 Roteiro generativo da IA
Roteiro generativo da IA
Um guia de aprendizado subjetivo para pesquisa generativa de IA, incluindo lista com curadoria de artigos e projetos
A IA generativa é um tópico quente hoje e este roteiro foi projetado para ajudar os iniciantes a obter conhecimento básico e a encontrar recursos úteis da IA generativa. Até os especialistas podem se referir a este roteiro para recordar o conhecimento antigo e desenvolver novas idéias.
Tabela de conteúdo
- Conhecimento de fundo
- Inferência de redes neurais e treinamento
- Arquitetura do transformador
- Modelos comuns baseados em transformadores
- Variado
- Modelos de idiomas grandes (LLMS)
- Pré-treinamento e ajuste fino
- Solicitando
- Avaliação
- Lidar com um longo contexto
- Ajuste fino eficiente
- Mergor do modelo
- Geração eficiente
- Edição de conhecimento
- Agentes movidos a LLM
- Descobertas
- Desafios abertos
- Modelos de difusão
- Geração de imagens
- Geração de vídeo
- Geração de áudio
- Pré-treinamento e ajuste fino
- Avaliação
- Geração eficiente
- Edição de conhecimento
- Desafios abertos
- Grandes modelos multimodais (LMMs)
- Arquiteturas modelo
- Em direção a agentes incorporados
- Desafios abertos
- Além dos transformadores
- Parâmetros implicitamente estruturados
- Novas arquiteturas de modelo
Conhecimento de fundo
Esta seção deve ajudá-lo a aprender ou recuperar o conhecimento básico das redes neurais (por exemplo, retropropagação), familiarizá-lo com a arquitetura do transformador e descrever alguns modelos comuns baseados em transformadores.
Inferência de redes neurais e treinamento
Você está muito familiarizado com as seguintes estruturas clássicas de rede neural?
- Perceptron de várias camadas (MLP)
- Rede Neural Convolucional (CNN)
- Rede Neural Recorrente (RNN)
Nesse caso, você deve responder a estas perguntas:
- Por que os CNNs funcionam melhor do que os MLPs em imagens?
- Por que os RNNs funcionam melhor do que os MLPs nos dados da série temporal?
- Qual é a diferença entre GRU e LSTM?
Backpropagation (BP) é a base do treinamento NN. Você não será um especialista em IA se não entender a BP . Existem muitos livros didáticos e tutoriais on -line ensinando BP, mas, infelizmente, a maioria deles não apresenta fórmulas em formas vetorizadas/tensorizadas. A fórmula da BP de uma camada NN é realmente tão arrumada quanto sua fórmula de passagem para a frente. É exatamente assim que a BP é implementada e deve ser implementada. Para entender a BP, leia os seguintes materiais:
- Redes neurais e aprendizado profundo [Capítulo 3.2 especialmente 3.2.6]
- MEPROP: Propagação Sparsificada Back para Aprendizado Deep Acelerado com Excesso Reduzido (ICML 2017) [Seção 2.1]
- RESPROP: reutilização de retropropagação (CVPR 2020) [Seção 3.1]
Se você entende a BP, poderá responder a estas perguntas:
- Como você descreverá a BP de uma camada convolucional?
- Qual é a proporção do custo de computação (ou seja, número de operações de ponto flutuante) entre o passe para a frente e o passe para trás de uma camada densa?
- Como você descreverá a BP de um MLP com duas camadas densas compartilhando a mesma matriz de peso?
Arquitetura do transformador
O transformador é a arquitetura base dos grandes modelos generativos existentes. É necessário entender todos os componentes do transformador. Leia os seguintes materiais:
- Atenção é tudo o que você precisa (Neurips 2017) [artigo original]
- Explicação do transformador: Aprendizagem interativa de modelos generativos de texto [um tutorial interativo]
- Uma imagem vale 16x16 palavras: transformadores para reconhecimento de imagem em escala (ICLR 2021) [Vision Transformer]
- Tradução da máquina neural com um transformador e keras [Grande explicação para a atenção multihead (MHA)]
- Flocos de um bloco de transformador [vamos praticar calculando os fracassos]
- Decodificação rápida do transformador: One Write-Head é tudo o que você precisa de [atenção multi-quadrada (MQA)]
- GQA: Treinando modelos generalizados de transformadores multi-query a partir de pontos de verificação de várias cabeças [Atenção de agrupamento (GQA)]]
- Transformador aprimorado com incorporação de posição rotativa [Entenda a incorporação posicional]
- INCLIMENTOS ROTÁRIOS: Uma Revolução Relativa [Entenda a incorporação posicional]
- Forçar o professor vs amostragem programada versus modo normal [Forçamento de professores no treinamento de transformadores]
- Flexgen: Inferência generativa de alto rendimento de grandes modelos de linguagem com uma única GPU [consulte a Seção 3 - Inferência generativa para saber como a geração de petróleo LLMS baseada no cache KV]
- Codificação de posição contextual: aprendendo a contar o que é importante [codificação posicional dependente do contexto]
Se você entende transformadores, poderá responder a estas perguntas:
- Quais são os prós e contras dos transformadores em comparação com os RNNs? (simultaneamente participando, paralelismo de treinamento, complexidade)
- Você pode coçar os fracassos do GQA? Veja quando se degrada para MHA e MQA?
