functionary
1.0.0

O funcionário é um modelo de idioma que pode interpretar e executar funções/plugins.
O modelo determina quando executar funções, paralelamente ou em série, e pode entender suas saídas. Só desencadeia funções conforme necessário. As definições de função são fornecidas como objetos de esquema JSON, semelhantes às chamadas de função do OpenAI GPT.
Documentação e mais exemplos: funcionário.meetkai.com
{type: "code_interpreter"} nas ferramentas)! O funcionário pode ser implantado usando nossos servidores VLLM ou SGLANG. Escolha qualquer um dependendo de suas preferências.
vllm
pip install -e .[vllm]SGLANG
pip install -e .[sglang] --find-links https://flashinfer.ai/whl/cu121/torch2.4/flashinfer/vllm
python3 server_vllm.py --model " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --max-model-len 8192SGLANG
python3 server_sglang.py --model-path " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --context-length 8192 Nossos modelos médios exigem: 4XA6000 ou 2XA100 80 GB para executar, precisam usar: tensor-parallel-size ou tp (sglang)
vllm
# vllm requires to run this first: https://github.com/vllm-project/vllm/issues/6152
export VLLM_WORKER_MULTIPROC_METHOD=spawn
python server_vllm.py --model " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --max-model-len 8192 --tensor-parallel-size 2SGLANG
python server_sglang.py --model-path " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --context-length 8192 --tp 2Semelhante ao LORA no VLLM, nosso servidor suporta servir adaptadores LORA tanto na inicialização quanto dinamicamente.
Para servir um adaptador LORA na Startup, execute o servidor com o argumento --lora-modules :
python server_vllm.py --model {BASE_MODEL} --enable-lora --lora-modules {name}={path} {name}={path} --host 0.0.0.0 --port 8000 Para servir um adaptador LORA dinamicamente, use o ponto final /v1/load_lora_adapter :
python server_vllm.py --model {BASE_MODEL} --enable-lora --host 0.0.0.0 --port 8000
# Load a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/load_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora",
"lora_path": "/path/to/my_lora_adapter"
} '
# Example chat request to lora adapter
curl -X POST http://localhost:8000/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "my_lora",
"messages": [...],
"tools": [...],
"tool_choice": "auto"
} '
# Unload a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/unload_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora"
} ' Também oferecemos nosso próprio recurso de amostragem gramatical que chama função, que restringe a geração do LLM a seguir sempre o modelo de prompt e garante 100% de precisão para o nome da função. Os parâmetros são gerados usando o eficiente-format-enforce, que garante que os parâmetros sigam o esquema da ferramenta chamada. Para ativar a amostragem gramatical, execute o servidor VLLM com o argumento da linha de comando --enable-grammar-sampling :
python3 server_vllm.py --model " meetkai/functionary-medium-v3.1 " --max-model-len 8192 --tensor-parallel-size 2 --enable-grammar-samplingNota: O suporte à amostragem gramatical é aplicável apenas para os modelos V2, v3.0, v3.2. Não existe esse suporte para modelos V1 e V3.1.
Também fornecemos um serviço que executa a inferência em modelos funcionários usando a inferência de geração de texto (TGI). Siga estas etapas para começar:
Instale o Docker seguindo suas instruções de instalação.
Instale o Docker SDK para Python
pip install dockerNa inicialização, o servidor TGI funcionário tenta se conectar a um terminal TGI existente. Nesse caso, você pode executar o seguinte:
python3 server_tgi.py --model < REMOTE_MODEL_ID_OR_LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT > Se o terminal TGI não existir, o servidor TGI funcionário iniciará um novo contêiner do TGI Endpoint com o endereço fornecido no argumento da CLI endpoint através do Docker Python SDK instalado. Execute os seguintes comandos para modelos remotos e locais, respectivamente:
python3 server_tgi.py --model < REMOTE_MODEL_ID > --remote_model_save_folder < PATH_TO_SAVE_AND_CACHE_REMOTE_MODEL > --endpoint < TGI_SERVICE_ENDPOINT > python3 server_tgi.py --model < LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT >Docker
Se você está tendo problemas com dependências e terá o NVIDIA-container-Toolkit, poderá iniciar seu ambiente como este:
sudo docker run --gpus all -it --ipc=host --name functionary -v ${PWD} /functionary_workspace:/workspace -p 8000:8000 nvcr.io/nvidia/pytorch:23.10-py3 from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" , api_key = "functionary" )
client . chat . completions . create (
model = "meetkai/functionary-small-v3.2" ,
messages = [{ "role" : "user" ,
"content" : "What is the weather for Istanbul?" }
],
tools = [{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}],
tool_choice = "auto"
) import requests
data = {
'model' : 'meetkai/functionary-small-v3.2' , # model name here is the value of argument "--model" in deploying: server_vllm.py or server.py
'messages' : [
{
"role" : "user" ,
"content" : "What is the weather for Istanbul?"
