 Feuille de route générative AI
Feuille de route générative AI
Un guide d'apprentissage subjectif pour la recherche générative d'IA, y compris la liste organisée des articles et des projets
L'IA générative est un sujet brûlant aujourd'hui et cette feuille de route est conçue pour aider les débutants à acquérir rapidement les connaissances de base et à trouver des ressources utiles de l'IA générative. Même les experts sont invités à se référer à cette feuille de route pour rappeler les anciennes connaissances et développer de nouvelles idées.
Tableau de contenu
- Connaissances de base
- Réseaux de neurones Inférence et formation
- Architecture transformateur
- Modèles basés sur un transformateur commun
- Divers
- Modèles de grande langue (LLMS)
- Pré-formation et affinage
- Incitation
- Évaluation
- Faire face à un long contexte
- Amende efficace
- Fusion de modèles
- Génération efficace
- Modification des connaissances
- Agents alimentés par LLM
- Résultats
- Défis ouverts
- Modèles de diffusion
- Génération d'images
- Génération de vidéos
- Génération audio
- Pré-formation et affinage
- Évaluation
- Génération efficace
- Modification des connaissances
- Défis ouverts
- Grands modèles multimodaux (LMM)
- Architectures de modèle
- Vers des agents incarnés
- Défis ouverts
- Au-delà des transformateurs
- Paramètres structurés implicitement
- Nouvelles architectures de modèle
Connaissances de base
Cette section devrait vous aider à apprendre ou à regagner les connaissances de base des réseaux de neurones (par exemple, rétro-propagation), vous familiariser avec l'architecture du transformateur et décrire certains modèles communs basés sur le transformateur.
Réseaux de neurones Inférence et formation
Êtes-vous très familier avec les structures de réseau neuronal classiques suivantes?
- Perceptron multi-couches (MLP)
- Réseau neuronal convolutionnel (CNN)
- Réseau neuronal récurrent (RNN)
Si c'est le cas, vous devriez pouvoir répondre à ces questions:
- Pourquoi les CNN fonctionnent-ils mieux que les MLP sur les images?
- Pourquoi les RNN fonctionnent-ils mieux que les MLP sur les données de la série temporelle?
- Quelle est la différence entre GRU et LSTM?
La rétropropagation (BP) est la base de la formation NN. Vous ne serez pas un expert en IA si vous ne comprenez pas BP . Il existe de nombreux manuels et tutoriels en ligne qui enseignent BP, mais malheureusement, la plupart d'entre eux ne présentent pas de formules sous des formes vectorisées / tenorisées. La formule BP d'une couche NN est en effet aussi soignée que sa formule de passe avant. C'est exactement ainsi que BP est implémenté et doit être mis en œuvre. Pour comprendre BP, veuillez lire les documents suivants:
- Réseaux de neurones et apprentissage en profondeur [Chapitre 3.2 en particulier 3.2.6]
- MEPROP: Propagation du dos sparsifiée pour l'apprentissage en profondeur accéléré avec un sur-ajustement réduit (ICML 2017) [Section 2.1]
- RESPROP: réutiliser la rétropropagation de la réduction (CVPR 2020) [Section 3.1]
Si vous comprenez BP, vous devriez être en mesure de répondre à ces questions:
- Comment décrirez-vous la PA d'une couche convolutionnelle?
- Quel est le rapport entre le coût informatique (c'est-à-dire le nombre d'opérations de points flottants) entre la passe avant et la passe arrière d'une couche dense?
- Comment décrirez-vous le BP d'un MLP avec deux couches denses partageant la même matrice de poids?
Architecture transformateur
Le transformateur est l'architecture de base des grands modèles génératifs existants. Il est nécessaire de comprendre chaque composant du transformateur. Veuillez lire les documents suivants:
- L'attention est tout ce dont vous avez besoin (Neirips 2017) [papier d'origine]
- Explicateur de transformateur: apprentissage interactif des modèles générateurs de texte [un tutoriel interactif]
- Une image vaut 16x16 mots: transformateurs pour la reconnaissance d'image à l'échelle (ICLR 2021) [Transformateur de vision]
- Traduction de machine neurale avec un transformateur et des keras [grande explication de l'attention multi-tête (MHA)]
- Les flops d'un bloc de transformateur [pratiquons le calcul des flops]
- Décodage du transformateur rapide: une tête d'écriture est tout ce dont vous avez besoin [ATTENTION multi-Quey (MQA)]
- GQA: Formation des modèles de transformateurs multi-redes généralisés à partir de points de contrôle multi-têtes [Attention à requête groupée (GQA)]
- Transformateur amélioré avec une position rotative Incorpore [Comprendre l'intégration de position]
- Incorporation rotative: une révolution relative [comprendre l'incorporation de position]
- Enseignant forçant par rapport à l'échantillonnage programmé vs mode normal [enseignant forçant la formation des transformateurs]
- Flexgen: inférence générative à haut débit de modèles de grands langues avec un seul GPU [voir la section 3 - Inférence générative pour apprendre comment la génération de LLMS PEFORM basée sur le cache KV]
- Encodage de position contextuelle: apprendre à compter ce qui est important [codage positionnel dépendant du contexte]
Si vous comprenez les transformateurs, vous devriez être en mesure de répondre à ces questions:
- Quels sont les avantages et les inconvénients des tranformes par rapport aux RNN? (simultanément assister, entraînement parallélisme, complexité)
- Pouvez-vous caculer les flops de GQA? Voyez quand se dégrade-t-il en MHA et MQA?