- Qual é a motivação do MQA e GQA?
- Como é a máscara de atenção causal e por quê?
- Como você descreverá o treinamento de transformadores somente para decodificadores passo a passo?
- Por que a corda é melhor do que a codificação posicional sinusoidal?
Modelos comuns baseados em transformadores
- Aprendendo modelos visuais transferíveis da supervisão da linguagem natural [clipe]
- Propriedades emergentes em transformadores de visão auto-supervisionados (ICCV 2021) [DINO]
- Autoencoders mascarados são alunos de visão escalável (CVPR 2022) [MAE]
- Visão de escala com mistura esparsa de especialistas (Neurips 2021) [MOE]
- Mistura de profundidades: alocando dinamicamente a computação em modelos de idiomas baseados em transformadores [mod]
Variado
Einsum é fácil e útil [um ótimo tutorial para o uso de Einsum/Einops]
A abertura é essencial para a inteligência sobre-humana artificial (ICML 2024) [Pensamentos sobre alcançar a IA sobre-humana]
Níveis de AGI para operacionalizar o progresso no caminho para a AGI
Modelos de idiomas grandes (LLMS)
LLMs são transformadores. Eles podem ser categorizados em arquiteturas somente codificador, codificador-decodificador e somente decodificador, como mostrado na árvore evolutiva LLM abaixo [fonte de imagem]. Verifique os documentos marcantes do LLMS.
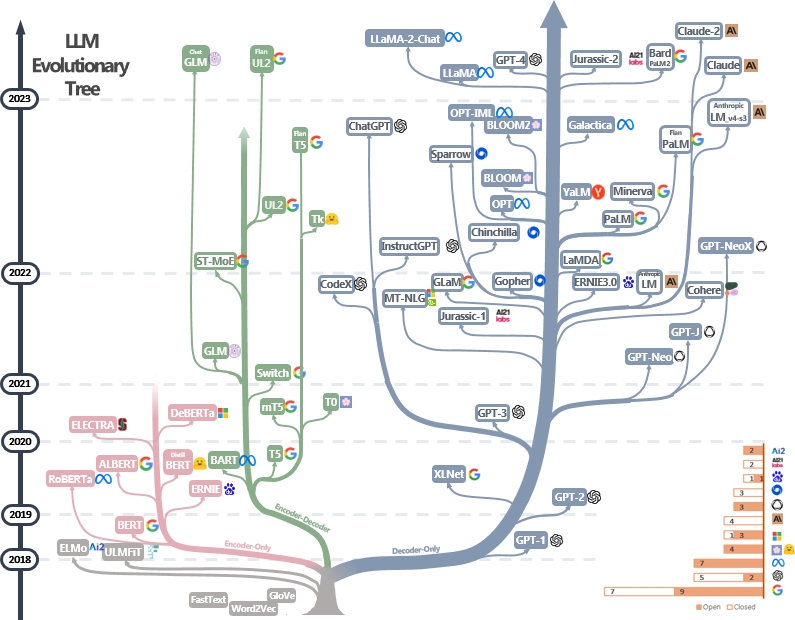
O modelo somente codificador pode ser usado para extrair recursos de frases, mas não possui energia generativa. Os modelos de decodificadores e decodificadores do codificador são usados para geração de texto. Em particular, a maioria dos LLMs existentes prefere estruturas apenas para decodificadores devido ao poder mais forte de repousentação. Intuitivamente, os modelos de codificadores de codificadores podem ser considerados uma versão esparsa dos modelos somente decodificador e as informações decaem mais do codificador ao decodificador. Verifique este artigo para obter mais detalhes.
Pré -treinamento e finetuning
Os LLMs são tipicamente pré -treinados de trilhões de tokens de texto por editores de modelos para internalizar a estrutura da linguagem natural. Os desenvolvedores de modelos de hoje também conduzem o ajuste fino instrucional e o aprendizado de reforço com o feedback humano (RLHF) para ensinar o modelo a seguir as instruções humanas e gerar respostas alinhadas com a preferência humana. Os usuários podem baixar o modelo publicado e o Finetune em pequenos conjuntos de dados pessoais (por exemplo, diálogo de filme). Devido à enorme quantidade de dados, a pré -treinamento requer recursos de computação maciços (por exemplo, mais de milhares de GPUs), o que não é acessível por indivíduos. Por outro lado, o ajuste fino é menos faminto por recursos e pode ser feito com algumas GPUs.
