 Generative AI Roadmap
Generative AI Roadmap
Ein subjektiver Lernhandbuch für generative KI -Forschung, einschließlich kuratierter Liste von Artikeln und Projekten
Generative AI ist heute ein heißes Thema, und diese Roadmap soll Anfängern helfen, schnell Grundkenntnisse zu erlangen und nützliche Ressourcen für generative KI zu finden. Sogar Experten können sich gerne auf diese Roadmap beziehen, um alte Kenntnisse zu erinnern und neue Ideen zu entwickeln.
Inhaltstabelle
- Hintergrundwissen
- Neuralnetzwerke Inferenz und Schulung
- Transformatorarchitektur
- Häufige transformatorbasierte Modelle
- Verschiedenes
- Großspracher Modelle (LLMs)
- Vorab- und Feinabstimmung
- Aufforderung
- Auswertung
- Umgang mit langem Kontext
- Effiziente Feinabstimmung
- Modellverführung
- Effiziente Generation
- Wissensbearbeitung
- LLM-Betroffene
- Ergebnisse
- Offene Herausforderungen
- Diffusionsmodelle
- Bildgenerierung
- Videogenerierung
- Audiogeneration
- Vorab- und Feinabstimmung
- Auswertung
- Effiziente Generation
- Wissensbearbeitung
- Offene Herausforderungen
- Große multimodale Modelle (LMMs)
- Modellarchitekturen
- Auf verkörperte Agenten
- Offene Herausforderungen
- Jenseits von Transformatoren
- Implizit strukturierte Parameter
- Neue Modellarchitekturen
Hintergrundwissen
Dieser Abschnitt soll Ihnen dabei helfen, das Grundkenntnis der neuronalen Netze (z. B. Backpropagation) zu lernen oder zurückzugewinnen, Sie mit der Transformatorarchitektur vertraut zu machen und einige gemeinsame Transformator-basierte Modelle zu beschreiben.
Neuralnetzwerke Inferenz und Schulung
Kennen Sie die folgenden klassischen neuronalen Netzwerkstrukturen sehr?
- Multi-Layer-Perzeptron (MLP)
- Faltungsnetzwerk (CNN)
- Wiederkehrendes neuronales Netzwerk (RNN)
In diesem Fall sollten Sie in der Lage sein, diese Fragen zu beantworten:
- Warum funktionieren CNNs besser als MLPs auf Bildern?
- Warum funktionieren RNNs besser als MLPs in Zeitreihen Daten?
- Was ist der Unterschied zwischen Gru und LSTM?
Backpropagation (BP) ist die Basis des NN -Trainings. Sie werden kein KI -Experte sein, wenn Sie BP nicht verstehen . Es gibt viele Lehrbücher und Online -Tutorials, die BP lehren, aber leider präsentieren die meisten keine Formeln in vektorisierten/geprägten Formen. Die BP -Formel einer NN -Schicht ist in der Tat so ordentlich wie ihre Vorwärtspassformel. Genau so wird BP implementiert und sollte implementiert werden. Um BP zu verstehen, lesen Sie bitte die folgenden Materialien:
- Neuronale Netze und tiefes Lernen [Kapitel 3.2, insbesondere 3.2.6]
- MEPROP: Sparifizierte Rückverbreitung für beschleunigtes Deep -Lernen mit reduzierter Überanpassung (ICML 2017) [Abschnitt 2.1]
- RESPROP: Sparifizierte Rückpropagation wiederverwenden (CVPR 2020) [Abschnitt 3.1]
Wenn Sie BP verstehen, sollten Sie in der Lage sein, diese Fragen zu beantworten:
- Wie werden Sie den Blutdruck einer Faltungsschicht beschreiben?
- Wie ist das Verhältnis der Rechenkosten (dh Anzahl der schwimmenden Punktvorgänge) zwischen dem Vorwärtspass und dem Rückwärtspass einer dichten Schicht?
- Wie werden Sie den Blutdruck eines MLP mit zwei dichten Schichten beschreiben, die die gleiche Gewichtsmatrix teilen?
Transformatorarchitektur
Transformator ist die Basisarchitektur vorhandener großer generativer Modelle. Es ist notwendig, jede Komponente im Transformator zu verstehen. Bitte lesen Sie die folgenden Materialien:
- Achtung ist alles, was Sie brauchen (Neurips 2017) [Originalpapier]
- Transformator Erklärer: Interaktives Lernen von Text-generativen Modellen [ein interaktives Tutorial]
- Ein Bild ist 16x16 Wörter wert: Transformatoren für die Bilderkennung im Maßstab (ICLR 2021) [Vision Transformator]
- Neuronale maschinelle Übersetzung mit einem Transformator und Keras [großartige Erklärung für Multihead -Aufmerksamkeit (MHA)]
- Flops eines Transformatorblocks [Üben Sie üben, Flops zu berechnen]
- Schnelltransformator Decodierung: Ein Schreibkopf ist alles, was Sie brauchen [Multiquery Achtung (MQA)]
- GQA: Schulungsverallgemeinerung verallgemeinerter Multiquery-Transformatormodelle von mehrköpfigen Kontrollpunkten [Aufmerksamkeitsgeschäfte (gruppy-query acht (gQA)]]
- Verbesserter Transformator mit der Einbettung der Rotationsposition [Positionseinbettung verstehen]
- Rotary -Einbettungen: Eine relative Revolution [Verstehe Positionseinbettung]
- Lehrerzweck gegen geplante Probenahme im Vergleich zum normalen Modus [Lehrerantrieb in der Transformatorausbildung]
- FlexGen: Hochdurchsatz generative Inferenz von Großsprachenmodellen mit einer einzelnen GPU [siehe Abschnitt 3 - Generative Inferenz, um zu erfahren, wie LLMs die Peform -Erzeugung basierend auf KV Cache]
- Kontextpositionskodierung: Lernen, zu zählen, was wichtig ist [kontextabhängige Positionscodierung]
Wenn Sie Transformers verstehen, sollten Sie in der Lage sein, diese Fragen zu beantworten:
- Was sind die Vor- und Nachteile von Tranformern im Vergleich zu RNNs? (gleichzeitig anwesend, Schulung der Parallelität, Komplexität)
- Können Sie die Flops von GQA kakulieren? Sehen Sie, wann sich auf MHA und MQA verschlechtert?
