 Генеративная дорожная карта ИИ
Генеративная дорожная карта ИИ
Субъективное руководство по обучению для генеративных исследований искусственного интеллекта, включая кураторный список статей и проектов
Generative AI - это горячая тема сегодня, и эта дорожная карта предназначена для того, чтобы помочь начинающим быстро получить базовые знания и найти полезные ресурсы генеративного искусственного интеллекта. Даже эксперты могут сослаться на эту дорожную карту, чтобы вспомнить старые знания и развить новые идеи.
Таблица контента
- Фоновые знания
- Нейронные сети выводы и обучение
- Архитектура трансформатора
- Обычные модели на основе трансформаторов
- Разнообразный
- Большие языковые модели (LLMS)
- Предварительная подготовка и тонкая настройка
- Подсказка
- Оценка
- Работа с длинным контекстом
- Эффективная тонкая настройка
- Модель слияния
- Эффективное поколение
- Редактирование знаний
- Агенты с питанием LLM
- Выводы
- Открытые проблемы
- Диффузионные модели
- Генерация изображений
- Видео генерация
- Аудио генерация
- Предварительная подготовка и тонкая настройка
- Оценка
- Эффективное поколение
- Редактирование знаний
- Открытые проблемы
- Большие мультимодальные модели (LMMS)
- Модель архитектуры
- К воплощенным агентам
- Открытые проблемы
- За пределами трансформаторов
- Неявно структурированные параметры
- Новая модель архитектуры
Фоновые знания
Этот раздел должен помочь вам изучить или восстановить базовые знания о нейронных сетях (например, обратное распространение), ознакомиться с архитектурой трансформатора и описать некоторые общие модели на основе трансформаторов.
Нейронные сети выводы и обучение
Вы очень хорошо знакомы со следующими классическими структурами нейронной сети?
- Многослойный персептрон (MLP)
- Сверточная нейронная сеть (CNN)
- Повторяющаяся нейронная сеть (RNN)
Если это так, вы сможете ответить на эти вопросы:
- Почему CNN работают лучше, чем MLP на изображениях?
- Почему RNN работают лучше, чем MLP в данных временных рядов?
- В чем разница между GRU и LSTM?
Бэкпропаг (BP) является основой обучения NN. Вы не будете экспертом по ИИ, если не поймете БП . Есть много учебников и онлайн -уроков, обучающих BP, но, к сожалению, большинство из них не представляют формулы в векторизованных/тензоризованных формах. Формула BP слоя NN действительно такая же аккуратная, как и ее формула вперед. Именно так BP реализовано и должно быть реализовано. Чтобы понять BP, прочитайте следующие материалы:
- Нейронные сети и глубокое обучение [глава 3.2, особенно 3.2.6]
- MEPROP: Редженое распространение спины для ускоренного глубокого обучения с уменьшением переживания (ICML 2017) [Раздел 2.1]
- RESPROP: повторно используйте разреженные обратные процессы (CVPR 2020) [Раздел 3.1]
Если вы понимаете BP, вы сможете ответить на эти вопросы:
- Как вы будете описать BP сверточного слоя?
- Каково соотношение затрат на вычислительные вычисления (то есть количество операций с плавающей запятой) между прямым проходом и обратным проходом плотного слоя?
- Как вы будете описать BP MLP с двумя плотными слоями, разделяющими одну и ту же матрицу веса?
Архитектура трансформатора
Трансформатор является базовой архитектурой существующих крупных генеративных моделей. Необходимо понять каждый компонент в трансформаторе. Пожалуйста, прочитайте следующие материалы:
- Внимание - это все, что вам нужно (Neurips 2017) [оригинальная статья]
- Объяснитель трансформатора: интерактивное изучение моделей генерации текста [интерактивный учебник]
- Изображение стоит 16x16 слов: трансформаторы для распознавания изображения в масштабе (ICLR 2021) [Vision Transformer]
- Трансляция нейронной машины с трансформатором и керас [отличное объяснение внимания мультизаря (MHA)]]
- Флопы блока трансформатора [давайте практиковать расчеты провалов]
- Быстрое декодирование трансформатора: одна из них-это все, что вам нужно [многопрофильное внимание (MQA)]
- GQA: Обучение обобщенных моделей многопрофильных трансформаторов с многопользовательских контрольных точек [Групповое внимание (GQA)]]
- Улучшенный трансформатор с внедрением положения роторного положения [Понимание позиционного встраивания]
- Ротари встраивания: относительная революция [Понимание позиционного встраивания]
- Учитель, навязывающий запланированную выборку против обычного режима [Учительский принуждение к обучению трансформаторам]
- FlexGen: высокопроизводительный генеративный вывод крупных языковых моделей с одним графическим процессором [см. Раздел 3 - Генеративный вывод, чтобы узнать, как генерация LLMS PEFORM на основе KV Cache]
- Контекстуальная позиция Кодирование: обучение, чтобы считать то, что важно [контекстно-зависимое позиционное кодирование]
Если вы понимаете трансформаторы, вы сможете ответить на эти вопросы:
- Каковы плюсы и минусы трансформеров по сравнению с RNNS (одновременно посещение, обучение параллелизму, сложности)
- Можете ли вы затопить провалы GQA? Посмотрите, когда он ухудшается до MHA и MQA?
