Generative AI Tutorial
1.0.0
دليل التعلم الذاتي لأبحاث الذكاء الاصطناعي بما في ذلك قائمة منسقة من المقالات والمشاريع
AI Generation هو موضوع ساخن اليوم ، وقد تم تصميم خريطة الطريق هذه لمساعدة المبتدئين بسرعة على اكتساب المعرفة الأساسية وإيجاد موارد مفيدة من الذكاء الاصطناعي. حتى الخبراء مرحب بهم للإشارة إلى خارطة الطريق هذه لتذكر المعرفة القديمة وتطوير أفكار جديدة.
يجب أن يساعدك هذا القسم على تعلم أو استعادة المعرفة الأساسية للشبكات العصبية (على سبيل المثال ، backpropagation) ، والتعرف على بنية المحولات ، ووصف بعض النماذج القائمة على المحولات الشائعة.
هل أنت معتاد جدًا على هياكل الشبكة العصبية الكلاسيكية التالية؟
إذا كان الأمر كذلك ، فيجب أن تكون قادرًا على الإجابة على هذه الأسئلة:
Backpropagation (BP) هي قاعدة التدريب NN. لن تكون خبيرًا في الذكاء الاصطناعي إذا كنت لا تفهم BP . هناك العديد من الكتب المدرسية والدروس التعليمية عبر الإنترنت التي تدرس BP ، ولكن لسوء الحظ ، فإن معظمها لا يقدم الصيغ في النماذج المتجهة/المتكررة. صيغة BP لطبقة NN هي في الواقع أنيقة مثل صيغة تمريرة الأمام. هذا هو بالضبط الطريقة التي يتم بها تنفيذ BP ويجب تنفيذها. لفهم BP ، يرجى قراءة المواد التالية:
إذا فهمت BP ، فيجب أن تكون قادرًا على الإجابة على هذه الأسئلة:
المحول هو البنية الأساسية للنماذج التوليدية الكبيرة الموجودة. من الضروري فهم كل مكون في المحول. يرجى قراءة المواد التالية:
إذا فهمت المحولات ، فيجب أن تكون قادرًا على الإجابة على هذه الأسئلة:
Einsum سهل ومفيد [برنامج تعليمي رائع لاستخدام einsum/einops]
الانطلاق المفتوح ضروري للذكاء الاصطناعي الخارق (ICML 2024) [أفكار حول تحقيق الذكاء الاصطناعي الخارق]
مستويات AGI لتشغيل التقدم على الطريق إلى AGI
LLMs هي المحولات. يمكن تصنيفها إلى بنيات تشفير فقط ، وترميز تشفير ، وفك الترميز فقط ، كما هو موضح في شجرة LLM التطورية أدناه [مصدر الصورة]. تحقق من أوراق المعلم من LLMS.
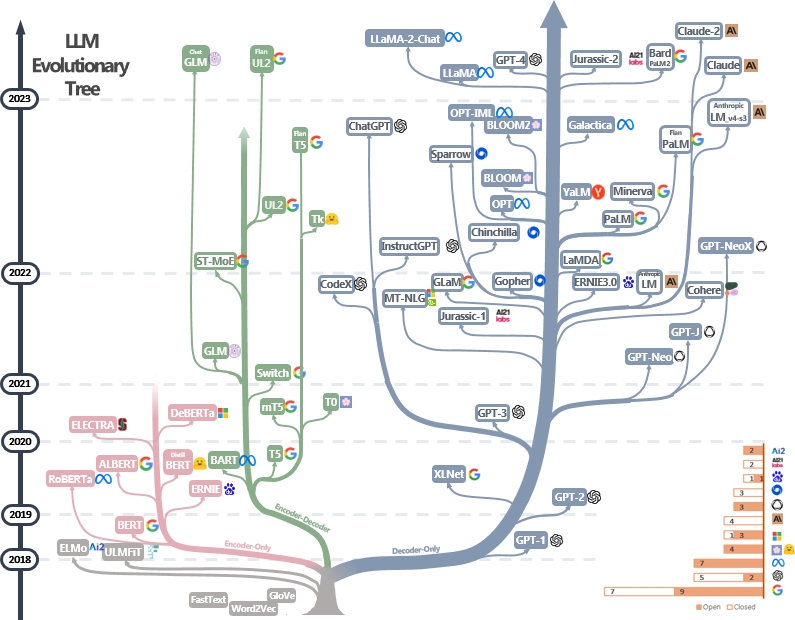
يمكن استخدام نموذج التشفير فقط لاستخراج ميزات الجملة ولكنه يفتقر إلى القوة التوليدية. يتم استخدام نماذج التشفير والرفض فقط لتوليد النصوص. على وجه الخصوص ، تفضل معظم LLMs الحالية الهياكل التي ترميزها فقط بسبب قوة إعادة البيع الأقوى. بشكل حدسي ، يمكن اعتبار نماذج التشفير-ترميز التشفير نسخة متناثرة من نماذج فك التشفير فقط والمعلومات تتحلل أكثر من التشفير إلى وحدة فك الترميز. تحقق من هذه الورقة لمزيد من التفاصيل.