- Was ist die Motivation von MQA und GQA?
- Wie sieht die kausale Aufmerksamkeitsmaske aus und warum?
- Wie werden Sie das Training von Decodierer-Transformatoren Schritt für Schritt beschreiben?
- Warum ist Seil besser als sinusförmige Positionscodierung?
Häufige transformatorbasierte Modelle
- Lernen übertragbarer visueller Modelle aus natürlicher Sprachüberwachung [Clip]
- Aufstrebende Eigenschaften in selbst beträchtlichen Sehtransformatoren (ICCV 2021) [DINO]
- Maskierte Autoencoder sind skalierbare Sehlerner (CVPR 2022) [MAE]
- Skalierungsvision mit spärlicher Mischung aus Experten (Neurips 2021) [MOE]
- Tiefenmischung: Dynamisch Berechnung in transformatorbasierten Sprachmodellen [MOD] dynamisch zuweisen
Verschiedenes
Einsum ist einfach und nützlich [ein großartiges Tutorial für die Verwendung von Einsum/Einops]
Open-Endness ist für die künstliche übermenschliche Intelligenz (ICML 2024) von wesentlicher Bedeutung [Gedanken über die Erreichung der übermenschlichen AI]
AGI -Niveaus zur Operationalisierung des Fortschritts auf dem Weg zur AGI
Großspracher Modelle (LLMs)
LLMs sind Transformatoren. Sie können nur in Encoder-, Encoder-Decoder- und Decoder-Architekturen eingeteilt werden, wie im LLM Evolutionary Tree unten [Bildquelle] gezeigt. Überprüfen Sie die Meilensteinpapiere von LLMs.
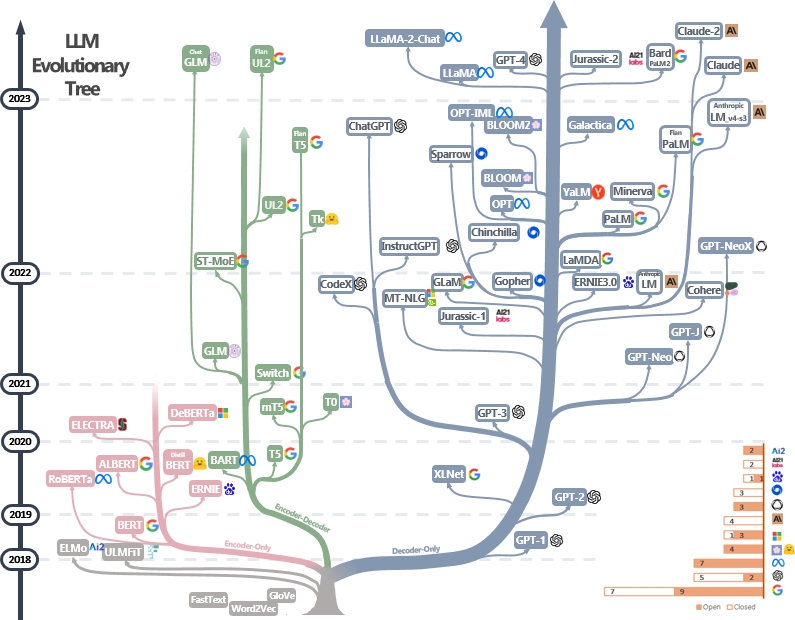
Nur-Encoder-Modell kann verwendet werden, um Satzmerkmale zu extrahieren, aber es fehlt eine generative Leistung. Für die Textgenerierung werden Encoder-Decoder- und Decoder-Modelle verwendet. Insbesondere bevorzugen die meisten vorhandenen LLMs aufgrund einer stärkeren Repesentationskraft nur Decoder-Strukturen. Intuitiv können Encoder-Decoder-Modelle als spärliche Version von Decoder-Modellen angesehen werden, und die Informationen zerfallen mehr von Encoder zu Decoder. Weitere Informationen finden Sie in diesem Artikel.
Vorab- und Finetuning
LLMs werden typischerweise von Modellverlagern aus Billionen Texttoken vorgelegt, um die natürliche Sprachstruktur zu verinnerlichen. Die heutigen Modellentwickler führen auch das Lernen für Feinabstimmungen und Verstärkung durch menschliches Feedback (RLHF) durch, um das Modell zu lehren, menschliche Anweisungen zu befolgen und Antworten zu generieren, die mit menschlichen Vorlieben ausgerichtet sind. Die Benutzer können dann das veröffentlichte Modell herunterladen und es auf kleinen persönlichen Datensätzen (z. B. Filmdialog) beenden. Aufgrund der enormen Datenmenge erfordert die Voranwälte massive Rechenressourcen (z. B. mehr als Tausende von GPUs), was von Einzelpersonen unerschwinglich ist. Auf der anderen Seite ist die Feinabstimmung weniger ressourcenhungry und kann mit ein paar GPUs durchgeführt werden.
