 Peta Jalan AI Generatif
Peta Jalan AI Generatif
Panduan Pembelajaran Subyektif untuk Penelitian AI Generatif termasuk daftar artikel dan proyek yang dikuratori
AI generatif adalah topik hangat saat ini dan peta jalan ini dirancang untuk membantu pemula dengan cepat mendapatkan pengetahuan dasar dan menemukan sumber daya yang berguna dari AI generatif. Bahkan para ahli dipersilakan untuk merujuk pada peta jalan ini untuk mengingat pengetahuan lama dan mengembangkan ide -ide baru.
Tabel konten
- Pengetahuan latar belakang
- Neural Networks Inference and Training
- Arsitektur Transformer
- Model berbasis transformator umum
- Aneka ragam
- Model Bahasa Besar (LLM)
- Pretraining dan fine-tuning
- Dorongan
- Evaluasi
- Berurusan dengan konteks yang panjang
- Fine-tuning yang efisien
- Penggabungan model
- Generasi yang efisien
- Pengeditan Pengetahuan
- Agen bertenaga LLM
- Temuan
- Tantangan terbuka
- Model Difusi
- Pembuatan gambar
- Pembuatan video
- Generasi audio
- Pretraining dan fine-tuning
- Evaluasi
- Generasi yang efisien
- Pengeditan Pengetahuan
- Tantangan terbuka
- Model multimodal besar (LMM)
- Arsitektur model
- Menuju agen yang diwujudkan
- Tantangan terbuka
- Di luar transformer
- Parameter terstruktur secara implisit
- Arsitektur model baru
Pengetahuan latar belakang
Bagian ini akan membantu Anda mempelajari atau mendapatkan kembali pengetahuan dasar jaringan saraf (misalnya, backpropagation), membuat Anda terbiasa dengan arsitektur transformator, dan menggambarkan beberapa model berbasis transformator umum.
Neural Networks Inference and Training
Apakah Anda sangat akrab dengan struktur jaringan saraf klasik berikut?
- Perceptron multi-layer (MLP)
- Convolutional Neural Network (CNN)
- Recurrent Neural Network (RNN)
Jika demikian, Anda harus dapat menjawab pertanyaan -pertanyaan ini:
- Mengapa CNN bekerja lebih baik daripada MLP pada gambar?
- Mengapa RNN bekerja lebih baik daripada MLP pada data seri-waktu?
- Apa perbedaan antara Gru dan LSTM?
Backpropagation (BP) adalah dasar pelatihan NN. Anda tidak akan menjadi ahli AI jika Anda tidak mengerti BP . Ada banyak buku teks dan tutorial online yang mengajarkan BP, tetapi sayangnya, kebanyakan dari mereka tidak menyajikan formula dalam bentuk yang divektor/tarik. Formula BP dari lapisan NN memang rapi seperti formula lulus ke depan. Ini persis bagaimana BP diimplementasikan dan harus diimplementasikan. Untuk memahami BP, silakan baca materi berikut:
- Jaringan saraf dan pembelajaran mendalam [Bab 3.2 terutama 3.2.6]
- MEPROP: Perbanyakan punggung yang dibuang untuk pembelajaran mendalam yang dipercepat dengan pengurangan overfitting (ICML 2017) [Bagian 2.1]
- Resprop: Reuse Backpropagation (CVPR 2020) [Bagian 3.1]
Jika Anda memahami BP, Anda harus dapat menjawab pertanyaan -pertanyaan ini:
- Bagaimana Anda menggambarkan BP lapisan konvolusional?
- Berapa rasio biaya komputasi (yaitu, jumlah operasi titik mengambang) antara umpan ke depan dan lulus mundur dari lapisan padat?
- Bagaimana Anda menggambarkan BP MLP dengan dua lapisan padat berbagi matriks berat yang sama?
Arsitektur Transformer
Transformer adalah arsitektur dasar dari model generatif besar yang ada. Penting untuk memahami setiap komponen dalam transformator. Baca materi berikut:
- Perhatian adalah yang Anda butuhkan (Neurips 2017) [Kertas Asli]
- Transformer Explainer: Pembelajaran interaktif model teks-generatif [tutorial interaktif]
- Gambar bernilai 16x16 kata: Transformers untuk pengenalan gambar pada skala (ICLR 2021) [Vision Transformer]
- Terjemahan mesin saraf dengan transformator dan keras [penjelasan hebat untuk perhatian multi -kepala (MHA)]
- Jepit blok transformator [mari kita berlatih menghitung jepit]
- Decoding Fast Transformer: Satu-head adalah semua yang Anda butuhkan [Multi-Query Attention (MQA)]
- GQA: Pelatihan Generalized Multi-Query Transformer Models dari multi-head checkpoints [Grouped-Query Attention (GQA)]
- Transformator yang ditingkatkan dengan embedding posisi putar [Memahami embedding posisi]
- Rotary Embeddings: Revolusi Relatif [Memahami Embedding Posisi]
- Guru Memaksa VS Terjadwal Sampling vs Mode Normal [Guru Memaksa dalam Pelatihan Transformer]
- Flexgen: Inferensi generatif throughput tinggi dari model bahasa besar dengan GPU tunggal [lihat Bagian 3 - Inferensi Generatif untuk mempelajari bagaimana pembuatan peform LLMS berdasarkan cache KV]
- Pengkodean Posisi Kontekstual: Belajar menghitung apa yang penting [pengkodean posisi yang bergantung pada konteks]
Jika Anda memahami Transformers, Anda harus dapat menjawab pertanyaan -pertanyaan ini:
- Apa pro dan kontra transformer dibandingkan dengan RNN? (secara bersamaan menghadiri, pelatihan paralelisme, kompleksitas)
- Bisakah Anda mensakulasikan jepit GQA? Lihat kapan itu menurun ke MHA dan MQA?