- Какова мотивация MQA и GQA?
- Как выглядит маска причинного внимания и почему?
- Как вы будете описать подготовку трансформаторов только декодера шаг за шагом?
- Почему веревка лучше синусоидальной позиционной кодирования?
Обычные модели на основе трансформаторов
- Обучение переносимым визуальным моделям из надзора естественного языка [клип]
- Новые свойства в самоотверженных трансформаторах зрения (ICCV 2021) [DINO]
- Автоэнкодеры в масках - это масштабируемые зрение (CVPR 2022) [MAE]
- Масштабирование зрения с редкой смесью экспертов (Neurips 2021) [Moe]
- Смесь глубины: динамически распределение вычислительных языков на основе трансформатора [MOD]
Разнообразный
Einsum - это простой и полезный [отличный учебник для использования Einsum/einops]
Открытая энтузиазм необходим для искусственного сверхчеловеческого интеллекта (ICML 2024) [Мысли о достижении сверхчеловеческого AI]
Уровни Agi для реализации прогресса на пути к Agi
Большие языковые модели (LLMS)
LLMS - это трансформаторы. Они могут быть классифицированы на энкодер, только энкодер-декодер и архитектуру только для декодера, как показано в эволюционном дереве LLM ниже [Источник изображения]. Проверьте веха документов LLMS.
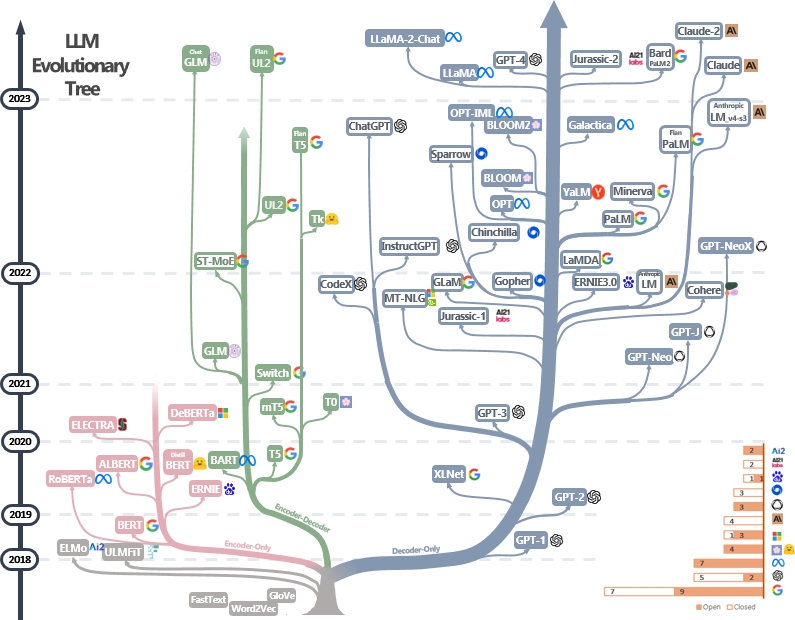
Модель только для энкодера может использоваться для извлечения функций предложений, но ей не хватает генеративной мощности. Модели Encoder-Decoder и Decoder используются только для генерации текста. В частности, большинство существующих LLM предпочитают только декодер структуры из-за более сильной повторной власти. Интуитивно, модели Encoder-Decoder можно считать редкой версией моделей только для декодера, а информация больше распадается от Encoder до декодера. Проверьте эту статью для получения более подробной информации.
Предварительная подготовка и создание
LLM, как правило, предварительно предварительно от триллионов текстовых токенов издателями моделей, чтобы усвоить структуру естественного языка. Современные разработчики модели также проводят обучение точной настройке и подкреплению обучения от человеческой обратной связи (RLHF), чтобы научить модель следовать человеческим инструкциям и генерировать ответы, соответствующие человеческим предпочтениям. Затем пользователи могут загрузить опубликованную модель и Finetune It на небольших личных наборах данных (например, Dialog Movie). Из -за огромного объема данных предварительная подготовка требует массовых вычислительных ресурсов (например, более тысяч графических процессоров), которые недоступны для отдельных лиц. С другой стороны, тонкая настройка менее жаждает ресурсов и может быть сделана с помощью нескольких графических процессоров.