Os seguintes materiais podem ajudá-lo a entender o processo de pré-treinamento e ajuste fino:
- Bert: Pré-treinamento de transformadores bidirecionais profundos para compreensão de idiomas [pré-treinamento e finetuning de LLMs somente para codificadores]
- Modelos de idiomas de instrução de escala-finheiros [pré-treinamento e finetuning instrucional]
- Ilustrando o aprendizado de reforço com o feedback humano (RLHF)
- Modelos de idiomas são poucos alunos do Shot [LLMS somente para decodificadores] [中文导读 por 李沐]
Mais tutoriais podem ser encontrados aqui.
Solicitando
As técnicas de solicitação de LLMs envolvem a criação de texto de entrada de uma maneira que orienta o modelo a gerar respostas ou saídas desejadas. Aqui estão os recursos úteis para ajudá -lo a escrever instruções melhores:
- [Dair.ai] Guia de engenharia imediata
- Prompts de chatgpt impressionantes - uma coleção de exemplos rápidos para serem usados com o modelo ChatGPT
- Awesome Deliberative Ording - Como pedir ao LLMS para produzir raciocínio confiável e tomar decisões responsivas à razão
- Autoprompt - Um método automatizado baseado na pesquisa guiada por gradiente para criar prompts para um conjunto diversificado de tarefas de PNL.
Avaliação
As ferramentas de avaliação para modelos de idiomas grandes ajudam a avaliar seu desempenho, recursos e limitações em diferentes tarefas e conjuntos de dados. Aqui estão algumas estratégias de avaliação comuns:
Métricas de avaliação automática : essas métricas avaliam o desempenho do modelo automaticamente sem intervenção humana. As métricas comuns incluem:
- Bleu: mede a semelhança entre o texto gerado e o texto de referência com base na sobreposição de n-gramas.
- ROUGE: Avalia o resumo do texto comparando N-gramas sobrepostas entre os resumos gerados e de referência.
- Perplexidade: mede o quão bem um modelo de idioma prevê uma amostra de texto. A menor perplexidade indica melhor desempenho. É equivalente à exponenciação da entropia cruzada entre os dados e as previsões do modelo.
- Pontuação F1: mede o equilíbrio entre precisão e recall em tarefas como classificação de texto ou reconhecimento de entidade nomeado.
Avaliação humana : O julgamento humano é essencial para avaliar a qualidade do texto gerado de forma abrangente. Os métodos comuns de avaliação humana incluem:
- Classificações humanas : os anotadores humanos geraram texto com base em critérios como fluência, coerência, relevância e gramaticalidade.
- Plataformas de crowdsourcing : plataformas como o Amazon Mechanical Turk ou a Figura oito facilitam a avaliação humana em larga escala pelas anotações de crowdsourcing.
- Avaliação de especialistas : os especialistas em domínio avaliam saídas do modelo para avaliar sua adequação a aplicações ou tarefas específicas.
Conjuntos de dados de referência : os conjuntos de dados padronizados permitem a comparação justa de modelos em diferentes tarefas e domínios. Exemplos incluem:
- Triviaqa: um conjunto de dados de desafio supervisionado em larga escala para a compreensão da leitura
- Hellaswag: Uma máquina pode realmente terminar sua frase?
- GSM8K: Treinando verificadores para resolver problemas de palavras matemáticas
- Uma lista completa pode ser encontrada aqui
Ferramentas de análise de modelo: ferramentas para analisar o comportamento e o desempenho do modelo incluem:
- Interpretabilidade automatizada - Código para geração, simulação e pontuação automaticamente explicações do comportamento do neurônio
- Visualização LLM - Visualizando LLMs em baixo nível.
- Análise de atenção - Analisando mapas de atenção do transformador Bert.
- Visualizador de neurônios - ferramenta para visualizar ativações e explicações de neurônios.
Uma lista completa pode ser encontrada aqui
As estruturas de avaliação padrão para os LLMs existentes incluem:
- LM-Evaluation-Harness-Uma estrutura para avaliação de poucos modelos de idiomas.
- LIGHTEVAL - Uma suíte de avaliação leve LLM que o rosto de abraço tem usado internamente.
- OLMO -EVAL - Um repositório para avaliar modelos de linguagem aberta.
- Instruct-Eval-Este repositório contém código para avaliar quantitativamente os modelos ajustados por instruções, como ALPACA e FLAN-T5, em tarefas de retirada.