- Quelle est la motivation de la MQA et du GQA?
- À quoi ressemble le masque d'attention causal et pourquoi?
- Comment décrirez-vous la formation des transformateurs uniquement sur le décodeur étape par étape?
- Pourquoi la corde est-elle meilleure que le codage positionnel sinusoïdal?
Modèles basés sur un transformateur commun
- Apprendre des modèles visuels transférables de la supervision du langage naturel [Clip]
- Propriétés émergentes dans les transformateurs de vision auto-supervisés (ICCV 2021) [Dino]
- Les autoencodeurs masqués sont des apprenants de vision évolutifs (CVPR 2022) [MAE]
- Échelle de la vision avec un mélange clairsemé d'experts (Neirips 2021) [MOE]
- Mélange de dépassement: allocation dynamiquement du calcul dans les modèles de langage basés sur les transformateurs [MOD]
Divers
Einsum est facile et utile [un excellent tutoriel pour utiliser Einsum / Einops]
L'ouverture de l'ouverture est essentielle pour l'intelligence surhumaine artificielle (ICML 2024) [Réflexions sur la réalisation de l'IA surhumaine]
Niveaux d'AGI pour l'opérationnalisation des progrès sur le chemin de l'AGI
Modèles de grande langue (LLMS)
Les LLM sont des transformateurs. Ils peuvent être classés en encodeur uniquement, encodeur encodeur et en architectures de décodeur uniquement, comme le montre l'arbre évolutionnaire LLM ci-dessous [source d'image]. Vérifiez les documents marquants de LLMS.
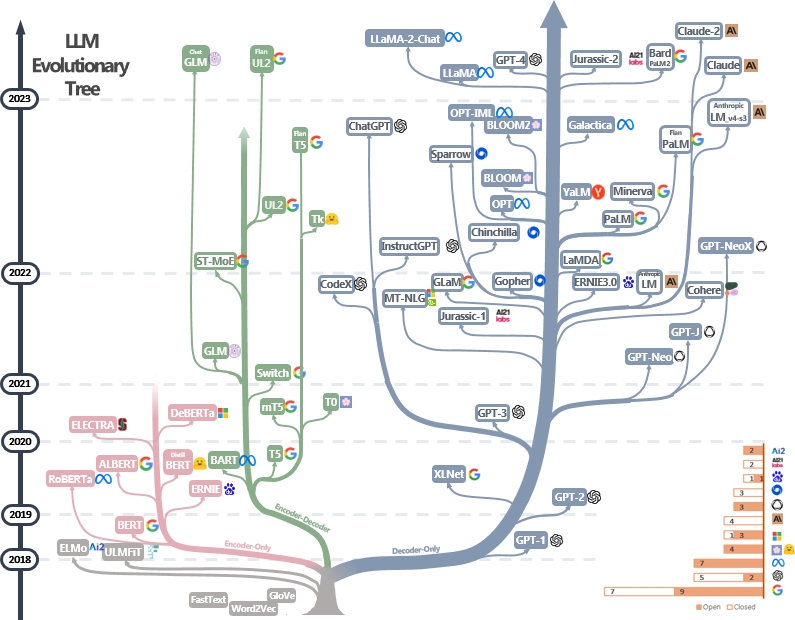
Le modèle de l'encodeur peut être utilisé pour extraire les caractéristiques de la phrase mais manque de puissance générative. Les modèles d'encodeur-décodeur et de décodeur sont utilisés pour la génération de texte. En particulier, la plupart des LLM existantes préfèrent les structures de décodeur uniquement en raison de la puissance de repsession plus forte. Intuitivement, les modèles d'encodeur peuvent être considérés comme une version clairsemée des modèles de décodeur uniquement et les informations se décomposent davantage d'un encodeur au décodeur. Vérifiez ce document pour plus de détails.
Pré-entraînement et finetun
Les LLM sont généralement pré-entraînées à partir de milliards de jetons de texte par des éditeurs de modèles pour intérioriser la structure du langage naturel. Les développeurs du modèle d'aujourd'hui mènent également des réglages pédagogiques et des renforts de l'apprentissage de la rétroaction humaine (RLHF) pour enseigner au modèle à suivre les instructions humaines et générer des réponses alignées sur la préférence humaine. Les utilisateurs peuvent ensuite télécharger le modèle publié et Finetune It sur de petits ensembles de données personnels (par exemple, la boîte de dialogue du film). En raison de l'énorme quantité de données, la pré-formation nécessite des ressources informatiques massives (par exemple, plus de milliers de GPU), ce qui est inabordable par les individus. D'un autre côté, le réglage fin est moins gourmand en ressources et peut être fait avec quelques GPU.
