harbor
v0.2.18 -

Executar sem esforço o LLM Backends, APIs, Frontends e Service com um comando.
O Harbor é um kit de ferramentas LLM em contêiner que permite executar o LLMS e serviços adicionais. Consiste em uma CLI e um aplicativo complementar que permite gerenciar e executar serviços de IA com facilidade.
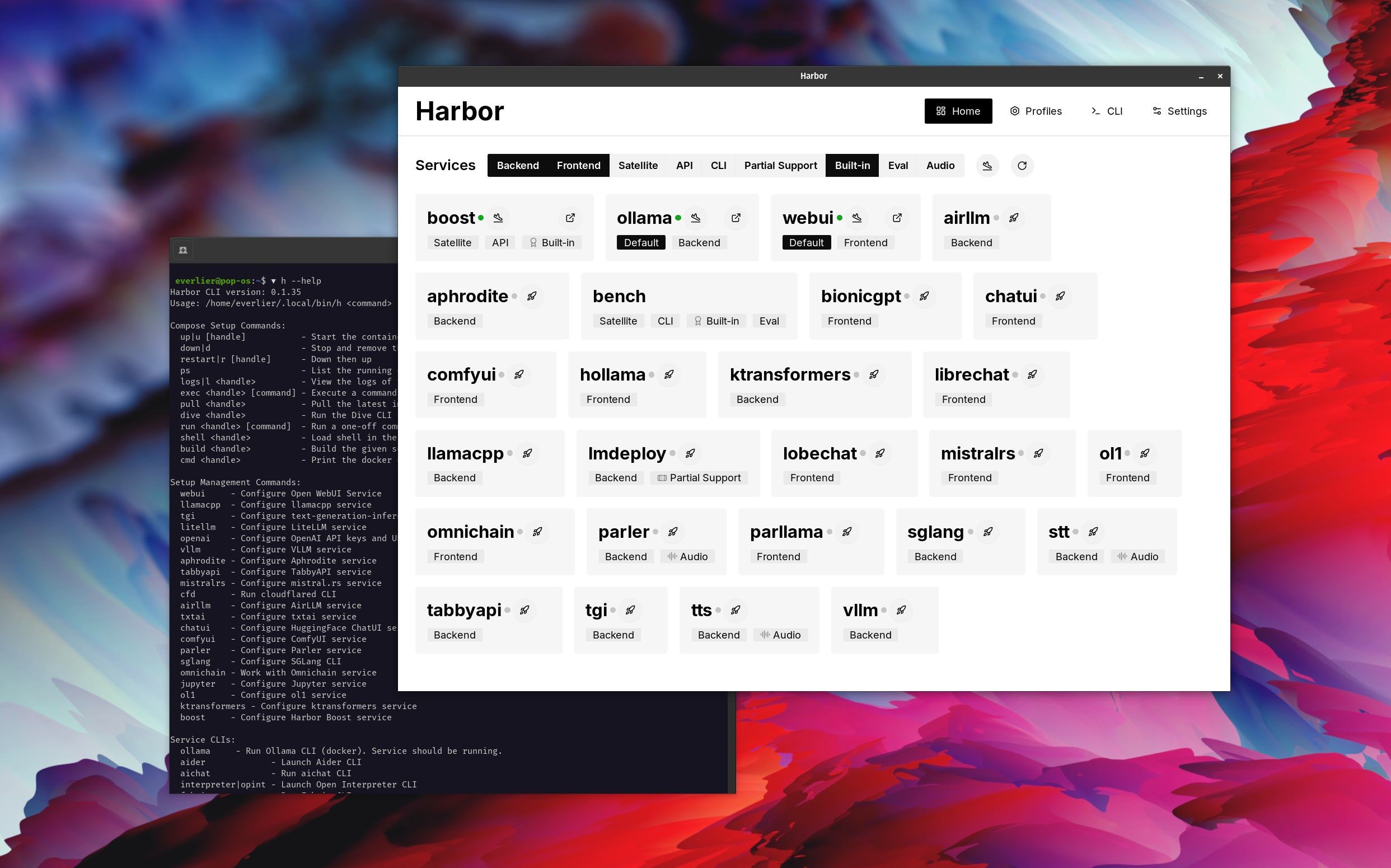
Open webui ⦁︎ confortyui ⦁︎ librechat ⦁︎ huggingface chatui ⦁︎ lobe chat ⦁︎ hollama ⦁︎ parllama ⦁︎ bionicgpt ⦁︎ qualquer coisa ⦁︎ bate -papo nio
Ollama ⦁︎ llama.cpp ⦁︎ vllm ⦁︎ Tabbyapi ⦁︎ Motor de Afrodite ⦁︎ Mistral.RS ⦁︎ Openedai-Estoque ⦁︎ Faster-Whisper-Server ⦁︎ Parler ⦁︎ Inferência de geração de texto ⦁︎ Lmdeploy ⦁︎ Airllm ⦁ SGLANG ⦁︎ Ktransformers ⦁︎ Nexa SDK
Banco do porto ⦁︎ Harbor Boost ⦁︎ Searxng ⦁︎ Perplexica ⦁︎ DIFY ⦁︎ PLANDEX ⦁︎ LITELLM ⦁︎ LANGFUSE ⦁︎ INTERPRETADOR DE ABERSO ⦁ ︎CLOUDLARED ⦁︎ CMDH ⦁︎ Tecido ⦁︎ TXTAI RAG ⦁︎ TEXTGRADGRGRADORD ⦁︎ AOCHAT ⦁ ︎ Omnichain ⦁︎ LM-Evaluation-Harness ⦁︎ Jupyterlab ⦁︎ ol1 ⦁︎ OpenHands ⦁︎ Litlytics ⦁︎ RepOpack ⦁︎ n8n ⦁︎ parafuso.Now ⦁︎ Open Webui Pipelines ⦁︎ QDRANT ⦁︎ K6 ⦁︎ PromptFoo ⦁︎ webtop ⦁︎ omnipars ⦁︎ Flowise
Consulte a documentação de serviços para obter uma breve visão geral de cada um.