- Apa motivasi MQA dan GQA?
- Seperti apa masker perhatian kausal itu dan mengapa?
- Bagaimana Anda menggambarkan pelatihan transformer khusus dekoder langkah demi langkah?
- Mengapa tali lebih baik daripada pengkodean posisi sinusoidal?
Model berbasis transformator umum
- Belajar model visual yang dapat ditransfer dari pengawasan bahasa alami [klip]
- Properti Muncul dalam Transformers Penglihatan Sendiri (ICCV 2021) [Dino]
- Autoencoder bertopeng adalah pelajar penglihatan yang dapat diskalakan (CVPR 2022) [MAE]
- Visi penskalaan dengan campuran para ahli yang jarang (Neurips 2021) [MOE]
- Campuran-Depths: Mengalokasikan komputasi secara dinamis dalam model bahasa berbasis transformator [MOD]
Aneka ragam
Einsum mudah dan berguna [tutorial yang bagus untuk menggunakan Einsum/Einops]
Open-end-ending sangat penting untuk kecerdasan manusia super buatan (ICML 2024) [Pikiran tentang pencapaian AI Superhuman]
Tingkat AGI untuk mengoperasionalkan kemajuan di jalan menuju AGI
Model Bahasa Besar (LLM)
LLMS adalah transformator. Mereka dapat dikategorikan ke dalam arsitektur Encoder-Only, Encoder-Decoder, dan Decoder saja, seperti yang ditunjukkan pada pohon evolusi LLM di bawah [sumber gambar]. Periksa makalah tonggak LLMS.
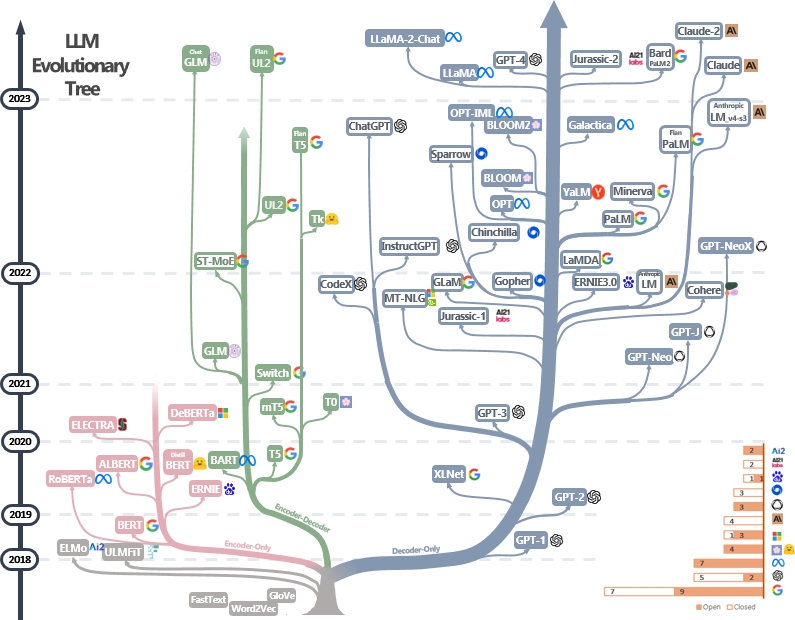
Model Encoder-only dapat digunakan untuk mengekstraksi fitur kalimat tetapi tidak memiliki kekuatan generatif. Model Encoder-Decoder dan Decoder saja digunakan untuk pembuatan teks. Secara khusus, sebagian besar LLM yang ada lebih suka struktur decoder-only karena kekuatan repesentasional yang lebih kuat. Secara intuitif, model encoder-decoder dapat dianggap sebagai versi jarang dari model decoder-only dan informasi lebih banyak meluruh dari encoder ke decoder. Periksa makalah ini untuk detail lebih lanjut.
Pretraining dan finetuning
LLM biasanya pretrained dari triliunan token teks oleh penerbit model untuk menginternalisasi struktur bahasa alami. Pengembang model saat ini juga melakukan penyempurnaan instruksional dan pembelajaran penguatan dari umpan balik manusia (RLHF) untuk mengajarkan model untuk mengikuti instruksi manusia dan menghasilkan jawaban yang selaras dengan preferensi manusia. Pengguna kemudian dapat mengunduh model yang diterbitkan dan finetune di set data pribadi kecil (misalnya, dialog film). Karena sejumlah besar data, pretraining membutuhkan sumber daya komputasi besar -besaran (misalnya, lebih dari ribuan GPU) yang tidak terjangkau oleh individu. Di sisi lain, fine-tuning kurang haus sumber daya dan dapat dilakukan dengan beberapa GPU.