Les documents suivants peuvent vous aider à comprendre le processus de pré-formation et de réglage fin:
- Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage [pré-formation et finetun de LLMS uniquement encodeur]
- Échelle des modèles de langue au fin des instructions [Finetuning de pré-formation et pédagogique]
- Illustrer l'apprentissage du renforcement de la rétroaction humaine (RLHF)
- Les modèles de langue sont des apprenants à quelques coups [LLMS uniquement du décodeur] [中文导读 par 李沐]
Plus de tutoriels peuvent être trouvés ici.
Incitation
Les techniques d'incitation pour les LLM impliquent la fabrication de texte d'entrée d'une manière qui guide le modèle pour générer des réponses ou des sorties souhaitées. Voici les ressources utiles pour vous aider à rédiger de meilleures invites:
- [Dair.ai] Guide d'ingénierie rapide
- Invites impressionnantes de chatppt - Une collection d'exemples rapides à utiliser avec le modèle Chatgpt
- Imposition délibérative impressionnante - Comment demander aux LLM pour produire un raisonnement fiable et prendre des décisions réactives
- AutoPropost - Une méthode automatisée basée sur la recherche guidée par un gradient pour créer des invites pour un ensemble diversifié de tâches NLP.
Évaluation
Les outils d'évaluation pour les modèles de grands langues aident à évaluer leurs performances, leurs capacités et leurs limites entre différentes tâches et ensembles de données. Voici quelques stratégies d'évaluation courantes:
Métriques d'évaluation automatiques : ces mesures évaluent automatiquement les performances du modèle sans intervention humaine. Les mesures courantes comprennent:
- BLEU: mesure la similitude entre le texte généré et le texte de référence basé sur le chevauchement N-gram.
- Rouge: évalue le résumé de texte en comparant les grammes de N qui se chevauchent entre les résumés générés et de référence.
- Perplexité: mesure dans quelle mesure un modèle de langue prédit un échantillon de texte. La perplexité plus faible indique de meilleures performances. Il équivaut à l'exponentiation de l'entropie croisée entre les données et les prédictions du modèle.
- Score F1: mesure l'équilibre entre la précision et le rappel dans les tâches comme la classification du texte ou la reconnaissance des entités nommées.
Évaluation humaine : le jugement humain est essentiel pour évaluer la qualité du texte généré de manière approfondie. Les méthodes d'évaluation humaine courantes comprennent:
- Évaluations humaines : le taux des annotateurs humains a généré du texte basé sur des critères tels que la maîtrise, la cohérence, la pertinence et la grammaticalité.
- Plateformes de crowdsourcing : des plates-formes comme Amazon Mechanical Turc ou la figure huit facilitent l'évaluation humaine à grande échelle par des annotations de crowdsourcing.
- Évaluation des experts : les experts du domaine évaluent les résultats du modèle pour évaluer leur aptitude à des applications ou des tâches spécifiques.
Ensembles de données de référence : les ensembles de données standardisés permettent une comparaison équitable des modèles entre différentes tâches et domaines. Les exemples incluent:
- Triviaqa: un ensemble de données de défi à grande échelle à grande échelle pour la compréhension de la lecture
- Hellaswag: Une machine peut-elle vraiment terminer votre phrase?
- GSM8K: Formation des vérificateurs pour résoudre les problèmes de mots mathématiques
- Une liste complète peut être trouvée ici
Outils d'analyse du modèle: les outils d'analyse du comportement et des performances du modèle comprennent:
- Interprétabilité automatisée - Code de génération, simulant et score automatiquement des explications du comportement des neurones
- Visualisation LLM - Visualiser les LLM à bas niveau.
- Analyse de l'attention - Analyser les cartes d'attention de Bert Transformer.
- Visionneuse de neurones - outil pour visualiser les activations et explications des neurones.
Une liste complète peut être trouvée ici
Les cadres d'évaluation standard pour les LLM existants comprennent:
- LM-Evaluation-Garness - Un cadre pour l'évaluation à quelques coups des modèles linguistiques.
- LightEval - une suite d'évaluation LLM légère que le visage étreint utilise en interne.
- OLMO-EVAL - Un référentiel pour évaluer les modèles de langage ouvert.
- Instruct-Eval - Ce référentiel contient du code pour évaluer quantitativement des modèles réglés par l'instruction tels que l'alpaca et le flan-T5 sur les tâches maintenues.
