 Hoja de ruta generativa de IA
Hoja de ruta generativa de IA
Una guía de aprendizaje subjetivo para una investigación generativa de IA que incluye una lista curada de artículos y proyectos
La IA generativa es un tema candente hoy y esta hoja de ruta está diseñada para ayudar a los principiantes a obtener rápidamente conocimientos básicos y encontrar recursos útiles de IA generativa. Incluso los expertos pueden referirse a esta hoja de ruta para recordar los viejos conocimientos y desarrollar nuevas ideas.
Tabla de contenido
- Conocimiento previo
- Inferencia y capacitación de redes neuronales
- Arquitectura del transformador
- Modelos comunes basados en transformadores
- Misceláneas
- Modelos de idiomas grandes (LLM)
- Preventiva y ajustado
- Incitación
- Evaluación
- Lidiar con un contexto largo
- Ajuste fino eficiente
- Modelo de fusión
- Generación eficiente
- Edición de conocimiento
- Agentes con alimentación de LLM
- Recomendaciones
- Desafíos abiertos
- Modelos de difusión
- Generación de imágenes
- Generación de videos
- Generación de audio
- Preventiva y ajustado
- Evaluación
- Generación eficiente
- Edición de conocimiento
- Desafíos abiertos
- Grandes modelos multimodales (LMM)
- Arquitecturas de modelos
- Hacia agentes encarnados
- Desafíos abiertos
- Más allá de los transformadores
- Parámetros estructurados implícitamente
- Nuevas arquitecturas de modelos
Conocimiento previo
Esta sección debe ayudarlo a aprender o recuperar el conocimiento básico de las redes neuronales (por ejemplo, la retroceso), familiarizarlo con la arquitectura del transformador y describir algunos modelos comunes basados en transformadores.
Inferencia y capacitación de redes neuronales
¿Estás muy familiarizado con las siguientes estructuras clásicas de redes neuronales?
- Perceptrón de múltiples capas (MLP)
- Red neuronal convolucional (CNN)
- Red neuronal recurrente (RNN)
Si es así, debería poder responder estas preguntas:
- ¿Por qué los CNN funcionan mejor que los MLP en las imágenes?
- ¿Por qué los RNN funcionan mejor que los MLP en los datos de la serie temporal?
- ¿Cuál es la diferencia entre GRU y LSTM?
Backpropagation (BP) es la base del entrenamiento NN. No será un experto en IA si no comprende BP . Hay muchos libros de texto y tutoriales en línea que enseñan BP, pero desafortunadamente, la mayoría de ellos no presentan fórmulas en formas vectorizadas/tensorizadas. La fórmula BP de una capa NN es tan ordenada como su fórmula de pase hacia adelante. Así es exactamente como se implementa BP y debe implementarse. Para comprender BP, lea los siguientes materiales:
- Redes neuronales y aprendizaje profundo [Capítulo 3.2 Especialmente 3.2.6]
- MEPROP: propagación de espalda dispersa para el aprendizaje profundo acelerado con sobreajuste reducido (ICML 2017) [Sección 2.1]
- Resprop: reutilización de backpropagation (CVPR 2020) [Sección 3.1]
Si comprende BP, debería poder responder estas preguntas:
- ¿Cómo describirás la BP de una capa convolucional?
- ¿Cuál es la relación del costo informático (es decir, el número de operaciones de puntos flotantes) entre el pase hacia adelante y el paso hacia atrás de una capa densa?
- ¿Cómo describirá la BP de un MLP con dos capas densas que comparten la misma matriz de peso?
Arquitectura del transformador
Transformer es la arquitectura base de los modelos generativos grandes existentes. Es necesario comprender cada componente del transformador. Lea los siguientes materiales:
- La atención es todo lo que necesita (Neurips 2017) [Documento original]
- Explicador de transformadores: aprendizaje interactivo de modelos generativos de texto [un tutorial interactivo]
- Una imagen vale 16x16 palabras: transformadores para el reconocimiento de imágenes a escala (ICLR 2021) [Transformador de visión]
- Traducción del automóvil neural con un transformador y keras [gran explicación para la atención de múltiples cabezas (MHA)]]
- Flops de un bloque de transformador [Practicemos Cálculo de fracasos]
- Decodificación de transformador rápido: una cabeza de escritura es todo lo que necesita [Atención múltiple (MQA)]]
- GQA: capacitación de modelos de transformadores múltiples generalizados desde puntos de control de múltiples cabezas [Atención agrupada (GQA)]
- Transformador mejorado con incrustación de posición rotativa [Comprender la incrustación posicional]
- INCREGOS ROTARIOS: una revolución relativa [Comprender la incrustación posicional]
- Force de maestro frente a muestreo programado frente al modo normal [Forzando el maestro en la capacitación del transformador]
- FlexGen: inferencia generativa de alto rendimiento de modelos de lenguaje grande con una sola GPU [ver Sección 3 - Inferencia generativa para aprender cómo LLMS PEFORM Generation basada en el caché de KV]
- Codificación de posición contextual: aprender a contar lo importante [codificación posicional dependiente del contexto]
Si comprende Transformers, debería poder responder estas preguntas:
- ¿Cuáles son los pros y los contras de los transformadores en comparación con los RNN? (asistir simultáneamente, capacitar al paralelismo, complejidad)
- ¿Puedes cacular los fracasos de GQA? ¿Ves cuándo se degrada a MHA y MQA?