Следующие материалы могут помочь вам понять процесс предварительной подготовки и тонкой настройки:
- БЕРТ: Предварительное обучение глубоких двунаправленных трансформаторов для понимания языка [предварительная подготовка и создание LLMS только для энкодера]
- Масштабирование инструкционных моделей языка [предварительная подготовка и обучающая конфигурация]
- Иллюстрация подкрепления обучения от обратной связи человека (RLHF)
- Языковые модели-это несколько учащихся [LLMS только для декодера] [中文导读 by 李沐]
Больше учебников можно найти здесь.
Подсказка
Методы подсказки для LLMS включают в себя создание входного текста таким образом, чтобы руководство моделью генерировала желаемые ответы или выходы. Вот полезные ресурсы, которые помогут вам написать лучшие подсказки:
- [Dair.ai]
- Потрясающие подсказки CHATGPT - коллекция быстрых примеров, которые можно использовать с моделью CATGPT
- Потрясающее совещательное подсказка - как попросить LLMS принять надежные рассуждения и принимать разумные решения
- AutoPrompt - автоматический метод, основанный на поиске с градиентом для создания подсказок для разнообразного набора задач NLP.
Оценка
Инструменты оценки для крупных языковых моделей помогают оценить их производительность, возможности и ограничения по разным задачам и наборам данных. Вот некоторые общие стратегии оценки:
Автоматические показатели оценки : эти метрики автоматически оценивают производительность модели без вмешательства человека. Общие показатели включают:
- Bleu: измеряет сходство между генерируемым текстом и эталонным текстом на основе перекрытия N-грамма.
- Rouge: оценивает текстовое суммирование, сравнивая перекрывающиеся N-граммы между генерируемыми и эталонными суммациями.
- Смущение: измеряет, насколько хорошо языковая модель предсказывает выборку текста. Более низкая недоумение указывает на лучшую производительность. Это эквивалентно экспоненте перекрестной энтропии между данными и прогнозами модели.
- Оценка F1: измеряет баланс между точностью и отзывами в таких задачах, как классификация текста или распознавание объектов.
Оценка человека : человеческое суждение имеет важное значение для всесторонней оценки качества генерируемого текста. Общие методы оценки человека включают:
- Рейтинги человека : аннотаторы человека сгенерировали текст на основе таких критериев, как беглость, когерентность, актуальность и грамматичность.
- Краудсорсинг платформы : такие платформы, как Amazon Mechanical Turk или Figure Eight, облегчают крупномасштабную оценку человека путем краудсорсинговых аннотаций.
- Экспертная оценка : Доменные эксперты оценивают выходы модели, чтобы оценить их пригодность для конкретных приложений или задач.
Наборы данных . Стандартизированные наборы данных обеспечивают справедливое сравнение моделей по разным задачам и доменам. Примеры включают:
- Viriviaqa: крупномасштабный набор данных с отдаленным контролем для понимания прочитанного
- Hellaswag: Может ли машина действительно закончить ваше предложение?
- GSM8K: Обучение проверки для решения задач по математике
- Полный список можно найти здесь
Инструменты анализа моделей: инструменты для анализа поведения и производительности модели включают:
- Автоматизированная интерпретация - код для автоматического генерирования, моделирования и оценки объяснений поведения нейронов
- Визуализация LLM - визуализация LLMS в низком уровне.
- Анализ внимания - анализ карт внимания от BRET Transformer.
- Neuron Viewer - инструмент для просмотра активаций и объяснений нейронов.
Полный список можно найти здесь
Стандартные структуры оценки для существующих LLM включают:
- LM-Evaluation-Harness-структура для нескольких выстрелов в оценке языковых моделей.
- LightEval - легкий набор оценки LLM, который обнимает лицо внутри.
- Olmo -Eval - репозиторий для оценки моделей открытого языка.
- INSTRUCT-EVAL-этот репозиторий содержит код для количественной оценки моделей, настроенных на инструкции, таких как Alpaca и Flan-T5, по удерживаемым задачам.