Faire face à un long contexte
Faire face à de longs contextes pose un défi pour les modèles de langue importants en raison de limitations de mémoire et de capacité de traitement. Les techniques existantes comprennent:
- Transformers efficaces
- LongFormer: le transformateur à long document
- Réformateur: le transformateur efficace (ICLR 2020)
- Modèles d'état d'espace
- Les transformateurs sont RNNS: Transformers autorégressifs rapides avec une attention linéaire (ICML 2020)
- Repenser l'attention avec les artistes
- Extrapolation de longueur
- Mamba: modélisation de séquences linéaires avec des espaces d'état sélectifs
- Roformer: transformateur amélioré avec une position rotative incorporation
- YARN: Extension de fenêtre de contexte efficace des grands modèles de langue
- Mémoire à long terme
- MemoryBank: Amélioration des modèles de grandes langues avec mémoire à long terme
- Lifère la capacité d'entrée de longueur infinie pour les modèles de langage à grande échelle avec un système de mémoire auto-contrôlée
Une liste complète peut être trouvée ici
Finetunage efficace
Les méthodes de réglage fin et économes par les paramètres (PEFT) permettent une adaptation efficace de grands modèles pré-entraînés à diverses applications en aval en affinant uniquement un petit nombre de paramètres (supplémentaires) au lieu de tous les paramètres du modèle:
- Réglage rapide: la puissance de l'échelle pour un réglage rapide économe en paramètres
- Préfixe Tuning: Préfixe-Tuning: Optimiser les invites continues pour la génération
- Lora: Lora: Adaptation de faible rang des modèles de grandes langues
- Vers une vision unifiée de l'apprentissage du transfert économe en paramètres
- Lora apprend moins et oublie moins
Plus de travaux peuvent être trouvés dans la collection de papier PEFT de HuggingFace et il est fortement recommandé de s'entraîner avec HuggingFace PEFT API.
Fusion de modèles
La fusion du modèle fait référence à la fusion de deux LLM ou plus formées sur différentes tâches dans un seul LLM. Cette technique vise à tirer parti des forces et des connaissances de différents modèles pour créer un modèle plus robuste et plus capable. Par exemple, un LLM pour la génération de code et un autre LLM pour la résolution de prolem mathématiques peuvent être fusionnés afin que le modèle fusionné soit capable de faire à la fois la génération de code et la résolution de problèmes mathématiques.
La fusion du modèle est intrigante car elle peut être réalisée efficacement avec des algorithmes très simples et bon marché (par exemple, combinaison linéaire de poids du modèle). Voici quelques articles représentatifs et matériel de lecture:
- Soupes modèles: la moyenne des poids de plusieurs modèles affinés améliore la précision sans augmenter le temps d'inférence
- Modification des modèles avec arithmétique de la tâche
- Fusionner les modèles de gros langues avec Mergekit
Plus d'articles sur la fusion de modèles peuvent être trouvés ici
Génération efficace
L'accélération du décodage des LLM est cruciale pour améliorer la vitesse et l'efficacité d'inférence, en particulier dans les applications en temps réel ou sensibles à la latence. Voici quelques travaux représentatifs pour accélérer le processus de décodage des LLMS:
- DEJA VU: Crateaux contextuels pour les LLM efficaces au moment de l'inférence (ICML 2023 oral)
- LLMLINGUA: compression des invites à l'inférence accélérée des modèles de gros langues (EMNLP 2023)
- Modèles efficaces de langage de streaming avec des puits d'attention
- Speinfer: accélération de la LLM générative servant avec une inférence spéculative et une vérification des arbres à jeton
- MEDUSA: Cadre d'accélération de l'inférence LLM simple avec plusieurs têtes de décodage
- Modèles de grande langue meilleurs et plus rapides via une prédiction multi-token
- Skip de calque: permettant une inférence de sortie précoce et un décodage autonome
Des travaux supplémentaires sur l'accélération du décodage LLM peuvent être trouvés via le lien 1 et le lien 2.
Modification des connaissances
L'édition des connaissances vise à modifier efficacement les comportements LLMS, tels que la réduction des biais et la révision des corrélations apprises. Il comprend de nombreux sujets tels que la localisation des connaissances et le désapprentissage. Le travail représentatif comprend:
- Édition de modèle basée sur la mémoire à grande échelle (ICML 2022)
- Transformateur-Patcher: Une erreur d'une valeur d'un neurone (ICLR 2023)
- Édition massive pour un modèle de grande langue via Meta Learning (ICLR 2024)
- Un cadre unifié pour l'édition de modèle
- Les couches d'alimentation transformateur sont des souvenirs de valeur clé (EMNLP 2021)
- Mémoire d'édition de masse dans un transformateur
Plus de papiers peuvent être trouvés ici.
Agents alimentés par LLM
En recevant une formation massive, LLMS digère les connaissances du monde et est capable de suivre précisément les instructions d'entrée. Avec ces capacités incroyables, les LLM peuvent jouer en tant qu'agents qui sont possibles à résoudre de manière autonome (et collaborative) des tâches complexes ou simuler les interactions humaines. Voici quelques articles représentatifs des agents LLM:
- Agents génératifs: Simulacra interactive du comportement humain (UIST 2023) [LLMS simule la société humaine dans les jeux vidéo]
- Sotopia: Évaluation interactive de l'intelligence sociale dans les agents linguistiques (ICLR 2024) [LLMS simule les interactions sociales]
- Voyager: un agent incarné à extrémité ouverte avec de grands modèles de langue [LLMS vivent dans le monde Minecraft]
- Les grands modèles de langue en tant que fabricants d'outils (ICLR 2024) [LLMS créent leurs propres outils réutilisables (par exemple, en fonctions Python) pour la résolution de problèmes]
- Metagpt: Meta Programming for Multi-Agent Collaborative Framework [LLMS en équipe pour le développement de logiciels automatisé]
- Webarena: un environnement Web réaliste pour la création d'agents autonomes (ICLR 2024) [LLMS utilise des applications Web]
- Mobile-env: une plate-forme d'évaluation et une référence pour l'interaction LLM-Gui [LLMS utilisent des applications mobiles]
- HuggingGpt: résoudre des tâches d'IA avec Chatgpt et ses amis dans un visage étreint (Nerips 2023) [LLMS cherche des modèles en étreinte pour la résolution de problèmes]
- AgentGyM: évoluer d'agents basés sur un modèle de langue importants dans divers environnements [divers environnements interactifs et tâches pour les agents basés sur LLM]
Une liste complète des articles, des plateformes et des outils d'évaluation peut être trouvée ici.