- ¿Cuál es la motivación de MQA y GQA?
- ¿Cómo se ve la máscara de atención causal y por qué?
- ¿Cómo describirá el entrenamiento de los transformadores de decodificadores paso a paso?
- ¿Por qué la cuerda es mejor que la codificación posicional sinusoidal?
Modelos comunes basados en transformadores
- Aprender modelos visuales transferibles a partir de supervisión del lenguaje natural [clip]
- Propiedades emergentes en transformadores de visión auto-supervisados (ICCV 2021) [Dino]
- Los autoencoders enmascarados son estudiantes de visión escalables (CVPR 2022) [MAE]
- Visión de escala con una mezcla escasa de expertos (Neurips 2021) [MOE]
- Mezcla de Dephs: asignación dinámica de cómputo en modelos de lenguaje basados en transformadores [MOD]
Misceláneas
Einsum es fácil y útil [un gran tutorial para usar Einsum/Einops]
El final abierto es esencial para la inteligencia sobrehumana artificial (ICML 2024) [Pensamientos sobre el logro de AI sobrehumana]
Niveles de AGI para operacionalizar el progreso en el camino hacia AGI
Modelos de idiomas grandes (LLM)
Los LLM son transformadores. Se pueden clasificar en arquitecturas solo codificadoras, codificadoras y decodificadores y solo decodificadores, como se muestra en el árbol evolutivo de LLM a continuación [fuente de imagen]. Verifique los documentos de hitos de LLM.
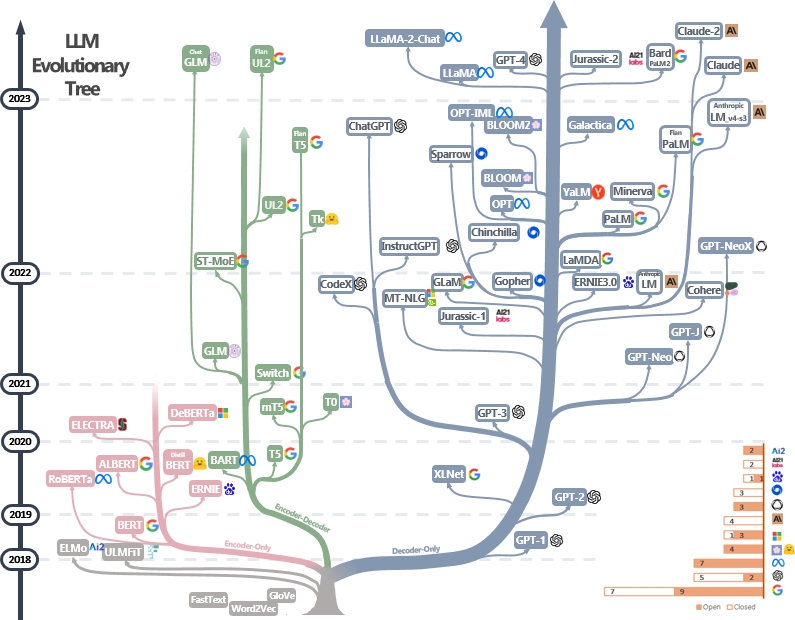
El modelo solo del codificador se puede usar para extraer características de oraciones, pero carece de potencia generativa. Los modelos de codificador y decodificador del codificador se utilizan solo para la generación de texto. En particular, la mayoría de los LLM existentes prefieren estructuras de decodificador solo debido al poder de repesentacional más fuerte. Intuitivamente, los modelos de codificador de codificadores pueden considerarse una versión escasa de los modelos de decodificadores y la información decae más de un codificador a otro. Consulte este documento para obtener más detalles.
Preventiva y fineta
Los LLM típicamente están provocados de billones de tokens de texto por editores de modelos para internalizar la estructura del lenguaje natural. Los desarrolladores de modelos de hoy también realizan el ajuste y el aprendizaje de refuerzo de fino instructivo de la retroalimentación humana (RLHF) para enseñar al modelo a seguir las instrucciones humanas y generar respuestas alineadas con la preferencia humana. Luego, los usuarios pueden descargar el modelo publicado y Finetune en pequeños conjuntos de datos personales (por ejemplo, diálogo de películas). Debido a la gran cantidad de datos, la previación requiere recursos informáticos masivos (por ejemplo, más de miles de GPU), lo cual es inasequible por los individuos. Por otro lado, el ajuste fino tiene menos hambre de recursos y se puede hacer con algunas GPU.
