8192 Наши средние модели требуют: 4xa6000 или 2xa100 80 ГБ для работы, необходимость использования: tensor-parallel-size или tp (Sglang)
vllm
# vllm requires to run this first: https://github.com/vllm-project/vllm/issues/6152
export VLLM_WORKER_MULTIPROC_METHOD=spawn
python server_vllm.py --model " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --max-model-len 8192 --tensor-parallel-size 2Sglang
python server_sglang.py --model-path " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --context-length 8192 --tp 2Подобно Лоре в VLLM, наш сервер поддерживает обслуживание адаптеров LORA как в стартапе, так и динамически.
Чтобы обслуживать адаптер LORA при запуске, запустите сервер с аргументом --lora-modules :
python server_vllm.py --model {BASE_MODEL} --enable-lora --lora-modules {name}={path} {name}={path} --host 0.0.0.0 --port 8000 Чтобы динамически обслуживать адаптер LORA, используйте конечную точку /v1/load_lora_adapter :
python server_vllm.py --model {BASE_MODEL} --enable-lora --host 0.0.0.0 --port 8000
# Load a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/load_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora",
"lora_path": "/path/to/my_lora_adapter"
} '
# Example chat request to lora adapter
curl -X POST http://localhost:8000/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "my_lora",
"messages": [...],
"tools": [...],
"tool_choice": "auto"
} '
# Unload a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/unload_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora"
} ' Мы также предлагаем нашу собственную функцию отбора проб грамматики, которая ограничивает генерацию LLM, чтобы всегда следовать шаблону быстрого приглашения и обеспечивает 100% точность для имени функции. Параметры генерируются с использованием эффективного LM-формата-энфорчика, который гарантирует, что параметры следуют за схемой инструмента, называемого. Чтобы включить выборку грамматики, запустите VLLM-сервер с аргументом командной строки --enable-grammar-sampling :
python3 server_vllm.py --model " meetkai/functionary-medium-v3.1 " --max-model-len 8192 --tensor-parallel-size 2 --enable-grammar-samplingПРИМЕЧАНИЕ. Поддержка отбора проб грамматики применима только для моделей V2, V3.0, V3.2. Там нет такой поддержки моделей V1 и V3.1.
Мы также предоставляем услугу, которая выполняет вывод на функциональные модели, используя инференцию Text Generation (TGI). Следуйте этим шагам, чтобы начать:
Установите Docker после их инструкций по установке.
Установите Docker SDK для Python
pip install dockerПри запуске функциональный сервер TGI пытается подключиться к существующей конечной точке TGI. В этом случае вы можете запустить следующее:
python3 server_tgi.py --model < REMOTE_MODEL_ID_OR_LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT > Если конечная точка TGI не существует, функциональный сервер TGI запустит новый контейнер с конечной точкой TGI с адресом, указанным в аргументе CLI endpoint через установленную Docker Python SDK. Запустите следующие команды для удаленных и локальных моделей соответственно:
python3 server_tgi.py --model < REMOTE_MODEL_ID > --remote_model_save_folder < PATH_TO_SAVE_AND_CACHE_REMOTE_MODEL > --endpoint < TGI_SERVICE_ENDPOINT > python3 server_tgi.py --model < LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT >Докер
Если у вас проблемы с зависимостями, и у вас есть nvidia-container-toolkit, вы можете начать свою среду так:
sudo docker run --gpus all -it --ipc=host --name functionary -v ${PWD} /functionary_workspace:/workspace -p 8000:8000 nvcr.io/nvidia/pytorch:23.10-py3 from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" , api_key = "functionary" )
client . chat . completions . create (
model = "meetkai/functionary-small-v3.2" ,
messages = [{ "role" : "user" ,
"content" : "What is the weather for Istanbul?" }
],
tools = [{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}],
tool_choice = "auto"
) import requests
data = {
'model' : 'meetkai/functionary-small-v3.2' , # model name here is the value of argument "--model" in deploying: server_vllm.py or server.py
'messages' : [
{
"role" : "user" ,
"content" : "What is the weather for Istanbul?"
