Generative AI Tutorial
1.0.0
生成AI研究的主觀學習指南,包括精心策劃的文章和項目清單
生成AI是當今的熱門話題,該路線圖旨在幫助初學者快速獲得基本知識並找到生成AI的有用資源。甚至歡迎專家參考此路線圖,以回憶舊知識並發展新的想法。
本節應幫助您學習或重新獲得神經網絡的基本知識(例如,反向傳播),讓您熟悉變壓器體系結構,並描述一些基於變壓器的模型。
您是否非常熟悉以下經典的神經網絡結構?
如果是這樣,您應該能夠回答以下問題:
反向傳播(BP)是NN培訓的基礎。如果您不了解BP,您將不會成為AI專家。有很多教科書和在線教程教授BP,但不幸的是,其中大多數沒有以矢量化/張力形式呈現公式。 NN層的BP公式確實與其正向通過公式一樣整潔。這正是BP的實施方式,應實現。要了解BP,請閱讀以下材料:
如果您了解BP,則應該能夠回答以下問題:
變壓器是現有大型生成模型的基本體系結構。有必要了解變壓器中的每個組件。請閱讀以下材料:
如果您了解變壓器,則應該能夠回答以下問題:
Einsum很容易且有用[用於使用Einsum/Einops的絕佳教程]
開放性對於人工超人智能(ICML 2024)[關於實現超人AI的想法]至關重要
在AGI路徑上運行進度的AGI水平
LLM是變壓器。它們可以分為僅編碼,編碼器編碼器和僅解碼器的體系結構,如下面的LLM進化樹[Image Source]所示。檢查LLM的里程碑論文。
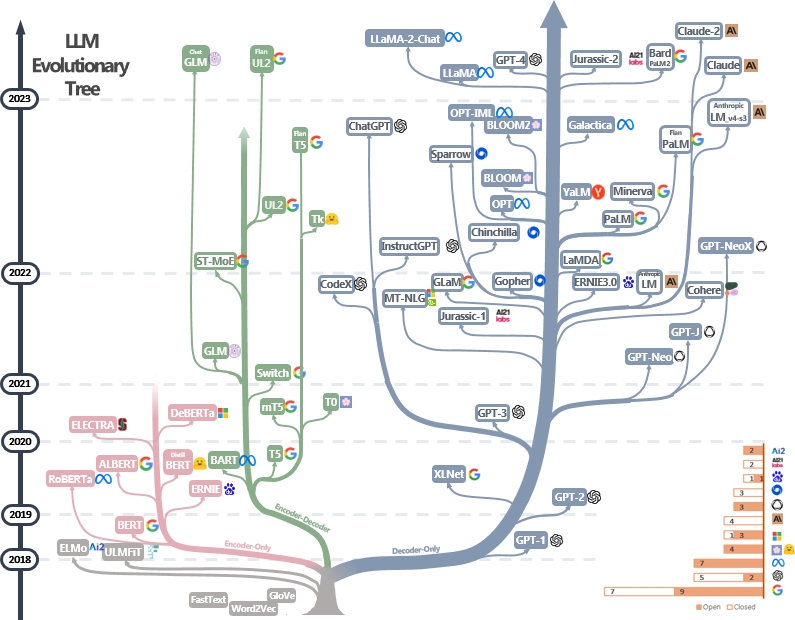
僅編碼模型可用於提取句子特徵,但缺乏生成力。編碼器編碼器和僅解碼器模型用於文本生成。特別是,由於更強的維修能力,大多數現有的LLM都喜歡僅解碼器結構。直觀地,編碼器模型可以視為僅解碼器模型的稀疏版本,並且信息從編碼器到解碼器的衰減更加衰減。檢查本文以獲取更多詳細信息。