Los siguientes materiales pueden ayudarlo a comprender el proceso previo y ajustado:
- BERT: Pretenerse de transformadores bidireccionales profundos para la comprensión del lenguaje [preventiva y finete de LLMS solo del codificador]
- Instrucción de escala Modelos de lenguaje financieros [preventivo y finete de instrucción]
- Ilustrando el aprendizaje de refuerzo de la retroalimentación humana (RLHF)
- Los modelos de idiomas son alumnos de pocos disparos [LLMS solo de decodificadores] [中文导读 por 李沐]
Se pueden encontrar más tutoriales aquí.
Incitación
Las técnicas de solicitación para LLM implican la elaboración del texto de entrada de una manera que guíe el modelo para generar respuestas o salidas deseadas. Estos son los recursos útiles para ayudarlo a escribir mejores indicaciones:
- [Dair.ai] Guía de ingeniería rápida
- Inicentes indicaciones de chatgpt: una colección de ejemplos de inmediato que se utilizarán con el modelo ChatGPT
- Impresionante solicitación deliberativa: cómo pedirle a LLM que produzca un razonamiento confiable y tome decisiones de respuesta a la razón
- Autoprompt: un método automatizado basado en la búsqueda guiada por el gradiente para crear indicaciones para un conjunto diverso de tareas de PNL.
Evaluación
Las herramientas de evaluación para modelos de idiomas grandes ayudan a evaluar su rendimiento, capacidades y limitaciones en diferentes tareas y conjuntos de datos. Aquí hay algunas estrategias de evaluación comunes:
Métricas de evaluación automática : estas métricas evalúan el rendimiento del modelo automáticamente sin intervención humana. Las métricas comunes incluyen:
- Bleu: mide la similitud entre el texto generado y el texto de referencia basado en la superposición de N-Gram.
- Rouge: evalúa el resumen del texto comparando n-gramos superpuestos entre resúmenes generados y de referencia.
- Perlexidad: mide qué tan bien un modelo de lenguaje predice una muestra de texto. La menor perplejidad indica un mejor rendimiento. Es equivalente a la exponenciación de la entropía cruzada entre los datos y las predicciones del modelo.
- Puntuación F1: mide el equilibrio entre precisión y retiro en tareas como la clasificación de texto o el reconocimiento de entidad nombrado.
Evaluación humana : el juicio humano es esencial para evaluar la calidad del texto generado de manera integral. Los métodos de evaluación humana comunes incluyen:
- Clasificaciones humanas : la tasa de anotadores humanos generó texto basado en criterios como fluidez, coherencia, relevancia y gramaticalidad.
- Plataformas de crowdsourcing : plataformas como Amazon Mechanical Turk o la Figura ocho facilitan la evaluación humana a gran escala mediante anotaciones de crowdsourcing.
- Evaluación de expertos : los expertos en dominios evalúan los resultados del modelo para medir su idoneidad para aplicaciones o tareas específicas.
Conjuntos de datos de referencia : los conjuntos de datos estandarizados permiten una comparación justa de modelos en diferentes tareas y dominios. Los ejemplos incluyen:
- Triviaqa: un conjunto de datos de desafío supervisado a gran escala para la comprensión de lectura
- HELLASWAG: ¿Puede una máquina realmente terminar tu oración?
- GSM8K: Verificadores de entrenamiento para resolver problemas de palabras matemáticas
- Una lista completa se puede encontrar aquí
Herramientas de análisis del modelo: las herramientas para analizar el comportamiento y el rendimiento del modelo incluyen:
- Interpretabilidad automatizada: código para generar, simular y calificar automáticamente explicaciones del comportamiento de las neuronas
- Visualización de LLM: visualización de LLM en bajo nivel.
- Análisis de atención: analizar mapas de atención del transformador Bert.
- Visor de neuronas: herramienta para ver las activaciones y explicaciones de las neuronas.
Una lista completa se puede encontrar aquí
Los marcos de evaluación estándar para LLM existentes incluyen:
- LM-Evaluación-Harness: un marco para la evaluación de pocos disparos de los modelos de idiomas.
- LightEval: un conjunto de evaluación LLM liviano que la cara abrazada ha estado utilizando internamente.
- Olmo -Eval: un repositorio para evaluar modelos de lenguaje abierto.
- Instruct-Eval: este repositorio contiene código para evaluar cuantitativamente modelos ajustados a instrucciones como Alpaca y Flan-T5 en tareas mantenidas.