Работа с длинным контекстом
Работа с длинными контекстами создает проблему для крупных языковых моделей из -за ограничений в памяти и обработке. Существующие методы включают:
- Эффективные трансформаторы
- Longformer: длинный документ трансформатор
- Реформатор: Эффективный трансформатор (ICLR 2020)
- Государственные космические модели
- Трансформаторы - это RNN: быстрые авторегрессивные трансформаторы с линейным вниманием (ICML 2020)
- Переосмысление внимания с исполнителями
- Длина экстраполяция
- Мамба: моделирование последовательности линейного времени с селективными пространствами состояния
- ROFORMER: Улучшенный трансформатор с внедрением роторного положения
- Пряжа: эффективное расширение окна контекста больших языковых моделей
- Долгосрочная память
- Блок памяти: улучшение больших языковых моделей с долговременной памятью
- Развязать входную способность бесконечной длины для крупномасштабных языковых моделей с самоконтролируемой системой памяти
Полный список можно найти здесь
Эффективное создание
Параметр-эффективные методы тонкой настройки (PEFT) обеспечивают эффективную адаптацию крупных предварительно предварительно предопределенных моделей к различным нижестоящим приложениям, только настраивая небольшое количество параметров (дополнительных) модели вместо всех параметров модели:
- Настройка быстрого настройки: мощность масштабирования для настройки с помощью параметров, эффективной
- Настройка префикса: настройка префикса: оптимизация непрерывных подсказок для генерации
- Лора: Лора: адаптация с низким уровнем ранга больших языковых моделей
- На пути к единому представлению об обучении переноса эффективного параметра
- Лора учится меньше и забывает меньше
Больше работ можно найти в коллекции Peft Peft Peft для HuggingFace, и настоятельно рекомендуется практиковать с API PEFT HuggingFace.
Модель слияния
Слияние модели относится к объединению двух или более LLM, обученных различным задачам в один LLM. Этот метод направлен на использование сильных сторон и знаний о различных моделях для создания более надежной и способной модели. Например, LLM для генерации кода и еще один LLM для математического решающего решения могут быть объединены вместе, чтобы объединенная модель способна выполнять как генерацию кода, так и математические задачи.
Слияние модели интригует, потому что она может быть эффективно достигнута с помощью очень простых и дешевых алгоритмов (например, линейная комбинация весов модели). Вот некоторые представительные документы и материалы для чтения:
- Модельные супы: усреднение веса многочисленных тонко настроенных моделей повышает точность без увеличения времени вывода
- Редактирование моделей с помощью арифметики задачи
- Объединить большие языковые модели с Mergekit
Больше документов о слиянии модели можно найти здесь
Эффективное поколение
Ускорение декодирования LLMS имеет решающее значение для повышения скорости и эффективности вывода, особенно в приложениях в режиме реального времени или чувствительных к задержке. Вот некоторые репрезентативные работы по ускорению процесса декодирования LLM:
- Deja Vu: контекстуальная редкость для эффективных LLMS во время вывода (ICML 2023 Oral)
- Llmlingua: сжатие подсказок для ускоренного вывода моделей крупных языков (EMNLP 2023)
- Эффективные потоковые языковые модели с утоплениями внимания
- Specinfer: ускорение генеративного LLM служащего с спекулятивным выводом и проверкой дерева токенов
- Medusa: Простая структура ускорения вывода LLM с несколькими декодирующими головками
- Лучшие и более быстрые крупные языковые модели с помощью многокачественного прогноза
- Slieler Skip: обеспечение раннего выхода вывода и самопрокативного декодирования
Больше работы по ускорению декодирования LLM можно найти через ссылку 1 и ссылку 2.
Редактирование знаний
Редактирование знаний направлено на эффективное изменение поведения LLMS, такое как уменьшение смещения и пересмотр учебных корреляций. Он включает в себя множество тем, таких как локализация знаний и отключение. Представительная работа включает в себя:
- Редактирование модели на основе памяти в масштабе (ICML 2022)
- Плачер-трансформатор: одна ошибка стоит одного нейрона (ICLR 2023)
- Массовое редактирование модели большой языка через мета -обучение (ICLR 2024)
- Унифицированная структура для редактирования модели
- Слои трансформатора-это воспоминания о ключевых значениях (EMNLP 2021)
- Восстановление массового редактирования в трансформаторе
Здесь можно найти больше бумаг.
Агенты с питанием LLM
Получив массовое обучение, LLMS Digrest World знает и способна точно следовать инструкциям по вводу. С этими удивительными возможностями, LLM могут играть за агенты, которые могут автономно (и совместно) решать сложные задачи или имитировать человеческие взаимодействия. Вот несколько репрезентативных документов агентов LLM:
- Генеративные агенты: интерактивная симулякра человеческого поведения (UIST 2023) [LLMS имитации человеческого общества в видеоиграх]
- Сотопия: интерактивная оценка социального интеллекта в языковых агентах (ICLR 2024) [LLMS моделирует социальные взаимодействия]
- Voyager: открытый воплощенный агент с большими языковыми моделями [LLMS живут в мире Minecraft]
- Большие языковые модели в качестве производителей инструментов (ICLR 2024) [LLMS создает свои собственные многоразовые инструменты (например, в функциях Python) для решения проблем]
- Метагпт: Мета программирование для многоагентных совместных рамках [LLMS как команда для автоматизированного разработки программного обеспечения]
- Webarena: реалистичная веб -среда для создания автономных агентов (ICLR 2024) [LLMS использует веб -приложения]
- Mobile-ENV: платформа оценки и эталон для взаимодействия LLM-GUI [LLMS используют мобильные приложения]
- HuggingGpt: решение задач ИИ с Chatgpt и его друзьями в обнимании лица (Neurips 2023) [LLMS ищут модели в Huggingface для решения проблем]
- Agentgym: развитие крупных языковых модельных агентов в различных средах [разнообразные интерактивные среды и задачи для агентов на основе LLM]
Полный список документов, платформ и инструментов оценки можно найти здесь.
