functionary
1.0.0

Le fonctionnaire est un modèle de langue qui peut interpréter et exécuter des fonctions / plugins.
Le modèle détermine quand exécuter des fonctions, que ce soit en parallèle ou en série, et peut comprendre leurs sorties. Il ne déclenche que les fonctions au besoin. Les définitions de fonction sont données sous forme d'objets de schéma JSON, similaires aux appels de fonction Openai GPT.
Documentation et plus d'exemples: functionary.meetkai.com
{type: "code_interpreter"} dans les outils)! Le fonctionnaire peut être déployé à l'aide de nos serveurs VLLM ou SGLANG. Choisissez l'un ou l'autre selon vos préférences.
vllm
pip install -e .[vllm]Sglang
pip install -e .[sglang] --find-links https://flashinfer.ai/whl/cu121/torch2.4/flashinfer/vllm
python3 server_vllm.py --model " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --max-model-len 8192Sglang
python3 server_sglang.py --model-path " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --context-length 8192 Nos modèles moyens nécessitent: 4xa6000 ou 2xa100 80 Go pour s'exécuter, à utiliser: tensor-parallel-size ou tp (SGlang)
vllm
# vllm requires to run this first: https://github.com/vllm-project/vllm/issues/6152
export VLLM_WORKER_MULTIPROC_METHOD=spawn
python server_vllm.py --model " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --max-model-len 8192 --tensor-parallel-size 2Sglang
python server_sglang.py --model-path " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --context-length 8192 --tp 2Semblable à LORA dans VLLM, notre serveur prend en charge les adaptateurs LORA à la fois au démarrage et dynamiquement.
Pour servir un adaptateur LORA au démarrage, exécutez le serveur avec l'argument --lora-modules :
python server_vllm.py --model {BASE_MODEL} --enable-lora --lora-modules {name}={path} {name}={path} --host 0.0.0.0 --port 8000 Pour servir dynamiquement un adaptateur LORA, utilisez le point de terminaison /v1/load_lora_adapter :
python server_vllm.py --model {BASE_MODEL} --enable-lora --host 0.0.0.0 --port 8000
# Load a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/load_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora",
"lora_path": "/path/to/my_lora_adapter"
} '
# Example chat request to lora adapter
curl -X POST http://localhost:8000/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "my_lora",
"messages": [...],
"tools": [...],
"tool_choice": "auto"
} '
# Unload a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/unload_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora"
} ' Nous proposons également notre propre fonctionnalité d'échantillonnage de grammaire appelant des fonctions qui contraint la génération de LLM pour toujours suivre le modèle invite, et assure une précision de 100% pour le nom de la fonction. Les paramètres sont générés à l'aide de l'efficacité LM-format-Enforcer, qui garantit que les paramètres suivent le schéma de l'outil appelé. Pour activer l'échantillonnage de grammaire, exécutez le serveur VLLM avec l'argument de la ligne de commande --enable-grammar-sampling :
python3 server_vllm.py --model " meetkai/functionary-medium-v3.1 " --max-model-len 8192 --tensor-parallel-size 2 --enable-grammar-samplingRemarque: La prise en charge d'échantillonnage de grammaire est applicable uniquement aux modèles V2, V3.0, V3.2. Il n'y a pas un tel support pour les modèles V1 et V3.1.
Nous fournissons également un service qui effectue l'inférence sur les modèles fonctionnels en utilisant l'inférence de génération de texte (TGI). Suivez ces étapes pour commencer:
Installez Docker suivant leurs instructions d'installation.