Lidiar con un contexto largo
Tratar con contextos largos plantea un desafío para los modelos de idiomas grandes debido a las limitaciones en la memoria y la capacidad de procesamiento. Las técnicas existentes incluyen:
- Transformadores eficientes
- Longformer: el transformador de documentos largos
- Reformador: el transformador eficiente (ICLR 2020)
- Modelos de espacio de estado
- Los transformadores son RNN: transformadores autorregresivos rápidos con atención lineal (ICML 2020)
- Repensar la atención con los artistas
- Extrapolación de longitud
- Mamba: modelado de secuencia de tiempo lineal con espacios de estado selectivos
- ROFORMER: Transformador mejorado con incrustación de posición giratoria
- Hilo: extensión de ventana de contexto eficiente de modelos de idiomas grandes
- Memoria a largo plazo
- MemoryBank: Mejora de modelos de idiomas grandes con memoria a largo plazo
- Desatar la capacidad de entrada de longitud infinita para modelos de lenguaje a gran escala con un sistema de memoria autocontrolado
Una lista completa se puede encontrar aquí
Finetuning eficiente
Los métodos de ajuste fino de los parámetros (PEFT) permiten una adaptación eficiente de grandes modelos previos a la aparición a varias aplicaciones aguas abajo al ajustar solo un pequeño número de parámetros del modelo (extra) en lugar de todos los parámetros del modelo:
- Ajuste de solicitud: el poder de la escala para el ajuste de inmediato de los parámetros eficientes
- Ajuste del prefijo: ajuste del prefijo: optimización de indicaciones continuas para la generación
- Lora: Lora: adaptación de bajo rango de modelos de idiomas grandes
- Hacia una visión unificada del aprendizaje de transferencia de parámetros-eficiente
- Lora aprende menos y olvida menos
Se puede encontrar más trabajo en Huggingface Peft Paper Collection y se recomienda practicar con Huggingface PEFT API.
Modelo de fusión
La fusión del modelo se refiere a fusionar dos o más LLM entrenados en diferentes tareas en un solo LLM. Esta técnica tiene como objetivo aprovechar las fortalezas y el conocimiento de los diferentes modelos para crear un modelo más robusto y capaz. Por ejemplo, una LLM para la generación de código y otra resolución de prolem de LLM para matemáticas se puede fusionar para que el modelo fusionado sea capaz de hacer la generación de código y la resolución de problemas de matemáticas.
La fusión del modelo es intrigante porque se puede lograr de manera efectiva con algoritmos muy simples y baratos (por ejemplo, combinación lineal de pesos del modelo). Aquí hay algunos documentos representativos y materiales de lectura:
- Sopas de modelo: promedio de pesos de múltiples modelos ajustados mejora la precisión sin aumentar el tiempo de inferencia
- Modelos de edición con aritmética de tareas
- Fusionar modelos de idiomas grandes con MergeKit
Se pueden encontrar más documentos sobre la fusión del modelo aquí
Generación eficiente
La decodificación de aceleración de LLM es crucial para mejorar la velocidad y la eficiencia de la inferencia, especialmente en aplicaciones en tiempo real o sensibles a la latencia. Aquí hay algunos trabajos representativos de acelerar el proceso de decodificación de LLM:
- Deja Vu: escasez contextual para LLM eficientes en el tiempo de inferencia (ICML 2023 oral)
- Llmlingua: indicaciones de comprimir para la inferencia acelerada de modelos de idiomas grandes (EMNLP 2023)
- Modelos de lenguaje de transmisión eficientes con sumideros de atención
- Specinfer: Acelerar Generation LLM Siring con inferencia especulativa y verificación de árboles de token
- Medusa: marco de aceleración de inferencia LLM simple con múltiples cabezas de decodificación
- Modelos de idiomas grandes mejores y más rápidos a través de una predicción múltiple
- Skip de capa: habilitando la inferencia de salida temprana y la decodificación autopeculativa
Se puede encontrar más trabajo sobre la aceleración de la decodificación de LLM a través del enlace 1 y el enlace 2.
Edición de conocimiento
La edición del conocimiento tiene como objetivo modificar eficientemente los comportamientos de LLMS, como reducir el sesgo y revisar las correlaciones aprendidas. Incluye muchos temas, como la localización del conocimiento y el desaprendizaje. El trabajo representativo incluye:
- Edición de modelo basada en la memoria a escala (ICML 2022)
- Transformer-Patcher: un error que vale una neurona (ICLR 2023)
- Edición masiva para un modelo de lenguaje grande a través del meta aprendizaje (ICLR 2024)
- Un marco unificado para la edición de modelos
- Las capas del transformador de alimentación son recuerdos de valor clave (EMNLP 2021)
- Memoria de edición de masa en un transformador
Se pueden encontrar más documentos aquí.
Agentes con alimentación de LLM
Al recibir una capacitación masiva, LLMS digerió el conocimiento del mundo y puede seguir las instrucciones de entrada con precisión. Con estas sorprendentes capacidades, los LLM pueden jugar como agentes que son posibles para resolver de forma autónoma (y colaborativamente) tareas complejas o simular interacciones humanas. Aquí hay algunos documentos representativos de los agentes de LLM:
- Agentes generativos: simulacros interactivos del comportamiento humano (Uist 2023) [LLMS simulan la sociedad humana en los videojuegos]
- Sotopia: Evaluación interactiva para la inteligencia social en los agentes del lenguaje (ICLR 2024) [LLMS simulan las interacciones sociales]
- Voyager: un agente incorporado abierto con modelos de idiomas grandes [LLMS vive en el mundo de Minecraft]
- Modelos de idiomas grandes como fabricantes de herramientas (ICLR 2024) [LLMS crean sus propias herramientas reutilizables (por ejemplo, en las funciones de Python) para la resolución de problemas]
- MetAgpt: Meta Programming para el marco colaborativo de múltiples agentes [LLMS como equipo para el desarrollo de software automatizado]
- Webarena: un entorno web realista para construir agentes autónomos (ICLR 2024) [LLMS usa aplicaciones web]
- Mobile-Env: una plataforma de evaluación y un punto de referencia para la interacción LLM-GUI [LLMS usa aplicaciones móviles]
- HuggingGPT: Resolver tareas de IA con ChatGPT y sus amigos en Hugging Face (Neurips 2023) [LLMS busca modelos en Huggingface para la resolución de problemas]
- AgentGym: evolucionando agentes basados en modelos de idiomas grandes en diversos entornos [entornos y tareas interactivos diversos para agentes basados en LLM]
Aquí puede encontrar una lista completa de documentos, plataformas y herramientas de evaluación.