Résultats
- Votre transformateur est secrètement linéaire
- Toutes les fonctionnalités du modèle de langue ne sont pas linéaires
- KAN ou MLP: une comparaison plus juste
- Transformateur se couche comme des peintres
- Les modèles de langue de vision sont aveugles
Défis ouverts
Les LLM sont confrontées à plusieurs défis ouverts que les chercheurs et les développeurs travaillent activement à relever. Ces défis incluent:
- Hallucination
- Une étude complète des techniques d'atténuation des hallucinations dans les modèles de grande langue
- Compression du modèle
- Une étude complète des algorithmes de compression pour les modèles de langue
- Évaluation
- Évaluation des modèles de grandes langues: une enquête complète
- Raisonnement
- Une enquête sur le raisonnement avec les modèles de fondation
- Explicabilité
- De la compréhension à l'utilisation: une enquête sur l'explication des modèles de grande langue
- Justice
- Une enquête sur l'équité dans les modèles de grande langue
- Factualité
- Une enquête sur la factualité dans les modèles de grande langue: connaissances, récupération et spécificité du domaine
- Intégration des connaissances
- Tendances dans l'intégration des connaissances et des modèles de grandes langues: une enquête et une taxonomie des méthodes, des références et des applications
Une liste complète peut être trouvée ici.
Modèles de diffusion
Les modèles de diffusion visent à environ la distribution de probabilité d'un domaine de données donné et à fournir un moyen de générer des échantillons à partir de sa distribution approximée. Leurs objectifs sont similaires à d'autres modèles génératifs populaires, tels que VAE, GANS et les flux de normalisation.
Le flux de travail de modèles de diffusion est présenté avec deux processus:
- Processus avant (processus de diffusion): il applique progressivement le bruit aux données d'entrée d'origine étape par étape jusqu'à ce que les données deviennent complètement le bruit.
- Processus inverse (processus de débraillé): un modèle NN (par exemple, CNN ou Tranformer) est formé pour estimer le bruit appliqué à chaque étape pendant le processus avant. Ce modèle NN formé peut ensuite être utilisé pour générer des données à partir de l'entrée de bruit. Les modèles de diffusion existants peuvent également accepter d'autres signaux (par exemple, les invites de texte des utilisateurs) pour conditionner la génération de données.
Consultez ce blog génial et des tutoriels d'introduction plus possibles peuvent être trouvés ici. Les modèles de diffusion peuvent être utilisés pour générer des images, des audios, des vidéos et plus encore, et il existe de nombreux sous-champs liés aux modèles de diffusion comme indiqué ci-dessous [Source de l'image]:
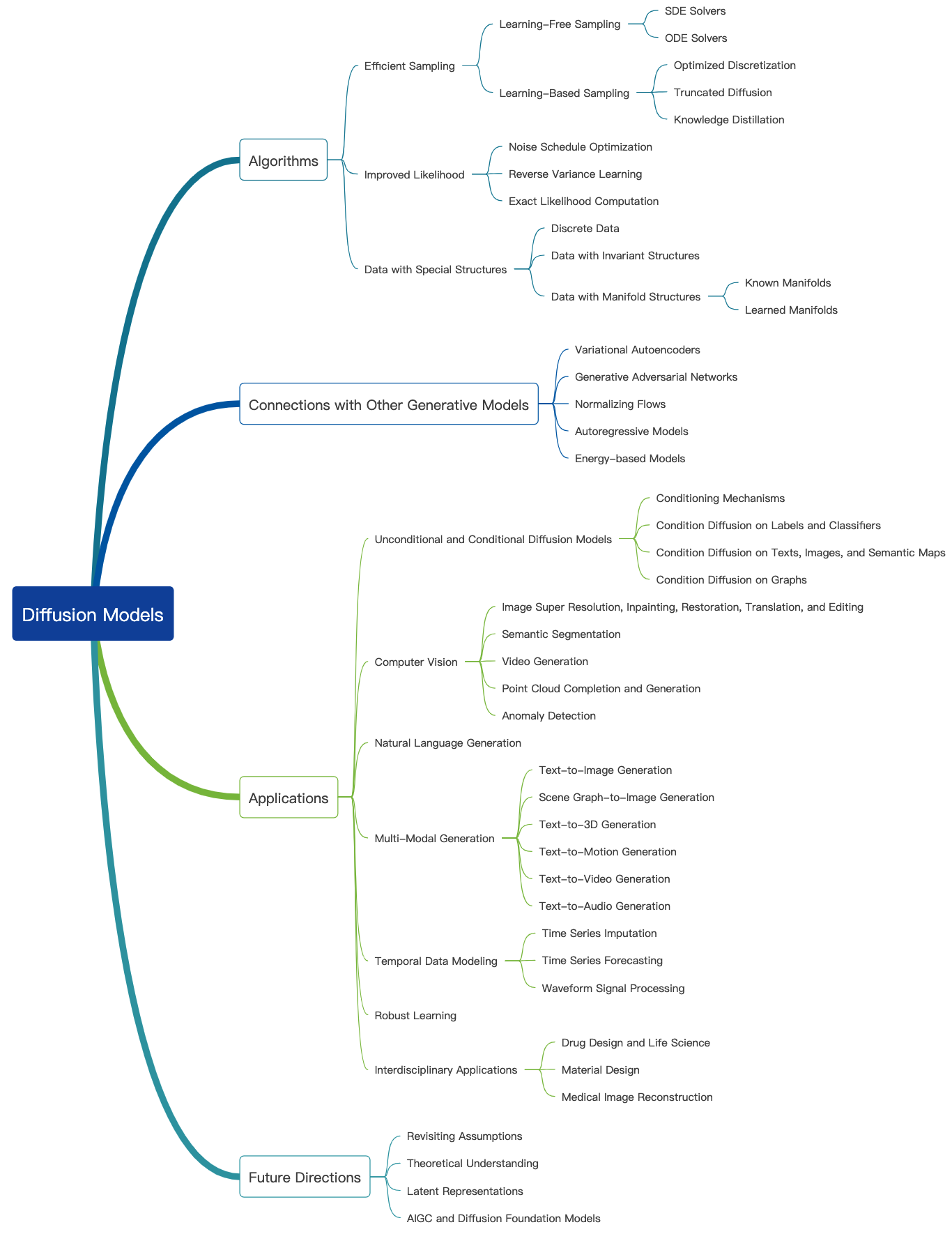