Bahan-bahan berikut dapat membantu Anda memahami proses pretraining dan fine-tuning:
- Bert: Pra-pelatihan transformator dua arah yang mendalam untuk pemahaman bahasa [pretraining dan finetuning LLMS khusus enkoder]
- Model Bahasa yang Di-Instruksi Penskalaan [pretraining dan finetuning instruksional]
- Menggambarkan pembelajaran penguatan dari umpan balik manusia (RLHF)
- Model bahasa adalah pelajar beberapa-shot [decoder-only llms] [中文导读 oleh 李沐]
Lebih banyak tutorial dapat ditemukan di sini.
Dorongan
Teknik yang mendorong untuk LLM melibatkan membuat teks input dengan cara yang memandu model untuk menghasilkan respons atau output yang diinginkan. Berikut adalah sumber daya yang berguna untuk membantu Anda menulis petunjuk yang lebih baik:
- [DAIR.AI] Panduan Teknik Prompt
- Prompt chatgpt yang luar biasa - kumpulan contoh prompt yang akan digunakan dengan model chatgpt
- Perkumpulan deliberatif yang luar biasa - Bagaimana cara meminta LLM untuk menghasilkan penalaran yang dapat diandalkan dan membuat keputusan yang responsif -responsif
- AutoPrompt - Metode otomatis berdasarkan pencarian yang dipandu gradien untuk membuat petunjuk untuk beragam tugas NLP.
Evaluasi
Alat evaluasi untuk model bahasa besar membantu menilai kinerja, kemampuan, dan keterbatasan mereka di berbagai tugas dan dataset. Berikut adalah beberapa strategi evaluasi umum:
Metrik Evaluasi Otomatis : Metrik ini menilai kinerja model secara otomatis tanpa intervensi manusia. Metrik umum meliputi:
- Bleu: Mengukur kesamaan antara teks yang dihasilkan dan teks referensi berdasarkan tumpang tindih N-gram.
- Rouge: Mengevaluasi ringkasan teks dengan membandingkan N-gram yang tumpang tindih antara ringkasan yang dihasilkan dan referensi.
- Kebingungan: Mengukur seberapa baik model bahasa memprediksi sampel teks. Kebingungan yang lebih rendah menunjukkan kinerja yang lebih baik. Ini setara dengan eksponensial entri-entropi antara data dan prediksi model.
- Skor F1: Mengukur keseimbangan antara presisi dan penarikan dalam tugas -tugas seperti klasifikasi teks atau pengenalan entitas yang disebutkan.
Evaluasi manusia : Penilaian manusia sangat penting untuk menilai kualitas teks yang dihasilkan secara komprehensif. Metode evaluasi manusia yang umum meliputi:
- Peringkat Manusia : Tingkat annotator manusia yang dihasilkan teks berdasarkan kriteria seperti kelancaran, koherensi, relevansi, dan tata bahasa.
- Platform Crowdsourcing : Platform seperti Amazon Mechanical Turk atau Gambar Delapan memfasilitasi evaluasi manusia skala besar dengan anotasi crowdsourcing.
- Evaluasi Ahli : Pakar domain menilai output model untuk mengukur kesesuaiannya untuk aplikasi atau tugas tertentu.
Dataset Benchmark : Dataset standar memungkinkan perbandingan model yang adil di berbagai tugas dan domain. Contohnya termasuk:
- Triviaqa: Dataset tantangan yang diawasi dengan skala besar untuk pemahaman membaca
- Hellaswag: Bisakah mesin benar -benar menyelesaikan kalimat Anda?
- GSM8K: Pelatihan verifikasi untuk menyelesaikan masalah kata matematika
- Daftar lengkap dapat ditemukan di sini
Alat Analisis Model: Alat untuk Menganalisis Perilaku dan Kinerja Model meliputi:
- Interpretabilitas Otomatis - Kode untuk secara otomatis menghasilkan, mensimulasikan, dan mencetak penjelasan perilaku neuron
- Visualisasi LLM - Visualisasi LLM di level rendah.
- Analisis Perhatian - Menganalisis peta perhatian dari Bert Transformer.
- Neuron Viewer - Alat untuk melihat aktivasi dan penjelasan neuron.
Daftar lengkap dapat ditemukan di sini
Kerangka kerja evaluasi standar untuk LLM yang ada meliputi:
- LM-Evaluasi-Harness-Kerangka kerja untuk evaluasi beberapa-shot dari model bahasa.
- Lighteval - Rangkaian evaluasi LLM yang ringan yang telah digunakan wajah memeluk secara internal.
- Olmo -eval - Repositori untuk mengevaluasi model bahasa terbuka.
- Instruce-Eval-Repositori ini berisi kode untuk mengevaluasi secara kuantitatif model yang disesuaikan dengan instruksi seperti alpaca dan Flan-T5 pada tugas yang diadakan.