Lidar com um longo contexto
Lidar com contextos longos representa um desafio para grandes modelos de idiomas devido a limitações na memória e na capacidade de processamento. As técnicas existentes incluem:
- Transformadores eficientes
- Longformer: o transformador de documentos de longa data
- Reformador: o transformador eficiente (ICLR 2020)
- Modelos de espaço de estado
- Transformadores são RNNs: Transformadores autorregressivos rápidos com atenção linear (ICML 2020)
- Repensando a atenção com artistas
- Extrapolação de comprimento
- Mamba: modelagem de sequência de tempo linear com espaços de estado seletivos
- ROFORMER: transformador aprimorado com incorporação de posição rotativa
- Fio: Extensão eficiente da janela de contexto de grandes modelos de linguagem
- Memória de longo prazo
- MemoryBank: Aprimorando grandes modelos de linguagem com memória de longo prazo
- Libertar a capacidade de entrada de comprimento infinito para modelos de linguagem em larga escala com sistema de memória autocontrolada
Uma lista completa pode ser encontrada aqui
Finetuning eficiente
Os métodos de ajuste fino (PEFT) com eficiência de parâmetro permitem adaptação eficiente de grandes modelos pré-treinados a várias aplicações a jusante, apenas ajustando um pequeno número de parâmetros (extras) do modelo em vez de todos os parâmetros do modelo:
- Ajuste rápido: o poder da escala para ajuste rápido com eficiência de parâmetro
- Ajuste do prefixo: ajuste do prefixo: otimizando os avisos contínuos para a geração
- Lora: Lora: Adaptação de baixo rank de grandes modelos de linguagem
- Em direção a uma visão unificada do aprendizado de transferência eficiente em parâmetro
- Lora aprende menos e esquece menos
Mais trabalho pode ser encontrado na coleção de papel do HuggingFace Peft e é altamente recomendável praticar com a API da HuggingFace Peft.
Mergor do modelo
A fusão do modelo refere -se à fusão de dois ou mais LLMs treinados em diferentes tarefas em um único LLM. Essa técnica visa alavancar os pontos fortes e o conhecimento de diferentes modelos para criar um modelo mais robusto e capaz. Por exemplo, um LLM para geração de código e outro LLM para a resolução de prolem de matemática podem ser mesclados para que o modelo mesclado seja capaz de fazer a geração de código e a solução de problemas de matemática.
A fusão do modelo é intrigante porque pode ser efetivamente alcançada com algoritmos muito simples e baratos (por exemplo, combinação linear de pesos do modelo). Aqui estão alguns papéis representativos e materiais de leitura:
- Sopas modelo: pesos médios de múltiplos modelos de ajuste fino melhora a precisão sem aumentar o tempo de inferência
- Editando modelos com aritmética de tarefas
- Mesclar modelos de idiomas grandes com Mergekit
Mais trabalhos sobre a fusão do modelo podem ser encontrados aqui
Geração eficiente
A decodificação de LLMs é crucial para melhorar a velocidade e a eficiência da inferência, especialmente em aplicações em tempo real ou sensíveis à latência. Aqui estão algum trabalho representativo de acelerar o processo de decodificação do LLMS:
- DEJA VU: Sparsidade contextual para LLMs eficientes em tempo de inferência (ICML 2023 oral)
- Llmlingua: comprimindo avisos para inferência acelerada de grandes modelos de linguagem (EMNLP 2023)
- Modelos de linguagem de streaming eficientes com afundamentos de atenção
- Especinfer: acelerando LLM generativo que serve com inferência especulativa e verificação de árvores de token
- Medusa: estrutura de aceleração de inferência LLM simples com várias cabeças de decodificação
- Modelos de idiomas grandes e mais rápidos por meio de previsão de vários toques
- Skip de camada: permitindo a inferência de saída precoce e decodificação auto-especulativa
Mais trabalho sobre a aceleração da decodificação LLM pode ser encontrada via link 1 e link 2.
Edição de conhecimento
A edição de conhecimento tem como objetivo modificar com eficiência os comportamentos do LLMS, como reduzir o viés e a revisão de correlações aprendidas. Inclui muitos tópicos, como localização de conhecimento e desaprendizagem. O trabalho representativo inclui:
- Edição de modelo baseado em memória em escala (ICML 2022)
- Transformer-Patcher: um erro no valor de um neurônio (ICLR 2023)
- Edição massiva para modelo de idioma grande via Meta Learning (ICLR 2024)
- Uma estrutura unificada para edição de modelos
- As camadas de feed-forward do transformador são memórias de valor-chave (EMNLP 2021)
- Memória de edição em massa em um transformador
Mais documentos podem ser encontrados aqui.
Agentes movidos a LLM
Ao receber o Massive Training, o LLMS Digest World Knowledge e é capaz de seguir com precisão as instruções de entrada. Com esses recursos incríveis, os LLMs podem ser executados como agentes possíveis para resolver autonomamente (e colaborativamente) tarefas complexas ou simular interações humanas. Aqui estão alguns trabalhos representativos dos agentes LLM:
- Agentes generativos: simulacra interativo do comportamento humano (UIST 2023) [LLMS simula a sociedade humana em videogames]
- Sotopia: avaliação interativa para inteligência social em agentes de idiomas (ICLR 2024) [LLMS simulam interações sociais]
- Voyager: um agente incorporado aberto com grandes modelos de idiomas [LLMS Live no mundo Minecraft]
- Grandes modelos de linguagem como fabricantes de ferramentas (ICLR 2024) [LLMS criam suas próprias ferramentas reutilizáveis (por exemplo, em funções Python) para solução de problemas]
- Metagpt: meta-programação para estrutura colaborativa multi-agente [LLMS como uma equipe para desenvolvimento automatizado de software]
- Webarena: um ambiente da Web realista para a construção de agentes autônomos (ICLR 2024) [LLMs usam aplicativos da Web]
- Mobile-ENV: Uma plataforma de avaliação e referência para interação LLM-GUI [LLMS Use aplicativos móveis]
- HuggingGPT: resolvendo tarefas de IA com ChatGPT e seus amigos no rosto abraçando (Neurips 2023) [LLMs buscam modelos em huggingface para solução de problemas]
- Agente: Evoluindo grandes agentes baseados em modelos de linguagem em diversos ambientes [diversos ambientes e tarefas interativas para agentes baseados em LLM]
Uma lista completa de artigos, plataformas e ferramentas de avaliação pode ser encontrada aqui.