}
],
'tools' :[ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
}
response = requests . post ( "http://127.0.0.1:8000/v1/chat/completions" , json = data , headers = {
"Content-Type" : "application/json" ,
"Authorization" : "Bearer xxxx"
})
# Print the response text
print ( response . text )| Модель | Описание | VRAM FP16 |
|---|---|---|
| функциональный средний V3.2 | Контекст 128K, интерпретатор кода, используя наш собственный шаблон | 160 ГБ |
| Funcary-Small-V3.2 / GGUF | Контекст 128K, интерпретатор кода, используя наш собственный шаблон | 24 ГБ |
| функциональный средний V3.1 / GGUF | Контекст 128K, интерпретатор кода, используя оригинальный шаблон приглашения Meta | 160 ГБ |
| Funcary-Small-V3.1 / GGUF | Контекст 128K, интерпретатор кода, используя оригинальный шаблон приглашения Meta | 24 ГБ |
| функциональный средний V3.0 / GGUF | 8K контекст, основанный на мета-лама/мета-3-70B-инструкторе | 160 ГБ |
| Funcary-Small-V2.5 / GGUF | 8K контекст, интерпретатор кода | 24 ГБ |
| Funcary-Small-V2.4 / GGUF | 8K контекст, интерпретатор кода | 24 ГБ |
| функциональный средний V2.4 / gguf | 8K контекст, интерпретатор кода, лучшая точность | 90 ГБ |
| Funcary-Small-V2.2 / GGUF | 8k контекста | 24 ГБ |
| функциональный средний V2.2 / GGUF | 8k контекста | 90 ГБ |
| Funcary-7b-V2.1 / gguf | 8k контекста | 24 ГБ |
| Функционар-7B-V2 / GGUF | Поддержка вызова параллельных функций. | 24 ГБ |
| Функционар-7B-V1.4 / GGUF | 4K контекст, лучшая точность (устарела) | 24 ГБ |
| Функционар-7B-V1.1 | 4K контекст (устаревший) | 24 ГБ |
| Функционар-7B-V0.1 | Контекст 2K (устаревший) не рекомендуется, используйте 2.1 далее | 24 ГБ |
Разница между Openai-Python V0 и V1 вы можете ссылаться на официальную документацию здесь
| Функция/проект | Функциональный | Nexusraven | Горилла | Глейв | GPT-4-1106-Preview |
|---|---|---|---|---|---|
| Однофункциональный вызов | ✅ | ✅ | ✅ | ✅ | ✅ |
| Вызовы параллельных функций | ✅ | ✅ | ✅ | ✅ | |
| Следуя аргументам отсутствующих функций | ✅ | ✅ | |||
| Многообразие | ✅ | ✅ | ✅ | ||
| Генерировать ответы модели, основанные на результатах выполнения инструментов | ✅ | ✅ | |||
| Чит-чат | ✅ | ✅ | ✅ | ✅ | |
| Переводчик кода | ✅ | ✅ |
Вы можете найти более подробную информацию о функциях здесь
Пример для вывода с использованием llama-cpp-python можно найти в: llama_cpp_inference.py.
Кроме того, функции также был интегрирован в Llama-Cpp-Python, однако интеграция может не быть быстро обновлена , поэтому, если в результате что-то не так или странно, используйте: вместо этого используйте: llama_cpp_inference.py. В настоящее время v2.5 не был интегрирован, поэтому, если вы используете Funcary-Small-V2.5-Gguf , используйте: llama_cpp_infere.py
Убедитесь, что последняя версия Llama-CPP-Python успешно установлена в вашей системе. Функциональный V2 полностью интегрирован в Llama-Cpp-Python. Вы можете выполнить вывод, используя модели GGUF функционара либо через нормальное завершение чата, либо через сервер, совместимый с Llama-CPP-Python, который ведет себя аналогично нашим.
Ниже приведен пример кода с использованием нормального завершения чата:
from llama_cpp import Llama
from llama_cpp . llama_tokenizer import LlamaHFTokenizer
# We should use HF AutoTokenizer instead of llama.cpp's tokenizer because we found that Llama.cpp's tokenizer doesn't give the same result as that from Huggingface. The reason might be in the training, we added new tokens to the tokenizer and Llama.cpp doesn't handle this successfully
llm = Llama . from_pretrained (
repo_id = "meetkai/functionary-small-v2.4-GGUF" ,
filename = "functionary-small-v2.4.Q4_0.gguf" ,
chat_format = "functionary-v2" ,
tokenizer = LlamaHFTokenizer . from_pretrained ( "meetkai/functionary-small-v2.4-GGUF" ),
n_gpu_layers = - 1
)
messages = [
{ "role" : "user" , "content" : "what's the weather like in Hanoi?" }
]
tools = [ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g., San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
result = llm . create_chat_completion (
messages = messages ,
tools = tools ,
tool_choice = "auto" ,
)
print ( result [ "choices" ][ 0 ][ "message" ])Вывод будет:
{ 'role' : 'assistant' , 'content' : None , 'tool_calls' : [{ 'type' : 'function' , 'function' : { 'name' : 'get_current_weather' , 'arguments' : '{ n "location": "Hanoi" n }' }}]}Для получения более подробной информации, пожалуйста, обратитесь к разделу вызова функции в Llama-Cpp-Python. Чтобы использовать наши функциональные модели GGUF с использованием сервера, совместимого с Llama-CPP-Python, обратитесь к более подробной информации и документации.