Выводы
- Ваш трансформатор тайно линейный
- Не все функции модели языка линейные
- Кан или MLP: более справедливое сравнение
- Трансформерные слои в качестве художников
- Модели языка зрения слепы
Открытые проблемы
LLMS сталкивается с несколькими открытыми проблемами, которые исследователи и разработчики активно работают. Эти проблемы включают:
- Галлюцинация
- Комплексный обзор методов смягчения галлюцинации в моделях крупных языков
- Модель сжатия
- Комплексный обзор алгоритмов сжатия для языковых моделей
- Оценка
- Оценка крупных языковых моделей: комплексный опрос
- Рассуждение
- Обзор рассуждений с моделями фундамента
- Объяснение
- От понимания до использования: опрос об объяснениях для крупных языковых моделей
- Справедливость
- Опрос справедливости в крупных языковых моделях
- Фактическая
- Опрос о фактических моделях: знание, поиск и специфичность домены
- Интеграция знаний
- Тенденции в интеграции знаний и крупных языковых моделей: опрос и таксономия методов, критериев и приложений
Полный список можно найти здесь.
Диффузионные модели
Диффузионные модели направлены на то, чтобы приблизить распределение вероятности данной области данных и обеспечить способ генерации образцов из ее приблизительного распределения. Их цели похожи на другие популярные генеративные модели, такие как Vae, Gans и нормализующие потоки.
Рабочий поток диффузионных моделей представлен с двумя процессами:
- Правопроцестный процесс (процесс диффузии): он постепенно применяет шум к исходным входным данным шаг за шагом, пока данные полностью не станут шумом.
- Обратный процесс (процесс двойного процесса): модель NN (например, CNN или трансформер) обучается оценке шума, применяемого на каждом этапе во время прямого процесса. Эта обученная модель NN может затем использоваться для генерации данных от входа шума. Существующие диффузионные модели также могут принимать другие сигналы (например, текстовые подсказки от пользователей) для обучения генерации данных.
Проверьте этот удивительный блог, и здесь можно найти больше вводных учебных пособий. Диффузионные модели могут использоваться для генерации изображений, звуков, видео и многого другого, и существует много подполи, связанных с диффузионными моделями, как показано ниже [Источник изображения]:
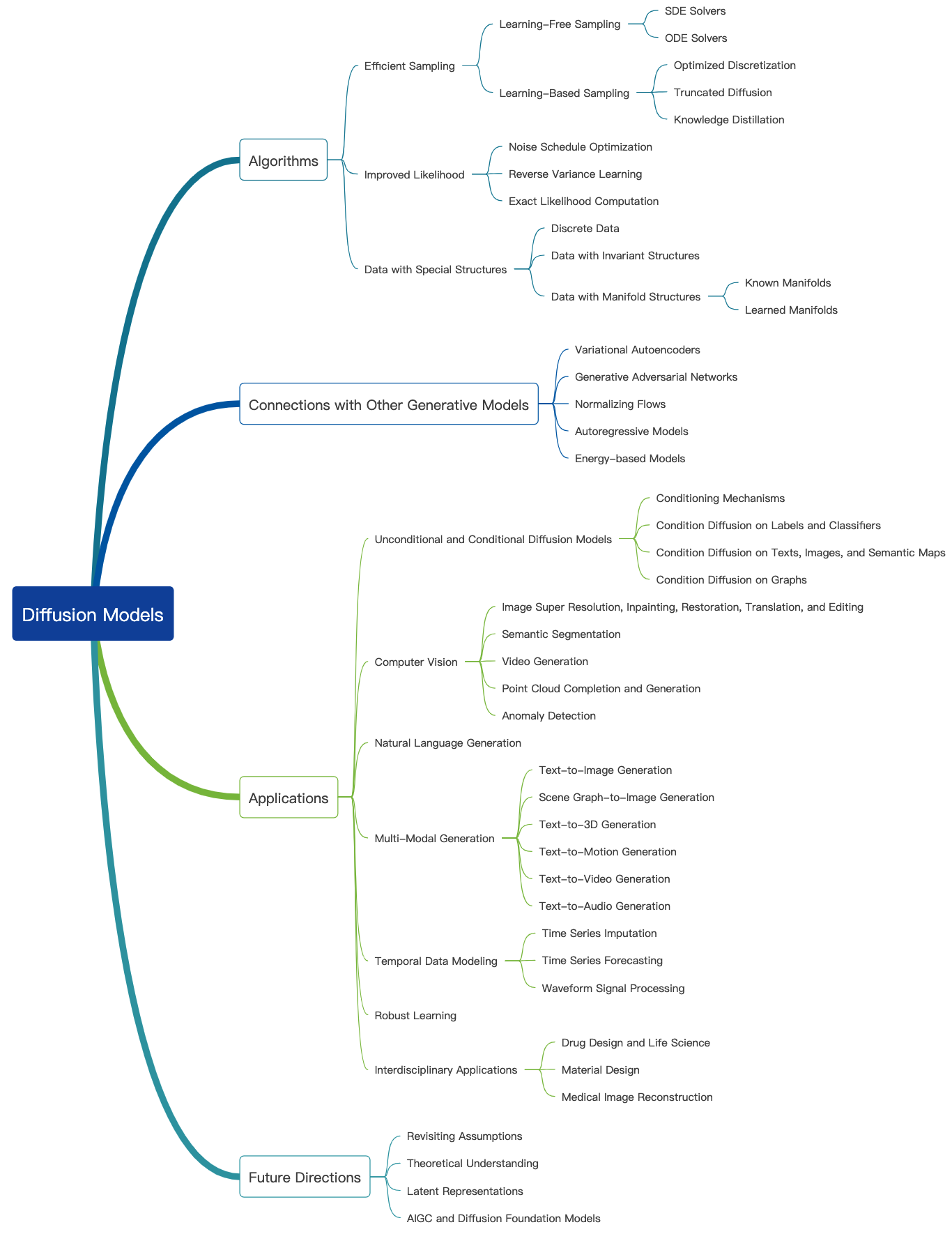
Генерация изображений
Вот несколько репрезентативных документов диффузионных моделей для генерации изображений:
- Синтез изображения с высоким разрешением с скрытыми диффузионными моделями (CVPR 2022)
- Палитра: диффузионные модели изображения до изображения (Siggraph 2022)
