Generative AI Tutorial
1.0.0
生成AI研究的主观学习指南,包括精心策划的文章和项目清单
生成AI是当今的热门话题,该路线图旨在帮助初学者快速获得基本知识并找到生成AI的有用资源。甚至欢迎专家参考此路线图,以回忆旧知识并发展新的想法。
本节应帮助您学习或重新获得神经网络的基本知识(例如,反向传播),让您熟悉变压器体系结构,并描述一些基于变压器的模型。
您是否非常熟悉以下经典的神经网络结构?
如果是这样,您应该能够回答以下问题:
反向传播(BP)是NN培训的基础。如果您不了解BP,您将不会成为AI专家。有很多教科书和在线教程教授BP,但不幸的是,其中大多数没有以矢量化/张力形式呈现公式。 NN层的BP公式确实与其正向通过公式一样整洁。这正是BP的实施方式,应实现。要了解BP,请阅读以下材料:
如果您了解BP,则应该能够回答以下问题:
变压器是现有大型生成模型的基本体系结构。有必要了解变压器中的每个组件。请阅读以下材料:
如果您了解变压器,则应该能够回答以下问题:
Einsum很容易且有用[用于使用Einsum/Einops的绝佳教程]
开放性对于人工超人智能(ICML 2024)[关于实现超人AI的想法]至关重要
在AGI路径上运行进度的AGI水平
LLM是变压器。它们可以分为仅编码,编码器编码器和仅解码器的体系结构,如下面的LLM进化树[Image Source]所示。检查LLM的里程碑论文。
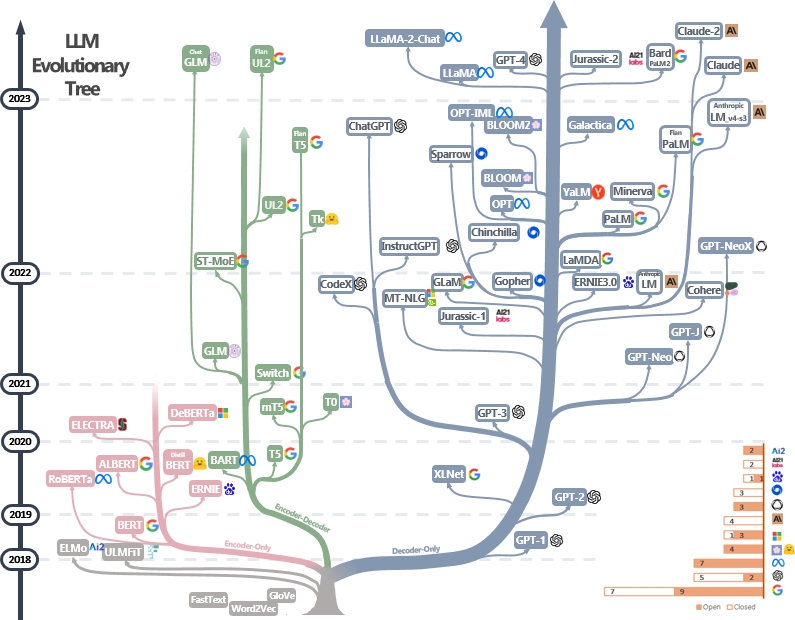
仅编码模型可用于提取句子特征,但缺乏生成力。编码器编码器和仅解码器模型用于文本生成。特别是,由于更强的维修能力,大多数现有的LLM都喜欢仅解码器结构。直观地,编码器模型可以视为仅解码器模型的稀疏版本,并且信息从编码器到解码器的衰减更加衰减。检查本文以获取更多详细信息。