Примечание:
messages .Чтобы вызвать реальную функцию Python, получить результат и извлечь результат для ответа, вы можете использовать Chatlab. В следующем примере используется Chatlab == 0.16.0:
Обратите внимание, что Chatlab в настоящее время не поддерживает параллельные вызовы функций. Этот пример кода совместим только с функциональной версией 1.4 и может неправильно работать с функциональной версией 2.0.
from chatlab import Conversation
import openai
import os
openai . api_key = "functionary" # We just need to set this something other than None
os . environ [ 'OPENAI_API_KEY' ] = "functionary" # chatlab requires us to set this too
openai . api_base = "http://localhost:8000/v1"
# now provide the function with description
def get_car_price ( car_name : str ):
"""this function is used to get the price of the car given the name
:param car_name: name of the car to get the price
"""
car_price = {
"tang" : { "price" : "$20000" },
"song" : { "price" : "$25000" }
}
for key in car_price :
if key in car_name . lower ():
return { "price" : car_price [ key ]}
return { "price" : "unknown" }
chat = Conversation ( model = "meetkai/functionary-7b-v2" )
chat . register ( get_car_price ) # register this function
chat . submit ( "what is the price of the car named Tang?" ) # submit user prompt
# print the flow
for message in chat . messages :
role = message [ "role" ]. upper ()
if "function_call" in message :
func_name = message [ "function_call" ][ "name" ]
func_param = message [ "function_call" ][ "arguments" ]
print ( f" { role } : call function: { func_name } , arguments: { func_param } " )
else :
content = message [ "content" ]
print ( f" { role } : { content } " )Вывод будет выглядеть так:
USER: what is the price of the car named Tang?
ASSISTANT: call function: get_car_price, arguments:{
"car_name": "Tang"
}
FUNCTION: {'price': {'price': '$20000'}}
ASSISTANT: The price of the car named Tang is $20,000.
Без сервера развертывание функциональных моделей поддерживается через сценарий modal_server_vllm.py . После регистрации и установки модала выполните эти шаги, чтобы развернуть наш сервер VLLM на Modal:
modal environment create devЕсли у вас уже создана среда Dev, нет необходимости создавать еще одну. Просто настройте на него на следующем шаге.
modal config set-environment devmodal serve modal_server_vllmmodal deploy modal_server_vllmВот несколько примеров того, как вы можете использовать эту систему вызова функции:
Функция plan_trip(destination: string, duration: int, interests: list) может принять пользовательский ввод, такой как «Я хочу спланировать 7-дневную поездку в Париж с акцентом на искусство и культуру» и соблюдать маршрут соответственно.
client . chat . completions . create ((
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'I want to plan a 7-day trip to Paris with a focus on art and culture' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "plan_trip" ,
"description" : "Plan a trip based on user's interests" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"destination" : {
"type" : "string" ,
"description" : "The destination of the trip" ,
},
"duration" : {
"type" : "integer" ,
"description" : "The duration of the trip in days" ,
},
"interests" : {
"type" : "array" ,
"items" : { "type" : "string" },
"description" : "The interests based on which the trip will be planned" ,
},
},
"required" : [ "destination" , "duration" , "interests" ],
}
}
}
]
)Ответ будет иметь:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Затем вам нужно позвонить в функцию plan_trip с предоставленными аргументами. Если вы хотите комментарий от модели, то вы снова позвоните в модель с ответом от функции, модель напишет необходимый комментарий.
Такая функция, как exatime_property_value (Property_details: DICT), может позволить пользователям вводить подробную информацию о свойстве (например, место, размер, количество номеров и т. Д.) И получать оценочную рыночную стоимость.
