Generative AI Tutorial
1.0.0
記事やプロジェクトのキュレーションリストを含む生成AI研究のための主観的な学習ガイド
生成AIは今日のホットトピックであり、このロードマップは、初心者が基本的な知識を迅速に獲得し、生成AIの有用なリソースを見つけるのに役立つように設計されています。専門家でさえ、このロードマップを参照して、古い知識を思い出し、新しいアイデアを開発することを歓迎します。
このセクションは、ニューラルネットワーク(例えば、バックプロパゲーション)の基本的な知識を学習または取り戻し、トランスアーキテクチャに精通し、一般的な変圧器ベースのモデルを説明するのに役立ちます。
次の古典的なニューラルネットワーク構造に非常に精通していますか?
もしそうなら、あなたはこれらの質問に答えることができるはずです:
BackPropagation(BP)は、NNトレーニングのベースです。 BPを理解していなければ、AIの専門家にはなりません。 BPを教える多くの教科書やオンラインチュートリアルがありますが、残念ながら、それらのほとんどは、ベクトル化/テンソージ化されたフォームに式を提示しません。 NN層のBP式は、実際にその前方パスフォーミュラと同じくらいきれいです。これはまさにBPの実装方法であり、実装する必要があります。 BPを理解するには、次の資料をお読みください。
BPを理解している場合は、これらの質問に答えることができるはずです。
トランスは、既存の大規模生成モデルの基本アーキテクチャです。トランス内のすべてのコンポーネントを理解する必要があります。次の資料をお読みください:
トランスを理解している場合は、これらの質問に答えることができるはずです。
うつは簡単で便利です[うつく/einopsを使用するための優れたチュートリアル]
無制限は人工超人知能(ICML 2024)に不可欠です[超人的AIの達成に関する考え]
AGIへの道の進捗状況を運用するためのAGIのレベル
LLMは変圧器です。 [画像ソース]のLLM進化ツリーに示すように、それらはエンコーダーのみ、エンコーダデコーダー、デコーダーのみのアーキテクチャに分類できます。 LLMSのマイルストーンペーパーを確認してください。