Berurusan dengan konteks yang panjang
Berurusan dengan konteks panjang menimbulkan tantangan bagi model bahasa besar karena keterbatasan dalam memori dan kapasitas pemrosesan. Teknik yang ada meliputi:
- Transformer yang efisien
- Longformer: Transformator Dokumen Panjang
- Reformer: The Efficient Transformer (ICLR 2020)
- Model ruang negara
- Transformers adalah RNNs: Transformator autoregresif cepat dengan perhatian linier (ICML 2020)
- Memikirkan kembali perhatian dengan pemain
- Ekstrapolasi panjang
- Mamba: Pemodelan Urutan Linear-Time Dengan Ruang Negara Selektif
- Roformer: Transformator yang ditingkatkan dengan embedding posisi putar
- Benang: Perpanjangan Jendela Konteks Efisien dari Model Bahasa Besar
- Memori jangka panjang
- MemoryBank: Meningkatkan model bahasa besar dengan memori jangka panjang
- Melepaskan kapasitas input panjang tak terbatas untuk model bahasa skala besar dengan sistem memori yang dikendalikan sendiri
Daftar lengkap dapat ditemukan di sini
Finetuning yang efisien
Metode parameter-efisien fine-tuning (PEFT) memungkinkan adaptasi yang efisien dari model pretrained besar ke berbagai aplikasi hilir dengan hanya menyempurnakan sejumlah kecil parameter model (tambahan) alih-alih semua parameter model:
- Tuning Prompt: Kekuatan Skala untuk Parameter-Efisien Penyetelan Prompt
- Tuning awalan: awalan tuning: mengoptimalkan permintaan kontinu untuk pembuatan
- Lora: Lora: Adaptasi rendah dari model bahasa besar
- Menuju pandangan terpadu dari pembelajaran transfer yang efisien parameter
- Lora belajar lebih sedikit dan lebih sedikit lupa
Lebih banyak pekerjaan dapat ditemukan di Huggingface Peft Paper Collection dan sangat disarankan untuk berlatih dengan Huggingface Peft API.
Penggabungan model
Penggabungan model mengacu pada penggabungan dua atau lebih LLM yang dilatih pada tugas yang berbeda menjadi satu LLM tunggal. Teknik ini bertujuan untuk memanfaatkan kekuatan dan pengetahuan dari berbagai model untuk menciptakan model yang lebih kuat dan mampu. Misalnya, LLM untuk pembuatan kode dan LLM lain untuk pemecahan matematika prolem dapat digabungkan sehingga model gabungan mampu melakukan pembuatan kode dan pemecahan masalah matematika.
Penggabungan model menarik karena dapat dicapai secara efektif dengan algoritma yang sangat sederhana dan murah (misalnya, kombinasi linier bobot model). Berikut adalah beberapa makalah yang representatif dan bahan bacaan:
- Sup Model: Rata-rata bobot dari beberapa model yang disesuaikan meningkatkan akurasi tanpa meningkatkan waktu inferensi
- Mengedit model dengan aritmatika tugas
- Gabungkan model bahasa besar dengan mergekit
Lebih banyak makalah tentang penggabungan model dapat ditemukan di sini
Generasi yang efisien
Decoding decoding LLM sangat penting untuk meningkatkan kecepatan dan efisiensi inferensi, terutama dalam aplikasi real-time atau latensi-sensitif. Berikut adalah beberapa pekerjaan representatif untuk mempercepat proses decoding LLMS:
- Deja Vu: Sparsity kontekstual untuk LLM yang efisien pada waktu inferensi (ICML 2023 oral)
- Llmlingua: compressing prompts untuk inferensi yang dipercepat dari model bahasa besar (EMNLP 2023)
- Model bahasa streaming yang efisien dengan wastafel perhatian
- Specinfer: Accelerating Generative LLM Melayani dengan inferensi spekulatif dan verifikasi pohon token
- Medusa: Kerangka kerja akselerasi inferensi LLM sederhana dengan beberapa kepala decoding
- Model bahasa besar yang lebih baik & lebih cepat melalui prediksi multi-token
- Lapisan Lapisan: Mengaktifkan inferensi keluar awal dan decoding spekulatif diri
Lebih banyak pekerjaan tentang mempercepat decoding LLM dapat ditemukan melalui tautan 1 dan tautan 2.
Pengeditan Pengetahuan
Pengeditan pengetahuan bertujuan untuk memodifikasi perilaku LLMS secara efisien, seperti mengurangi bias dan merevisi korelasi yang dipelajari. Ini mencakup banyak topik seperti lokalisasi pengetahuan dan tidak belajar. Pekerjaan perwakilan meliputi:
- Pengeditan model berbasis memori pada skala (ICML 2022)
- Transformer-Patcher: Satu kesalahan bernilai satu neuron (ICLR 2023)
- Pengeditan besar -besaran untuk model bahasa besar melalui meta learning (ICLR 2024)
- Kerangka kerja terpadu untuk mengedit model
- Lapisan feed-forward transformer adalah kenangan nilai kunci (EMNLP 2021)
- Memori pengeditan massal dalam transformator
Lebih banyak makalah dapat ditemukan di sini.