Génération d'images
Voici quelques articles représentatifs de modèles de diffusion pour la génération d'images:
- Synthèse d'image à haute résolution avec des modèles de diffusion latente (CVPR 2022)
- Palette: Modèles de diffusion d'image à image (Siggraph 2022)
- Super-résolution d'image par raffinement itératif
- Intégralité de l'utilisation de modèles probabilistes de diffusion de dénoçage (CVPR 2022)
- Ajout d'un contrôle conditionnel aux modèles de diffusion de texte à l'image (ICCV 2023)
Plus de papiers peuvent être trouvés ici.
Génération de vidéos
Voici quelques articles représentatifs de modèles de diffusion pour la génération de vidéos:
- Modèles de diffusion vidéo
- Modélisation de diffusion flexible des longues vidéos (Neirips 2022)
- Échelle des modèles de diffusion vidéo latente à de grands ensembles de données
- I2VGEN-XL: Synthèse d'image à vidéo de haute qualité via des modèles de diffusion en cascade
Plus de papiers peuvent être trouvés ici.
Génération audio
Voici quelques articles représentatifs de modèles de diffusion pour la génération audio:
- Grad-TTS: un modèle probabiliste de diffusion pour le texte-parole
- Génération de texte à audio à l'aide de LLM et de modèle de diffusion latente réglées par instruction
- Conditionnement vocal zéro-tir pour les modèles TTS de diffusion de débrassement
- Editts: Édition basée sur les scores pour un texte vocable contrôlable
- Prodiff: modèle de diffusion rapide progressive pour le texte vock de haute qualité
Plus de papiers peuvent être trouvés ici.
Pré-entraînement et finetun
Semblable à d'autres grands modèles génératifs, les modèles de diffusion sont également pré-étendus sur une grande quantité de données Web (par exemple, ensemble de données LAION-5B) et consomment des ressources informatiques massives. Les utilisateurs peuvent télécharger les poids publiés peuvent affiner davantage le modèle sur les ensembles de données personnels.
Voici quelques articles représentatifs de réglage fin efficace des modèles de diffusion:
- Dreambooth: Modèles de diffusion de texte à l'image à réglage fin pour la génération axée sur le sujet (CVPR 2023)
- Une image vaut un mot: personnaliser la génération de texte à l'image en utilisant l'inversion textuelle (ICLR 2023)
- Diffusion personnalisée: personnalisation multi-concept de la diffusion du texte à l'image (CVPR 2023)
- Contrôle de la diffusion du texte à l'image par des finetuning orthogonaux (Neirips 2023)
Plus de papiers peuvent être trouvés ici.
Il est fortement recommandé de faire une certaine pratique avec l'API des diffuseurs HuggingFace.
Évaluation
Nous parlons ici de l'évaluation des modèles de diffusion pour la génération d'images. De nombreuses mesures de qualité d'image existantes peuvent être appliquées.