Descobertas
- Seu transformador é secretamente linear
- Nem todos os recursos do modelo de idioma são lineares
- Kan ou MLP: uma comparação mais justa
- Camadas de transformador como pintores
- Os modelos de linguagem de visão são cegos
Desafios abertos
Os LLMs enfrentam vários desafios abertos que pesquisadores e desenvolvedores estão trabalhando ativamente para enfrentar. Esses desafios incluem:
- Alucinação
- Uma pesquisa abrangente de técnicas de mitigação de alucinação em grandes modelos de idiomas
- Modelo de compactação
- Uma pesquisa abrangente de algoritmos de compressão para modelos de idiomas
- Avaliação
- Avaliando grandes modelos de idiomas: uma pesquisa abrangente
- Raciocínio
- Uma pesquisa de raciocínio com modelos de fundação
- Explicação
- Do entendimento à utilização: uma pesquisa sobre explicação para grandes modelos de idiomas
- Justiça
- Uma pesquisa sobre justiça em grandes modelos de idiomas
- Factualidade
- Uma pesquisa sobre factualidade em grandes modelos de idiomas: conhecimento, recuperação e especificidade de domínio
- Integração do conhecimento
- Tendências na integração de conhecimentos e grandes modelos de idiomas: uma pesquisa e taxonomia de métodos, benchmarks e aplicativos
Uma lista completa pode ser encontrada aqui.
Modelos de difusão
Os modelos de difusão visam aproximar a distribuição de probabilidade de um determinado domínio de dados e fornecer uma maneira de gerar amostras a partir de sua distribuição aproximada. Seus objetivos são semelhantes a outros modelos generativos populares, como VAE, Gans e fluxos normalizando.
O fluxo de trabalho dos modelos de difusão é apresentado com dois processos:
- Processo de encaminhamento (processo de difusão): ele aplica progressivamente ruído aos dados de entrada original passo a passo até que os dados se tornem completamente ruído.
- Processo reverso (processo de denoising): um modelo NN (por exemplo, CNN ou Transformer) é treinado para estimar o ruído aplicado em cada etapa durante o processo a termo. Esse modelo NN treinado pode ser usado para gerar dados a partir de entrada de ruído. Os modelos de difusão existentes também podem aceitar outros sinais (por exemplo, instruções de texto dos usuários) para condicionar a geração de dados.
Verifique este blog incrível e mais tutoriais introdutórios podem ser encontrados aqui. Os modelos de difusão podem ser usados para gerar imagens, áudios, vídeos e muito mais, e há muitos subcampos relacionados a modelos de difusão, como mostrado abaixo [Fonte da imagem]:
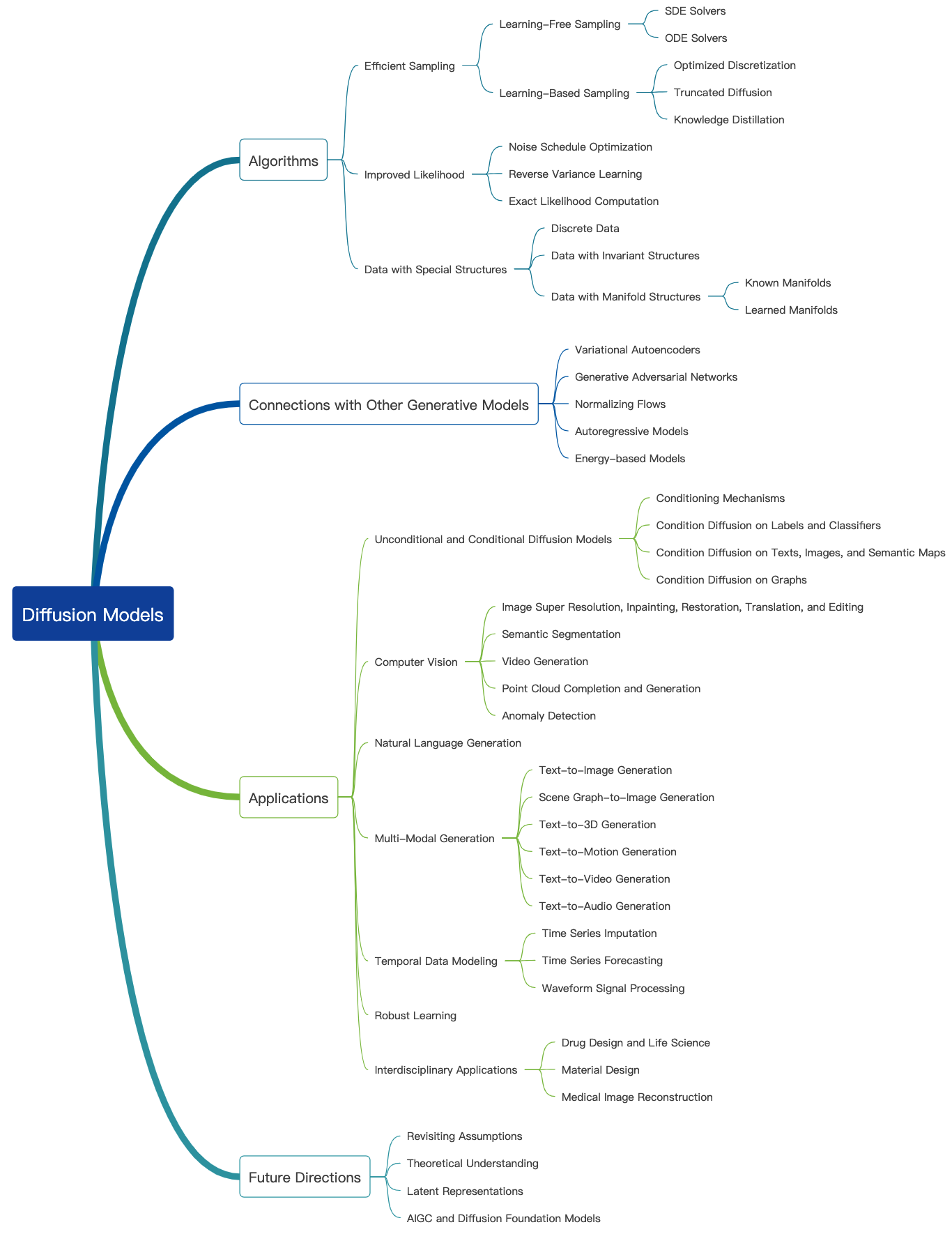
Geração de imagens
Aqui estão alguns trabalhos representativos de modelos de difusão para geração de imagens:
- Síntese de imagem de alta resolução com modelos de difusão latente (CVPR 2022)