# Run Harbor with default services:
# Open WebUI and Ollama
harbor up
# Run Harbor with additional services
# Running SearXNG automatically enables Web RAG in Open WebUI
harbor up searxng
# Run additional/alternative LLM Inference backends
# Open Webui is automatically connected to them.
harbor up llamacpp tgi litellm vllm tabbyapi aphrodite sglang ktransformers
# Run different Frontends
harbor up librechat chatui bionicgpt hollama
# Get a free quality boost with
# built-in optimizing proxy
harbor up boost
# Use FLUX in Open WebUI in one command
harbor up comfyui
# Use custom models for supported backends
harbor llamacpp model https://huggingface.co/user/repo/model.gguf
# Shortcut to HF Hub to find the models
harbor hf find gguf gemma-2
# Use HFDownloader and official HF CLI to download models
harbor hf dl -m google/gemma-2-2b-it -c 10 -s ./hf
harbor hf download google/gemma-2-2b-it
# Where possible, cache is shared between the services
harbor tgi model google/gemma-2-2b-it
harbor vllm model google/gemma-2-2b-it
harbor aphrodite model google/gemma-2-2b-it
harbor tabbyapi model google/gemma-2-2b-it-exl2
harbor mistralrs model google/gemma-2-2b-it
harbor opint model google/gemma-2-2b-it
harbor sglang model google/gemma-2-2b-it
# Convenience tools for docker setup
harbor logs llamacpp
harbor exec llamacpp ./scripts/llama-bench --help
harbor shell vllm
# Tell your shell exactly what you think about it
harbor opint
harbor aider
harbor aichat
harbor cmdh
# Use fabric to LLM-ify your linux pipes
cat ./file.md | harbor fabric --pattern extract_extraordinary_claims | grep " LK99 "
# Access service CLIs without installing them
harbor hf scan-cache
harbor ollama list
# Open services from the CLI
harbor open webui
harbor open llamacpp
# Print yourself a QR to quickly open the
# service on your phone
harbor qr
# Feeling adventurous? Expose your harbor
# to the internet
harbor tunnel
# Config management
harbor config list
harbor config set webui.host.port 8080
# Create and manage config profiles
harbor profile save l370b
harbor profile use default
# Lookup recently used harbor commands
harbor history
# Eject from Harbor into a standalone Docker Compose setup
# Will export related services and variables into a standalone file.
harbor eject searxng llamacpp > docker-compose.harbor.yml
# Run a build-in LLM benchmark with
# your own tasks
harbor bench run
# Gimmick/Fun Area
# Argument scrambling, below commands are all the same as above
# Harbor doesn't care if it's "vllm model" or "model vllm", it'll
# figure it out.
harbor model vllm
harbor vllm model
harbor config get webui.name
harbor get config webui_name
harbor tabbyapi shell
harbor shell tabbyapi
# 50% gimmick, 50% useful
# Ask harbor about itself
harbor how to ping ollama container from the webui ? Na demonstração, o Harbor App é usado para iniciar uma pilha padrão com os serviços OLLAMA e OPEN Webui. Mais tarde, o Searxng também é iniciado e o Webui pode se conectar a ele para o pano da web imediatamente. Depois disso, o Harbor Boost também é iniciado e conectado ao WebUI automaticamente para induzir resultados mais criativos. Como uma etapa final, a configuração do porto é ajustada no aplicativo para o módulo klmbr no impulso do porto, o que torna a saída inigualável para o LLM (mas ainda não resistente para os seres humanos).
Se você se sentir confortável com a administração Docker e Linux - provavelmente não precisa de porto em si para gerenciar seu ambiente LLM local. No entanto, é provável que você finalmente chegue a uma solução semelhante. Eu sei disso de fato, já que eu estava usando uma configuração praticamente semelhante, apenas sem todos os apitos e sinos.
O porto não foi projetado como uma solução de implantação, mas como um ajudante para o ambiente de desenvolvimento local do LLM. É um bom ponto de partida para experimentar o LLMS e serviços relacionados.
Mais tarde, você pode ejetar do porto e usar os serviços em sua própria configuração ou continuar usando o Harbor como base para sua própria configuração.
Este projeto consiste em uma CLI de shell bastante grande, arquivo .env bastante pequeno e enourmous (para uma quantidade de repositório) de arquivos docker-compose .
hf , ollama , etc.) via Docker sem instalaçãoharbor eject