}
],
'tools' :[ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
}
response = requests . post ( "http://127.0.0.1:8000/v1/chat/completions" , json = data , headers = {
"Content-Type" : "application/json" ,
"Authorization" : "Bearer xxxx"
})
# Print the response text
print ( response . text )| Modelo | Descrição | VRAM FP16 |
|---|---|---|
| funcionário-medium-v3.2 | Contexto 128k, intérprete de código, usando nosso próprio modelo de prompt | 160 GB |
| funcionário-small-v3.2 / gguf | Contexto 128k, intérprete de código, usando nosso próprio modelo de prompt | 24 GB |
| funcionário-medium-v3.1 / gguf | Contexto 128k, intérprete de código, usando o modelo de prompt do Meta Original | 160 GB |
| funcionário-small-v3.1 / gguf | Contexto 128k, intérprete de código, usando o modelo de prompt do Meta Original | 24 GB |
| funcionário-medium-v3.0 / gguf | Contexto de 8k, baseado em meta-llama/meta-llama-3-70b-Instruct | 160 GB |
| funcionário-small-v2.5 / gguf | Contexto de 8k, intérprete de código | 24 GB |
| funcionário-small-v2.4 / gguf | Contexto de 8k, intérprete de código | 24 GB |
| funcionário-medium-v2.4 / gguf | Contexto de 8k, intérprete de código, melhor precisão | 90 GB |
| funcionário-small-v2.2 / gguf | Contexto de 8k | 24 GB |
| funcionário-medium-v2.2 / gguf | Contexto de 8k | 90 GB |
| funcionário-7b-v2.1 / gguf | Contexto de 8k | 24 GB |
| funcionário-7b-v2 / gguf | Suporte de chamada de função paralela. | 24 GB |
| funcionário-7b-v1.4 / gguf | Contexto 4K, melhor precisão (depreciada) | 24 GB |
| funcionário-7b-v1.1 | Contexto 4K (depreciado) | 24 GB |
| funcionário-7b-v0.1 | Contexto 2K (depreciado) não recomendado, use 2.1 em diante | 24 GB |
A diferença entre o OpenAI-Python V0 e V1, você pode se referir à documentação oficial aqui
| Recurso/projeto | Funcionário | Nexusraven | Gorila | Gládio | GPT-4-1106-PREVISÃO |
|---|---|---|---|---|---|
| Chamada de função única | ✅ | ✅ | ✅ | ✅ | ✅ |
| Chamadas de função paralela | ✅ | ✅ | ✅ | ✅ | |
| Seguindo os argumentos de função ausente | ✅ | ✅ | |||
| Multi-turn | ✅ | ✅ | ✅ | ||
| Gerar respostas do modelo fundamentadas nos resultados de execução das ferramentas | ✅ | ✅ | |||
| Chit-Chat | ✅ | ✅ | ✅ | ✅ | |
| Interpretador de código | ✅ | ✅ |
Você pode encontrar mais detalhes dos recursos aqui
Exemplo de inferência usando llama-cpp-python pode ser encontrado em: llama_cpp_inference.py.
Além disso, o funcionário também foi integrado ao llama-cpp-python, no entanto, a integração pode não ser atualizada rapidamente ; portanto, se houver algo errado ou estranho no resultado, use: llama_cpp_inference.py. Atualmente, a v2.5 não foi integrada; portanto, se você estiver usando o funcionário-small-v2.5-gguf , use: llama_cpp_inference.py
Verifique se a versão mais recente do LLAMA-CPP-Python está instalada com sucesso em seu sistema. O V2 funcionário está totalmente integrado ao LLAMA-CPP-Python. Você pode executar a inferência usando os modelos GGUF da Suncionário por meio de conclusão normal de bate-papo ou através do servidor compatível com o OpenAI-OpenAI do LLAMA-CPPON, que se comporta de maneira semelhante à nossa.