Recomendaciones
- Tu transformador es secretamente lineal
- No todas las características del modelo de idioma son lineales
- Kan o MLP: una comparación más justa
- Capas de transformadores como pintores
- Los modelos de lenguaje de visión son ciegos
Desafíos abiertos
Los LLM enfrentan varios desafíos abiertos que los investigadores y desarrolladores están trabajando activamente para abordar. Estos desafíos incluyen:
- Alucinación
- Una encuesta completa de las técnicas de mitigación de alucinación en modelos de idiomas grandes
- Compresión modelo
- Una encuesta completa de algoritmos de compresión para modelos de idiomas
- Evaluación
- Evaluación de modelos de idiomas grandes: una encuesta completa
- Razonamiento
- Una encuesta de razonamiento con modelos de base
- Explicación
- Desde la comprensión hasta la utilización: una encuesta sobre explicación de modelos de idiomas grandes
- Justicia
- Una encuesta sobre equidad en modelos de idiomas grandes
- Realidad
- Una encuesta sobre facturidad en modelos de idiomas grandes: conocimiento, recuperación y especificidad de dominio
- Integración del conocimiento
- Tendencias en la integración del conocimiento y modelos de idiomas grandes: una encuesta y taxonomía de métodos, puntos de referencia y aplicaciones
Una lista completa se puede encontrar aquí.
Modelos de difusión
Los modelos de difusión apuntan a aproximadamente la distribución de probabilidad de un dominio de datos dado y proporcionar una forma de generar muestras a partir de su distribución aproximada. Sus objetivos son similares a otros modelos generativos populares, como VAE, Gans y flujos de normalización.
El flujo de trabajo de los modelos de difusión se presenta con dos procesos:
- Proceso de avance (proceso de difusión): aplica progresivamente el ruido a los datos de entrada originales paso a paso hasta que los datos se vuelven por completo.
- Proceso inverso (proceso de DENOISEIS): se capacita a un modelo NN (p. Ej., CNN o Tranformer) para estimar el ruido que se aplica en cada paso durante el proceso de avance. Este modelo NN entrenado se puede usar para generar datos a partir de la entrada de ruido. Los modelos de difusión existentes también pueden aceptar otras señales (por ejemplo, indicaciones de texto de los usuarios) para condicionar la generación de datos.
Consulte este increíble blog y se pueden encontrar más tutoriales introductorios aquí. Los modelos de difusión se pueden usar para generar imágenes, audios, videos y más, y hay muchos subcampos relacionados con los modelos de difusión como se muestra a continuación [fuente de imágenes]:
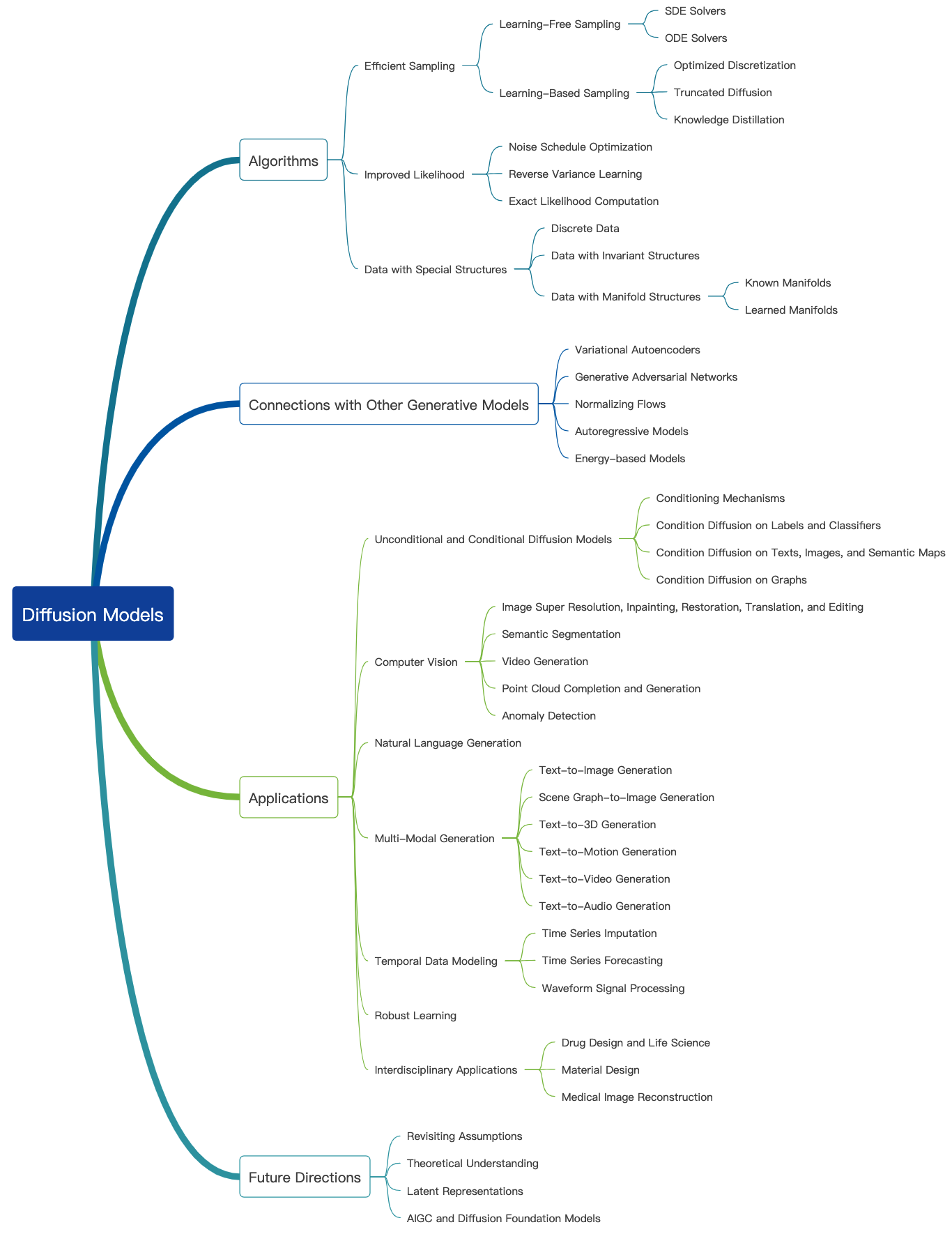
Generación de imágenes