Die folgenden Materialien können Ihnen helfen, den Vor- und Feinabstimmungsvorgang zu verstehen:
- Bert: Vorausbildung von tiefen bidirektionalen Transformatoren für das Sprachverständnis [Vorab- und Finetuning von LLMs nur für Encoder]
- Skalierungsunterrichts-Finetuned-Sprachmodelle [Vorab- und Unterrichtsfonetuning]
- Illustrieren des Verstärkungslernens durch menschliches Feedback (RLHF)
- Sprachmodelle sind nur wenige Schusslernende [Nur Decoder-LLMs] [中文导读 von 李沐]
Weitere Tutorials finden Sie hier.
Aufforderung
Das Aufsuchen von Techniken für LLMs beinhaltet das Erstellen von Eingabetxt auf eine Weise, die das Modell leitet, um die gewünschten Antworten oder Ausgaben zu generieren. Hier sind die nützlichen Ressourcen, mit denen Sie bessere Eingabeaufforderungen schreiben können:
- [Dair.AI] Schnelltechnischer Leitfaden
- Fantastische ChatGPT -Eingabeaufforderungen - Eine Sammlung von schnellen Beispielen, die mit dem Chatgpt -Modell verwendet werden sollen
- Fantastische Absichtsanforderung - Wie man LLMs bittet, zuverlässige Argumentation zu erstellen und verantwortungsbewusste Entscheidungen zu treffen
- AUTOPROMPT - Eine automatisierte Methode, die auf der durchladientengesteuerten Suche basiert, um Eingabeaufforderungen für eine Vielzahl von NLP -Aufgaben zu erstellen.
Auswertung
Bewertungswerkzeuge für große Sprachmodelle helfen dabei, ihre Leistung, Funktionen und Einschränkungen für verschiedene Aufgaben und Datensätze zu bewerten. Hier sind einige gemeinsame Bewertungsstrategien:
Automatische Bewertungsmetriken : Diese Metriken bewerten die Modellleistung automatisch ohne menschliche Intervention. Gemeinsame Metriken umfassen:
- BLEU: misst die Ähnlichkeit zwischen generiertem Text und Referenztext basierend auf N-Gram-Überlappung.
- Rouge: Bewertet die Textübersicht, indem Sie überlappende N-Gramm zwischen generierten und Referenzzusammenfassungen verglichen.
- Verwirrung: Misst, wie gut ein Sprachmodell eine Textprobe vorhersagt. Eine geringere Verwirrung zeigt eine bessere Leistung an. Es entspricht der Exponentiation der Kreuzentropie zwischen den Daten- und Modellvorhersagen.
- F1 -Punktzahl: misst das Gleichgewicht zwischen Präzision und Rückruf in Aufgaben wie Textklassifizierung oder benannter Entitätserkennung.
Menschliche Bewertung : Das menschliche Urteilsvermögen ist für die umfassende Qualität des generierten Textes unerlässlich. Gemeinsame menschliche Bewertungsmethoden umfassen:
- Menschliche Bewertungen : Humaner Annotatoren bewerten Text, die auf Kriterien wie Fließende, Kohärenz, Relevanz und Grammatikalität basieren.
- Crowdsourcing-Plattformen : Plattformen wie Amazon Mechanical Turk oder Abbildung acht erleichtern die große menschliche Bewertung durch Crowdsourcing-Anmerkungen.
- Expertenbewertung : Domänenexperten bewerten die Modellausgaben, um ihre Eignung für bestimmte Anwendungen oder Aufgaben zu messen.
Benchmark -Datensätze : Standardisierte Datensätze ermöglichen einen fairen Vergleich von Modellen über verschiedene Aufgaben und Domänen hinweg. Beispiele sind:
- Triviaqa: Ein großes, weit entferntes Herausforderungsdatensatz für das Leseverständnis
- Hellaswag: Kann eine Maschine Ihren Satz wirklich beenden?
- GSM8K: Trainingsprüfer zur Lösung mathematischer Wortprobleme
- Eine vollständige Liste finden Sie hier
Modellanalysetools: Zu den Tools zur Analyse des Modellverhaltens und der Leistung gehören:
- Automatisierte Interpretierbarkeit - Code zum automatischen Generieren, Simulieren und Bewerten von Erklärungen für das Neuronverhalten
- LLM -Visualisierung - Visualisierung von LLMs auf niedrigem Niveau.
- Aufmerksamkeitsanalyse - Analyse der Aufmerksamkeitskarten aus Bert -Transformator.
- Neuron Viewer - Werkzeug zum Betrachten von Aktivierungen und Erklärungen von Neuronen.
Eine vollständige Liste finden Sie hier
Zu den Standardbewertungsrahmen für vorhandene LLMs gehören:
- LM-Evaluation-HARTNESS-Ein Rahmen für die Bewertung von Sprachmodellen für wenige Schüsse.
- LightVal - Eine leichte LLM -Bewertungssuite, die das Umarmungsgesicht intern verwendet hat.
- Olmo -Eval - Ein Repository zur Bewertung offener Sprachmodelle.
- BESTUCT-EVAL-Dieses Repository enthält Code, um die mit Alpaka und FLAN-T5 bei gehaltenen Aufgaben abgestimmten Anweisungsmodellen quantitativ zu bewerten.