Installez le SDK Docker pour Python
pip install dockerAu démarrage, le serveur TGI fonctionnaire essaie de se connecter à un point de terminaison TGI existant. Dans ce cas, vous pouvez exécuter ce qui suit:
python3 server_tgi.py --model < REMOTE_MODEL_ID_OR_LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT > Si le point de terminaison TGI n'existe pas, le serveur TGI fonctionnaire démarrera un nouveau conteneur TGI Endpoint avec l'adresse fournie dans l'argument CLI endpoint via le SDK Docker Python installé. Exécutez respectivement les commandes suivantes pour les modèles distants et locaux:
python3 server_tgi.py --model < REMOTE_MODEL_ID > --remote_model_save_folder < PATH_TO_SAVE_AND_CACHE_REMOTE_MODEL > --endpoint < TGI_SERVICE_ENDPOINT > python3 server_tgi.py --model < LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT >Docker
Si vous rencontrez des problèmes avec les dépendances et que vous avez Nvidia-Container-Toolkit, vous pouvez démarrer votre environnement comme ceci:
sudo docker run --gpus all -it --ipc=host --name functionary -v ${PWD} /functionary_workspace:/workspace -p 8000:8000 nvcr.io/nvidia/pytorch:23.10-py3 from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" , api_key = "functionary" )
client . chat . completions . create (
model = "meetkai/functionary-small-v3.2" ,
messages = [{ "role" : "user" ,
"content" : "What is the weather for Istanbul?" }
],
tools = [{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}],
tool_choice = "auto"
) import requests
data = {
'model' : 'meetkai/functionary-small-v3.2' , # model name here is the value of argument "--model" in deploying: server_vllm.py or server.py
'messages' : [
{
"role" : "user" ,
"content" : "What is the weather for Istanbul?"
}
],
'tools' :[ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
}
response = requests . post ( "http://127.0.0.1:8000/v1/chat/completions" , json = data , headers = {
"Content-Type" : "application/json" ,
"Authorization" : "Bearer xxxx"
})
# Print the response text
print ( response . text )| Modèle | Description | VRAM FP16 |
|---|---|---|
| fonctionnaire-médium-v3.2 | Contexte 128K, interprète de code, en utilisant notre propre modèle d'invite | 160 Go |
| fonctionnaire-petit-v3.2 / gguf | Contexte 128K, interprète de code, en utilisant notre propre modèle d'invite | 24 Go |
| fonctionnaire-médium-v3.1 / gguf | Contexte 128K, interprète de code, en utilisant le modèle d'invite de Meta d'origine | 160 Go |
| Fonctionnaire-Sall-V3.1 / GGUF | Contexte 128K, interprète de code, en utilisant le modèle d'invite de Meta d'origine | 24 Go |
| fonctionnaire-médium-v3.0 / gguf | Contexte 8K, basé sur Meta-Lama / Meta-Lama-3-70B-Istruct | 160 Go |
| Fonctionnaire-Sall-V2.5 / GGUF | Contexte 8K, interprète de code | 24 Go |
| Fonctionnaire-Sall-V2.4 / GGUF | Contexte 8K, interprète de code | 24 Go |
| fonctionnaire-médium-v2.4 / gguf | Contexte 8k, interprète de code, meilleure précision | 90 Go |
| fonctionnaire-petit-v2.2 / gguf | Contexte 8K | 24 Go |
| fonctionnaire-médium-v2.2 / gguf | Contexte 8K | 90 Go |
| fonctionnaire-7b-v2.1 / gguf | Contexte 8K | 24 Go |
| fonctionnaire-7b-v2 / gguf | Prise en charge de l'appel de fonction parallèle. | 24 Go |
| fonctionnaire-7b-v1.4 / gguf | 4K Contexte, meilleure précision (obsolète) | 24 Go |
| fonctionnaire-7b-v1.1 | 4K Contexte (déprécié) | 24 Go |
| fonctionnaire-7b-v0.1 | Contexte 2k (déprécié) Non recommandé, utilisez 2.1 à partir | 24 Go |
La différence entre Openai-Python V0 et V1 Vous pouvez vous référer à la documentation officielle ici
| Caractéristique / projet | Fonctionnaire | Nexusraven | Gorille | Gloire | GPT-4-1106-Preview |
|---|---|---|---|---|---|
| Appel à fonction unique | ✅ | ✅ | ✅ | ✅ | ✅ |
| Appels de fonction parallèles | ✅ | ✅ | ✅ | ✅ | |
| Suivre les arguments de fonction manquants | ✅ | ✅ | |||
| Multi-tour | ✅ | ✅ | ✅ | ||
| Générer des réponses du modèle fondées sur les résultats de l'exécution des outils | ✅ | ✅ | |||
| Bavardage | ✅ | ✅ | ✅ | ✅ | |
| Interprète de code | ✅ | ✅ |
Vous pouvez trouver plus de détails sur les fonctionnalités ici
Un exemple d'inférence à l'aide de llama-cpp-python peut être trouvé dans: llama_cpp_inference.py.
