functionary
1.0.0

El funcionario es un modelo de lenguaje que puede interpretar y ejecutar funciones/complementos.
El modelo determina cuándo ejecutar funciones, ya sea en paralelo o en serie, y puede comprender sus salidas. Solo desencadena funciones según sea necesario. Las definiciones de funciones se dan como objetos de esquema JSON, similares a las llamadas de función OpenAI GPT.
Documentación y más ejemplos: funcionario.meetkai.com
{type: "code_interpreter"} en las herramientas)! El funcionario se puede implementar utilizando nuestros servidores VLLM o SGLANG. Elija cualquiera de los cuales depende de sus preferencias.
vllm
pip install -e .[vllm]Sglang
pip install -e .[sglang] --find-links https://flashinfer.ai/whl/cu121/torch2.4/flashinfer/vllm
python3 server_vllm.py --model " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --max-model-len 8192Sglang
python3 server_sglang.py --model-path " meetkai/functionary-small-v3.2 " --host 0.0.0.0 --port 8000 --context-length 8192 Nuestros modelos medios requieren: 4xa6000 o 2xa100 80 GB para ejecutar, necesitar usar: tensor-parallel-size o tp (Sglang)
vllm
# vllm requires to run this first: https://github.com/vllm-project/vllm/issues/6152
export VLLM_WORKER_MULTIPROC_METHOD=spawn
python server_vllm.py --model " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --max-model-len 8192 --tensor-parallel-size 2Sglang
python server_sglang.py --model-path " meetkai/functionary-medium-v3.1 " --host 0.0.0.0 --port 8000 --context-length 8192 --tp 2Similar a Lora en VLLM, nuestro servidor admite los adaptadores de Lora tanto al inicio como dinámicamente.
Para servir un adaptador Lora al inicio, ejecute el servidor con el argumento --lora-modules :
python server_vllm.py --model {BASE_MODEL} --enable-lora --lora-modules {name}={path} {name}={path} --host 0.0.0.0 --port 8000 Para servir dinámicamente un adaptador Lora, use el punto final /v1/load_lora_adapter :
python server_vllm.py --model {BASE_MODEL} --enable-lora --host 0.0.0.0 --port 8000
# Load a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/load_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora",
"lora_path": "/path/to/my_lora_adapter"
} '
# Example chat request to lora adapter
curl -X POST http://localhost:8000/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "my_lora",
"messages": [...],
"tools": [...],
"tool_choice": "auto"
} '
# Unload a LoRA adapter dynamically
curl -X POST http://localhost:8000/v1/unload_lora_adapter
-H " Content-Type: application/json "
-d ' {
"lora_name": "my_lora"
} ' También ofrecemos nuestra propia función de muestreo de gramática de llamada de función que limita la generación de la LLM para seguir siempre la plantilla de inmediato, y garantiza una precisión del 100% para el nombre de la función. Los parámetros se generan utilizando el comprador de formato LM eficiente, que asegura que los parámetros sigan el esquema de la herramienta llamada. Para habilitar el muestreo de gramática, ejecute el servidor VLLM con el argumento de la línea de comandos --enable-grammar-sampling :
python3 server_vllm.py --model " meetkai/functionary-medium-v3.1 " --max-model-len 8192 --tensor-parallel-size 2 --enable-grammar-samplingNota: El soporte de muestreo de gramática solo es aplicable para los modelos V2, V3.0, V3.2. No existe tal soporte para los modelos V1 y V3.1.
También proporcionamos un servicio que realiza una inferencia en modelos funcionales utilizando la inferencia de generación de texto (TGI). Siga estos pasos para comenzar:
Instale Docker después de sus instrucciones de instalación.