Umgang mit langem Kontext
Der Umgang mit langen Kontexten stellt aufgrund von Einschränkungen in Bezug auf Gedächtnis und Verarbeitungskapazität eine Herausforderung für große Sprachmodelle dar. Bestehende Techniken umfassen:
- Effiziente Transformatoren
- Longformer: Der Langdokumentwandler
- Reformer: Der effiziente Transformator (ICLR 2020)
- Zustandsraummodelle
- Transformatoren sind RNNs: schnelle autoregressive Transformatoren mit linearer Aufmerksamkeit (ICML 2020)
- Aufmerksamkeit mit Darstellern überdenken
- Länge Extrapolation
- Mamba: Modellierung der linearen Zeitsequenz mit selektiven Zustandsräumen
- ROFORMER: Verbesserter Transformator mit der Einbettung von Rotary Position
- Garn: Effiziente Kontextfenstererweiterung großer Sprachmodelle
- Langzeitspeicher
- MemoryBank: Verbesserung großer Sprachmodelle mit Langzeitgedächtnis
- Entfesselung der Eingangskapazität von Infinitenlängen für großräumige Sprachmodelle mit selbstkontrolliertem Speichersystem
Eine vollständige Liste finden Sie hier
Effiziente Finetuning
PEFT-Methoden (Parametereffiziente Fine-Tuning) ermöglichen eine effiziente Anpassung großer vorbereiteter Modelle an verschiedene nachgeschaltete Anwendungen, indem nur eine kleine Anzahl von (zusätzlichen) Modellparametern anstelle aller Parameter des Modells fein:
- Schnellstimmung: Die Skalierungsleistung für parametereffiziente Eingabeaufforderung zum Einschalten
- Präfix-Tuning: Präfix-Tuning: Optimieren Sie kontinuierliche Eingabeaufforderungen für die Generation
- LORA: LORA: Niedrige Anpassung von Großsprachmodellen
- Auf eine einheitliche Ansicht des parametereffizienten Transferlernens
- Lora lernt weniger und vergisst weniger
Weitere Arbeiten finden Sie in der Sammlung von Peft -Papierpapierpapier und werden dringend empfohlen, mit Huggingface Peft -API zu üben.
Modellverführung
Das Modellverführen bezieht sich auf das Zusammenführen von zwei oder mehr LLMs, die auf verschiedenen Aufgaben in ein einzelnes LLM trainiert wurden. Diese Technik zielt darauf ab, die Stärken und das Wissen verschiedener Modelle zu nutzen, um ein robusteres und fähigeres Modell zu schaffen. Beispielsweise kann ein LLM für die Codegenerierung und ein weiteres LLM für die Lösung von Mathematik -Prolemen zusammengeführt werden, sodass das fusionierte Modell sowohl die Codegenerierung als auch die Mathematik -Problemlösung durchführen kann.
Die Modellverführung ist faszinierend, da sie mit sehr einfachen und billigen Algorithmen (z. B. lineare Kombination von Modellgewichten) effektiv erreicht werden kann. Hier sind einige repräsentative Papiere und Lesematerialien:
- Modellsuppen: Die Mittelung von Gewichten mehrerer fein abgestimmter Modelle verbessert die Genauigkeit, ohne die Inferenzzeit zu erhöhen
- Bearbeitungsmodelle mit Aufgabenarithmetik
- Mergekit großer Sprachmodelle zusammenführen
Weitere Arbeiten über das Modellverführen finden Sie hier
Effiziente Generation
Die Beschleunigung der Dekodierung von LLMs ist entscheidend für die Verbesserung der Inferenzgeschwindigkeit und -effizienz, insbesondere in Echtzeit- oder Latenz-sensitiven Anwendungen. Hier sind einige repräsentative Arbeiten, um den Dekodierungsprozess von LLMs zu beschleunigen:
- Deja Vu: Kontextsparsity für effiziente LLMs zu Inferenzzeiten (ICML 2023 oral)
- Llmlingua: Komprimieren von Eingabeaufforderungen für beschleunigte Inferenz großer Sprachmodelle (EMNLP 2023)
- Effiziente Streaming -Sprachmodelle mit Aufmerksamkeits sinken
- Specinfer: Beschleunigen generative LLM, die mit spekulativen Inferenz- und Tokenbaumverifizierung dient
- Medusa: Einfache LLM -Inferenzbeschleunigungs -Framework mit mehreren Dekodierungsköpfen
- Bessere und schnellere große Sprachmodelle über mehrfache Vorhersage
- Layer Skip: Aktivieren Sie die frühe Ausstiegsauslegung und selbstspezifische Dekodierung
Weitere Arbeiten zum Beschleunigen von LLM -Dekodierung finden Sie über Link 1 und Link 2.
Wissensbearbeitung
Die Wissensbearbeitung zielt darauf ab, das LLM -Verhalten effizient zu verändern, z. B. die Verringerung der Verzerrung und die Überarbeitung erlernter Korrelationen. Es umfasst viele Themen wie Lokalisierung des Wissens und das Verunehmen. Repräsentative Arbeiten umfassen:
- Speicherbasierte Modellbearbeitung im Maßstab (ICML 2022)
- Transformator-Patcher: Ein Fehler im Wert von einem Neuron (ICLR 2023)
- Massive Bearbeitung für großes Sprachmodell über Meta -Lernen (ICLR 2024)
- Ein einheitliches Framework für die Modellbearbeitung
- Transformator Feed-Forward-Schichten sind Schlüsselwertgefeiler (EMNLP 2021)
- Massenbearbeitungsgedächtnis in einem Transformator
Hier finden Sie mehr Papiere.