Agen bertenaga LLM
Dengan menerima pelatihan besar -besaran, LLMS mencerna pengetahuan dunia dan dapat mengikuti instruksi input secara tepat. Dengan kemampuan luar biasa ini, LLM dapat bermain sebagai agen yang dimungkinkan untuk menyelesaikan tugas kompleks secara otonom (dan kolaboratif), atau mensimulasikan interaksi manusia. Berikut adalah beberapa makalah representatif dari agen LLM:
- Agen Generatif: Simulacra Interaktif Perilaku Manusia (UIST 2023) [LLMS mensimulasikan masyarakat manusia dalam video game]
- Sotopia: Evaluasi Interaktif untuk Kecerdasan Sosial dalam Agen Bahasa (ICLR 2024) [LLMS mensimulasikan interaksi sosial]
- Voyager: agen terwujud terbuka dengan model bahasa besar [llms hidup di dunia minecraft]
- Model Bahasa Besar Sebagai Pembuat Alat (ICLR 2024) [LLMS membuat alat yang dapat digunakan kembali sendiri (misalnya, dalam fungsi Python) untuk pemecahan masalah]
- Metagpt: Pemrograman Meta untuk Kerangka Kolaboratif Multi-Agen [LLMS sebagai tim untuk pengembangan perangkat lunak otomatis]
- Webarena: Lingkungan web yang realistis untuk membangun agen otonom (ICLR 2024) [LLMS menggunakan aplikasi web]
- Mobile-ENV: Platform evaluasi dan tolok ukur untuk interaksi LLM-GUI [LLMS menggunakan aplikasi seluler]
- HuggingGPT: Memecahkan tugas AI dengan chatgpt dan teman-temannya di Face Hugging (Neurips 2023) [LLMS mencari model dalam permukaan pelukan untuk pemecahan masalah]
- Agen: Mengembangkan agen berbasis model bahasa besar di berbagai lingkungan [berbagai lingkungan dan tugas interaktif untuk agen berbasis LLM]
Daftar lengkap makalah, platform, dan alat evaluasi dapat ditemukan di sini.
Temuan
- Transformator Anda diam -diam linier
- Tidak semua fitur model bahasa linier
- Kan atau MLP: Perbandingan yang lebih adil
- Lapisan transformator sebagai pelukis
- Model Bahasa Visi Buta
Tantangan terbuka
LLMS menghadapi beberapa tantangan terbuka yang secara aktif oleh para peneliti dan pengembang bekerja. Tantangan ini meliputi:
- Halusinasi
- Survei komprehensif tentang teknik mitigasi halusinasi dalam model bahasa besar
- Kompresi model
- Survei komprehensif algoritma kompresi untuk model bahasa
- Evaluasi
- Mengevaluasi Model Bahasa Besar: Survei Komprehensif
- Pemikiran
- Survei Penalaran dengan Model Yayasan
- Kemampuan dijelaskan
- Dari pemahaman hingga pemanfaatan: survei tentang kemampuan menjelaskan untuk model bahasa besar
- Keadilan
- Survei tentang keadilan dalam model bahasa besar
- Faktualitas
- Survei tentang Faktualitas dalam Model Bahasa Besar: Pengetahuan, Pengambilan dan Spesialisasi Domain
- Integrasi pengetahuan
- Tren dalam integrasi pengetahuan dan model bahasa besar: survei dan taksonomi metode, tolok ukur, dan aplikasi
Daftar lengkap dapat ditemukan di sini.
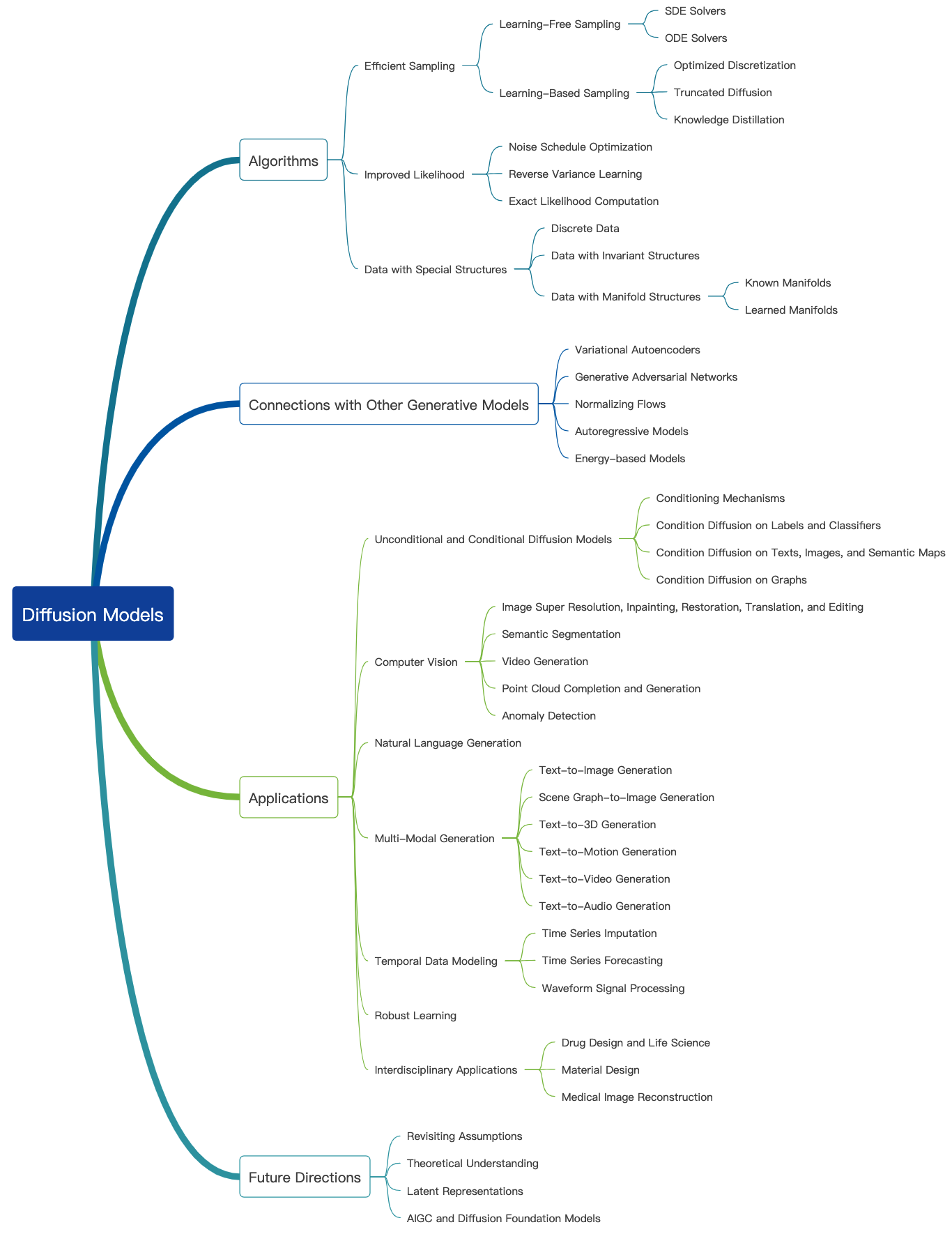
Model Difusi
Model difusi bertujuan untuk mendekati distribusi probabilitas dari domain data yang diberikan, dan menyediakan cara untuk menghasilkan sampel dari distribusi yang diperkirakan. Tujuan mereka mirip dengan model generatif populer lainnya, seperti VAE, GANS, dan arus normalisasi.