Instale el SDK Docker para Python
pip install dockerAl iniciar, el servidor TGI funcional intenta conectarse a un punto final TGI existente. En este caso, puede ejecutar lo siguiente:
python3 server_tgi.py --model < REMOTE_MODEL_ID_OR_LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT > Si el punto final TGI no existe, el servidor TGI funcional iniciará un nuevo contenedor de punto final TGI con la dirección proporcionada en el argumento CLI endpoint a través del SDK de Docker Python instalado. Ejecute los siguientes comandos para modelos remotos y locales respectivamente:
python3 server_tgi.py --model < REMOTE_MODEL_ID > --remote_model_save_folder < PATH_TO_SAVE_AND_CACHE_REMOTE_MODEL > --endpoint < TGI_SERVICE_ENDPOINT > python3 server_tgi.py --model < LOCAL_MODEL_PATH > --endpoint < TGI_SERVICE_ENDPOINT >Estibador
Si tiene problemas con las dependencias y tiene Nvidia-Conseiner-Toolkit, puede comenzar su entorno de esta manera:
sudo docker run --gpus all -it --ipc=host --name functionary -v ${PWD} /functionary_workspace:/workspace -p 8000:8000 nvcr.io/nvidia/pytorch:23.10-py3 from openai import OpenAI
client = OpenAI ( base_url = "http://localhost:8000/v1" , api_key = "functionary" )
client . chat . completions . create (
model = "meetkai/functionary-small-v3.2" ,
messages = [{ "role" : "user" ,
"content" : "What is the weather for Istanbul?" }
],
tools = [{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}],
tool_choice = "auto"
) import requests
data = {
'model' : 'meetkai/functionary-small-v3.2' , # model name here is the value of argument "--model" in deploying: server_vllm.py or server.py
'messages' : [
{
"role" : "user" ,
"content" : "What is the weather for Istanbul?"
}
],
'tools' :[ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g. San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
}
response = requests . post ( "http://127.0.0.1:8000/v1/chat/completions" , json = data , headers = {
"Content-Type" : "application/json" ,
"Authorization" : "Bearer xxxx"
})
# Print the response text
print ( response . text )| Modelo | Descripción | VRAM FP16 |
|---|---|---|
| funcionario-medio-v3.2 | Contexto de 128k, intérprete de código, utilizando nuestra propia plantilla de inmediato | 160 GB |
| funcionario-small-v3.2 / gguf | Contexto de 128k, intérprete de código, utilizando nuestra propia plantilla de inmediato | 24 GB |
| funcionario-medio-v3.1 / gguf | Contexto de 128k, intérprete de código, utilizando la plantilla de inmediato de Meta original | 160 GB |
| funcionario-small-v3.1 / gguf | Contexto de 128k, intérprete de código, utilizando la plantilla de inmediato de Meta original | 24 GB |
| Funcionario-Medio-V3.0 / Gguf | Contexto de 8k, basado en Meta-Llama/Meta-Llama-3-70B-Instructo | 160 GB |
| Funcionario-Small-V2.5 / Gguf | Contexto de 8k, intérprete de código | 24 GB |
| Funcionario-Small-V2.4 / Gguf | Contexto de 8k, intérprete de código | 24 GB |
| Funcionario-medio-v2.4 / gguf | Contexto de 8k, intérprete de código, mejor precisión | 90 GB |
| Funcionario-Small-V2.2 / Gguf | Contexto de 8k | 24 GB |
| Funcionario-medio-v2.2 / gguf | Contexto de 8k | 90 GB |
| funcionario-7b-v2.1 / gguf | Contexto de 8k | 24 GB |
| funcionario-7b-v2 / gguf | Soporte de llamadas de función paralela. | 24 GB |
| funcionario-7b-v1.4 / gguf | Contexto 4K, mejor precisión (desaprobada) | 24 GB |
| funcionario-7b-v1.1 | Contexto 4K (desaprobado) | 24 GB |
| funcionario-7b-v0.1 | Contexto de 2k (desaprobado) no recomendado, use 2.1 en adelante | 24 GB |
La diferencia entre Operai-Python V0 y V1 puede consultar la documentación oficial aquí
| Característica/proyecto | Funcionario | Nexusraven | Gorila | Glaive | GPT-4-1106 previa |
|---|---|---|---|---|---|
| Llamada de función única | ✅ | ✅ | ✅ | ✅ | ✅ |
| Llamadas de función paralela | ✅ | ✅ | ✅ | ✅ | |
| Siguiendo los argumentos de la función faltante | ✅ | ✅ | |||
| Múltiple | ✅ | ✅ | ✅ | ||
| Generar respuestas modelo basadas en los resultados de la ejecución de herramientas | ✅ | ✅ | |||
| Charla | ✅ | ✅ | ✅ | ✅ | |
| Intérprete de código | ✅ | ✅ |
Puede encontrar más detalles de las características aquí.