- Изображение супер-разрешение через итеративное уточнение
- Inpainting с использованием вероятных моделей Denoising Diffusion (CVPR 2022)
- Добавление условного управления в диффузионные модели текста до изображения (ICCV 2023)
Здесь можно найти больше бумаг.
Видео генерация
Вот несколько репрезентативных документов диффузионных моделей для генерации видео:
- Видео диффузионные модели
- Гибкое диффузионное моделирование длинных видео (Neurips 2022)
- Масштабирование скрытых моделей диффузии видео до больших наборов данных
- I2VGEN-XL: высококачественный синтез изображения к видео посредством каскадированных диффузионных моделей
Здесь можно найти больше бумаг.
Аудио генерация
Вот несколько репрезентативных документов диффузионных моделей для генерации звука:
- Grad-TTS: диффузионная вероятностная модель для текста в речь
- Генерация текста в Аулио с использованием LLM с инструкциями и скрытой диффузионной моделью
- Основная кондиционирование голоса с нулевым выстрелом
- Редактирование: редактирование на основе баллов для управляемого текста в речь
- Prodiff: Прогрессивная модель быстрой диффузии для высококачественного текста в речь
Здесь можно найти больше бумаг.
Предварительная подготовка и создание
Подобно другим крупным генеративным моделям, диффузионные модели также предварительно предварительно предоставляются в большом объеме веб-данных (например, набор данных LAION-5B) и потребляют огромные вычислительные ресурсы. Пользователи могут скачать выпущенные веса, которые могут еще больше настроить модель на личных наборах данных.
Вот некоторые репрезентативные статьи эффективной тонкой настройки диффузионных моделей:
- Dreambooth: тонкая настройка моделей диффузии текста до изображения для генерации, управляемой субъектом (CVPR 2023)
- Изображение стоит одного слова: персонализация генерации текста до изображения с использованием текстовой инверсии (ICLR 2023)
- Пользовательская диффузия: настройка мульти-концепции диффузии текста до изображения (CVPR 2023)
- Контроль диффузии текста к изображению ортогональным искусством (Neurips 2023)
Здесь можно найти больше бумаг.
Настоятельно рекомендуется провести некоторую практику с API Diffusers HuggingFace.
Оценка
Здесь мы говорим об оценке диффузионных моделей для генерации изображений. Многие существующие показатели качества изображения могут быть применены.
- Оценка клипа: Оценка клипа измеряет совместимость пар с изображением. Более высокие показатели клипа подразумевают более высокую совместимость. Было обнаружено, что оценка клипа имеет высокую корреляцию с человеческим суждением.