- Score de clip: le score de clip mesure la compatibilité des paires d'images. Les scores de clip plus élevés impliquent une compatibilité plus élevée. Le score de clip s'est avéré avoir une corrélation élevée avec le jugement humain.
- FRÉCHET INCECTION Distance (FID): FID vise à mesurer à quel point les deux ensembles de données d'images sont similaires. Il est calculé en calculant la distance Fréchet entre deux Gaussiens adaptés à des représentations du réseau de création
- Clip Directionnel de similitude: il mesure la cohérence du changement entre les deux images (dans l'espace clip) avec le changement entre les deux légendes d'image.
Plus de métriques de qualité d'image et d'outils de calcul peuvent être trouvés ici.
Génération efficace
Les modèles de diffusion nécessitent plusieurs étapes avant pour générer des données, ce qui est coûteux. Voici quelques articles représentatifs de modèles de diffusion pour une génération efficace:
- Je dois aller vite lors de la génération de données avec des modèles basés sur les scores
- Échantillonnage rapide des modèles de diffusion avec intégrateur exponentiel
- Apprendre des échantillonneurs rapides pour les modèles de diffusion en différenciant la qualité de l'échantillon
- Accélération des modèles de diffusion via un arrêt précoce du processus de diffusion
Plus de papiers peuvent être trouvés ici.
Modification des connaissances
Voici quelques articles représentatifs de l'édition des connaissances pour les modèles de diffusion:
- Effacer les concepts des modèles de diffusion (ICCV 2023)
- Édition de concepts massifs dans les modèles de diffusion de texte à l'image
- Oublier-moi: apprendre à oublier dans les modèles de diffusion texto-image
Plus de papiers peuvent être trouvés ici.
Défis ouverts
Voici quelques documents d'enquête parlant des défis auxquels sont confrontés les modèles de diffusion.
- Une étude des modèles de génération d'images basés sur la diffusion
- Une enquête sur les modèles de diffusion vidéo
- Modèles de diffusion de pointe sur l'informatique visuelle
- Modèles de diffusion dans la PNL: une enquête
Grands modèles multimodaux (LMM)
Les LMM typiques sont construites en connectant et en réglant des modèles unimodaux pré-éradés existants. Certains sont également pré-entraînés à partir de zéro. Vérifiez comment les LMM évoluent dans l'image ci-dessous [source d'image].
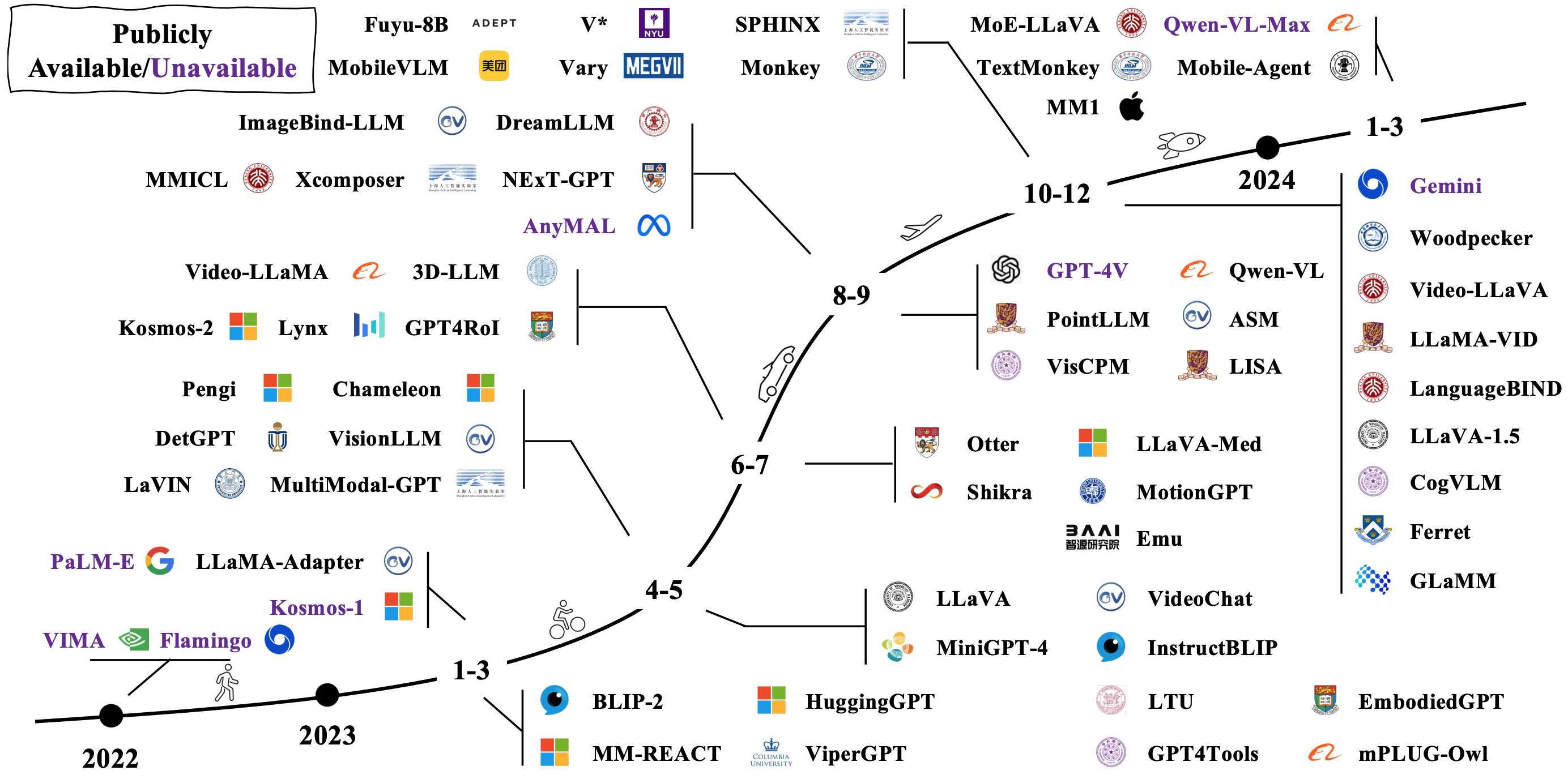
Architectures de modèle
Il existe de nombreuses façons différentes de contraindre les LMM. Les architectures représentatives comprennent:
- Les modèles de langue sont des interfaces à usage général
- Flamingo: un modèle de langage visuel pour l'apprentissage à quelques coups (Neirips 2022)
- BLIP: Bootstrap-Image-Image pré-formation pour la compréhension et la génération unifiées de la vision (ICML 2022)
- Blip-2: Bootstrapage-image-image pré-formation avec des encodeurs d'images congelés et des modèles de grands langues (ICML 2023)
- Mplug-Owl2: Révolution du modèle de grande langue multimodal avec collaboration de modalité