- Paleta: modelos de difusão de imagem a imagem (Siggraph 2022)
- Super-resolução de imagem via refinamento iterativo
- Painting usando modelos probabilísticos de difusão de denoising (CVPR 2022)
- Adicionando controle condicional aos modelos de difusão de texto para imagem (ICCV 2023)
Mais documentos podem ser encontrados aqui.
Geração de vídeo
Aqui estão alguns documentos representativos de modelos de difusão para geração de vídeo:
- Modelos de difusão de vídeo
- Modelagem de difusão flexível de vídeos longos (Neurips 2022)
- Escala modelos de difusão em vídeo latentes para grandes conjuntos de dados
- I2VGEN-XL: Síntese de imagem para video de alta qualidade via modelos de difusão em cascata
Mais documentos podem ser encontrados aqui.
Geração de áudio
Aqui estão alguns trabalhos representativos de modelos de difusão para geração de áudio:
- Grad-tts: um modelo probabilístico de difusão para texto em fala
- Geração de texto para áudio usando LLM ajustado para instrução e modelo de difusão latente
- Condicionamento de voz com tiro zero para modelos TTS de difusão de denoising
- Editts: edição baseada em pontuação para o texto em fala controlável
- Prodiff: Modelo de difusão rápida progressiva para texto em fala de alta qualidade
Mais documentos podem ser encontrados aqui.
Pré -treinamento e finetuning
Semelhante a outros grandes modelos generativos, os modelos de difusão também são pré-treinados em uma grande quantidade de dados da Web (por exemplo, conjunto de dados Laion-5b) e consomem enormes recursos de computação. Os usuários podem baixar os pesos lançados podem ajustar ainda mais o modelo em conjuntos de dados pessoais.
Aqui estão alguns trabalhos representativos de ajuste fino eficiente de modelos de difusão:
- Dreambooth: Modelos de difusão de texto de ajuste fino para geração orientada por assuntos (CVPR 2023)
- Uma imagem vale uma palavra: personalizar a geração de texto para imagem usando inversão textual (ICLR 2023)
- Difusão personalizada: Personalização de conceito multi-conceito da difusão de texto a imagem (CVPR 2023)
- Controlando a difusão de texto para a imagem por finetuning ortogonal (Neurips 2023)
Mais documentos podem ser encontrados aqui.
É altamente recomendável fazer alguma prática com a API do HuggingFacer Diffusers.
Avaliação
Aqui falamos sobre avaliação de modelos de difusão para geração de imagens. Muitas métricas de qualidade de imagem existentes podem ser aplicadas.
- Pontuação do clipe: a pontuação do clipe mede a compatibilidade dos pares de capturas de imagem. Os escores mais altos do clipe implicam maior compatibilidade. Verificou -se que a pontuação do clipe apresentava alta correlação com o julgamento humano.