عادةً ما يتم تأثر LLMs من تريليونات من الرموز النصية من قبل الناشرين النماذج لاستيعاب بنية اللغة الطبيعية. يقوم مطورو النماذج اليوم أيضًا بإجراء التعلم التعليمي التعليمي والتعزيز من التعليقات البشرية (RLHF) لتدريس النموذج لاتباع التعليمات البشرية وتوليد إجابات تتماشى مع التفضيل البشري. يمكن للمستخدمين بعد ذلك تنزيل النموذج المنشور و finetune على مجموعات البيانات الشخصية الصغيرة (على سبيل المثال ، مربع حوار الفيلم). بسبب كمية كبيرة من البيانات ، يتطلب التدريب قبل الموارد الحوسبة الضخمة (على سبيل المثال ، أكثر من آلاف وحدات معالجة الرسومات) التي لا يمكن تحملها من قبل الأفراد. من ناحية أخرى ، فإن الضبط الدقيق أقل إثارة للموارد ويمكن القيام به مع عدد قليل من وحدات معالجة الرسومات.
يمكن أن تساعدك المواد التالية على فهم عملية الاستطلاع والضوء:
يمكن العثور على المزيد من البرامج التعليمية هنا.
تتضمن تقنيات المطالبة بـ LLMs صياغة نص الإدخال بطريقة توجه النموذج لإنشاء الاستجابات أو المخرجات المطلوبة. فيما يلي الموارد المفيدة لمساعدتك في كتابة مطالبات أفضل:
تساعد أدوات التقييم لنماذج اللغة الكبيرة في تقييم أدائها وقدراتهم والقيود في المهام ومجموعات البيانات المختلفة. فيما يلي بعض استراتيجيات التقييم الشائعة:
مقاييس التقييم التلقائي : تقيم هذه المقاييس أداء النموذج تلقائيًا دون تدخل بشري. تشمل المقاييس الشائعة:
التقييم البشري : الحكم الإنساني ضروري لتقييم جودة النص الناتج بشكل شامل. تشمل طرق التقييم البشري الشائع:
مجموعات البيانات القياسية : تتيح مجموعات البيانات الموحدة مقارنة عادل للنماذج عبر المهام والمجالات المختلفة. تشمل الأمثلة:
أدوات تحليل النماذج: أدوات لتحليل سلوك النموذج والأداء تشمل:
يمكن العثور على قائمة كاملة هنا
تشمل أطر التقييم القياسية لـ LLMs الحالية:
يمثل التعامل مع السياقات الطويلة تحديًا لنماذج اللغة الكبيرة بسبب القيود في الذاكرة وقدرة المعالجة. تشمل التقنيات الحالية:
يمكن العثور على قائمة كاملة هنا
تتيح أساليب الضبط الدقيق (PEFT) الموفرة للمعلمة التكيف الفعال للنماذج الكبيرة المسبقة لتطبيقات المصب المختلفة من خلال صياغة عدد صغير فقط من المعلمات النموذجية (الإضافية) بدلاً من جميع معلمات النموذج:
يمكن العثور على مزيد من العمل في مجموعة ورق Huggingface Peft ، ويوصى بشدة بالتدريب مع API PEFT API.
يشير دمج النموذج إلى دمج اثنين أو أكثر من LLMs المدربين على مهام مختلفة في LLM واحد. تهدف هذه التقنية إلى الاستفادة من نقاط القوة ومعرفة النماذج المختلفة لإنشاء نموذج أكثر قوة وقدرة. على سبيل المثال ، يمكن دمج LLM لتوليد الكود و LLM آخر لحل Math Prolem معًا بحيث يكون النموذج المدمج قادرًا على القيام بتوليد الكود وحل مشكلات الرياضيات.