LLM通常是從模型出版商內部化自然語言結構內部化的文本令牌中鑑定的。當今的模型開發人員還向人類反饋(RLHF)進行教學微調和強化學習,以教導該模型遵循人類的指示並產生與人類偏愛保持一致的答案。然後,用戶可以下載已發布的模型並在小型個人數據集(例如,電影對話框)上進行Finetune。由於大量數據,預處理需要大量的計算資源(例如,超過數千個GPU),這是個人無法承受的。另一方面,微調少資源不足,可以使用一些GPU來完成。
以下材料可以幫助您了解預處理和微調過程:
可以在這裡找到更多的教程。
提示LLM的技術涉及以指導模型生成所需響應或輸出的方式製作輸入文本。這是幫助您編寫更好的提示的有用資源:
大型語言模型的評估工具有助於評估其跨不同任務和數據集的性能,能力和局限性。以下是一些常見的評估策略:
自動評估指標:這些指標會自動評估模型性能而無需人工干預。常見指標包括:
人類評估:人類判斷對於全面評估生成的文本的質量至關重要。常見的人類評估方法包括:
基準數據集:標準化數據集可以對不同任務和域的模型進行公平比較。示例包括:
模型分析工具:用於分析模型行為和性能的工具包括:
可以在此處找到完整的列表
現有LLM的標準評估框架包括:
由於記憶和處理能力的限制,處理長篇小說對大語言模型構成了挑戰。現有技術包括:
可以在此處找到完整的列表
參數有效的微調(PEFT)方法僅通過微調少量(額外的)模型參數而不是所有模型參數來使大型預審計模型有效地適應各種下游應用程序:
在Huggingface Peft紙收藏中可以找到更多的工作,強烈建議使用HuggingFace Peft API練習。