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{
"role" : "user" ,
"content" : 'What is the estimated value of a 3-bedroom house in San Francisco with 2000 sq ft area?'
},
{
"role" : "assistant" ,
"content" : None ,
"tool_calls" : [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"arguments" : '{ n "property_details": {"location": "San Francisco", "size": 2000, "rooms": 3} n }'
}
}
]
}
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"description" : "Estimate the market value of a property" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"property_details" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The location of the property"
},
"size" : {
"type" : "integer" ,
"description" : "The size of the property in square feet"
},
"rooms" : {
"type" : "integer" ,
"description" : "The number of rooms in the property"
}
},
"required" : [ "location" , "size" , "rooms" ]
}
},
"required" : [ "property_details" ]
}
}
}
],
tool_choice = "auto"
)Ответ будет иметь:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Затем вам нужно позвонить в функцию plan_trip с предоставленными аргументами. Если вам нужен комментарий из модели, то вы снова позвоните в модель с ответом от функции, модель напишет необходимый комментарий.
Функция parse_customer_complaint(complaint: {issue: string, frequency: string, duration: string}) может помочь в извлечении структурированной информации из сложной, повествовательной жалобы клиента, определения основной проблемы и потенциальных решений. Объект complaint может включать такие свойства, как issue (основная проблема), frequency (как часто возникает проблема) и duration (как долго возникала проблема).
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'My internet has been disconnecting frequently for the past week' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "parse_customer_complaint" ,
"description" : "Parse a customer complaint and identify the core issue" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"complaint" : {
"type" : "object" ,
"properties" : {
"issue" : {
"type" : "string" ,
"description" : "The main problem" ,
},
"frequency" : {
"type" : "string" ,
"description" : "How often the issue occurs" ,
},
"duration" : {
"type" : "string" ,
"description" : "How long the issue has been occurring" ,
},
},
"required" : [ "issue" , "frequency" , "duration" ],
},
},
"required" : [ "complaint" ],
}
}
}
],
tool_choice = "auto"
)Ответ будет иметь:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " parse_customer_complaint " , "arguments" : '{n "complaint": {"issue": "internet disconnecting", "frequency": "frequently", "duration": "past week" } n } '}} ]}Затем вам нужно вызвать функцию parse_customer_complaint с предоставленными аргументами. Если вы хотите комментарий от модели, то вы снова позвоните в модель с ответом от функции, модель напишет необходимый комментарий.
Мы преобразуем определения функций в аналогичный текст в определениях типографии. Затем мы вводим эти определения в качестве подсказки системы. После этого мы вводим подсказку системы по умолчанию. Затем мы начинаем разговорные сообщения.
Пример приглашения можно найти здесь: v1 (v1.4), v2 (v2, v2.1, v2.2, v2.4) и v2.llama3 (v2.5)
Мы не меняем вероятности логита, чтобы соответствовать определенной схеме, но сама модель знает, как соответствовать. Это позволяет нам легко использовать существующие инструменты и системы кэширования.
Мы занимаем второе место в списке лидеров в Беркли (последнее обновление: 2024-08-11)
| Название модели | Точность вызова функции (имя и аргументы) |
|---|---|
| Meetkai/функциональный средний V3.1 | 88,88% |
| GPT-4-1106-Preview (Приглашение) | 88,53% |
| Meetkai/Funcary-Small-V3.2 | 82,82% |
| Meetkai/Funcary-Small-V3.1 | 82,53% |
| Firefunction-V2 (FC) | 78,82,47% |
Мы также оцениваем наши модели по инструментам и коробку, этот эталон гораздо сложнее, чем в таблице лидеров Berkeley . Этот эталон включает в себя выполнение состояния инструмента, неявные зависимости состояния между инструментами, встроенный симулятор пользователей, поддерживающий динамическую оценку на политике и стратегию динамической оценки для промежуточных и конечных этапов по произвольной траектории. Авторы этого эталона показали, что между моделями с открытым исходным кодом и запатентованными моделями существует огромный разрыв в производительности.