A seguir, é apresentado o código de amostra usando a conclusão normal do bate -papo:
from llama_cpp import Llama
from llama_cpp . llama_tokenizer import LlamaHFTokenizer
# We should use HF AutoTokenizer instead of llama.cpp's tokenizer because we found that Llama.cpp's tokenizer doesn't give the same result as that from Huggingface. The reason might be in the training, we added new tokens to the tokenizer and Llama.cpp doesn't handle this successfully
llm = Llama . from_pretrained (
repo_id = "meetkai/functionary-small-v2.4-GGUF" ,
filename = "functionary-small-v2.4.Q4_0.gguf" ,
chat_format = "functionary-v2" ,
tokenizer = LlamaHFTokenizer . from_pretrained ( "meetkai/functionary-small-v2.4-GGUF" ),
n_gpu_layers = - 1
)
messages = [
{ "role" : "user" , "content" : "what's the weather like in Hanoi?" }
]
tools = [ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g., San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
result = llm . create_chat_completion (
messages = messages ,
tools = tools ,
tool_choice = "auto" ,
)
print ( result [ "choices" ][ 0 ][ "message" ])A saída seria:
{ 'role' : 'assistant' , 'content' : None , 'tool_calls' : [{ 'type' : 'function' , 'function' : { 'name' : 'get_current_weather' , 'arguments' : '{ n "location": "Hanoi" n }' }}]}Para mais detalhes, consulte a seção de chamadas de função no llama-cpp-python. Para usar nossos modelos funcionários do GGUF usando o servidor compatível com o OpenAI-OpenAI-Python, consulte aqui para obter mais detalhes e documentação.
Observação:
messages .Para chamar a função Python real, obtenha o resultado e extraia o resultado para responder, você pode usar o Chatlab. O exemplo a seguir usa chatlab == 0.16.0:
Observe que o Chatlab atualmente não suporta chamadas de função paralela. Este código de amostra é compatível apenas com a versão 1.4 funcionária e pode não funcionar corretamente com a versão 2.0 funcionária.
from chatlab import Conversation
import openai
import os
openai . api_key = "functionary" # We just need to set this something other than None
os . environ [ 'OPENAI_API_KEY' ] = "functionary" # chatlab requires us to set this too
openai . api_base = "http://localhost:8000/v1"
# now provide the function with description
def get_car_price ( car_name : str ):
"""this function is used to get the price of the car given the name
:param car_name: name of the car to get the price
"""
car_price = {
"tang" : { "price" : "$20000" },
"song" : { "price" : "$25000" }
}
for key in car_price :
if key in car_name . lower ():
return { "price" : car_price [ key ]}
return { "price" : "unknown" }
chat = Conversation ( model = "meetkai/functionary-7b-v2" )
chat . register ( get_car_price ) # register this function
chat . submit ( "what is the price of the car named Tang?" ) # submit user prompt
# print the flow
for message in chat . messages :
role = message [ "role" ]. upper ()
if "function_call" in message :
func_name = message [ "function_call" ][ "name" ]
func_param = message [ "function_call" ][ "arguments" ]
print ( f" { role } : call function: { func_name } , arguments: { func_param } " )
else :
content = message [ "content" ]
print ( f" { role } : { content } " )A saída será assim:
USER: what is the price of the car named Tang?
ASSISTANT: call function: get_car_price, arguments:{
"car_name": "Tang"
}
FUNCTION: {'price': {'price': '$20000'}}
ASSISTANT: The price of the car named Tang is $20,000.
A implantação sem servidor de modelos funcionários é suportada através do script modal_server_vll.py . Depois de se inscrever e instalar o Modal, siga estas etapas para implantar nosso servidor VLLM no Modal:
modal environment create devSe você já possui um ambiente de desenvolvimento criado, não há necessidade de criar outro. Basta configurar para ele na próxima etapa.
modal config set-environment devmodal serve modal_server_vllmmodal deploy modal_server_vllmAqui estão alguns exemplos de como você pode usar este sistema de chamada de função:
A função plan_trip(destination: string, duration: int, interests: list) pode levar a entrada do usuário como "Quero planejar uma viagem de 7 dias a Paris com foco em arte e cultura" e gerar um itinerário de acordo.
client . chat . completions . create ((
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'I want to plan a 7-day trip to Paris with a focus on art and culture' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "plan_trip" ,
"description" : "Plan a trip based on user's interests" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"destination" : {
"type" : "string" ,
"description" : "The destination of the trip" ,
},
"duration" : {
"type" : "integer" ,
"description" : "The duration of the trip in days" ,
},
"interests" : {
"type" : "array" ,
"items" : { "type" : "string" },
"description" : "The interests based on which the trip will be planned" ,
},
},
"required" : [ "destination" , "duration" , "interests" ],
}
}
}
]
)Resposta terá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Em seguida, você precisa chamar a função plan_trip com argumentos fornecidos. Se você quiser um comentário do modelo, chamará o modelo novamente com a resposta da função, o modelo escreverá o comentário necessário.