LLM通常是从模型出版商内部化自然语言结构内部化的文本令牌中鉴定的。当今的模型开发人员还向人类反馈(RLHF)进行教学微调和强化学习,以教导该模型遵循人类的指示并产生与人类偏爱保持一致的答案。然后,用户可以下载已发布的模型并在小型个人数据集(例如,电影对话框)上进行Finetune。由于大量数据,预处理需要大量的计算资源(例如,超过数千个GPU),这是个人无法承受的。另一方面,微调少资源不足,可以使用一些GPU来完成。
以下材料可以帮助您了解预处理和微调过程:
可以在这里找到更多的教程。
提示LLM的技术涉及以指导模型生成所需响应或输出的方式制作输入文本。这是帮助您编写更好的提示的有用资源:
大型语言模型的评估工具有助于评估其跨不同任务和数据集的性能,能力和局限性。以下是一些常见的评估策略:
自动评估指标:这些指标会自动评估模型性能而无需人工干预。常见指标包括:
人类评估:人类判断对于全面评估生成的文本的质量至关重要。常见的人类评估方法包括:
基准数据集:标准化数据集可以对不同任务和域的模型进行公平比较。示例包括:
模型分析工具:用于分析模型行为和性能的工具包括:
可以在此处找到完整的列表
现有LLM的标准评估框架包括:
由于记忆和处理能力的限制,处理长篇小说对大语言模型构成了挑战。现有技术包括:
可以在此处找到完整的列表
参数有效的微调(PEFT)方法仅通过微调少量(额外的)模型参数而不是所有模型参数来使大型预审计模型有效地适应各种下游应用程序:
在Huggingface Peft纸收藏中可以找到更多的工作,强烈建议使用HuggingFace Peft API练习。