- Florence-2: Faire avancer une représentation unifiée pour une variété de tâches de vision
- Connecteur dense pour MLLMS
Plus de documents peuvent être trouvés via le lien 1 et le lien 2.
Vers des agents incarnés
En combinant les LMM avec des robots, les chercheurs visent à développer des systèmes d'IA qui peuvent percevoir, raisonner et agir sur le monde d'une manière plus naturelle et intuitive, avec des applications potentielles couvrant la robotique, les assistants virtuels, les véhicules autonomes et au-delà. Voici quelques travaux représentatifs de réalisation de l'IA incarnée avec LMMS:
- RT-1: Transformateur robotique pour le contrôle du monde réel à grande échelle
- RT-2: Les modèles d'action visuelle-action transfèrent les connaissances Web vers un contrôle robotique
- RT-H: Hiérarchies d'action utilisant la langue
- Palm-E: un modèle de langue multimodale incarnée
- Transic: transfert de stratégie SIM à réaliser en apprenant à partir de la correction en ligne
Plus de documents peuvent être trouvés via le lien 1 et le lien 2.
Voici quelques simulateurs et ensembles de données populaires pour évaluer les performances de LMMS pour une IA incarnée:
- Habitat 3.0: une plate-forme de simulation IA incarnée pour étudier les tâches collaboratives d'interaction humaine-robot dans les environnements domestiques
- Prosthor-10k: 10k Environnements ménagers interactifs pour l'IA incarnée
- Arnold: une référence pour l'apprentissage des tâches à la langue avec des états continus dans des scènes 3D réalistes
- Légende: plate-forme ouverte pour les agents incarnés
- Robocase: Simulation à grande échelle des tâches quotidiennes pour les robots généralistes
Plus de ressources peuvent être trouvées ici.
Défis ouverts
Voici quelques documents d'enquête parlant de défis ouverts pour l'IA incarnée par LMM:
- La montée et le potentiel des agents basés sur un modèle de langue grande: une enquête
- Navigation de la vision avec une intelligence incarnée: une enquête
- Une étude de l'IA incarnée: des simulateurs aux tâches de recherche
- Une enquête sur les agents autonomes basés sur LLM
- Mindstorms dans les sociétés d'esprit basées sur le langage naturel
Au-delà des transformateurs
Les chercheurs essaient d'explorer de nouveaux modèles autres que les transformateurs. Les efforts comprennent implicitement implicitement les paramètres du modèle et la définition de nouvelles architectures de modèle.
Paramètres structurés implicitement
- Mixer Monarch: Revisiter Bert, sans attention ou MLPS
- Mamba: modélisation de séquences linéaires avec des espaces d'état sélectifs
Nouvelles architectures de modèle
- Hiérarchie de l'hyène: vers des modèles de langage convolutionnel plus larges
- RWKV: Réinventer des RNN pour l'ère du transformateur
- Réseau de rétention: un successeur du transformateur pour les modèles de grande langue
- Mamba: modélisation de séquences linéaires avec des espaces d'état sélectifs
- Kan: réseaux Kolmogorov - Arnold
- Les transformateurs sont SSM
Voici un didacticiel génial pour les modèles d'espace d'État.