Uma função como Estimate_property_Value (Property_Details: DICT) pode permitir que os usuários inserissem detalhes sobre uma propriedade (como localização, tamanho, número de salas etc.) e receber um valor de mercado estimado.
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{
"role" : "user" ,
"content" : 'What is the estimated value of a 3-bedroom house in San Francisco with 2000 sq ft area?'
},
{
"role" : "assistant" ,
"content" : None ,
"tool_calls" : [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"arguments" : '{ n "property_details": {"location": "San Francisco", "size": 2000, "rooms": 3} n }'
}
}
]
}
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"description" : "Estimate the market value of a property" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"property_details" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The location of the property"
},
"size" : {
"type" : "integer" ,
"description" : "The size of the property in square feet"
},
"rooms" : {
"type" : "integer" ,
"description" : "The number of rooms in the property"
}
},
"required" : [ "location" , "size" , "rooms" ]
}
},
"required" : [ "property_details" ]
}
}
}
],
tool_choice = "auto"
)Resposta terá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Em seguida, você precisa chamar a função plan_trip com argumentos fornecidos. Se você quiser um comentário do modelo, chamará o modelo novamente com a resposta da função, o modelo escreverá o comentário necessário.
Uma função parse_customer_complaint(complaint: {issue: string, frequency: string, duration: string}) poderia ajudar a extrair informações estruturadas de uma reclamação complexa e narrativa do cliente, identificando a questão central e as soluções em potencial. O objeto complaint pode incluir propriedades como issue (o principal problema), frequency (com que frequência ocorre o problema) e duration (há quanto tempo ocorreu o problema).
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'My internet has been disconnecting frequently for the past week' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "parse_customer_complaint" ,
"description" : "Parse a customer complaint and identify the core issue" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"complaint" : {
"type" : "object" ,
"properties" : {
"issue" : {
"type" : "string" ,
"description" : "The main problem" ,
},
"frequency" : {
"type" : "string" ,
"description" : "How often the issue occurs" ,
},
"duration" : {
"type" : "string" ,
"description" : "How long the issue has been occurring" ,
},
},
"required" : [ "issue" , "frequency" , "duration" ],
},
},
"required" : [ "complaint" ],
}
}
}
],
tool_choice = "auto"
)Resposta terá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " parse_customer_complaint " , "arguments" : '{n "complaint": {"issue": "internet disconnecting", "frequency": "frequently", "duration": "past week" } n } '}} ]}Então você precisa chamar a função parse_customer_complant com argumentos fornecidos. Se você quiser um comentário do modelo, chamará o modelo novamente com a resposta da função, o modelo escreverá o comentário necessário.
Convertemos definições de função em um texto semelhante às definições do TypeScript. Em seguida, injetamos essas definições como solicitações do sistema. Depois disso, injetamos o prompt do sistema padrão. Então começamos as mensagens de conversa.
O exemplo rápido pode ser encontrado aqui: v1 (v1.4), v2 (v2, v2.1, v2.2, v2.4) e v2.llama3 (v2.5)
Não alteramos as probabilidades de logit para estar em conformidade com um determinado esquema, mas o próprio modelo sabe como se conformar. Isso nos permite usar ferramentas e sistemas de cache existentes com facilidade.
Estamos classificados em 2º na tabela de classificação de chamadas de função de Berkeley (Última atualização: 2024-08-11)
| Nome do modelo | Função de precisão de chamada (nome e argumentos) |
|---|---|
| meetkai/funcionário-medium-v3.1 | 88,88% |
| GPT-4-1106-PREVISE (PROMPT) | 88,53% |
| meetkai/funcionário-small-v3.2 | 82,82% |
| meetkai/funcionário-small-v3.1 | 82,53% |
| Firefunção-V2 (FC) | 78,82,47% |
Também avaliamos nossos modelos no ToolSandBox, este benchmark é muito mais difícil do que a tabela de classificação de chamadas de funções de Berkeley . Esse benchmark inclui a execução de ferramentas com estado, dependências implícitas do estado entre as ferramentas, um simulador de usuário integrado que suporta avaliação conversacional na política e uma estratégia de avaliação dinâmica para marcos intermediários e finais em uma trajetória arbitrária. Os autores deste benchmark mostraram que há uma enorme lacuna de desempenho entre os modelos de código aberto e os modelos proprietários.