- FIRCHET INCCECTIONS Distância (FID): FID pretende medir quão semelhantes são dois conjuntos de dados de imagens. É calculado calculando a distância de Fréchet entre dois gaussianos instalados para apresentar representações da rede de início
- A semelhança direcional do clipe: ele mede a consistência da mudança entre as duas imagens (no espaço do clipe) com a mudança entre as duas legendas da imagem.
Mais métricas de qualidade de imagem e ferramentas de cálculo podem ser encontradas aqui.
Geração eficiente
Os modelos de difusão requerem várias etapas avançadas para gerar dados, o que é caro. Aqui estão alguns trabalhos representativos de modelos de difusão para geração eficiente:
- Tenho que ir rápido ao gerar dados com modelos baseados em pontuação
- Amostragem rápida de modelos de difusão com integrador exponencial
- Aprendendo amostradores rápidos para modelos de difusão, diferenciando -se através da qualidade da amostra
- Acelerando modelos de difusão via parada precoce do processo de difusão
Mais documentos podem ser encontrados aqui.
Edição de conhecimento
Aqui estão alguns artigos representativos da edição de conhecimento para modelos de difusão:
- Apagando os conceitos de modelos de difusão (ICCV 2023)
- Editando conceitos maciços em modelos de difusão de texto a imagem
- Esqueça-me-não: Aprendendo a esquecer nos modelos de difusão de texto para imagem
Mais documentos podem ser encontrados aqui.
Desafios abertos
Aqui estão alguns trabalhos de pesquisa falando sobre os desafios enfrentados pelos modelos de difusão.
- Uma pesquisa com modelos de geração de imagem baseados em difusão
- Uma pesquisa sobre modelos de difusão de vídeo
- Estado da arte em modelos de difusão para computação visual
- Modelos de difusão na NLP: uma pesquisa
Grandes modelos multimodais (LMMs)
Os LMMs típicos são construídos pela conexão e ajuste fino, modelos unimodais pré-ridicularizados existentes. Alguns também são pré -treinados do zero. Verifique como o LMMS evolui na imagem abaixo [Fonte da imagem].
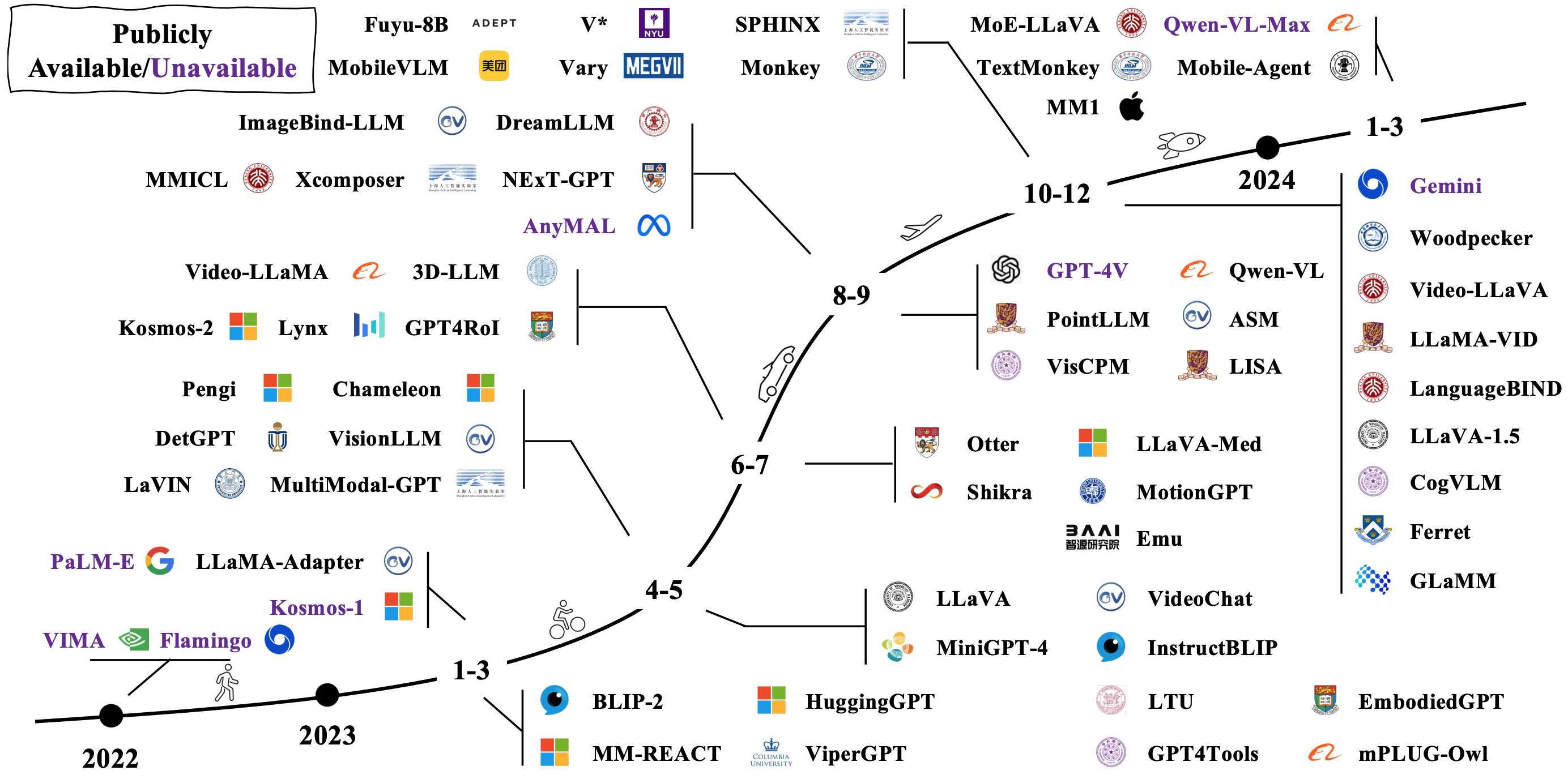
Arquiteturas modelo
Existem muitas maneiras diferentes de contribuir com LMMs. As arquiteturas representativas incluem:
- Modelos de idiomas são interfaces de uso geral
- Flamingo: um modelo de linguagem visual para aprendizado de poucos tiros (Neurips 2022)
- Blip: Pré-treinamento de imagem de linguagem de bootstrapping para compreensão e geração unificada da linguagem da visão (ICML 2022)
- BLIP-2: Pré-treinamento de imagem de linguagem de inicialização com codificadores de imagem congelada e modelos de linguagem grandes (ICML 2023)
- mplug-awl2: revolucionando o modelo de linguagem grande multimodal com colaboração de modalidade
- Florence-2: Avançar uma representação unificada para uma variedade de tarefas de visão
- Conector denso para mllms
Mais documentos podem ser encontrados via link 1 e link 2.