Aquí hay algunos documentos representativos de modelos de difusión para la generación de imágenes:
- Síntesis de imágenes de alta resolución con modelos de difusión latente (CVPR 2022)
- Paleta: modelos de difusión de imagen a imagen (siggraph 2022)
- Imagen Super-Resolución a través del refinamiento iterativo
- Inpenación utilizando modelos probabilísticos de difusión de difusión Denoising (CVPR 2022)
- Agregar control condicional a los modelos de difusión de texto a imagen (ICCV 2023)
Se pueden encontrar más documentos aquí.
Generación de videos
Aquí hay algunos documentos representativos de modelos de difusión para la generación de videos:
- Modelos de difusión de video
- Modelado de difusión flexible de videos largos (Neurips 2022)
- Escala de modelos de difusión de video latente a grandes conjuntos de datos
- I2VGen-XL: síntesis de imagen a video de alta calidad a través de modelos de difusión en cascada
Se pueden encontrar más documentos aquí.
Generación de audio
Aquí hay algunos documentos representativos de modelos de difusión para la generación de audio:
- Grad-TTS: un modelo probabilístico de difusión para texto a voz
- Generación de texto a audio utilizando LLM ajustado de instrucciones y modelo de difusión latente
- Acondicionamiento de voz de disparo cero para modelos de difusión de difusión TTS
- Editts: edición basada en puntaje para texto a voz controlable
- Prodiff: modelo de difusión rápida progresiva para texto a voz de alta calidad
Se pueden encontrar más documentos aquí.
Preventiva y fineta
Similar a otros modelos generativos grandes, los modelos de difusión también están en una gran cantidad de datos web (por ejemplo, el conjunto de datos LAION-5B) y consumen recursos informáticos masivos. Los usuarios pueden descargar los pesos liberados pueden ajustar aún más el modelo en conjuntos de datos personales.
Aquí hay algunos documentos representativos de ajuste fino eficiente de modelos de difusión:
- Dreambooth: modelos de difusión de texto a imagen de ajuste fino para la generación impulsada por el sujeto (CVPR 2023)
- Una imagen vale una palabra: personalizar la generación de texto a imagen utilizando inversión textual (ICLR 2023)
- Difusión personalizada: personalización de múltiples concepto de difusión de texto a imagen (CVPR 2023)
- Control de difusión de texto a imagen por finete ortogonal (Neurips 2023)
Se pueden encontrar más documentos aquí.
Se recomienda practicar algo con la API de difusores de Huggingface.
Evaluación
Aquí hablamos sobre la evaluación de modelos de difusión para la generación de imágenes. Se pueden aplicar muchas métricas existentes de calidad de imagen.