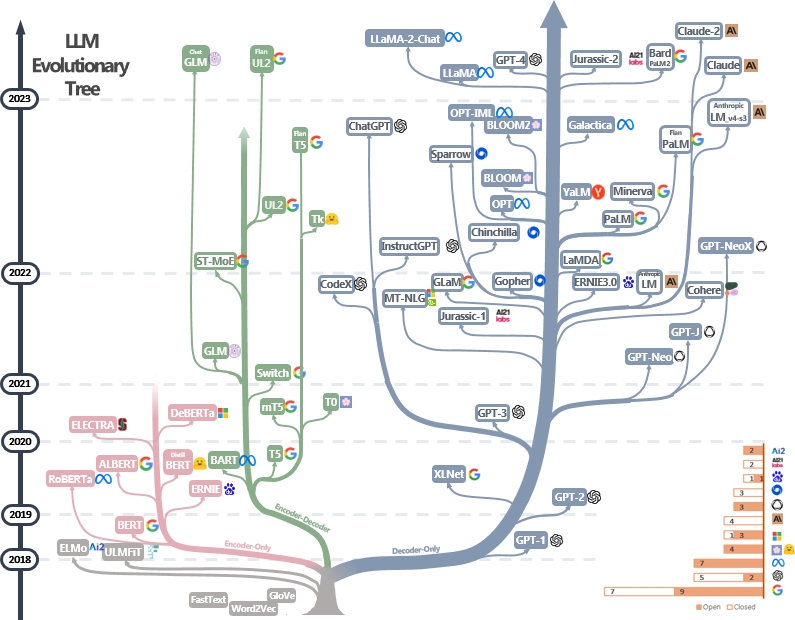
エンコーダのみのモデルを使用して文の機能を抽出できますが、生成パワーがありません。エンコーダデコーダーとデコーダーのみのモデルは、テキスト生成に使用されます。特に、ほとんどの既存のLLMは、繰り返しの力が強いため、デコーダーのみの構造を好みます。直感的には、エンコーダーデコーダーモデルは、デコーダーのみのモデルのまばらなバージョンと見なすことができ、情報はエンコーダーからデコーダーまでより多く減衰します。詳細については、この論文を確認してください。
LLMは通常、自然言語構造を内面化するために、モデルパブリッシャーによって数兆個のテキストトークンから前処理されます。また、今日のモデル開発者は、人間のフィードバック(RLHF)からの指導的微調整と強化学習を実施して、モデルに人間の指示に従い、人間の好みに合った答えを生成するように教えます。その後、ユーザーは公開されたモデルをダウンロードして、小さな個人データセット(ムービーのダイアログなど)でFinetuneそれを獲得できます。膨大な量のデータにより、事前削除には、個人が手に負えない大規模なコンピューティングリソース(たとえば、数千を超えるGPU)が必要です。一方、微調整はリソースに飢えが少なく、いくつかのGPUで行うことができます。
次の材料は、前削減と微調整プロセスを理解するのに役立ちます。
その他のチュートリアルはこちらをご覧ください。
LLMSのプロンプト技術には、モデルをガイドして目的の応答または出力を生成する方法で入力テキストを作成することが含まれます。ここに、より良いプロンプトを書くのに役立つ有用なリソースがあります。
大規模な言語モデルの評価ツールは、さまざまなタスクやデータセットにわたるパフォーマンス、機能、制限を評価するのに役立ちます。一般的な評価戦略は次のとおりです。
自動評価メトリック:これらのメトリックは、人間の介入なしにモデルのパフォーマンスを自動的に評価します。一般的なメトリックは次のとおりです。
人間の評価:人間の判断は、生成されたテキストの品質を包括的に評価するために不可欠です。一般的な人間の評価方法は次のとおりです。