Ejemplo de inferencia usando Llama-CPP-Python se puede encontrar en: Llama_CPP_inference.py.
Además, el funcionario también se integró en Llama-CPP-Python, sin embargo, la integración podría no actualizarse rápidamente , por lo que si hay algo mal o extraño en el resultado, use: Llama_CPP_inference.py. Actualmente, V2.5 no se ha integrado, por lo que si está utilizando Funcionary-Small-V2.5-GGUF , use: Llama_CPP_inference.py
Asegúrese de que la última versión de Llama-CPP-Python esté instalada exitosamente en su sistema. Funcionary V2 está completamente integrado en Llama-CPP-Python. Puede realizar una inferencia utilizando los modelos GGUF de Funcionary, ya sea a través de la finalización de chat normal o a través del servidor compatible con OpenAI de Llama-CPP-Python que se comporta de manera similar al nuestro.
El siguiente es el código de muestra utilizando la finalización normal de chat:
from llama_cpp import Llama
from llama_cpp . llama_tokenizer import LlamaHFTokenizer
# We should use HF AutoTokenizer instead of llama.cpp's tokenizer because we found that Llama.cpp's tokenizer doesn't give the same result as that from Huggingface. The reason might be in the training, we added new tokens to the tokenizer and Llama.cpp doesn't handle this successfully
llm = Llama . from_pretrained (
repo_id = "meetkai/functionary-small-v2.4-GGUF" ,
filename = "functionary-small-v2.4.Q4_0.gguf" ,
chat_format = "functionary-v2" ,
tokenizer = LlamaHFTokenizer . from_pretrained ( "meetkai/functionary-small-v2.4-GGUF" ),
n_gpu_layers = - 1
)
messages = [
{ "role" : "user" , "content" : "what's the weather like in Hanoi?" }
]
tools = [ # For functionary-7b-v2 we use "tools"; for functionary-7b-v1.4 we use "functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type" : "function" ,
"function" : {
"name" : "get_current_weather" ,
"description" : "Get the current weather" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The city and state, e.g., San Francisco, CA"
}
},
"required" : [ "location" ]
}
}
}
]
result = llm . create_chat_completion (
messages = messages ,
tools = tools ,
tool_choice = "auto" ,
)
print ( result [ "choices" ][ 0 ][ "message" ])La salida sería:
{ 'role' : 'assistant' , 'content' : None , 'tool_calls' : [{ 'type' : 'function' , 'function' : { 'name' : 'get_current_weather' , 'arguments' : '{ n "location": "Hanoi" n }' }}]}Para obtener más detalles, consulte la sección de llamadas de funciones en Llama-CPP-Python. Para utilizar nuestros modelos GGUF funcionales utilizando el servidor compatible con OpenAI de Llama-CPP-Python, consulte aquí para obtener más detalles y documentación.
Nota:
messages .Para llamar a la función real de Python, obtener el resultado y extraer el resultado para responder, puede usar ChatLab. El siguiente ejemplo usa chatLab == 0.16.0:
Tenga en cuenta que ChatLab actualmente no admite llamadas a funciones paralelas. Este código de muestra es compatible solo con la versión funcional 1.4 y puede no funcionar correctamente con la versión funcional 2.0.