LLM-Betroffene
Durch den Erhalt massiver Schulungen können LLMS -Digest World Wissen genau befolgen. Mit diesen erstaunlichen Funktionen können LLMs als Agenten spielen, die autonom (und gemeinsam) komplexe Aufgaben lösen oder menschliche Interaktionen simulieren können. Hier sind einige repräsentative Arbeiten von LLM -Agenten:
- Generative Agents: Interaktive Simulacra des menschlichen Verhaltens (UIST 2023) [LLMs simuliert die menschliche Gesellschaft in Videospielen]
- Sotopie: Interaktive Bewertung für soziale Intelligenz in Sprachagenten (ICLR 2024) [LLMs simulieren soziale Interaktionen]
- Voyager: Ein offener verkörperter Agent mit großartigen Modellen [LLMs leben in der Minecraft-Welt]
- Großsprachenmodelle als Werkzeughersteller (ICLR 2024) [LLMs erstellen ihre eigenen wiederverwendbaren Werkzeuge (z. B. in Python-Funktionen) zur Problemlösung]
- METAGPT: Meta-Programmierung für Collaborative Framework mit mehreren Agenten [LLMs als Team für automatisierte Softwareentwicklung]
- Webarena: Eine realistische Webumgebung zum Aufbau autonomer Agenten (ICLR 2024) [LLMs verwenden Webanwendungen]
- Mobile-Env: Eine Bewertungsplattform und ein Benchmark für LLM-GUI-Interaktion [LLMs verwenden mobile Anwendungen]
- Hugginggpt: Lösen von KI-Aufgaben mit Chatgpt und seinen Freunden im Umarmungsgesicht (Neurips 2023) [LLMs suchen Modelle in Huggingface zur Problemlösung]
- Agentgymus: Entwicklung von modellbasierten Wirkstoffen in großer Sprache in verschiedenen Umgebungen [verschiedene interaktive Umgebungen und Aufgaben für LLM-basierte Agenten]
Eine vollständige Liste von Arbeiten, Plattformen und Bewertungstools finden Sie hier.
Ergebnisse
- Ihr Transformator ist heimlich linear
- Nicht alle Sprachmodellmerkmale sind linear
- Kan oder MLP: Ein gerechterer Vergleich
- Transformatorschichten als Maler
- Vision -Sprachmodelle sind blind
Offene Herausforderungen
LLMs stehen vor mehreren offenen Herausforderungen, die Forscher und Entwickler aktiv daran arbeiten. Diese Herausforderungen umfassen:
- Halluzination
- Eine umfassende Übersicht über Halluzinationsminderungstechniken in Großsprachenmodellen
- Modellkomprimierung
- Eine umfassende Übersicht über Komprimierungsalgorithmen für Sprachmodelle
- Auswertung
- Bewertung von großsprachigen Modellen: Eine umfassende Umfrage
- Argumentation
- Eine Übersicht über die Argumentation mit Stiftungsmodellen
- Erklärung
- Vom Verständnis zur Nutzung: Eine Umfrage zur Erklärung von Großsprachmodellen
- Fairness
- Eine Umfrage zur Fairness in großen Sprachmodellen
- Tatsache
- Eine Umfrage zur Sachlichkeit in Großsprachenmodellen: Wissen, Abruf und Domänenspezifität
- Wissensintegration
- Trends zur Integration von Wissen und Großsprachmodellen: Eine Umfrage und Taxonomie von Methoden, Benchmarks und Anwendungen
Eine vollständige Liste finden Sie hier.
Diffusionsmodelle
Diffusionsmodelle zielen darauf ab, die Wahrscheinlichkeitsverteilung einer bestimmten Datendomäne zu approximieren und eine Möglichkeit zur Erzeugung von Proben aus seiner ungefähren Verteilung zu bieten. Ihre Ziele ähneln anderen populären generativen Modellen wie Vae, Gans und Normalisierungsströmen.
Der Arbeitsablauf von Diffusionsmodellen wird mit zwei Prozessen vorgestellt:
- Vorwärtsprozess (Diffusionsprozess): Es wird schrittweise die Rauschen schrittweise auf die ursprünglichen Eingangsdaten angewendet, bis die Daten vollständig zu Rauschen werden.
- Reverse Process (Denoising -Prozess): Ein NN -Modell (z. B. CNN oder Tranformator) wird geschult, um das in jedem Schritt während des Vorwärtsprozesses angewendete Rauschen abzuschätzen. Dieses geschulte NN -Modell kann dann verwendet werden, um Daten aus dem Rauscheingang zu generieren. Vorhandene Diffusionsmodelle können auch andere Signale (z. B. Texteingabeaufforderungen von Benutzern) akzeptieren, um die Datenerzeugung zu konditionieren.