合併模型是指將兩個或多個在不同任務培訓的LLM合併為單個LLM。該技術旨在利用不同模型的優勢和知識來創建一個更健壯和有能力的模型。例如,可以將代碼生成的LLM和其他用於數學求解的LLM合併在一起,以便合併的模型能夠同時進行代碼生成和數學問題解決。
模型合併很有趣,因為它可以通過非常簡單且廉價的算法有效地實現(例如,模型權重的線性組合)。以下是一些代表性的論文和閱讀材料:
有關模型合併的更多論文可以在此處找到
LLM的加速解碼對於提高推理速度和效率至關重要,尤其是在實時或對潛伏期敏感的應用中。這是加速LLM的解碼過程的一些代表性工作:
可以通過鏈接1和鏈接2找到有關加速LLM解碼的更多工作。
知識編輯旨在有效地修改LLMS行為,例如減少偏見和修訂學到的相關性。它包括許多主題,例如知識本地化和學習。代表性工作包括:
可以在這裡找到更多論文。
通過接受大規模的培訓,LLMS Digest World知識並能夠準確遵循輸入指令。借助這些驚人的功能,LLM可以作為可以自主(和協作)解決複雜任務的代理商發揮作用,或模擬人類的互動。以下是LLM代理的一些代表性論文:
可以在此處找到論文,平台和評估工具的完整列表。
LLMS面臨著研究人員和開發人員積極努力解決的幾個公開挑戰。這些挑戰包括:
可以在此處找到一個完整的列表。
擴散模型旨在近似給定數據域的概率分佈,並提供一種從其近似分佈中生成樣品的方法。他們的目標類似於其他流行的生成模型,例如vae,gan和歸一化的流量。
擴散模型的工作流有兩個過程:
查看此很棒的博客,並在此處找到更多的介紹性教程。擴散模型可用於生成圖像,音頻,視頻等,並且有許多與擴散模型相關的子字段,如下所示[圖像源]:
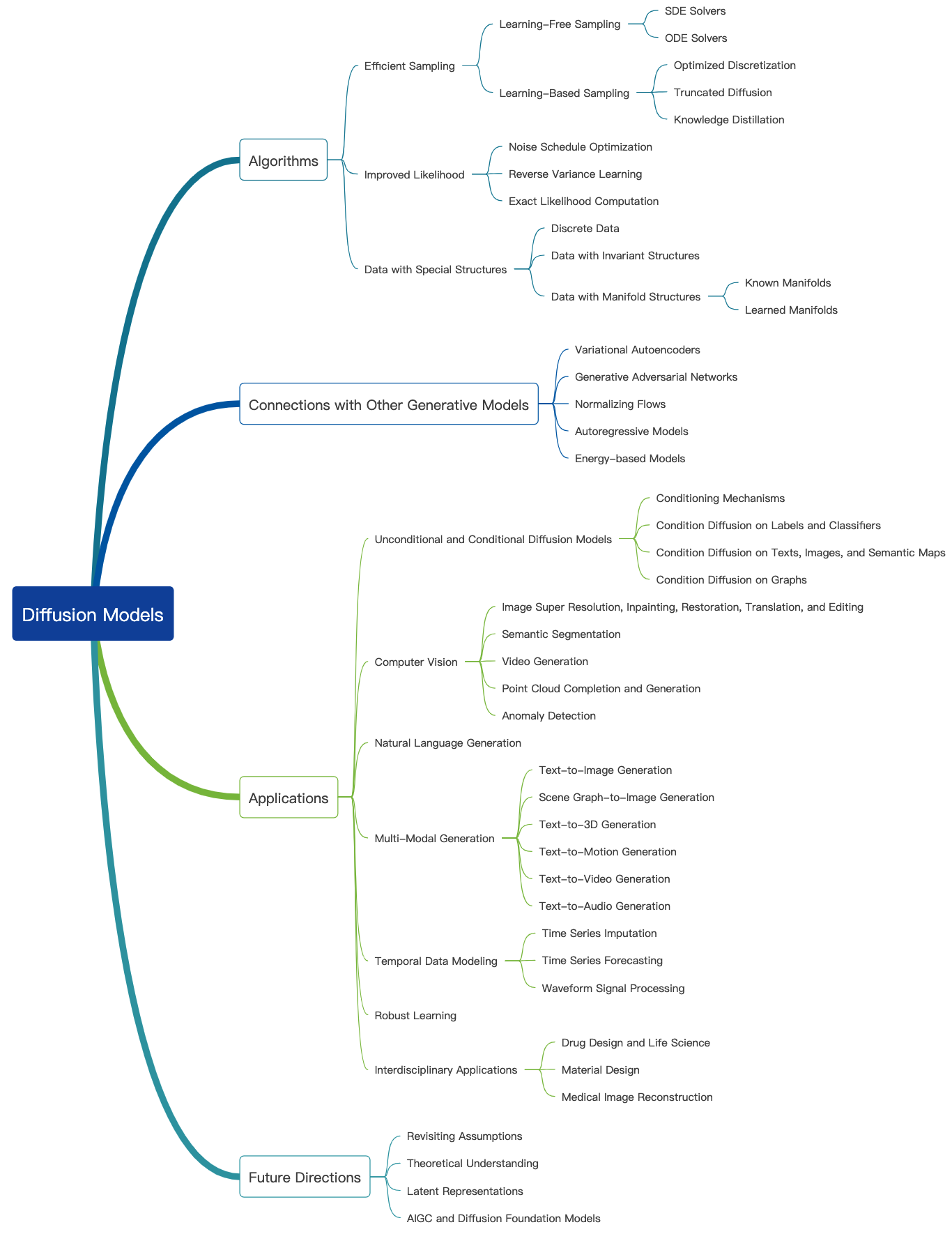
以下是圖像生成的擴散模型的一些代表性論文:
可以在這裡找到更多論文。
以下是一些代表性的傳播模型論文:視頻生成:
可以在這裡找到更多論文。