from chatlab import Conversation
import openai
import os
openai . api_key = "functionary" # We just need to set this something other than None
os . environ [ 'OPENAI_API_KEY' ] = "functionary" # chatlab requires us to set this too
openai . api_base = "http://localhost:8000/v1"
# now provide the function with description
def get_car_price ( car_name : str ):
"""this function is used to get the price of the car given the name
:param car_name: name of the car to get the price
"""
car_price = {
"tang" : { "price" : "$20000" },
"song" : { "price" : "$25000" }
}
for key in car_price :
if key in car_name . lower ():
return { "price" : car_price [ key ]}
return { "price" : "unknown" }
chat = Conversation ( model = "meetkai/functionary-7b-v2" )
chat . register ( get_car_price ) # register this function
chat . submit ( "what is the price of the car named Tang?" ) # submit user prompt
# print the flow
for message in chat . messages :
role = message [ "role" ]. upper ()
if "function_call" in message :
func_name = message [ "function_call" ][ "name" ]
func_param = message [ "function_call" ][ "arguments" ]
print ( f" { role } : call function: { func_name } , arguments: { func_param } " )
else :
content = message [ "content" ]
print ( f" { role } : { content } " )La salida se verá así:
USER: what is the price of the car named Tang?
ASSISTANT: call function: get_car_price, arguments:{
"car_name": "Tang"
}
FUNCTION: {'price': {'price': '$20000'}}
ASSISTANT: The price of the car named Tang is $20,000.
La implementación sin servidor de modelos funcionales se admite a través del script modal_server_vllm.py . Después de registrarse e instalar Modal, siga estos pasos para implementar nuestro servidor VLLM en modal:
modal environment create devSi ya tiene un entorno de desarrollo creado, no hay necesidad de crear otro. Simplemente configúrelo en el siguiente paso.
modal config set-environment devmodal serve modal_server_vllmmodal deploy modal_server_vllmAquí hay algunos ejemplos de cómo puede usar este sistema de llamadas de funciones:
La función plan_trip(destination: string, duration: int, interests: list) puede tomar la entrada del usuario, como "Quiero planificar un viaje de 7 días a París con un enfoque en el arte y la cultura" y generar un itinerario en consecuencia.
client . chat . completions . create ((
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'I want to plan a 7-day trip to Paris with a focus on art and culture' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "plan_trip" ,
"description" : "Plan a trip based on user's interests" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"destination" : {
"type" : "string" ,
"description" : "The destination of the trip" ,
},
"duration" : {
"type" : "integer" ,
"description" : "The duration of the trip in days" ,
},
"interests" : {
"type" : "array" ,
"items" : { "type" : "string" },
"description" : "The interests based on which the trip will be planned" ,
},
},
"required" : [ "destination" , "duration" , "interests" ],
}
}
}
]
)La respuesta tendrá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Luego debe llamar a la función plan_trip con argumentos proporcionados. Si desea un comentario del modelo, volverá a llamar al modelo con la respuesta de la función, el modelo escribirá los comentarios necesarios.
Una función como estimado_property_value (Property_details: Dict) podría permitir a los usuarios ingresar detalles sobre una propiedad (como ubicación, tamaño, número de habitaciones, etc.) y recibir un valor de mercado estimado.
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{
"role" : "user" ,
"content" : 'What is the estimated value of a 3-bedroom house in San Francisco with 2000 sq ft area?'
},
{
"role" : "assistant" ,
"content" : None ,
"tool_calls" : [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"arguments" : '{ n "property_details": {"location": "San Francisco", "size": 2000, "rooms": 3} n }'
}
}
]
}
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "estimate_property_value" ,
"description" : "Estimate the market value of a property" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"property_details" : {
"type" : "object" ,
"properties" : {
"location" : {
"type" : "string" ,
"description" : "The location of the property"
},
"size" : {
"type" : "integer" ,
"description" : "The size of the property in square feet"
},
"rooms" : {
"type" : "integer" ,
"description" : "The number of rooms in the property"
}
},
"required" : [ "location" , "size" , "rooms" ]
}
},
"required" : [ "property_details" ]
}
}
}
],
tool_choice = "auto"
)La respuesta tendrá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " plan_trip " , "arguments" : '{n "destination": "Paris",n "duration": 7,n "interests": ["art", "culture"]n } ' } } ]} Luego debe llamar a la función plan_trip con argumentos proporcionados. Si desea un comentario del modelo, volverá a llamar al modelo con la respuesta de la función, el modelo escribirá los comentarios necesarios.