Sehen Sie sich diesen großartigen Blog an und weitere Einführungs -Tutorials finden Sie hier. Diffusionsmodelle können verwendet werden, um Bilder, Audios, Videos und mehr zu generieren, und es gibt viele Unterfelder, die sich auf Diffusionsmodelle beziehen, wie unten gezeigt [Bildquelle]:
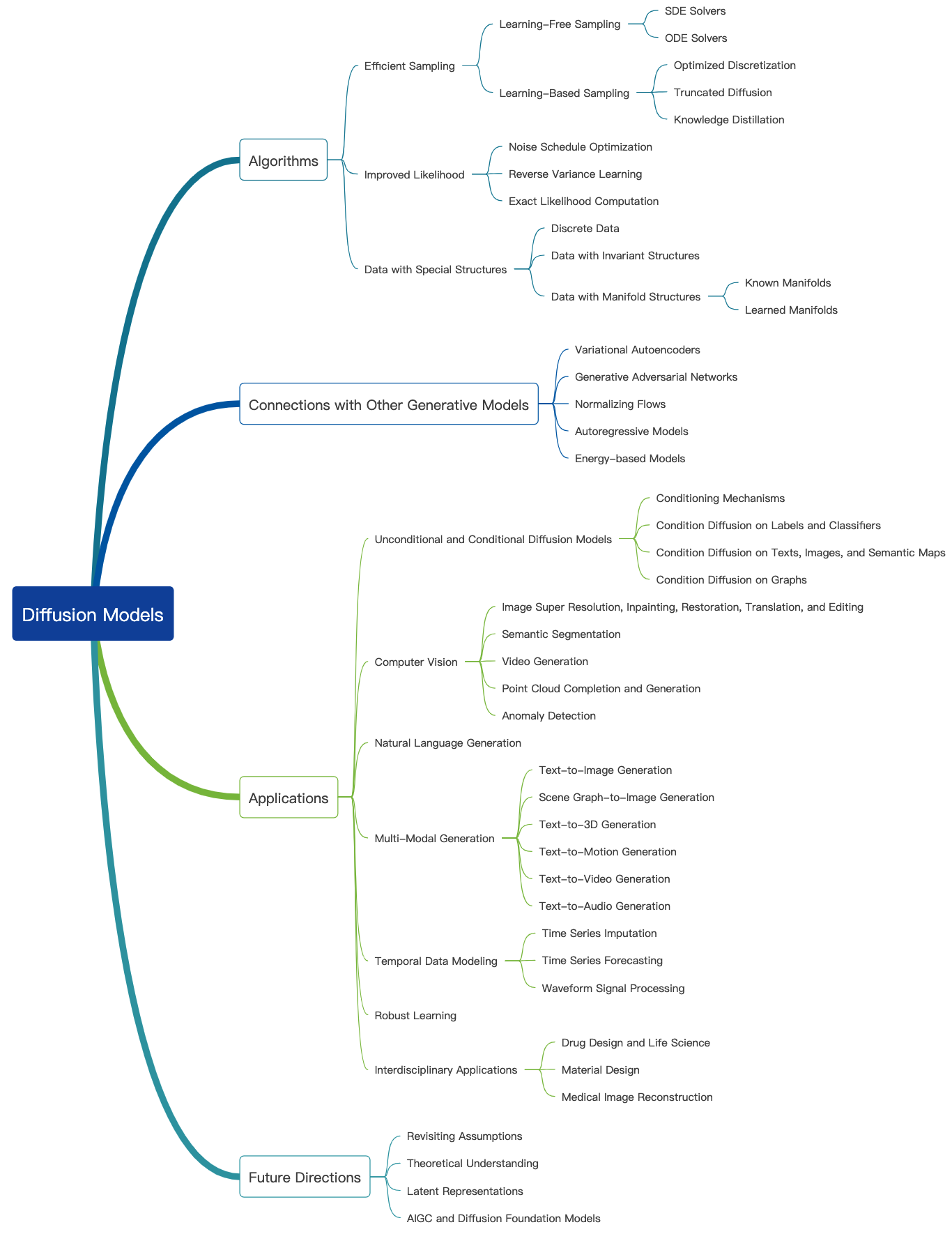
Bildgenerierung
Hier sind einige repräsentative Artikel von Diffusionsmodellen für die Bildgenerierung:
- Hochauflösende Bildsynthese mit latenten Diffusionsmodellen (CVPR 2022)
- Palette: Image-zu-Image-Diffusionsmodelle (Siggraph 2022)
- Bild superauflösung durch iterative Verfeinerung
- Inpainting unter Verwendung der Denoising -Diffusion probabilistischer Modelle (CVPR 2022)
- Hinzufügen einer bedingten Steuerung zu Text-zu-Image-Diffusionsmodellen (ICCV 2023)
Hier finden Sie mehr Papiere.
Videogenerierung
Hier sind einige repräsentative Artikel von Diffusionsmodellen für die Videogenerierung:
- Videodiffusionsmodelle
- Flexible Diffusionsmodellierung langer Videos (Neurips 2022)
- Skalierung latenter Videodiffusionsmodelle zu großen Datensätzen
- I2Vgen-XL: Hochwertige Bild-zu-Video-Synthese über kaskadierte Diffusionsmodelle
Hier finden Sie mehr Papiere.
Audiogeneration
Hier sind einige repräsentative Artikel von Diffusionsmodellen für die Audiogenerierung:
- Grad-TTs: Ein diffusions-probabilistisches Modell für Text-to-Speech
- Text-to-Audio-Generierung unter Verwendung von LLM und Latent-Diffusionsmodell für Anweisungen
- Sprachkonditionierung von Zero-Shot-Konditionierung zur Denoisierung von TTS-Modellen der Diffusion
- EDitts: Score-basierte Bearbeitung für kontrollierbare Text-zu-Sprache
- Prodiff: Progressives schnelles Diffusionsmodell für hochwertige Text-zu-Sprach
Hier finden Sie mehr Papiere.
Vorab- und Finetuning
Ähnlich wie bei anderen großen generativen Modellen werden auch Diffusionsmodelle in einer großen Menge an Webdaten (z. B. Laion-5b-Datensatz) vorgelegt und massive Rechenressourcen konsumieren. Benutzer können die freigegebenen Gewichte herunterladen, die das Modell auf persönlichen Datensätzen weiter abstellen können.
Hier sind einige repräsentative Artikel über eine effiziente Feinabstimmung von Diffusionsmodellen:
- Dreambooth: Feinabstimmungsdiffusionsmodelle für die Subjektbetriebenerzeugung (CVPR 2023)
- Ein Bild ist ein Wort wert: Personalisierung der Text-zu-Image-Generierung mithilfe der Textinversion (ICLR 2023)
- Benutzerdefinierte Diffusion: Multi-Konzept-Anpassung der Text-zu-Image-Diffusion (CVPR 2023)
- Kontrolle der Text-zu-Im-Image-Diffusion durch orthogonale Finetuning (Neurips 2023)
Hier finden Sie mehr Papiere.
Es wird dringend empfohlen, mit Huggingface -Diffusors -API zu üben.