إن دمج النموذج مثير للاهتمام لأنه يمكن تحقيقه بفعالية مع خوارزميات بسيطة ورخيصة للغاية (على سبيل المثال ، مزيج خطي من أوزان النموذج). فيما يلي بعض الأوراق التمثيلية ومواد القراءة:
يمكن العثور على المزيد من الأوراق حول دمج النموذج هنا
يعد تسريع فك تشفير LLMS أمرًا بالغ الأهمية لتحسين سرعة الاستدلال والكفاءة ، وخاصة في التطبيقات في الوقت الفعلي أو الحساسة لمواصلة. فيما يلي بعض الأعمال التمثيلية لتسريع عملية فك تشفير LLMS:
يمكن العثور على مزيد من العمل حول تسريع فك تشفير LLM عبر الرابط 1 والرابط 2.
يهدف تحرير المعرفة إلى تعديل سلوكيات LLMS بكفاءة ، مثل الحد من التحيز ومراجعة الارتباطات المستفادة. ويشمل العديد من الموضوعات مثل توطين المعرفة وعدم التعلم. يشمل العمل التمثيلي:
يمكن العثور على المزيد من الأوراق هنا.
من خلال تلقي التدريب الهائل ، فإن LLMS Digest World Knowledge و Van على اتباع تعليمات الإدخال على وجه التحديد. من خلال هذه القدرات المذهلة ، يمكن أن تلعب LLMs كوكلاء ممكنة لحل المهام المعقدة (والتعاونية) بشكل مستقل ، أو محاكاة التفاعلات البشرية. فيما يلي بعض الأوراق التمثيلية لعوامل LLM:
يمكن العثور على قائمة كاملة من الأوراق والمنصات وأدوات التقييم هنا.
تواجه LLMs العديد من التحديات المفتوحة التي يعمل بها الباحثون والمطورين بنشاط لمعالجتها. وتشمل هذه التحديات:
يمكن العثور على قائمة كاملة هنا.
تهدف نماذج الانتشار إلى تقارب توزيع احتمالية مجال بيانات معين ، وتوفير وسيلة لإنشاء عينات من توزيعه التقريبي. تشبه أهدافهم النماذج التوليدية الشائعة الأخرى ، مثل VAE و Gans والتدفقات التطبيع.
يتميز تدفق عمل نماذج الانتشار بعملية:
تحقق من هذه المدونة الرائعة ويمكن العثور على المزيد من البرامج التعليمية التمهيدية هنا. يمكن استخدام نماذج الانتشار لإنشاء الصور والسمعات ومقاطع الفيديو والمزيد ، وهناك العديد من الحقول الفرعية المتعلقة بنماذج الانتشار كما هو موضح أدناه [مصدر الصورة]:
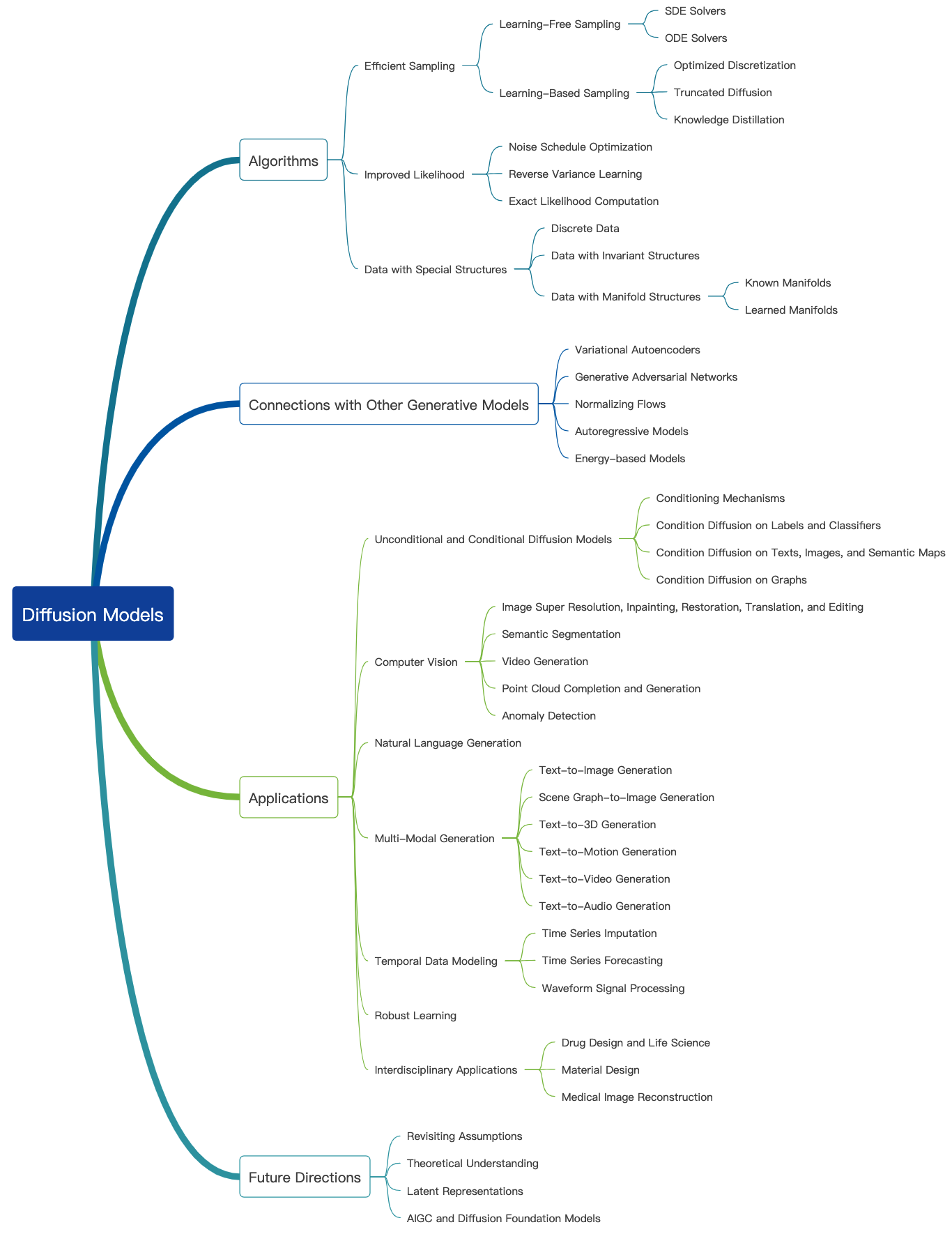
فيما يلي بعض الأوراق التمثيلية لنماذج الانتشار لتوليد الصور:
يمكن العثور على المزيد من الأوراق هنا.
فيما يلي بعض الأوراق التمثيلية لنماذج الانتشار لتوليد الفيديو:
يمكن العثور على المزيد من الأوراق هنا.
فيما يلي بعض الأوراق التمثيلية لنماذج الانتشار لتوليد الصوت:
يمكن العثور على المزيد من الأوراق هنا.
على غرار النماذج التوليدية الكبيرة الأخرى ، يتم أيضًا ملائمة نماذج الانتشار على كمية كبيرة من بيانات الويب (على سبيل المثال ، مجموعة بيانات LAION-5B) وتستهلك موارد الحوسبة الضخمة. يمكن للمستخدمين تنزيل الأوزان التي تم إصدارها يمكن أن تؤدي إلى زيادة ضبط النموذج على مجموعات البيانات الشخصية.
فيما يلي بعض الأوراق التمثيلية لضبط نماذج الانتشار الفعالة:
يمكن العثور على المزيد من الأوراق هنا.
من المستحسن بشدة القيام ببعض الممارسات مع API لانتشار الواجهة.
هنا نتحدث عن تقييم نماذج الانتشار لتوليد الصور. يمكن تطبيق العديد من مقاييس جودة الصورة الحالية.
يمكن العثور على مزيد من مقاييس جودة الصورة وأدوات الحساب هنا.
تتطلب نماذج الانتشار خطوات متعددة للأمام لإنشاء البيانات ، وهي مكلفة. فيما يلي بعض الأوراق التمثيلية لنماذج الانتشار لتوليد كفاءة:
يمكن العثور على المزيد من الأوراق هنا.
فيما يلي بعض الأوراق التمثيلية لتحرير المعرفة لنماذج الانتشار:
يمكن العثور على المزيد من الأوراق هنا.
فيما يلي بعض أوراق المسح تتحدث عن التحديات التي تواجه نماذج الانتشار.
يتم إنشاء LMMs النموذجية عن طريق توصيل وضبط النماذج الأحادية الوسيطة الموجودة. بعضها أيضًا مدروسة من الصفر. تحقق من كيفية تطور LMMS في الصورة أدناه [مصدر الصورة].