- Расстояние основания Fréchet (FID): FID стремится измерить, насколько похожи два набора данных изображений. Он рассчитывается путем вычисления расстояния Фреше между двумя гауссонами, установленными в соответствии с представлениями о начальной сети
- Сходство направления клипа: он измеряет согласованность изменения между двумя изображениями (в пространстве клипа) с изменением между двумя подписями изображения.
Больше показателей качества изображения и инструментов расчета можно найти здесь.
Эффективное поколение
Диффузионные модели требуют многократных шагов вперед для генерации данных, что является дорогостоящим. Вот несколько репрезентативных работ диффузионных моделей для эффективной генерации:
- Должен идти быстро при создании данных с моделями на основе баллов
- Быстрая выборка диффузионных моделей с экспоненциальным интегратором
- Изучение быстрых пробоотборников для диффузионных моделей путем дифференциации через качество выборки
- Ускоряющие диффузионные модели через раннюю остановку процесса диффузии
Здесь можно найти больше бумаг.
Редактирование знаний
Вот некоторые репрезентативные документы по редактированию знаний для диффузионных моделей:
- Стирание концепций из диффузионных моделей (ICCV 2023)
- Редактирование массивных концепций в моделях диффузии текста до изображения
- Забыть-меня-нет: научиться забывать в моделях диффузии текста до изображения
Здесь можно найти больше бумаг.
Открытые проблемы
Вот несколько документов опроса, в которых рассказывается о проблемах, с которыми сталкиваются диффузионные модели.
- Обзор моделей генерации изображений на основе диффузии
- Опрос о моделях диффузии видео
- Состояние искусства на диффузионных моделях для визуальных вычислений
- Диффузионные модели в НЛП: опрос
Большие мультимодальные модели (LMMS)
Типичные LMM строится путем соединения и тонкой настройки существующих предварительно проведенных унимодальных моделей. Некоторые также предварительно подготовлены с нуля. Проверьте, как развиваются LMM на изображении ниже [Источник изображения].
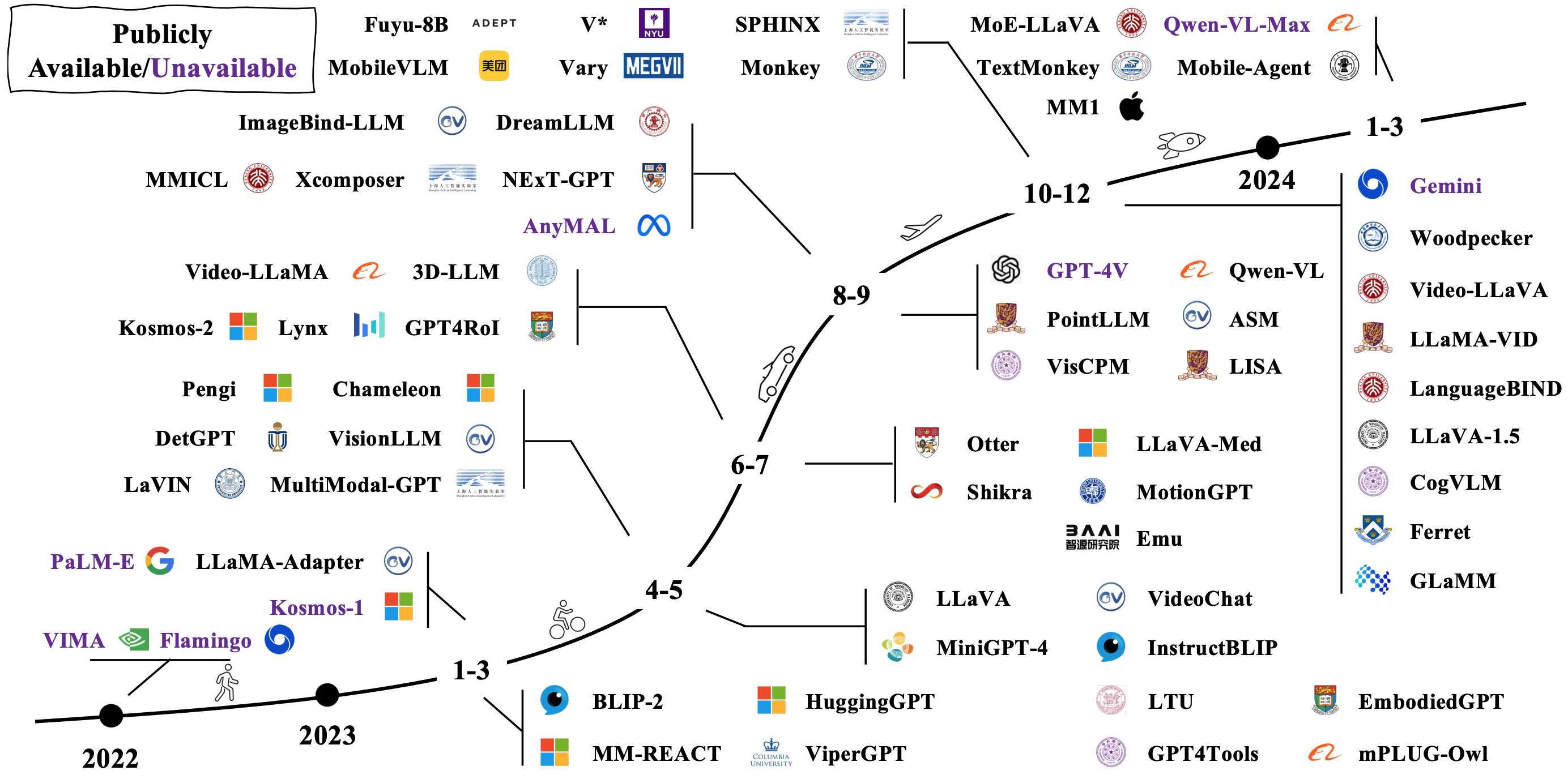
Модель архитектуры
Есть много разных способов противоречить LMMS. Представительные архитектуры включают в себя:
- Языковые модели-это интерфейсы общего назначения
- Flamingo: модель визуального языка для нескольких выстрелов (Neurips 2022)
- Blip: начальная тренировка на основе обработки языка для объединенного понимания и поколения на языке зрения (ICML 2022)
- BLIP-2: предварительная тренировка языка на основе начальной загрузки с замороженными энкодерами изображения и большими языковыми моделями (ICML 2023)
- MPLUG-OWL2: революция в многомодальной большой языковой модели с сотрудничеством модальности
- Флоренция-2: продвижение единого представления для различных задач зрения
- Плотный разъем для MLLMS