- Puntuación de clip: la puntuación de clip mide la compatibilidad de los pares de aplicación de imagen. Los puntajes de clip más altos implican una mayor compatibilidad. Se descubrió que la puntuación de clip tenía una alta correlación con el juicio humano.
- Distancia de inicio de Fréchet (FID): FID tiene como objetivo medir cuán similares son dos conjuntos de datos de imágenes. Se calcula calculando la distancia de Fréchet entre dos gaussianos equipados para presentar representaciones de la red de inicio
- Similitud direccional de clip: mide la consistencia del cambio entre las dos imágenes (en el espacio de clip) con el cambio entre los dos subtítulos de imagen.
Se pueden encontrar más métricas de calidad de imagen y herramientas de cálculo aquí.
Generación eficiente
Los modelos de difusión requieren múltiples pasos de avance para generar datos, lo cual es costoso. Aquí hay algunos documentos representativos de modelos de difusión para una generación eficiente:
- Tengo que ir rápido al generar datos con modelos basados en puntaje
- Muestreo rápido de modelos de difusión con integrador exponencial
- Aprender muestreadores rápidos para modelos de difusión diferenciando a través de la calidad de la muestra
- Acelerar los modelos de difusión a través de la parada temprana del proceso de difusión
Se pueden encontrar más documentos aquí.
Edición de conocimiento
Aquí hay algunos documentos representativos de edición de conocimiento para modelos de difusión:
- Borrar conceptos de modelos de difusión (ICCV 2023)
- Edición de conceptos masivos en modelos de difusión de texto a imagen
- Forgir-yo-no: aprender a olvidar en modelos de difusión de texto a imagen
Se pueden encontrar más documentos aquí.
Desafíos abiertos
Aquí hay algunos documentos de encuesta que hablan sobre los desafíos que enfrentan los modelos de difusión.
- Una encuesta de modelos de generación de imágenes basados en difusión
- Una encuesta sobre modelos de difusión de video
- Estado del arte en modelos de difusión para computación visual
- Modelos de difusión en PNL: una encuesta
Grandes modelos multimodales (LMM)
Los LMM típicos se construyen conectando y ajustando modelos unimodales previos a los pretrados existentes. Algunos también están previos a la calle desde cero. Verifique cómo evolucionan LMM en la imagen a continuación [fuente de imagen].
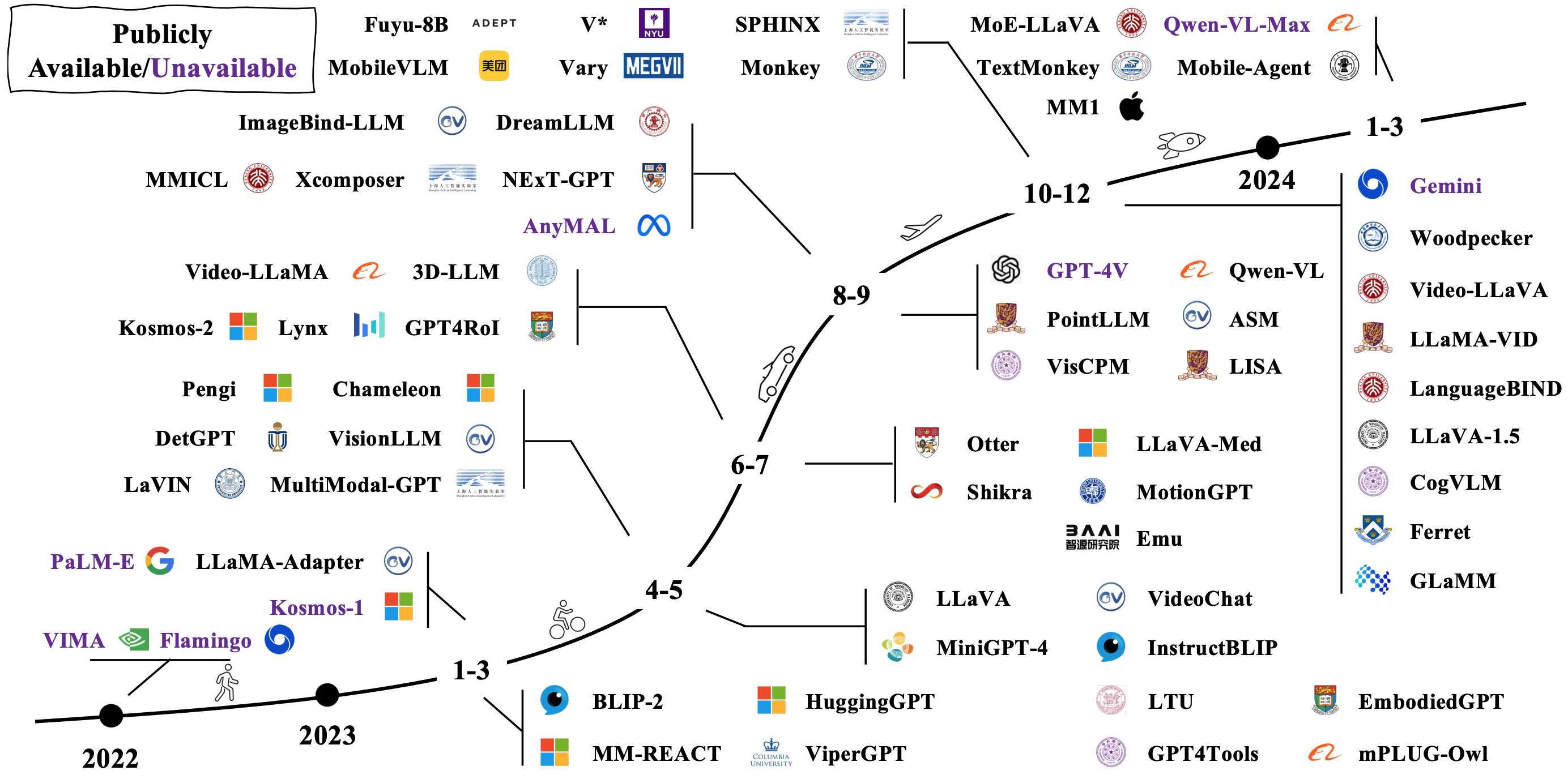
Arquitecturas de modelos
Hay muchas formas diferentes de contratar LMM. Las arquitecturas representativas incluyen:
- Los modelos de idiomas son interfaces de uso general
- Flamingo: un modelo de lenguaje visual para el aprendizaje de pocos disparos (Neurips 2022)
- BLIP: Bootstrapping Language-Image Pretringing para comprensión y generación de lenguaje de visión unificado (ICML 2022)
- BLIP-2: Bootstrapping Language-Image Pretringing con codificadores de imágenes congeladas y modelos de idiomas grandes (ICML 2023)
- MPLUG-BOWL2: Revolucionar el modelo de lenguaje grande multimodal con colaboración de modalidad
- Florence-2: Avance de una representación unificada para una variedad de tareas de visión