Do nosso resultado de avaliação, nossos modelos são comparáveis aos melhores modelos proprietários e muito melhores do que outros modelos de código aberto.
| Nome do modelo | Pontuação média de similaridade |
|---|---|
| GPT-4O-2024-05-13 | 73 |
| Claude-3-Opus-20240229 | 69.2 |
| Funcionário-medium-v3.1 | 68.87 |
| GPT-3.5-Turbo-0125 | 65.6 |
| GPT-4-0125-PREVISÃO | 64.3 |
| CLAUDE-3-SONNET-20240229 | 63.8 |
| Funcionário-small-v3.1 | 63.13 |
| Gemini-1.5-Pro-001 | 60.4 |
| Funcionário-small-v3.2 | 58.56 |
| Claude-3-Haiku-20240307 | 54.9 |
| Gemini-1.0-Pro | 38.1 |
| Hermes-2-Pro-Mistral-7b | 31.4 |
| Mistral-7b-Instruct-V0.3 | 29.8 |
| C4AI-COMMAND-R-V01 | 26.2 |
| Gorilla-Openfunctions-V2 | 25.6 |
| C4AI-COMMAND R+ | 24.7 |
Função de avaliação Previsão de chamada no conjunto de dados SGD. A métrica de precisão mede a correção geral das chamadas de função prevista, incluindo a previsão de nomes da função e a extração de argumentos.
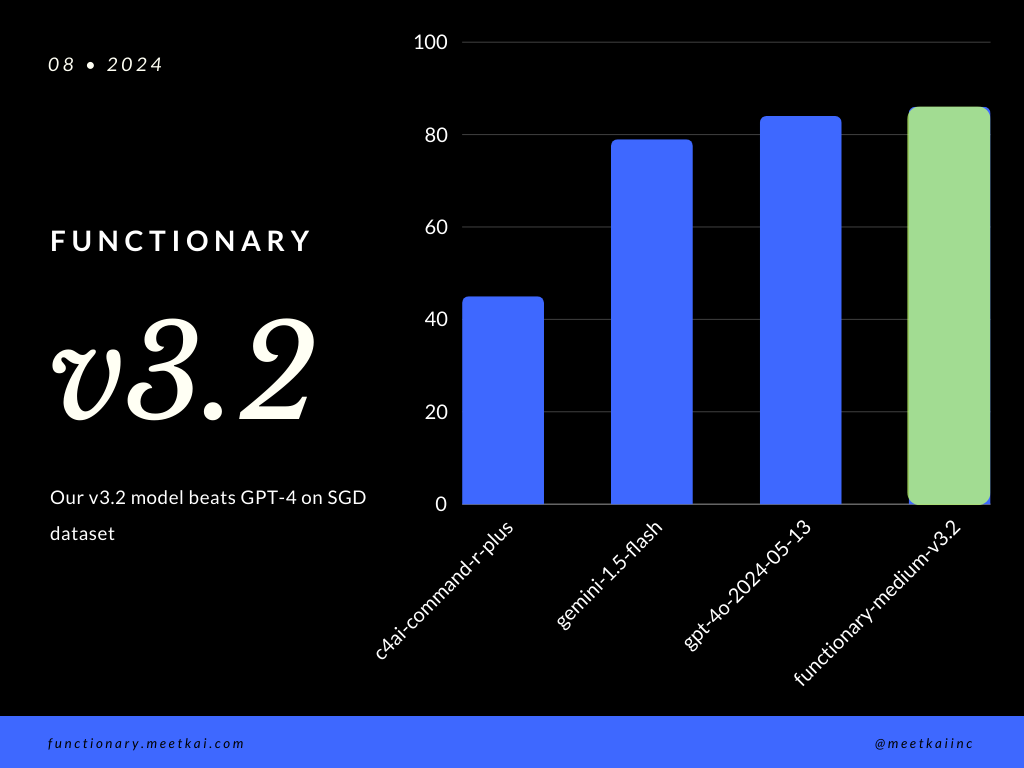
| Conjunto de dados | Nome do modelo | Função de precisão de chamada (nome e argumentos) |
|---|---|---|
| Sgd | meetkai/funcionário-medium-v3.1 | 88,11% |
| Sgd | GPT-4O-2024-05-13 | 82,75% |
| Sgd | Gemini-1.5-Flash | 79,64% |
| Sgd | C4AI-COMMAND-R-PLUS | 45,66% |
Veja o treinamento ReadMe
Embora não seja estritamente aplicado, para garantir uma execução mais segura da função, pode -se permitir a amostragem gramatical para aplicar a verificação do tipo. As principais verificações de segurança precisam ser feitas nas próprias funções/ações. Como a validação da entrada fornecida ou o OPUT que será dado ao modelo.