Больше бумаг можно найти через ссылку 1 и ссылку 2.
К воплощенным агентам
Объединяя LMM с роботами, исследователи стремятся разработать системы ИИ, которые могут воспринимать, разум и действовать и действовать более естественным и интуитивно понятным образом, с потенциальными приложениями, охватывающими робототехнику, виртуальные помощники, автономные транспортные средства и за его пределами. Вот некоторые представительные работы по реализации воплощенного ИИ с LMMS:
- RT-1: трансформатор робототехники для управления реальным миром в масштабе
- RT-2: модели на языке зрения-назывов
- RT-H: Иерархии действия с использованием языка
- Palm-E: модель воплощенного мультимодального языка
- Transic: Передача политики с рисованием в реальность путем обучения из онлайн-коррекции
Больше бумаг можно найти через ссылку 1 и ссылку 2.
Вот несколько популярных симуляторов и наборов данных для оценки производительности LMMS для воплощенного ИИ:
- Хабитат 3.0: воплощенная платформа для имитации ИИ для изучения совместных задач взаимодействия человека-робот в домашних условиях
- Procstor-10K: 10K Интерактивная домашняя среда для воплощенного ИИ
- Арнольд: эталон для обучения на языке с непрерывными состояниями в реалистичных трехмерных сценах
- Legent: открытая платформа для воплощенных агентов
- Robocasa: крупномасштабное моделирование повседневных задач для генеральных роботов
Больше ресурсов можно найти здесь.
Открытые проблемы
Вот несколько документов опроса, рассказывающих о открытых проблемах для воплощенного ИИ с поддержкой LMM:
- Рост и потенциал агентов, основанных на моделях, на основе крупных языковых моделей: опрос
- Навигация на языку зрения с воплощенным интеллектом: опрос
- Обзор воплощенного ИИ: от симуляторов до исследовательских задач
- Обследование автономных агентов на основе LLM
- Mindstorms в естественных обществах разума
За пределами трансформаторов
Исследователи пытаются изучить новые модели, кроме трансформаторов. Усилия включают в себя неявную структуру параметров модели и определение новых архитектур модели.
Подразумевает структурированные параметры
- Monarch Mixer: повторное количество BERT, без внимания или MLPS
- Мамба: моделирование последовательности линейного времени с селективными пространствами состояния
Новая модель архитектуры
- Гиена иерархия: к более крупным моделям сверточного языка
- RWKV: переосмысление RNN для эпохи трансформатора
- Удерживающая сеть: преемник трансформатора для крупных языковых моделей
- Мамба: моделирование последовательности линейного времени с селективными пространствами состояния
- Кан: Колмогоров -Арнольд Сети
- Трансформаторы - это SSM: обобщенные модели и эффективные алгоритмы через структурированное пространство состояния двойственность
Вот потрясающее руководство для государственных космических моделей.