Una función parse_customer_complaint(complaint: {issue: string, frequency: string, duration: string}) podría ayudar a extraer información estructurada de una queja compleja de clientes narrativas, identificando el problema central y las posibles soluciones. El objeto complaint podría incluir propiedades como el issue (el problema principal), frequency (con qué frecuencia ocurre el problema) y duration (cuánto tiempo ha estado ocurriendo el problema).
client . chat . completions . create (
model = "meetkai/functionary-7b-v2" ,
messages = [
{ "role" : "user" , "content" : 'My internet has been disconnecting frequently for the past week' },
],
tools = [
{
"type" : "function" ,
"function" : {
"name" : "parse_customer_complaint" ,
"description" : "Parse a customer complaint and identify the core issue" ,
"parameters" : {
"type" : "object" ,
"properties" : {
"complaint" : {
"type" : "object" ,
"properties" : {
"issue" : {
"type" : "string" ,
"description" : "The main problem" ,
},
"frequency" : {
"type" : "string" ,
"description" : "How often the issue occurs" ,
},
"duration" : {
"type" : "string" ,
"description" : "How long the issue has been occurring" ,
},
},
"required" : [ "issue" , "frequency" , "duration" ],
},
},
"required" : [ "complaint" ],
}
}
}
],
tool_choice = "auto"
)La respuesta tendrá:
{ "role" : " assistant " , "content" : null , "tool_calls" : [{ "type" : " function " , "function" : { "name" : " parse_customer_complaint " , "arguments" : '{n "complaint": {"issue": "internet disconnecting", "frequency": "frequently", "duration": "past week" } n } '}} ]}Luego debe llamar a la función parse_customer_comlaint con argumentos proporcionados. Si desea un comentario del modelo, volverá a llamar al modelo con la respuesta de la función, el modelo escribirá los comentarios necesarios.
Convertimos definiciones de funciones a un texto similar a las definiciones de TypeScript. Luego inyectamos estas definiciones como indicaciones del sistema. Después de eso, inyectamos la solicitud de sistema predeterminada. Luego comenzamos los mensajes de conversación.
El ejemplo de pedido se puede encontrar aquí: V1 (V1.4), V2 (V2, V2.1, V2.2, V2.4) y V2.Llama3 (V2.5)
No cambiamos las probabilidades de logit para ajustarse a un determinado esquema, pero el modelo en sí sabe cómo conformarse. Esto nos permite usar herramientas existentes y sistemas de almacenamiento en caché con facilidad.
Estamos en el segundo lugar en la tabla de clasificación de la función de Berkeley (última actualización: 2024-08-11)
| Nombre del modelo | Función de precisión de llamadas (nombre y argumentos) |
|---|---|
| Meetkai/funcionario-medio-v3.1 | 88.88% |
| GPT-4-1106-Preview (aviso) | 88.53% |
| Meetkai/funcional-small-v3.2 | 82.82% |
| Meetkai/funcional-small-v3.1 | 82.53% |
| FireFunction-V2 (FC) | 78.82.47% |
También evaluamos nuestros modelos en Toolsandbox, este punto de referencia es mucho más difícil que la tabla de clasificación de las funciones de Berkeley . Este punto de referencia incluye la ejecución de herramientas con estado, las dependencias de estado implícitas entre las herramientas, un simulador de usuario incorporado que admite evaluación conversacional sobre política y una estrategia de evaluación dinámica para hitos intermedios y finales en una trayectoria arbitraria. Los autores de este punto de referencia mostraron que existe una gran brecha de rendimiento entre los modelos de código abierto y los modelos propietarios.
A partir de nuestro resultado de la evaluación, nuestros modelos son comparables a los mejores modelos patentados y mucho mejores que otros modelos de código abierto.