ベンチマークデータセット:標準化されたデータセットにより、さまざまなタスクやドメインにわたるモデルの公正な比較が可能になります。例は次のとおりです。
モデル分析ツール:モデルの動作とパフォーマンスを分析するためのツールには以下が含まれます。
完全なリストはここにあります
既存のLLMの標準評価フレームワークは次のとおりです。
長いコンテキストに対処することは、メモリと処理能力の制限により、大規模な言語モデルに課題をもたらします。既存の手法には次のものがあります。
完全なリストはここにあります
パラメーター効率の高い微調整(PEFT)メソッドは、すべてのモデルのパラメーターではなく、少数の(余分な)モデルパラメーターを微調整することにより、さまざまな下流アプリケーションに大規模な前提型モデルを効率的に適応させることができます。
Huggingface Peft Paper Collectionにはさらに多くの作業があり、Huggingface PEFT APIで練習することを強くお勧めします。
モデルのマージとは、異なるタスクでトレーニングされた2つ以上のLLMを単一のLLMに統合することを指します。この手法は、さまざまなモデルの長所と知識を活用して、より堅牢で有能なモデルを作成することを目的としています。たとえば、コード生成用のLLMと数学プロレム解決のための別のLLMをマージすることができ、合併モデルがコード生成と数学の問題解決の両方を実行できるようにすることができます。
モデルのマージは、非常にシンプルで安価なアルゴリズム(モデル重量の線形組み合わせ)で効果的に実現できるため、興味深いです。代表的な論文と読書資料は次のとおりです。
モデルの合併に関するその他の論文は、こちらをご覧ください
LLMSのデコードを加速することは、特にリアルタイムまたは潜伏に敏感なアプリケーションで、推論の速度と効率を改善するために重要です。 LLMSのデコードプロセスをスピードアップする代表的な作業を以下に示します。
LLMデコードの加速に関するその他の作業は、リンク1とリンク2を介して見つけることができます。
知識の編集は、バイアスの削減や学習した相関の改訂など、LLMSの動作を効率的に変更することを目的としています。知識のローカリゼーションや学習など、多くのトピックが含まれています。代表的な仕事には以下が含まれます。