Aliran kerja model difusi ditampilkan dengan dua proses:
- Proses Maju (Proses Difusi): Ini secara progresif menerapkan noise ke data input asli langkah demi langkah sampai data sepenuhnya menjadi noise.
- Proses terbalik (proses denoising): Model NN (misalnya, CNN atau transformer) dilatih untuk memperkirakan kebisingan yang diterapkan pada setiap langkah selama proses maju. Model NN yang terlatih ini kemudian dapat digunakan untuk menghasilkan data dari input noise. Model difusi yang ada juga dapat menerima sinyal lain (misalnya, permintaan teks dari pengguna) untuk mengkondisikan pembuatan data.
Periksa blog yang luar biasa ini dan lebih banyak tutorial pengantar dapat ditemukan di sini. Model difusi dapat digunakan untuk menghasilkan gambar, audio, video, dan banyak lagi, dan ada banyak subbidang yang terkait dengan model difusi seperti yang ditunjukkan di bawah ini [sumber gambar]:
Pembuatan gambar
Berikut adalah beberapa makalah yang representatif dari model difusi untuk pembuatan gambar:
- Sintesis gambar resolusi tinggi dengan model difusi laten (CVPR 2022)
- Palet: Model Difusi Gambar-ke-Gambar (Siggraph 2022)
- Gambar super-resolusi melalui penyempurnaan berulang
- Menggunakan Model Probabilistik Difusi Denoising (CVPR 2022)
- Menambahkan kontrol bersyarat ke model difusi teks-ke-gambar (ICCV 2023)
Lebih banyak makalah dapat ditemukan di sini.
Pembuatan video
Berikut adalah beberapa makalah yang representatif dari model difusi untuk pembuatan video:
- Model Difusi Video
- Pemodelan difusi fleksibel dari video panjang (Neurips 2022)
- Menskalakan Model Difusi Video Laten ke Dataset Besar
- I2VGen-XL: Sintesis gambar-ke-video berkualitas tinggi melalui model difusi bertingkat
Lebih banyak makalah dapat ditemukan di sini.
Generasi audio
Berikut adalah beberapa makalah yang representatif dari model difusi untuk pembuatan audio:
- Grad-TTS: Model probabilistik difusi untuk teks-ke-kekuatan
- Pembuatan Teks-ke-Audio Menggunakan Instruksi-Tuned LLM dan Model Difusi Laten
- Pengkondisian Suara Zero-Shot untuk Denoising Difusion TTS Model
- Editts: Pengeditan berbasis skor untuk teks-ke-kekuatan yang dapat dikendalikan
- Prodiff: Model Difusi Cepat Progresif untuk Teks Kualitas Tinggi
Lebih banyak makalah dapat ditemukan di sini.
Pretraining dan finetuning
Mirip dengan model generatif besar lainnya, model difusi juga pretrained pada sejumlah besar data web (misalnya, dataset LAION-5B) dan mengkonsumsi sumber daya komputasi besar-besaran. Pengguna dapat mengunduh bobot yang dirilis selanjutnya dapat menyempurnakan model pada set data pribadi.
Berikut adalah beberapa makalah yang representatif dari penyempurnaan model difusi yang efisien:
- DreamBooth: Model difusi teks-ke-gambar yang menyempurnakan untuk generasi yang didorong oleh subjek (CVPR 2023)
- Gambar bernilai satu kata: Personalisasi pembuatan teks-ke-gambar menggunakan Inversi Tekstual (ICLR 2023)
- Difusi Kustom: Kustomisasi multi-konsep difusi teks-ke-gambar (CVPR 2023)
- Mengontrol difusi teks-ke-gambar dengan finetuning ortogonal (Neurips 2023)
Lebih banyak makalah dapat ditemukan di sini.
Sangat disarankan untuk melakukan beberapa latihan dengan Huggingface Diffusers API.