En outre, le fonctionnaire a également été intégré à Llama-Cpp-Python, mais l'intégration peut ne pas être rapidement mise à jour , donc s'il y a quelque chose de mal ou de bizarre dans le résultat, veuillez utiliser: llama_cpp_inference.py à la place. Actuellement, la v2.5 n'a pas été intégrée, donc si vous utilisez fonctionnaire-Small-V2.5-Gguf , veuillez utiliser: llama_cpp_inference.py
Assurez-vous que la dernière version de LLAMA-CPP-Python est installée avec succès dans votre système. Le V2 fonctionnaire est entièrement intégré dans LLAMA-CPP-Python. Vous pouvez effectuer l'inférence en utilisant les modèles GGUF de fonctionnaire via l'achèvement du chat normal ou via le serveur compatible OpenAI de LLAMA-CPP-Python qui se comporte de manière similaire à la nôtre.
Ce qui suit est l'exemple de code en utilisant l'achèvement du chat normal:
from llama_cpp import Llama
from llama_cpp . llama_tokenizer import LlamaHFTokenizer
# We should use HF AutoTokenizer instead of llama.cpp's tokenizer because we found that Llama.cpp's tokenizer doesn't give the same result as that from Huggingface. The reason might be in the training, we added new tokens to the tokenizer and Llama.cpp doesn't handle this successfully
llm = Llama . from_pretrained (
repo_id = "meetkai/functionary-small-v2.4-GGUF" ,
filename = "functionary-small-v2.4.Q4_0.gguf" ,
chat_format = "functionary-v2" ,
tokenizer = LlamaHFTokenizer . from_pretrained ( "meetkai/functionary-small-v2.4-GGUF" ),
n_gpu_layers = - 1
)
messages = [
{ "role" : "user" , "content" : "what's the weather like in Hanoi?" }
]
tools = [ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g., San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
result = llm . create_chat_completion (
messages = messages ,
tools = tools ,
tool_choice = "auto" ,
)
print ( result [ "choices" ][ 0 ][ "message" ])La sortie serait:
{ 'role' : 'assistant' , 'content' : None , 'tool_calls' : [{ 'type' : 'function' , 'function' : { 'name' : 'get_current_weather' , 'arguments' : '{ n "location": "Hanoi" n }' }}]}Pour plus de détails, veuillez vous référer à la section d'appel de la fonction dans LLAMA-CPP-Python. Pour utiliser nos modèles GGUF fonctionnels à l'aide du serveur compatible OpenAI-compatible de LLAMA-CPP-Python, veuillez vous référer à ici pour plus de détails et de documentation.
Note:
messages .Pour appeler la fonction réelle Python, obtenez le résultat et extraire le résultat pour répondre, vous pouvez utiliser ChatLab. L'exemple suivant utilise ChatLab == 0.16.0:
Veuillez noter que ChatLab ne prend actuellement pas en charge les appels de fonction parallèles. Cet exemple de code est compatible uniquement avec la version 1.4 fonctionnelle et peut ne pas fonctionner correctement avec la version 2.0 fonctionnaire.