ここには、その他の論文があります。
大規模なトレーニングを受けることにより、LLMSは世界の知識を消化し、入力命令に正確に従うことができます。これらの驚くべき機能により、LLMは複雑なタスクを自律的に(そして協力して)解決したり、人間の相互作用をシミュレートすることができるエージェントとして再生できます。 LLMエージェントの代表的な論文は次のとおりです。
ここには、論文、プラットフォーム、評価ツールの完全なリストがあります。
LLMSは、研究者と開発者が積極的に取り組むために取り組んでいるいくつかのオープンな課題に直面しています。これらの課題には次のものがあります。
完全なリストはここにあります。
拡散モデルは、特定のデータドメインの確率分布を近似し、近似分布からサンプルを生成する方法を提供することを目指しています。彼らの目標は、VAE、GAN、正規化フローなど、他の一般的な生成モデルに似ています。
拡散モデルのワーキングフローは、2つのプロセスで紹介されています。
この素晴らしいブログをチェックしてください。詳細なチュートリアルはこちらをご覧ください。拡散モデルを使用して画像、オーディオ、ビデオなどを生成することができ、以下に示すように拡散モデルに関連する多くのサブフィールドがあります。
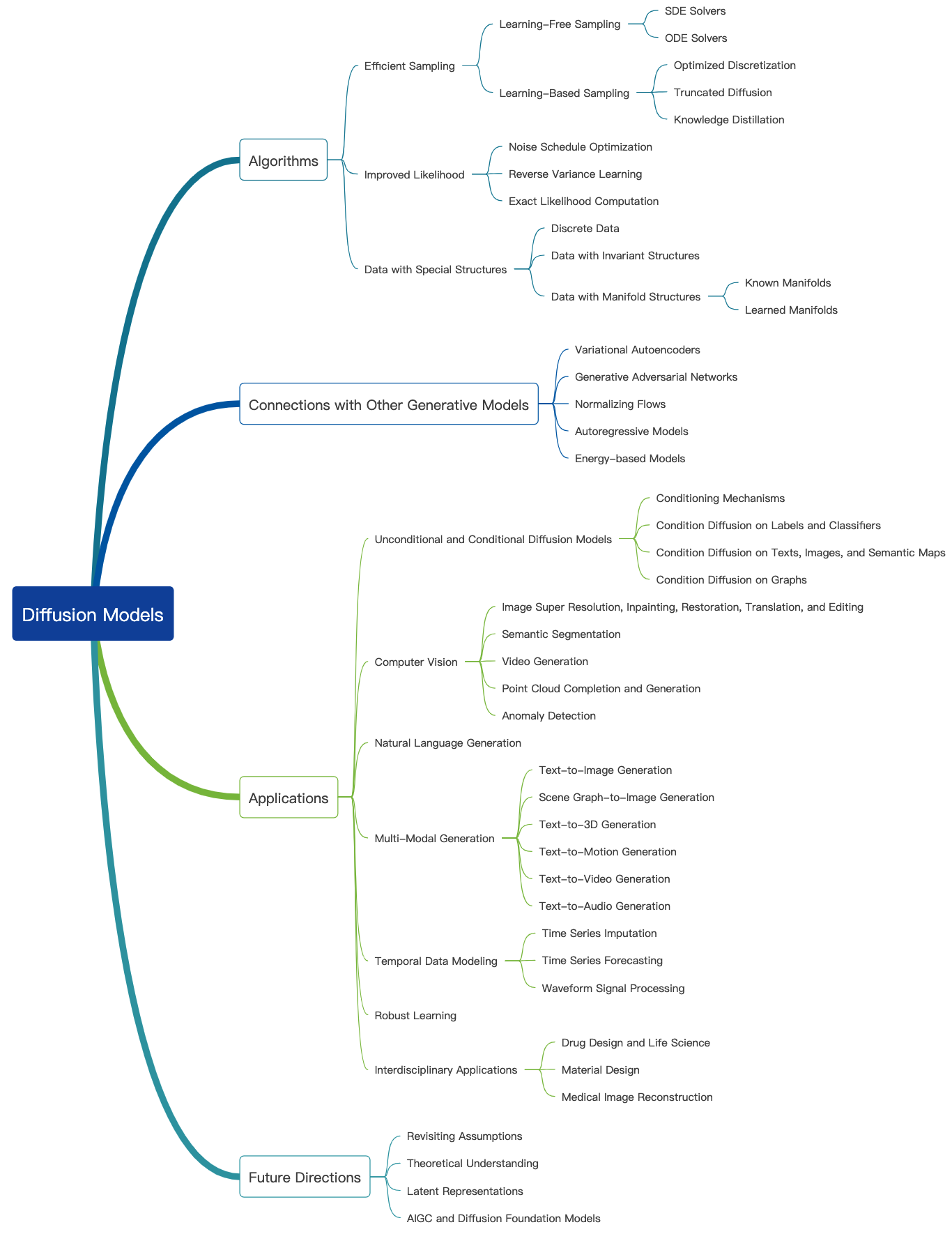
画像生成のための拡散モデルの代表的な論文を次に示します。
ここには、その他の論文があります。
ビデオ生成のための拡散モデルのいくつかの代表的な論文を次に示します。
ここには、その他の論文があります。
オーディオ生成のための拡散モデルの代表的な論文を以下に示します。
ここには、その他の論文があります。
他の大規模な生成モデルと同様に、拡散モデルも大量のWebデータ(Laion-5Bデータセットなど)で前提とされ、大規模なコンピューティングリソースを消費します。ユーザーは、リリースされたウェイトをダウンロードできます。個人データセットでモデルをさらに微調整できます。
拡散モデルの効率的な微調整の代表的な論文を以下に示します。
ここには、その他の論文があります。