Auswertung
Hier sprechen wir über die Bewertung von Diffusionsmodellen für die Bilderzeugung. Viele vorhandene Kennzahlen zur Bildqualität können angewendet werden.
- Clip-Score: Die Clip-Score misst die Kompatibilität von Bildkaptionspaaren. Höhere Clip -Scores bedeuten eine höhere Kompatibilität. Es wurde festgestellt, dass die Clip -Score eine hohe Korrelation mit dem menschlichen Urteilsvermögen aufweist.
- Fréchet Inception Distanz (FID): FID zielt darauf ab, zu messen, wie ähnlich zwei Datensätze sind. Es wird berechnet, indem der Fréchet -Abstand zwischen zwei Gaußern berechnet wird, die dazu geeignet sind, Darstellungen des Inception -Netzwerks zu finden
- Clip Directional -Ähnlichkeit: Es misst die Konsistenz der Änderung zwischen den beiden Bildern (im Clip -Raum) mit der Änderung zwischen den beiden Bildunterschriften.
Weitere Bildqualitätsmetriken und Berechnungswerkzeuge finden Sie hier.
Effiziente Generation
Diffusionsmodelle erfordern mehrere Vorwärtsschritte, um Daten zu generieren, was teuer ist. Hier sind einige repräsentative Artikel von Diffusionsmodellen für die effiziente Generation:
- Ich muss schnell gehen, wenn ich Daten mit bewertungsbasierten Modellen generiere
- Schnelle Abtastung von Diffusionsmodellen mit Exponentialintegrator
- Lernen schneller Sampler für Diffusionsmodelle durch Differenzierung durch Probenqualität
- Beschleunigung der Diffusionsmodelle durch einen frühen Stopp des Diffusionsprozesses
Hier finden Sie mehr Papiere.
Wissensbearbeitung
Hier sind einige repräsentative Arbeiten der Wissensbearbeitung für Diffusionsmodelle:
- Löschen von Konzepten aus Diffusionsmodellen (ICCV 2023)
- Bearbeitung massiver Konzepte in Text-zu-Image-Diffusionsmodellen
- Vergiss-me-nicht: Lernen, in Text-zu-Image-Diffusionsmodellen zu vergessen,
Hier finden Sie mehr Papiere.
Offene Herausforderungen
Hier sind einige Umfragepapiere über die Herausforderungen, denen sich Diffusionsmodelle gegenübersehen.
- Eine Übersicht über diffusionsbasierte Bildgenerierungsmodelle
- Eine Umfrage zu Videodiffusionsmodellen
- Stand der Technik zu Diffusionsmodellen für visuelles Computing
- Diffusionsmodelle in NLP: Eine Umfrage
Große multimodale Modelle (LMMs)
Typische LMMs werden konstruiert, indem vorhandene unimodale Modelle angeschlossen und fein abtroffen werden. Einige werden auch von Grund auf neu vorgezogen. Überprüfen Sie, wie sich LMMs im Bild unten entwickeln [Bildquelle].
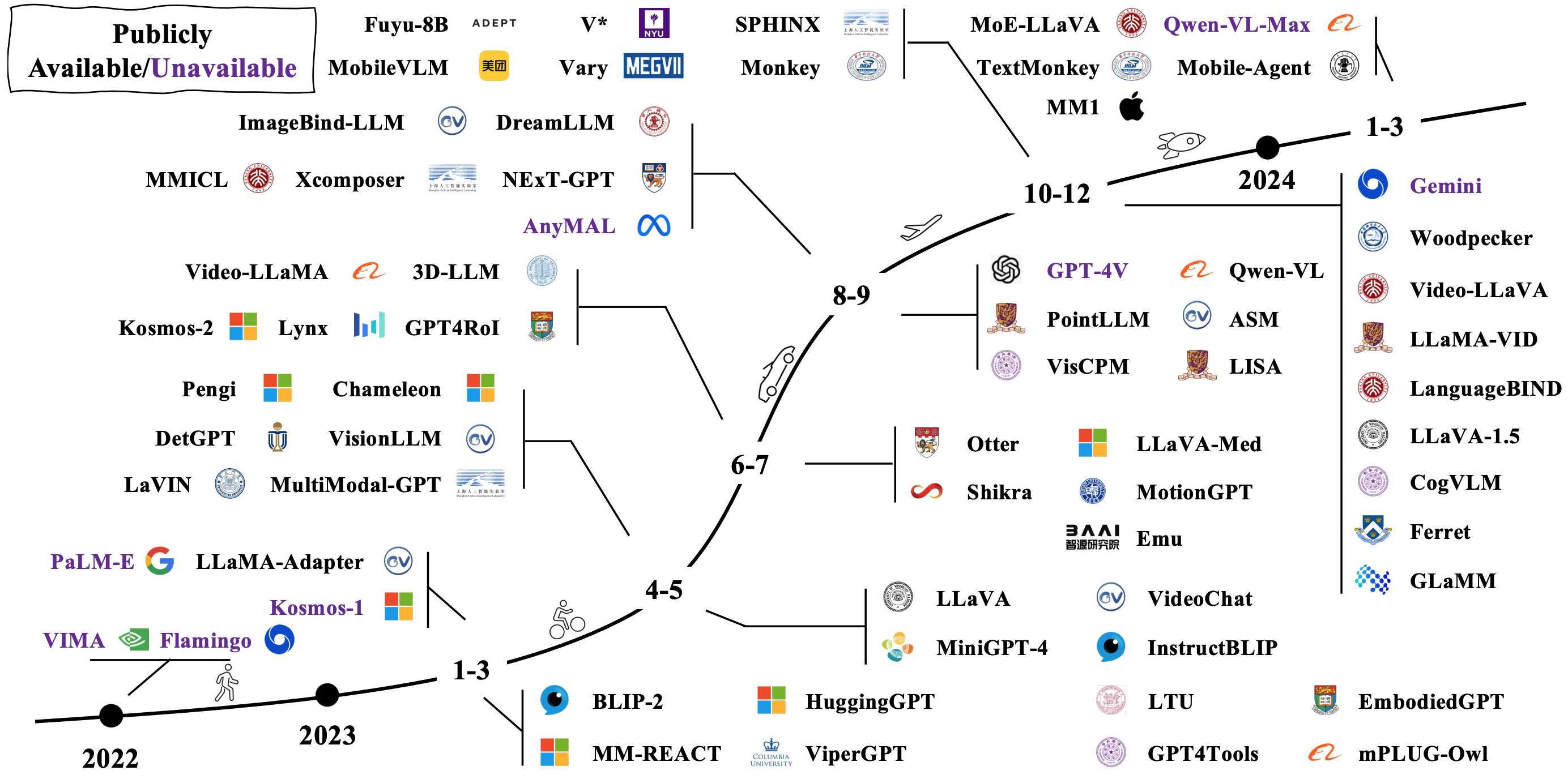
Modellarchitekturen
Es gibt viele verschiedene Möglichkeiten, LMMs zu konstruieren. Repräsentative Architekturen umfassen:
- Sprachmodelle sind allgemeine Schnittstellen
- Flamingo: Ein visuelles Sprachmodell für wenige Lernen (Neurips 2022)
- BLIP: Bootstrapping Sprachbild Vorausbildung für einheitliches Verständnis und Generation von Visionsprachen (ICML 2022)
- BLIP-2: Bootstrapping-Sprachbild vor der Ausbildung mit gefrorenen Bildcodierern und großen Sprachmodellen (ICML 2023)
- MPLUG-UWL2: revolutionieren multimodales Großsprachmodell mit Modalitätszusammenarbeit