| Nombre del modelo | Puntaje de similitud promedio |
|---|---|
| GPT-4O-2024-05-13 | 73 |
| Claude-3-OPUS-20240229 | 69.2 |
| Funcionario-medio-v3.1 | 68.87 |
| GPT-3.5-TURBO-0125 | 65.6 |
| GPT-4-0125 Preview | 64.3 |
| Claude-3-Sonnet-20240229 | 63.8 |
| Funcionario-Small-V3.1 | 63.13 |
| Géminis-1.5-Pro-001 | 60.4 |
| Funcionario-Small-V3.2 | 58.56 |
| Claude-3-HAIKU-20240307 | 54.9 |
| Géminis-1.0-Pro | 38.1 |
| Hermes-2-Pro-Mistral-7b | 31.4 |
| Mistral-7B-Instructo-V0.3 | 29.8 |
| C4AI-Command-R-V01 | 26.2 |
| Gorilla-Openfunctions-V2 | 25.6 |
| C4AI-Command R+ | 24.7 |
Predicción de llamadas de la función de evaluación en el conjunto de datos SGD. La métrica de precisión mide la corrección general de las llamadas de función pronosticadas, incluida la predicción del nombre de la función y la extracción de argumentos.
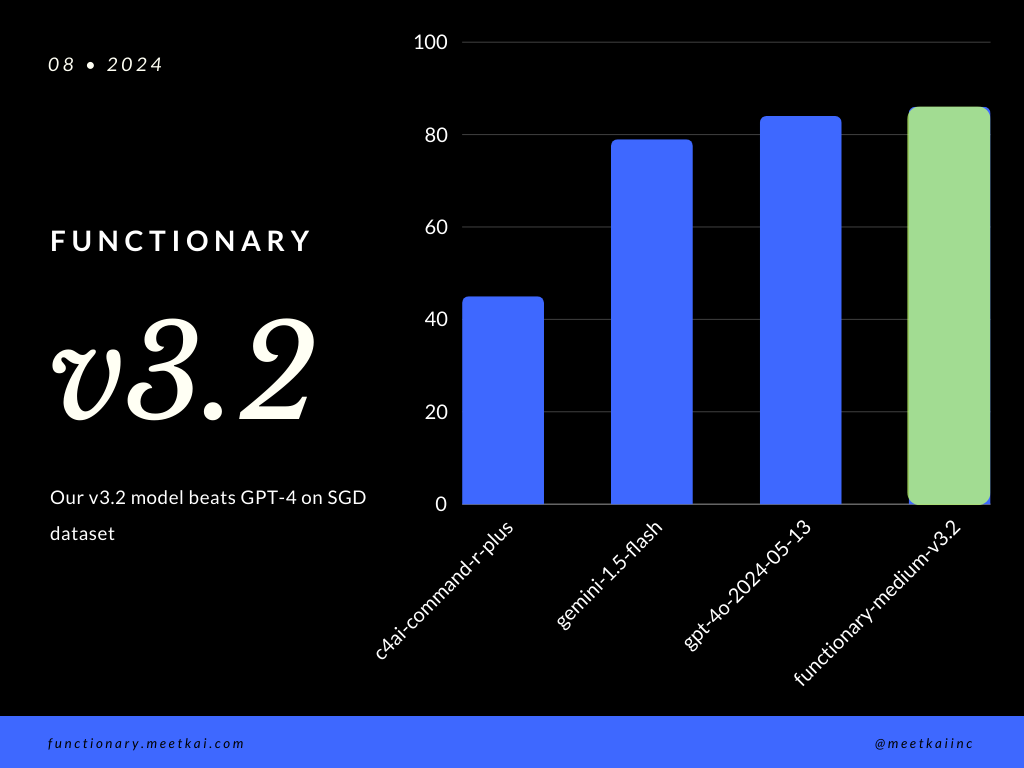
| Conjunto de datos | Nombre del modelo | Función de precisión de llamadas (nombre y argumentos) |
|---|---|---|
| Sgd | Meetkai/funcionario-medio-v3.1 | 88.11% |
| Sgd | GPT-4O-2024-05-13 | 82.75% |
| Sgd | Géminis-1.5 flash | 79.64% |
| Sgd | c4ai-command-r-plus | 45.66% |
Ver Readme de entrenamiento
Si bien no se aplica estrictamente, para garantizar una ejecución de funciones más segura , uno puede habilitar el muestreo de gramática para hacer cumplir la verificación de tipo. Los principales controles de seguridad deben hacerse en las funciones/acciones mismas. Como la validación de la entrada dada, o la salida que se le dará al modelo.