Evaluasi
Di sini kita berbicara tentang evaluasi model difusi untuk pembuatan gambar. Banyak metrik kualitas gambar yang ada dapat diterapkan.
- Skor klip: Skor klip mengukur kompatibilitas pasangan capsi gambar. Skor klip yang lebih tinggi menyiratkan kompatibilitas yang lebih tinggi. Skor klip ditemukan memiliki korelasi tinggi dengan penilaian manusia.
- Fréchet Inception Distance (FID): FID bertujuan untuk mengukur seberapa mirip dua set data gambar. Itu dihitung dengan menghitung jarak fréchet antara dua Gauss yang dipasang untuk fitur representasi dari jaringan awal
- Klip Directional Kesamaan: Ini mengukur konsistensi perubahan antara kedua gambar (dalam ruang klip) dengan perubahan antara dua teks gambar.
Lebih banyak metrik kualitas gambar dan alat perhitungan dapat ditemukan di sini.
Generasi yang efisien
Model difusi memerlukan beberapa langkah ke depan untuk menghasilkan data, yang mahal. Berikut adalah beberapa makalah yang representatif dari model difusi untuk generasi yang efisien:
- Harus cepat saat menghasilkan data dengan model berbasis skor
- Sampling cepat model difusi dengan integrator eksponensial
- Mempelajari sampler cepat untuk model difusi dengan membedakan melalui kualitas sampel
- Model difusi yang mempercepat melalui penghentian awal proses difusi
Lebih banyak makalah dapat ditemukan di sini.
Pengeditan Pengetahuan
Berikut adalah beberapa makalah yang representatif dari pengeditan pengetahuan untuk model difusi:
- Menghapus Konsep dari Model Difusi (ICCV 2023)
- Mengedit konsep besar dalam model difusi teks-ke-gambar
- Lupakan-aku-tidak: Belajar melupakan dalam model difusi teks-ke-gambar
Lebih banyak makalah dapat ditemukan di sini.
Tantangan terbuka
Berikut adalah beberapa makalah survei yang berbicara tentang tantangan yang dihadapi oleh model difusi.
- Survei model pembuatan gambar berbasis difusi
- Survei tentang Model Difusi Video
- Keadaan seni pada model difusi untuk komputasi visual
- Model Difusi di NLP: Survei
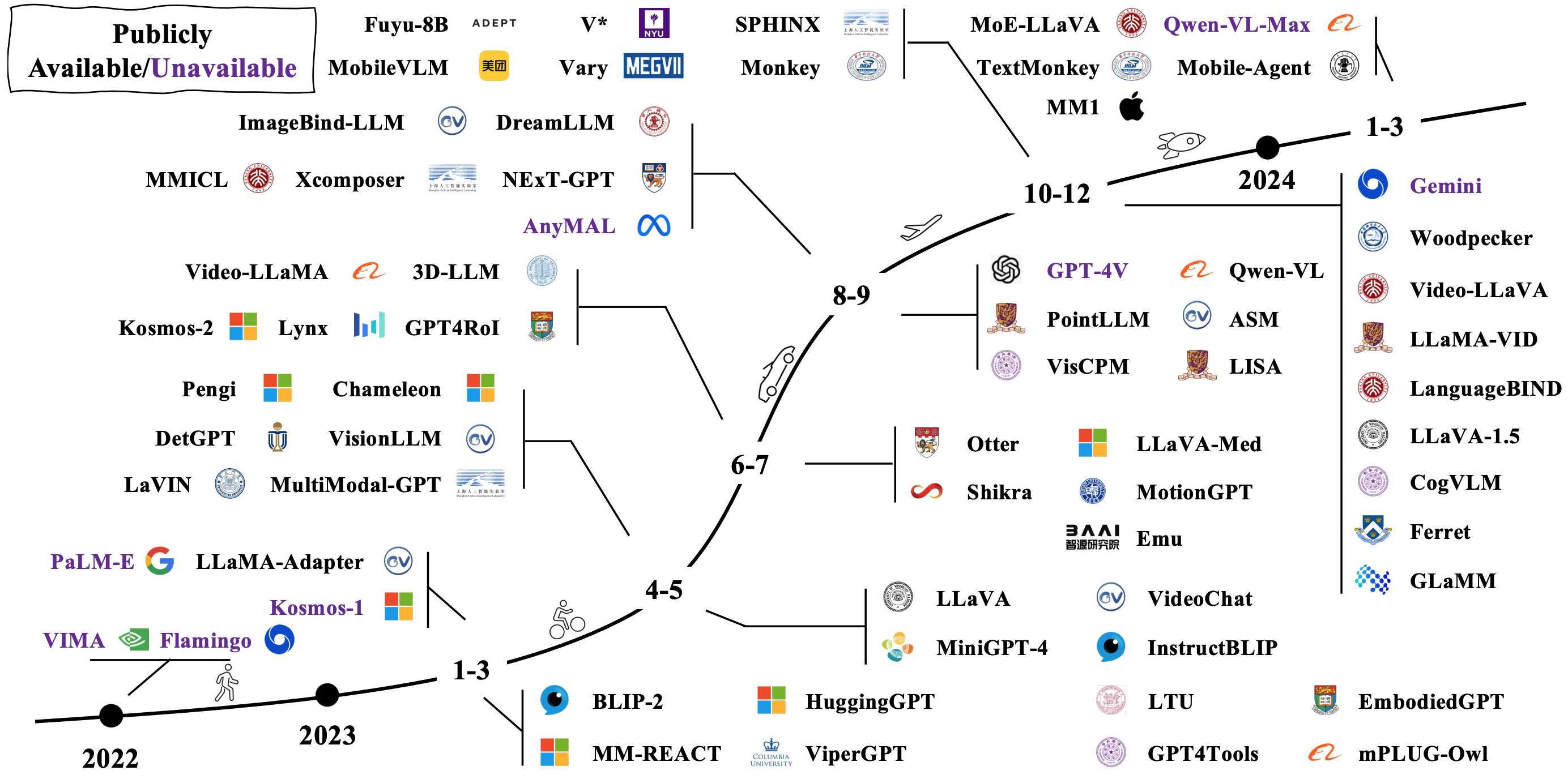
Model multimodal besar (LMM)
LMM khas dibangun dengan menghubungkan dan menyempurnakan model unimodal pretrained yang ada. Beberapa juga pretrained dari awal. Periksa bagaimana LMM berevolusi pada gambar di bawah [sumber gambar].