合并模型是指将两个或多个在不同任务培训的LLM合并为单个LLM。该技术旨在利用不同模型的优势和知识来创建一个更健壮和有能力的模型。例如,可以将代码生成的LLM和其他用于数学求解的LLM合并在一起,以便合并的模型能够同时进行代码生成和数学问题解决。
模型合并很有趣,因为它可以通过非常简单且廉价的算法有效地实现(例如,模型权重的线性组合)。以下是一些代表性的论文和阅读材料:
有关模型合并的更多论文可以在此处找到
LLM的加速解码对于提高推理速度和效率至关重要,尤其是在实时或对潜伏期敏感的应用中。这是加速LLM的解码过程的一些代表性工作:
可以通过链接1和链接2找到有关加速LLM解码的更多工作。
知识编辑旨在有效地修改LLMS行为,例如减少偏见和修订学到的相关性。它包括许多主题,例如知识本地化和学习。代表性工作包括:
可以在这里找到更多论文。
通过接受大规模的培训,LLMS Digest World知识并能够准确遵循输入指令。借助这些惊人的功能,LLM可以作为可以自主(和协作)解决复杂任务的代理商发挥作用,或模拟人类的互动。以下是LLM代理的一些代表性论文:
可以在此处找到论文,平台和评估工具的完整列表。
LLMS面临着研究人员和开发人员积极努力解决的几个公开挑战。这些挑战包括:
可以在此处找到一个完整的列表。
扩散模型旨在近似给定数据域的概率分布,并提供一种从其近似分布中生成样品的方法。他们的目标类似于其他流行的生成模型,例如vae,gan和归一化的流量。
扩散模型的工作流有两个过程:
查看此很棒的博客,并在此处找到更多的介绍性教程。扩散模型可用于生成图像,音频,视频等,并且有许多与扩散模型相关的子字段,如下所示[图像源]:
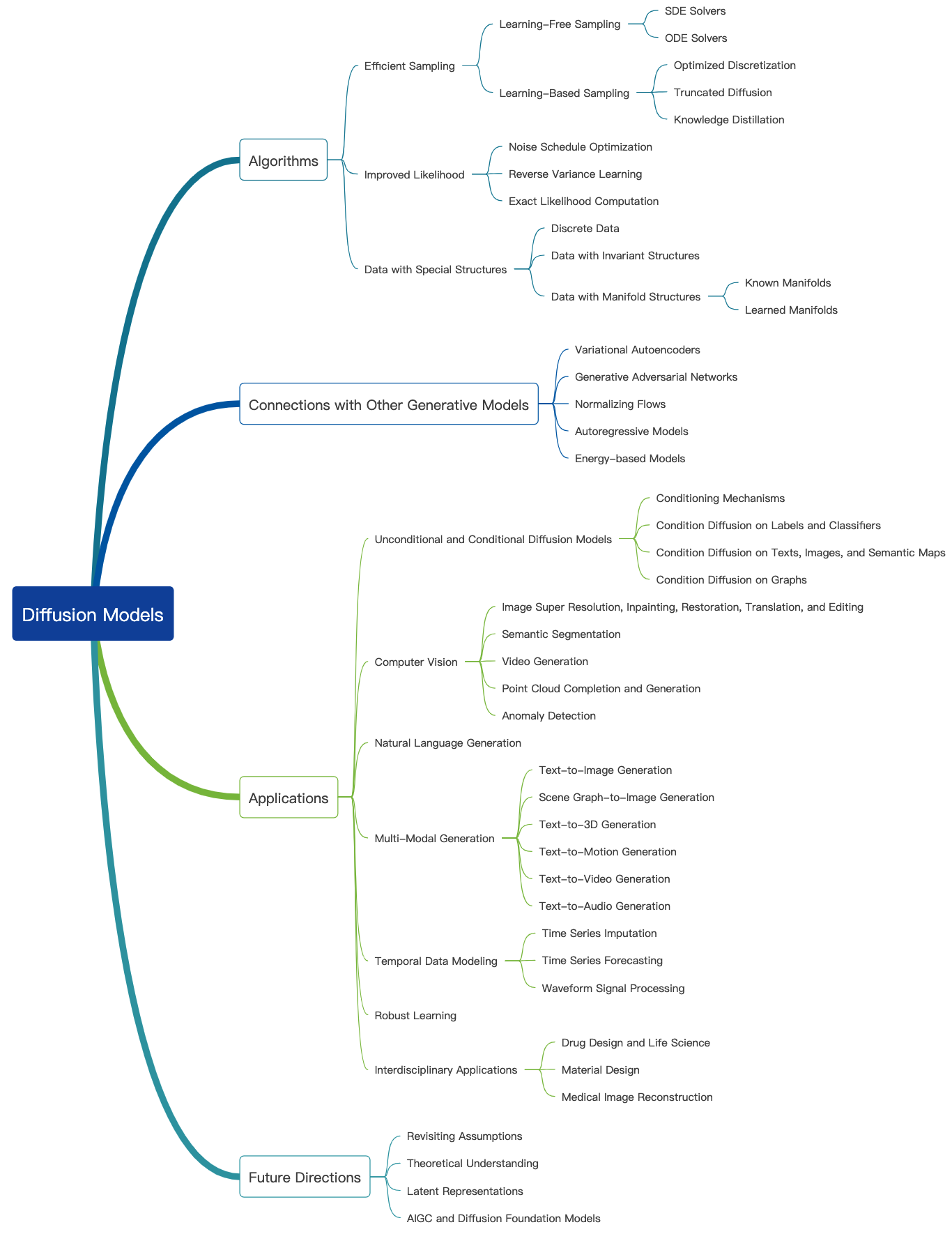
以下是图像生成的扩散模型的一些代表性论文:
可以在这里找到更多论文。
以下是一些代表性的传播模型论文:视频生成:
可以在这里找到更多论文。