- Florence-2: Förderung einer einheitlichen Darstellung für eine Vielzahl von Sichtaufgaben
- Dichter Stecker für Mllms
Weitere Arbeiten finden Sie über Link 1 und Link 2.
Auf verkörperte Agenten
Durch die Kombination von LMMs mit Robotern wollen die Forscher AI -Systeme entwickeln, die die Welt auf natürlichere und intuitivere Weise erkennen, den Vernunft für die Welt wahrnehmen und auf die Welt reagieren können, mit potenziellen Anwendungen, die Robotik, virtuelle Assistenten, autonome Fahrzeuge und darüber hinaus überspannen. Hier sind einige repräsentative Arbeiten, um verkörperte KI mit LMMs zu verwirklichen:
- RT-1: Robotics-Transformator für die reale Steuerung im Maßstab
- RT-2: Vision-Sprach-Action-Modelle übertragen Webwissen auf Roboterkontrolle
- RT-H: Aktionshierarchien mit Sprache
- Palm-E: Ein verkörpertes multimodales Sprachmodell
- TRANSIC: SIM-to-Real-Richtlinienübertragung durch Lernen durch Online-Korrektur
Weitere Arbeiten finden Sie über Link 1 und Link 2.
Hier sind einige beliebte Simulatoren und Datensätze zur Bewertung der LMMS -Leistung für verkörperte KI:
- Habitat 3.0: Eine verkörperte KI-Simulationsplattform zur Untersuchung der kollaborativen Aufgaben des Human-Robot-Interaktion in häuslichen Umgebungen
- Procthor-10K: 10K Interaktive Haushaltsumgebungen für verkörperte KI
- ARNOLD: Ein Maßstab für das Lernen von Sprach aufgaben mit kontinuierlichen Zuständen in realistischen 3D-Szenen
- Legent: Offene Plattform für verkörperte Agenten
- Robocasa: Große Simulation alltäglicher Aufgaben für Generalist Roboter
Hier finden Sie mehr Ressourcen.
Offene Herausforderungen
Hier sind einige Umfragepapiere über offene Herausforderungen für LMM-fähige verkörperte KI:
- Der Anstieg und das Potenzial von modellbasierten Wirkstoffen in großer Sprache: eine Umfrage
- Vision-Sprachnavigation mit verkörperter Intelligenz: Eine Umfrage
- Eine Übersicht über verkörperte KI: Von Simulatoren bis hin zu Forschungsaufgaben
- Eine Umfrage zu autonomen LLM-basierten Agenten
- Mindstorms in natürlichen Sprachgesellschaften des Geistes
Jenseits von Transformatoren
Forscher versuchen, andere Modelle als Transformatoren zu erkunden. Die Bemühungen umfassen implizit die Modellparameter und die Definition neuer Modellarchitekturen.
Implizit strukturierte Parameter
- Monarch -Mixer: Bert ohne Aufmerksamkeit oder MLPs überprüft
- Mamba: Modellierung der linearen Zeitsequenz mit selektiven Zustandsräumen
Neue Modellarchitekturen
- Hyänenhierarchie: Auf dem Weg zu größeren Faltungssprachmodellen
- RWKV: RNNs für die Transformator -Ära neu erfinden
- Retentive Network: Ein Nachfolger des Transformators für große Sprachmodelle
- Mamba: Modellierung der linearen Zeitsequenz mit selektiven Zustandsräumen
- Kan: Kolmogorov -Arnold -Netzwerke
- Transformatoren sind SSMs: Verallgemeinerte Modelle und effiziente Algorithmen durch strukturierte Zustandsraum Dualität
Hier ist ein großartiges Tutorial für Staatsraummodelle.