Из нашего результата оценки наши модели сопоставимы с лучшими проприетарными моделями и намного лучше, чем другие модели с открытым исходным кодом.
| Название модели | Средний показатель сходства |
|---|---|
| GPT-4o-2024-05-13 | 73 |
| Claude-3-Opus-201240229 | 69,2 |
| Функциональный средний V3.1 | 68,87 |
| GPT-3.5-Turbo-0125 | 65,6 |
| GPT-4-0125-Preview | 64.3 |
| Claude-3-Sonnet-20240229 | 63,8 |
| Функционар-SMALL-V3.1 | 63.13 |
| Близнецы-1,5-про-001 | 60.4 |
| Функционар-SMALL-V3.2 | 58.56 |
| Claude-3-haiku-201240307 | 54,9 |
| Близнецы-1,0-про | 38.1 |
| Hermes-2-pro-mistral-7b | 31.4 |
| MISTRAL-7B-INSTRUCT-V0.3 | 29,8 |
| C4AI-Command-R-V01 | 26.2 |
| Горилла-Опенфункция-V2 | 25.6 |
| C4ai-Command R+ | 24.7 |
Прогнозирование вызова функции оценки в наборе данных SGD. Метрика точности измеряет общую правильность предсказанных вызовов функций, включая прогноз имени функции и извлечение аргументов.
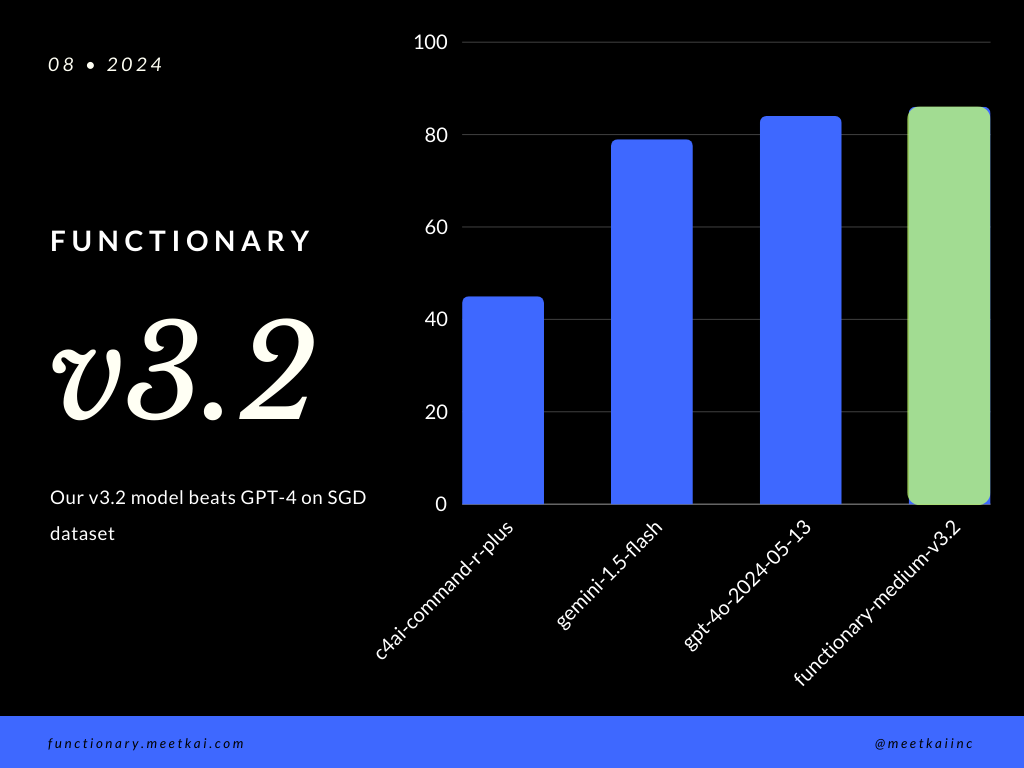
| Набор данных | Название модели | Точность вызова функции (имя и аргументы) |
|---|---|---|
| SGD | Meetkai/функциональный средний V3.1 | 88,11% |
| SGD | GPT-4o-2024-05-13 | 82,75% |
| SGD | Близнецы-1,5-флаш | 79,64% |
| SGD | C4ai-Command-R-Plus | 45,66% |
Смотрите обучение Readme
Хотя это не строго применяется, чтобы обеспечить более безопасное выполнение функций, можно включить выборку грамматики для обеспечения проверки типов. Основные проверки безопасности должны быть выполнены в самих функциях/действиях. Такие как проверка заданного входа или объем, которая будет передана модели.