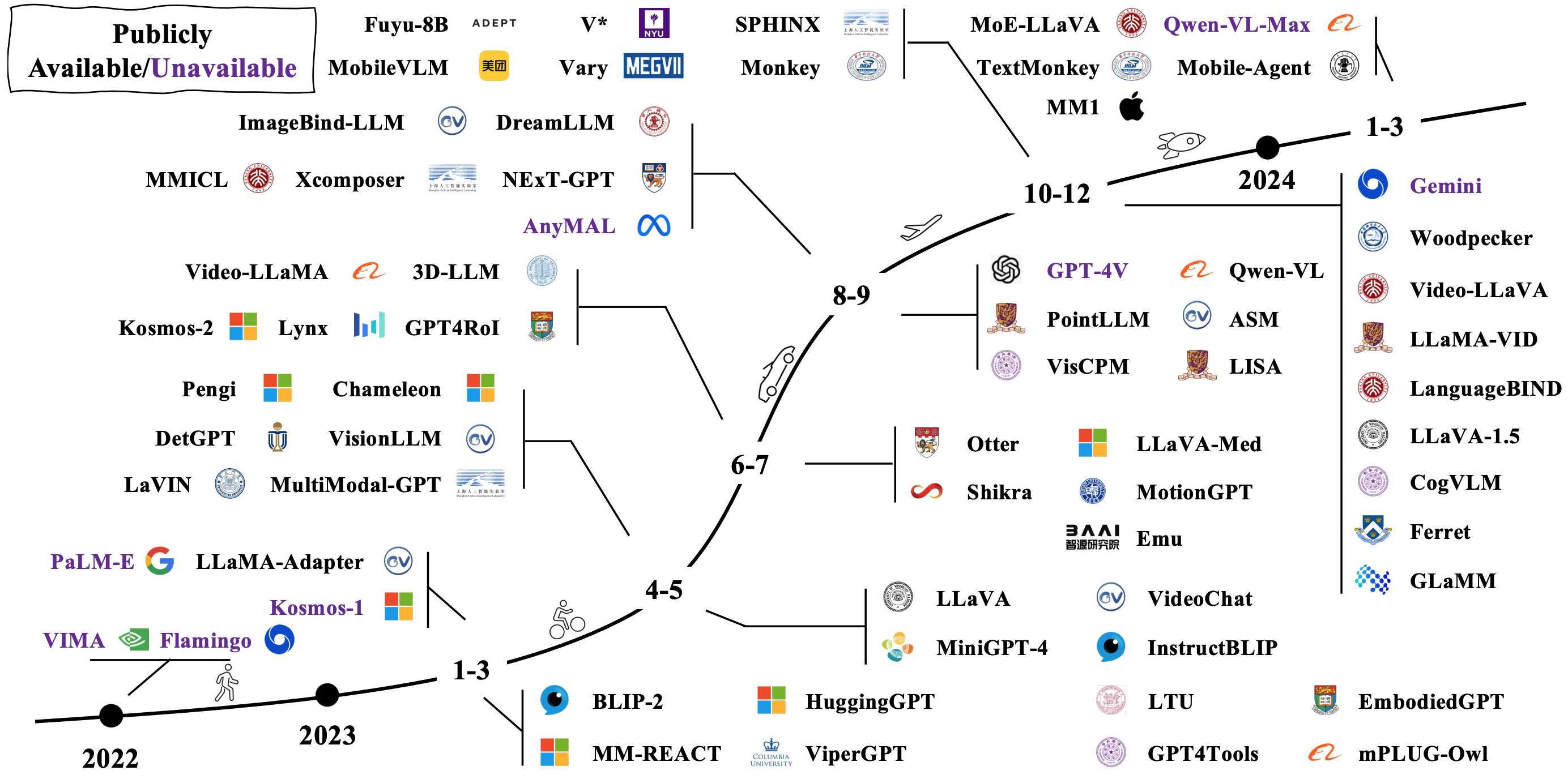
هناك العديد من الطرق المختلفة لتناقض LMMS. تشمل البنى التمثيلية:
يمكن العثور على المزيد من الأوراق عبر الرابط 1 والرابط 2.
من خلال الجمع بين LMMs مع الروبوتات ، يهدف الباحثون إلى تطوير أنظمة الذكاء الاصطناعى التي يمكن أن تتصور ، والسبب في العالم بطريقة أكثر طبيعية وبديهية ، مع تطبيقات محتملة تمتد على الروبوتات ، والمساعدين الافتراضيين ، والمركبات المستقلة ، وما بعدها. فيما يلي بعض الأعمال التمثيلية لتحقيق الذكاء الاصطناعي المجسد مع LMMS:
يمكن العثور على المزيد من الأوراق عبر الرابط 1 والرابط 2.
فيما يلي بعض أجهزة المحاكاة ومجموعات البيانات الشائعة لتقييم أداء LMMS لـ AI المجسدة:
يمكن العثور على مزيد من الموارد هنا.
فيما يلي بعض أوراق الاستقصاء التي تتحدث عن التحديات المفتوحة التي تتم تمكينها من الذكاء الاصطناعي المتمثل في LMM:
يحاول الباحثون استكشاف نماذج جديدة بخلاف المحولات. وتشمل الجهود هيكلة المعلمات النموذجية ضمنيًا وتحديد بنيات نموذجية جديدة.
إليك برنامج تعليمي رائع لنماذج فضاء الولاية.