Arsitektur model
Ada banyak cara berbeda untuk mengontrak LMM. Arsitektur representatif meliputi:
- Model bahasa adalah antarmuka tujuan umum
- Flamingo: Model Bahasa Visual untuk Pembelajaran Beberapa-Shot (Neurips 2022)
- BLIP: Bootstrapping Pre-Training-Image-Image untuk Pemahaman dan Generasi Bahasa Visi Terpadu (ICML 2022)
- Blip-2: Bootstrapping Pre-Training Bahasa-Image dengan Encoder Gambar Beku dan Model Bahasa Besar (ICML 2023)
- MPLUG-OWL2: Merevolusi Model Bahasa Multi-Modal Besar dengan Kolaborasi Modalitas
- Florence-2: Memajukan representasi terpadu untuk berbagai tugas penglihatan
- Konektor padat untuk mllms
Lebih banyak makalah dapat ditemukan melalui tautan 1 dan tautan 2.
Menuju agen yang diwujudkan
Dengan menggabungkan LMM dengan robot, para peneliti bertujuan untuk mengembangkan sistem AI yang dapat memahami, alasan, dan bertindak atas dunia dengan cara yang lebih alami dan intuitif, dengan aplikasi potensial yang mencakup robotika, asisten virtual, kendaraan otonom, dan seterusnya. Berikut adalah beberapa karya representatif untuk mewujudkan AI yang diwujudkan dengan LMM:
- RT-1: Transformator Robotika untuk Kontrol Dunia Nyata pada Skala
- RT-2: Model-aksi penglihatan-aksi mentransfer pengetahuan web ke kontrol robot
- RT-H: Hirarki aksi menggunakan bahasa
- Palm-E: Model Bahasa Multimodal yang Diwujudkan
- Transik: Transfer Kebijakan Sim-to-Real dengan belajar dari koreksi online
Lebih banyak makalah dapat ditemukan melalui tautan 1 dan tautan 2.
Berikut adalah beberapa simulator dan set data populer untuk mengevaluasi kinerja LMMS untuk AI yang diwujudkan:
- Habitat 3.0: Platform simulasi AI yang diwujudkan untuk mempelajari tugas interaksi manusia-robot kolaboratif di lingkungan rumah
- Procthor-10k: Lingkungan rumah tangga interaktif 10k untuk AI yang diwujudkan
- Arnold: Benchmark untuk Pembelajaran Tugas Berdasarkan Bahasa dengan Keadaan Berkelanjutan dalam Adegan 3D Realistis
- Legent: platform terbuka untuk agen yang diwujudkan
- Robocasa: Simulasi skala besar dari tugas sehari-hari untuk robot generalis
Lebih banyak sumber daya dapat ditemukan di sini.
Tantangan terbuka
Berikut adalah beberapa makalah survei yang berbicara tentang tantangan terbuka untuk AI yang diwujudkan LMM:
- Kebangkitan dan potensi agen berbasis model bahasa besar: survei
- Navigasi bahasa penglihatan dengan kecerdasan yang diwujudkan: survei
- Survei AI yang diwujudkan: Dari simulator hingga tugas meneliti
- Survei tentang agen otonom berbasis LLM
- MindStorms dalam masyarakat pikiran berbasis bahasa alami
Di luar transformer
Para peneliti mencoba mengeksplorasi model baru selain transformator. Upaya ini mencakup parameter model penataan implisit dan mendefinisikan arsitektur model baru.
Parameter terstruktur yang tersirat
- Monarch Mixer: Revisiting Bert, Tanpa Perhatian atau MLP
- Mamba: Pemodelan Urutan Linear-Time Dengan Ruang Negara Selektif
Arsitektur model baru
- Hierarki Hyena: Menuju Model Bahasa Konvolusional yang Lebih Besar
- RWKV: menciptakan kembali RNN untuk era transformator
- Jaringan Retentif: Penerus Transformator Untuk Model Bahasa Besar
- Mamba: Pemodelan Urutan Linear-Time Dengan Ruang Negara Selektif
- Kan: Jaringan Kolmogorov -Arnold
- Transformer adalah SSM: Model Umum dan Algoritma Efisien Melalui Dualitas Ruang Negara Terstruktur
Berikut adalah tutorial yang luar biasa untuk model ruang negara.