以下是音頻產生擴散模型的一些代表性論文:
可以在這裡找到更多論文。
與其他大型生成模型類似,擴散模型也在大量的Web數據(例如LAION-5B數據集)上進行了預測,並消耗了大量的計算資源。用戶可以下載發布的權重可以進一步調整個人數據集上的模型。
以下是一些有效微調擴散模型的代表性論文:
可以在這裡找到更多論文。
強烈建議使用HuggingFace擴散器API進行一些練習。
在這裡,我們談論對圖像生成的擴散模型的評估。可以應用許多現有的圖像質量指標。
可以在此處找到更多圖像質量指標和計算工具。
擴散模型需要多個正向步驟以生成昂貴的數據。以下是一些有效產生的擴散模型的代表性論文:
可以在這裡找到更多論文。
以下是一些用於擴散模型的知識編輯的代表性論文:
可以在這裡找到更多論文。
以下是一些調查論文,討論了擴散模型所面臨的挑戰。
典型的LMM是通過連接和微調現有預驗證的單峰模型來構建的。有些也從頭開始審議。檢查LMM在下面的圖像中如何發展[圖像源]。
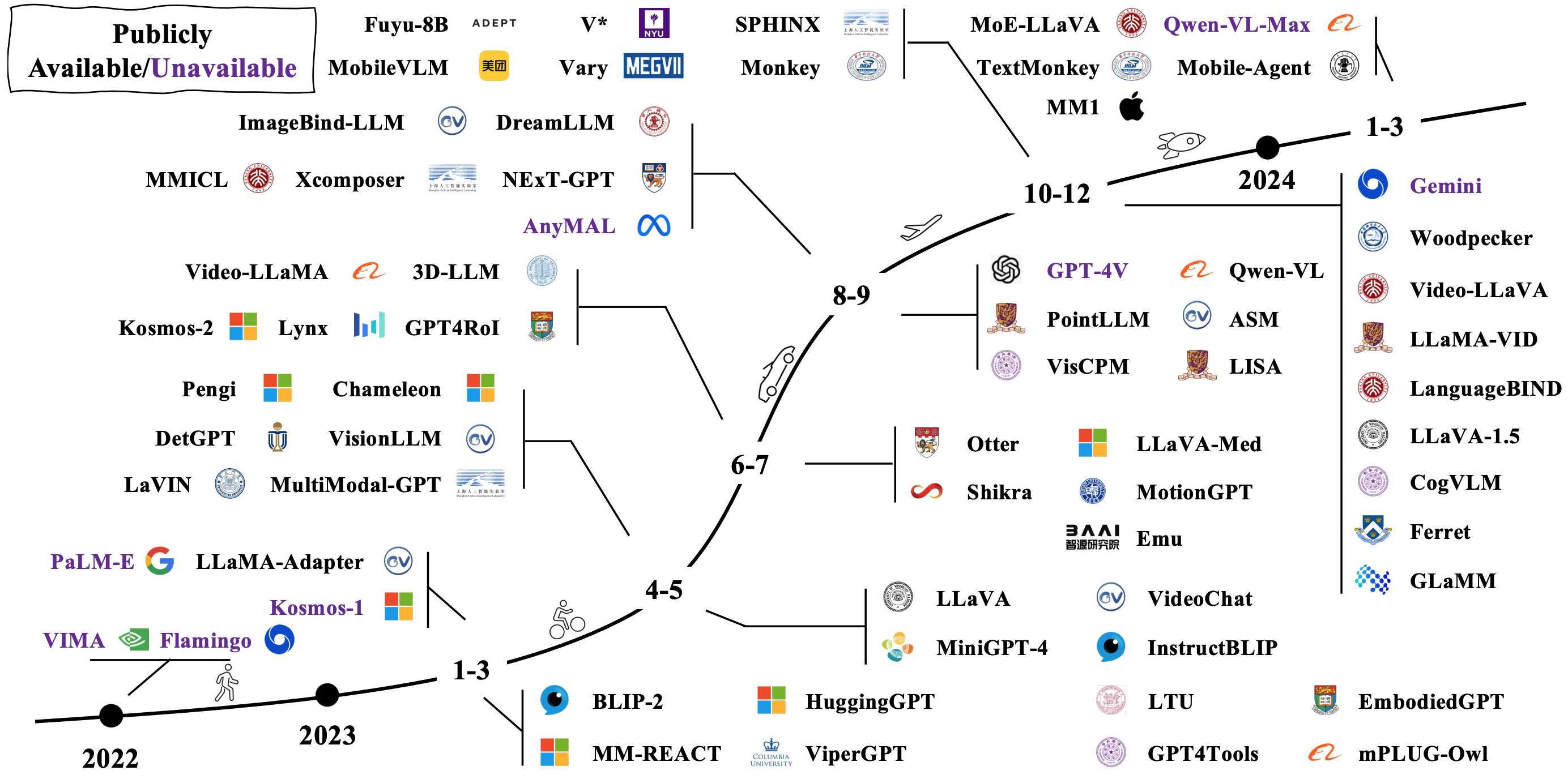
有許多不同的LMM的方法。代表性架構包括:
可以通過鏈接1和鏈接2找到更多論文。
通過將LMM與機器人相結合,研究人員的目標是開發可以以更自然和直觀的方式感知,理性和行動的AI系統,以及涵蓋機器人,虛擬助手,自動駕駛汽車及以後的潛在應用。這是實現LMM體現的AI的一些代表性工作:
可以通過鏈接1和鏈接2找到更多論文。
以下是一些流行的模擬器和數據集,用於評估體現AI的LMMS性能:
可以在這裡找到更多資源。
以下是一些調查論文,討論了針對LMM支持體現的AI的公開挑戰:
研究人員正在嘗試探索除變壓器以外的新模型。努力包括隱式構建模型參數和定義新的模型體系結構。
這是國家空間模型的很棒的教程。