from chatlab import Conversation
import openai
import os
openai . api_key = "functionary" # We just need to set this something other than None
os . environ [ 'OPENAI_API_KEY' ] = "functionary" # chatlab requires us to set this too
openai . api_base = "http://localhost:8000/v1"
# now provide the function with description
def get_car_price ( car_name : str ):
"""this function is used to get the price of the car given the name
:param car_name: name of the car to get the price
"""
car_price = {
"tang" : { "price" : "$20000" },
"song" : { "price" : "$25000" }
}
for key in car_price :
if key in car_name . lower ():
return { "price" : car_price [ key ]}
return { "price" : "unknown" }
chat = Conversation ( model = "meetkai/functionary-7b-v2" )
chat . register ( get_car_price ) # register this function
chat . submit ( "what is the price of the car named Tang?" ) # submit user prompt
# print the flow
for message in chat . messages :
role = message [ "role" ]. upper ()
if "function_call" in message :
func_name = message [ "function_call" ][ "name" ]
func_param = message [ "function_call" ][ "arguments" ]
print ( f" { role } : call function: { func_name } , arguments: { func_param } " )
else :
content = message [ "content" ]
print ( f" { role } : { content } " )La sortie ressemblera à ceci:
USER: what is the price of the car named Tang?
ASSISTANT: call function: get_car_price, arguments:{
"car_name": "Tang"
}
FUNCTION: {'price': {'price': '$20000'}}
ASSISTANT: The price of the car named Tang is $20,000.
Le déploiement sans serveur de modèles fonctionnels est pris en charge via le script modal_server_vllm.py . Après avoir inscrit et installé Modal, suivez ces étapes pour déployer notre serveur VLLM sur Modal:
modal environment create devSi vous avez déjà un environnement de développement créé, il n'est pas nécessaire d'en créer un autre. Configurez-le simplement à l'étape suivante.
modal config set-environment devmodal serve modal_server_vllmmodal deploy modal_server_vllmVoici quelques exemples de la façon dont vous pouvez utiliser ce système d'appel de fonction:
La fonction plan_trip(destination: string, duration: int, interests: list) peut prendre une entrée des utilisateurs telle que "Je veux planifier un voyage de 7 jours à Paris en mettant l'accent sur l'art et la culture" et générer un itinéraire en conséquence.
client . chat . completions . create ((
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'I want to plan a 7-day trip to Paris with a focus on art and culture' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "plan_trip" ,
"description" : "Plan a trip based on user's interests" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"destination" : {
"type" : "string" ,
"description" : "The destination of the trip" ,
},
"duration" : {
"type" : "integer" ,
"description" : "The duration of the trip in days" ,
},
"interests" : {
"type" : "array" ,
"items" : { "type" : "string" },
"description" : "The interests based on which the trip will be planned" ,
},
},
"required" : [ "destination" , "duration" , "interests" ],
}
}
}
]
)La réponse aura:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Ensuite, vous devez appeler la fonction plan_trip avec des arguments fournis. Si vous souhaitez un commentaire du modèle, vous appellerez à nouveau le modèle avec la réponse de la fonction, le modèle rédigera le commentaire nécessaire.
Une fonction comme Estimate_Property_Value (Property_Details: Dict) pourrait permettre aux utilisateurs de saisir des détails sur une propriété (tels que l'emplacement, la taille, le nombre de pièces, etc.) et de recevoir une valeur marchande estimée.
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{
"role" : "user" ,
"content" : 'What is the estimated value of a 3-bedroom house in San Francisco with 2000 sq ft area?'
},
{
"role" : "assistant" ,
"content" : None ,
"tool_calls" : [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"arguments" : '{ n "property_details": {"location": "San Francisco", "size": 2000, "rooms": 3} n }'
}
}
]
}
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"description" : "Estimate the market value of a property" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"property_details" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The location of the property"
},
"size" : {
"type" : "integer" ,
"description" : "The size of the property in square feet"
},
"rooms" : {
"type" : "integer" ,
"description" : "The number of rooms in the property"
}
},
"required" : [ "location" , "size" , "rooms" ]
}
},
"required" : [ "property_details" ]
}
}
}
],
tool_choice = "auto"
)La réponse aura:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Ensuite, vous devez appeler la fonction plan_trip avec des arguments fournis. Si vous souhaitez un commentaire du modèle, vous appellerez à nouveau le modèle avec la réponse de la fonction, le modèle rédigera le commentaire nécessaire.