Huggingface Diffusers APIでいくつかの練習をすることを強くお勧めします。
ここでは、画像生成の拡散モデルの評価について説明します。多くの既存の画質メトリックを適用できます。
より多くの画質メトリックと計算ツールは、こちらをご覧ください。
拡散モデルでは、データを生成するために複数のフォワードステップオーバーが必要です。これは高価です。効率的な生成のための拡散モデルの代表的な論文を以下に示します。
ここには、その他の論文があります。
拡散モデルの知識編集の代表的な論文を以下に示します。
ここには、その他の論文があります。
拡散モデルが直面する課題について話している調査論文をいくつか紹介します。
典型的なLMMは、既存の事前に処理されたユニモーダルモデルを接続および微調整することにより構築されます。いくつかもゼロから前もってされています。 [画像ソース]の下の画像でLMMSがどのように進化するかを確認してください。
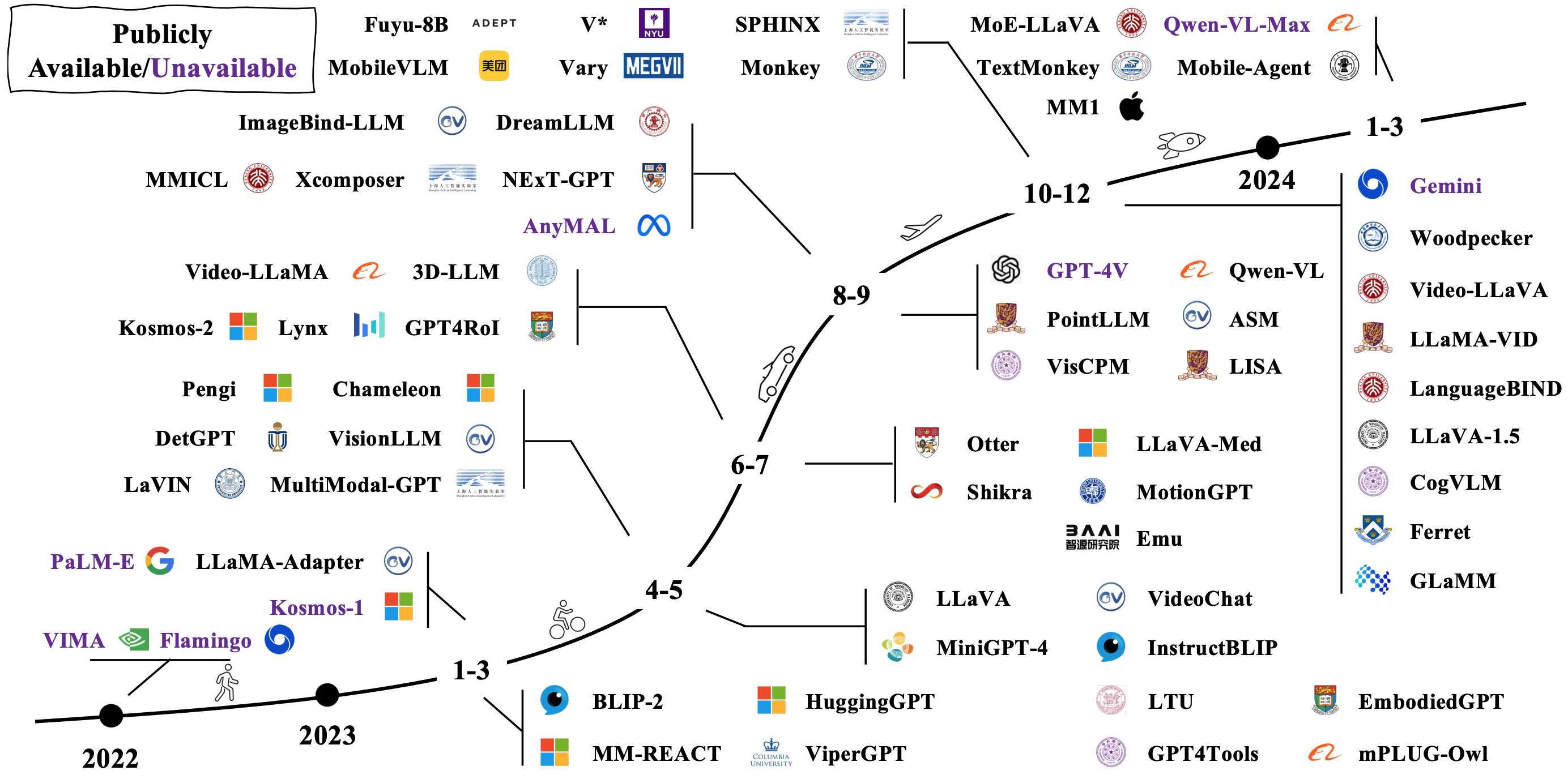
LMMに対処するには、さまざまな方法があります。代表的なアーキテクチャは次のとおりです。
より多くの論文は、リンク1およびリンク2を介して見つけることができます。
LMMとロボットを組み合わせることにより、研究者は、ロボット工学、仮想アシスタント、自律車両などにまたがる潜在的なアプリケーションを使用して、より自然で直感的な方法で世界に行動することができるAIシステムを開発することを目指しています。 LMMSを使用して具体化されたAIを実現する代表的な作業を次に示します。
より多くの論文は、リンク1およびリンク2を介して見つけることができます。
具体化されたAIのLMMSパフォーマンスを評価するための一般的なシミュレーターとデータセットを次に示します。
ここには、より多くのリソースがあります。
LMM対応の具体化されたAIのオープンな課題について話している調査論文をいくつか紹介します。
研究者は、変圧器以外の新しいモデルを探索しようとしています。取り組みには、モデルパラメーターを暗黙的に構築し、新しいモデルアーキテクチャの定義が含まれます。
State Space Modelsの素晴らしいチュートリアルです。