- Conector denso para MLLMS
Se pueden encontrar más documentos a través del enlace 1 y el enlace 2.
Hacia agentes encarnados
Al combinar LMM con robots, los investigadores tienen como objetivo desarrollar sistemas de IA que puedan percibir, razonar y actuar sobre el mundo de una manera más natural e intuitiva, con aplicaciones potenciales que abarcan robótica, asistentes virtuales, vehículos autónomos y más allá. Aquí hay algunos trabajos representativos para realizar IA incorporados con LMM:
- RT-1: Transformador de robótica para el control del mundo real a escala
- RT-2: los modelos de acción-lenguaje de visión transfieren el conocimiento web al control robótico
- RT-H: Jerarquías de acción usando el lenguaje
- Palm-E: un modelo de lenguaje multimodal incorporado
- Transico: transferencia de política de sim a Realización de la corrección en línea
Se pueden encontrar más documentos a través del enlace 1 y el enlace 2.
Aquí hay algunos simuladores y conjuntos de datos populares para evaluar el rendimiento de LMMS para la IA incorporada:
- Hábitat 3.0: una plataforma de simulación de IA incorporada para estudiar tareas colaborativas de interacción humana-robot en entornos de hogar
- Procthor-10K: entornos domésticos interactivos de 10k para IA incorporada
- Arnold: un punto de referencia para el aprendizaje de tareas con tierra con estados continuos en escenas 3D realistas
- Legente: plataforma abierta para agentes encarnados
- Robocasa: simulación a gran escala de tareas cotidianas para robots generalistas
Se pueden encontrar más recursos aquí.
Desafíos abiertos
Aquí hay algunos documentos de encuesta que hablan sobre desafíos abiertos para la IA incorporada con LMM: AI:
- El aumento y el potencial de los agentes basados en modelos de idiomas grandes: una encuesta
- Navegación en idioma de visión con inteligencia incorporada: una encuesta
- Una encuesta de IA incorporada: de simuladores a tareas de investigación
- Una encuesta sobre agentes autónomos basados en LLM
- Tormentas mental en sociedades mentales basadas en el lenguaje natural
Más allá de los transformadores
Los investigadores están tratando de explorar nuevos modelos que no sean transformadores. Los esfuerzos incluyen estructurar implícitamente parámetros del modelo y definir arquitecturas de nuevos modelos.
Parámetros implícitamente estructurados
- Mezclador monarca: revisando a Bert, sin atención o MLPS
- Mamba: modelado de secuencia de tiempo lineal con espacios de estado selectivos
Nuevas arquitecturas de modelos
- Jerarquía de hiena: hacia modelos de idiomas convolucionales más grandes
- RWKV: Reinventando RNN para la era del transformador
- Red retentiva: un sucesor para transformador para modelos de idiomas grandes
- Mamba: modelado de secuencia de tiempo lineal con espacios de estado selectivos
- Kan: Kolmogorov -Arnold Networks
- Los transformadores son SSM: modelos generalizados y algoritmos eficientes a través de la dualidad del espacio de estado estructurado
Aquí hay un tutorial increíble para los modelos de espacio estatal.