Une fonction parse_customer_complaint(complaint: {issue: string, frequency: string, duration: string}) pourrait aider à extraire des informations structurées à partir d'une plainte complexe et narrative du client, identifiant le problème de base et les solutions potentielles. L'objet complaint peut inclure des propriétés telles que issue (le problème principal), frequency (à quelle fréquence le problème se produit) et duration (combien de temps le problème a eu lieu).
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'My internet has been disconnecting frequently for the past week' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "parse_customer_complaint" ,
"description" : "Parse a customer complaint and identify the core issue" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"complaint" : {
"type" : "object" ,
"properties" : {
"issue" : {
"type" : "string" ,
"description" : "The main problem" ,
},
"frequency" : {
"type" : "string" ,
"description" : "How often the issue occurs" ,
},
"duration" : {
"type" : "string" ,
"description" : "How long the issue has been occurring" ,
},
},
"required" : [ "issue" , "frequency" , "duration" ],
},
},
"required" : [ "complaint" ],
}
}
}
],
tool_choice = "auto"
)La réponse aura:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " parse_customer_complaint " , "arguments" : '{n "complaint": {"issue": "internet disconnecting", "frequency": "frequently", "duration": "past week" } n } '}} ]}Ensuite, vous devez appeler la fonction PARSE_CUSURAT_COMPLAINT avec des arguments fournis. Si vous souhaitez un commentaire du modèle, vous appellerez à nouveau le modèle avec la réponse de la fonction, le modèle rédigera le commentaire nécessaire.
Nous convertissons les définitions de fonction en un texte similaire aux définitions de typeScript. Ensuite, nous injectons ces définitions en tant qu'invites système. Après cela, nous injectons l'invite du système par défaut. Ensuite, nous commençons les messages de conversation.
L'exemple de l'invite peut être trouvé ici: v1 (v1.4), v2 (v2, v2.1, v2.2, v2.4) et v2.llama3 (v2.5)
Nous ne modifions pas les probabilités logit pour se conformer à un certain schéma, mais le modèle lui-même sait se conformer. Cela nous permet d'utiliser facilement des outils et des systèmes de mise en cache existants.
Nous sommes classés 2e dans le classement de Berkeley Fonction-appelant (Dernière mise à jour: 2024-08-11)
| Nom du modèle | Fonction d'appel de fonction (nom et arguments) |
|---|---|
| Meetkai / Fonctionnaire-Medium-V3.1 | 88,88% |
| GPT-4-1106-Preview (invite) | 88,53% |
| meeetkai / fonctionnaire-small-v3.2 | 82,82% |
| meeetkai / fonctionnaire-small-v3.1 | 82,53% |
| Firefunction-V2 (FC) | 78,82,47% |
Nous évaluons également nos modèles sur ToolsandBox, cette référence est beaucoup plus difficile que le classement de Berkeley Function-appelant . Cette référence comprend l'exécution d'outils avec état, les dépendances implicites de l'état entre les outils, un simulateur d'utilisateur intégré prenant en charge l'évaluation conversationnelle en politique et une stratégie d'évaluation dynamique pour les jalons intermédiaires et finaux sur une trajectoire arbitraire. Les auteurs de cette référence ont montré qu'il existe un énorme écart de performance entre les modèles open source et les modèles propriétaires.
D'après notre résultat d'évaluation, nos modèles sont comparables aux meilleurs modèles propriétaires et bien meilleurs que les autres modèles open source.
| Nom du modèle | Score de similitude moyen |
|---|---|
| GPT-4O-2024-05-13 | 73 |
| Claude-3-Opus-20240229 | 69.2 |
| Fonctionnaire-médium-V3.1 | 68.87 |
| GPT-3.5-turbo-0125 | 65.6 |
| GPT-4-0125-Preview | 64.3 |
| Claude-3-Sonnet-20240229 | 63.8 |
| Fonctionnaire-Small-V3.1 | 63.13 |
| Gemini-1.5-Pro-001 | 60.4 |
| Fonctionnaire-small-v3.2 | 58,56 |
| Claude-3-Haiku-20240307 | 54.9 |
| Gemini-1.0-pro | 38.1 |
| Hermes-2-Pro-Mistral-7b | 31.4 |
| Mistral-7B-Instruct-V0.3 | 29.8 |
| C4ai-Command-R-V01 | 26.2 |
| Gorila-openfonctions-v2 | 25.6 |
| C4ai-Command R + | 24.7 |
Prédiction des appels de la fonction d'évaluation dans l'ensemble de données SGD. La métrique de précision mesure l'exactitude globale des appels de fonction prédits, y compris la prédiction du nom de fonction et l'extraction des arguments.