Em direção a agentes incorporados
Ao combinar LMMs com robôs, os pesquisadores pretendem desenvolver sistemas de IA que possam perceber, raciocinar e agir sobre o mundo de uma maneira mais natural e intuitiva, com aplicações em potencial abrangendo robótica, assistentes virtuais, veículos autônomos e além. Aqui estão algum trabalho representativo de realizar IA incorporada com LMMs:
- RT-1: Transformador de robótica para controle do mundo real em escala
- RT-2: Modelos de ação de visão de visão transferem conhecimento da Web para controle robótico
- RT-H: hierarquias de ação usando linguagem
- Palm-E: um modelo de linguagem multimodal incorporada
- Transic: transferência de políticas SIM-para-real, aprendendo da correção on-line
Mais documentos podem ser encontrados via link 1 e link 2.
Aqui estão alguns simuladores e conjuntos de dados populares para avaliar o desempenho do LMMS para IA incorporada:
- Habitat 3.0: Uma plataforma de simulação de IA incorporada para estudar tarefas colaborativas de interação humana-robô em ambientes domésticos
- ProcThor-10k: 10K ambientes domésticos interativos para IA incorporada
- Arnold: Uma referência para o aprendizado de tarefas fundamentado em idiomas com estados contínuos em cenas 3D realistas
- LEGENT: plataforma aberta para agentes incorporados
- Robocasa: simulação em larga escala de tarefas diárias para robôs generalistas
Mais recursos podem ser encontrados aqui.
Desafios abertos
Aqui estão alguns documentos de pesquisa falando sobre desafios abertos para IA incorporada habilitada para LMM:
- A ascensão e potencial de grandes agentes baseados em modelos de linguagem: uma pesquisa
- Navegação em linguagem de visão com inteligência incorporada: uma pesquisa
- Uma pesquisa de IA incorporada: de simuladores a tarefas de pesquisa
- Uma pesquisa sobre agentes autônomos baseados em LLM
- Tempestades mentais em sociedades mentais baseadas em linguagem natural
Além dos transformadores
Os pesquisadores estão tentando explorar novos modelos além dos transformadores. Os esforços incluem implicitamente estruturando parâmetros do modelo e definição de novas arquiteturas de modelos.
Parâmetros implicados de estruturas
- Mixer Monarch: Revisitando Bert, sem atenção ou MLPs
- Mamba: modelagem de sequência de tempo linear com espaços de estado seletivos
Novas arquiteturas de modelo
- Hierarquia de hiena: em direção a maiores modelos de linguagem convolucional
- RWKV: Reinventando RNNs para a era do transformador
- Rede retentiva: um sucessor para transformador para grandes modelos de idiomas
- Mamba: modelagem de sequência de tempo linear com espaços de estado seletivos
- KAN: Redes Kolmogorov -Arnold
- Transformadores são SSMs: modelos generalizados e algoritmos eficientes através da dualidade de espaço de estado estruturado
Aqui está um tutorial incrível para modelos de espaço do estado.