以下是音频产生扩散模型的一些代表性论文:
可以在这里找到更多论文。
与其他大型生成模型类似,扩散模型也在大量的Web数据(例如LAION-5B数据集)上进行了预测,并消耗了大量的计算资源。用户可以下载发布的权重可以进一步调整个人数据集上的模型。
以下是一些有效微调扩散模型的代表性论文:
可以在这里找到更多论文。
强烈建议使用HuggingFace扩散器API进行一些练习。
在这里,我们谈论对图像生成的扩散模型的评估。可以应用许多现有的图像质量指标。
可以在此处找到更多图像质量指标和计算工具。
扩散模型需要多个正向步骤以生成昂贵的数据。以下是一些有效产生的扩散模型的代表性论文:
可以在这里找到更多论文。
以下是一些用于扩散模型的知识编辑的代表性论文:
可以在这里找到更多论文。
以下是一些调查论文,讨论了扩散模型所面临的挑战。
典型的LMM是通过连接和微调现有预验证的单峰模型来构建的。有些也从头开始审议。检查LMM在下面的图像中如何发展[图像源]。
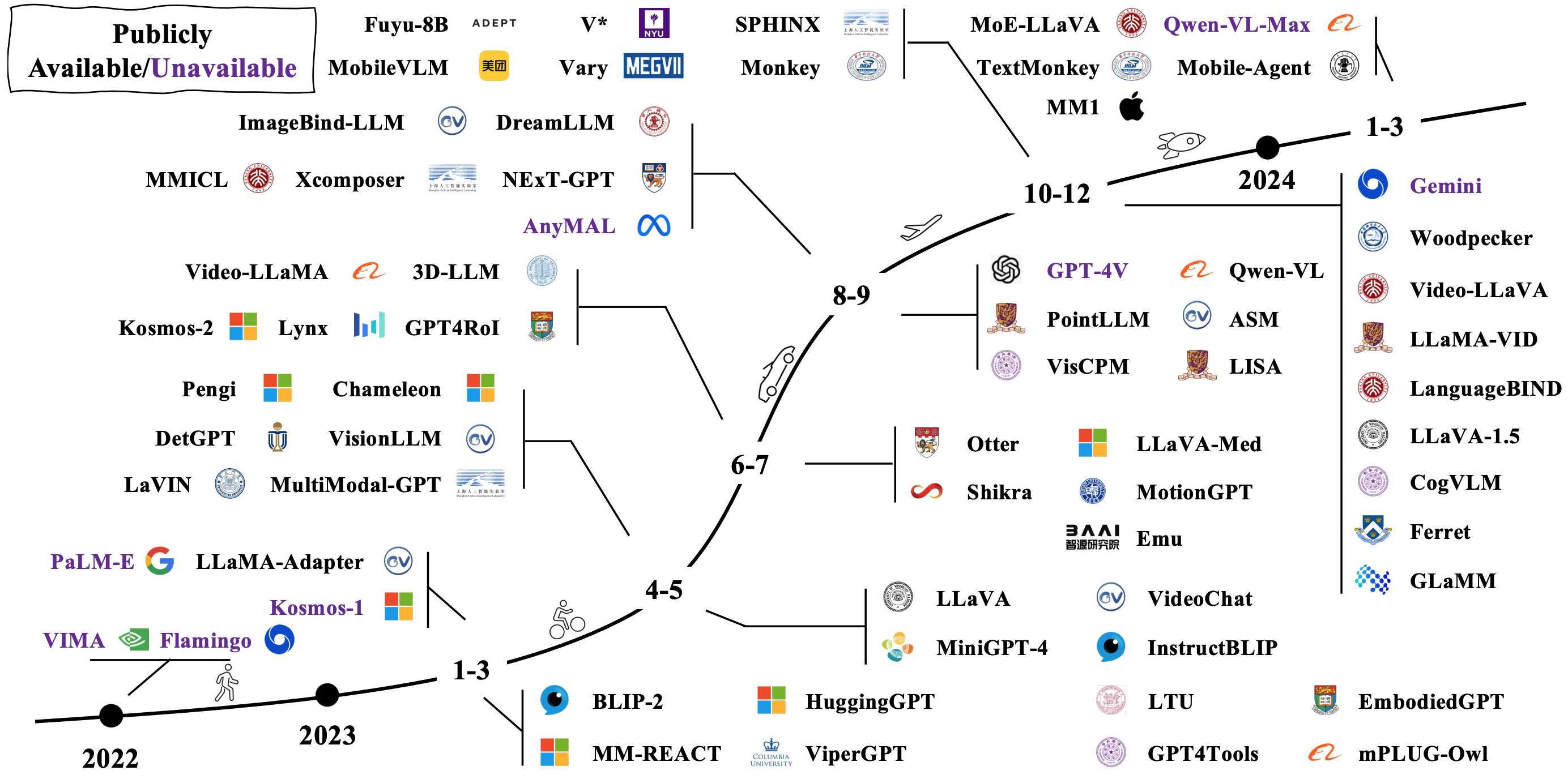
有许多不同的LMM的方法。代表性架构包括:
可以通过链接1和链接2找到更多论文。
通过将LMM与机器人相结合,研究人员的目标是开发可以以更自然和直观的方式感知,理性和行动的AI系统,以及涵盖机器人,虚拟助手,自动驾驶汽车及以后的潜在应用。这是实现LMM体现的AI的一些代表性工作:
可以通过链接1和链接2找到更多论文。
以下是一些流行的模拟器和数据集,用于评估体现AI的LMMS性能:
可以在这里找到更多资源。
以下是一些调查论文,讨论了针对LMM支持体现的AI的公开挑战:
研究人员正在尝试探索除变压器以外的新模型。努力包括隐式构建模型参数和定义新的模型体系结构。
这是国家空间模型的很棒的教程。