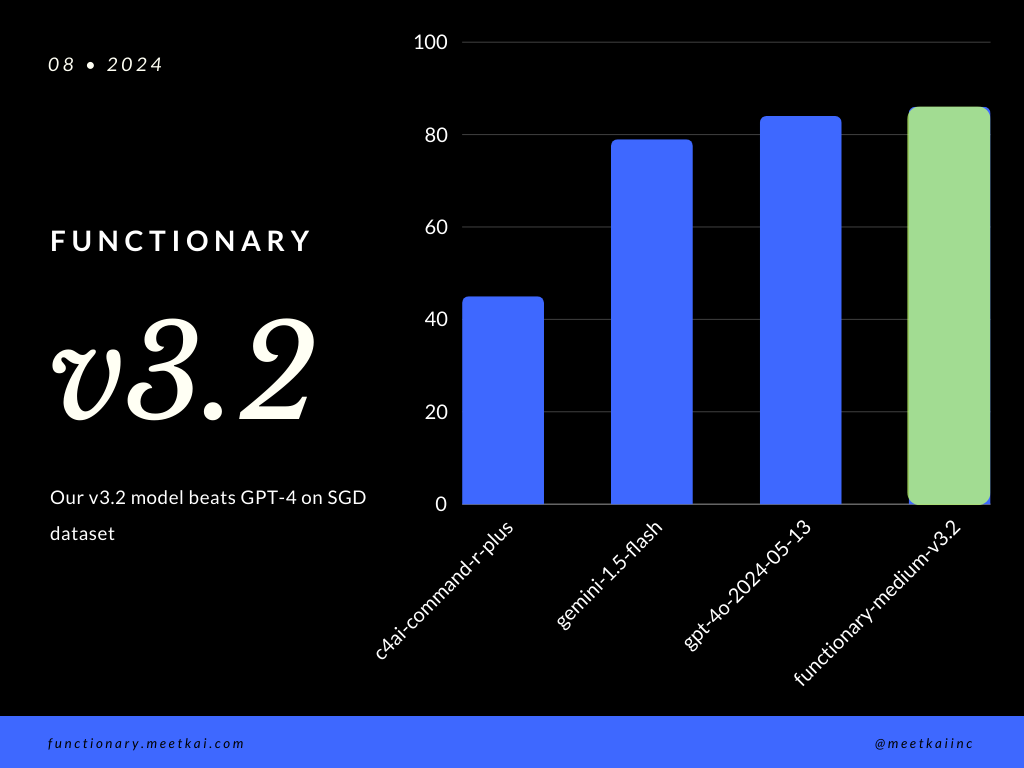
| Ensemble de données | Nom du modèle | Fonction d'appel de fonction (nom et arguments) |
|---|---|---|
| SGD | Meetkai / Fonctionnaire-Medium-V3.1 | 88,11% |
| SGD | GPT-4O-2024-05-13 | 82,75% |
| SGD | Gémeaux | 79,64% |
| SGD | C4ai-Command-R-Plus | 45,66% |
Voir la formation Readme
Bien qu'il ne soit pas strictement appliqué, pour assurer une exécution de fonction plus sécurisée , on peut permettre l'échantillonnage de grammaire pour appliquer la vérification du type. Les principaux contrôles de sécurité doivent être effectués dans les fonctions / actions elles-mêmes. Tels que la validation de l'entrée donnée, ou l'ouput qui sera donné au modèle.


