Generative AI Tutorial
1.0.0
คู่มือการเรียนรู้แบบอัตนัยสำหรับการวิจัย AI แบบกำเนิดรวมถึงรายการบทความและโครงการที่รวบรวมไว้
Generative AI เป็นหัวข้อร้อนแรงในวันนี้และแผนงานนี้ได้รับการออกแบบมาเพื่อช่วยให้ผู้เริ่มต้นได้รับความรู้พื้นฐานอย่างรวดเร็วและค้นหาทรัพยากรที่เป็นประโยชน์ของ AI Generative แม้แต่ผู้เชี่ยวชาญก็ยินดีที่จะอ้างถึงแผนงานนี้เพื่อระลึกถึงความรู้เก่า ๆ และพัฒนาความคิดใหม่ ๆ
ส่วนนี้จะช่วยให้คุณเรียนรู้หรือฟื้นความรู้พื้นฐานของเครือข่ายประสาท (เช่น backpropagation) ช่วยให้คุณคุ้นเคยกับสถาปัตยกรรมหม้อแปลงและอธิบายโมเดลที่ใช้หม้อแปลงทั่วไป
คุณคุ้นเคยกับโครงสร้างเครือข่ายประสาทคลาสสิกต่อไปนี้หรือไม่?
ถ้าเป็นเช่นนั้นคุณควรตอบคำถามเหล่านี้:
Backpropagation (BP) เป็นฐานของการฝึกอบรม NN คุณจะไม่เป็นผู้เชี่ยวชาญ AI หากคุณไม่เข้าใจ BP มีตำราหลายเล่มและแบบฝึกหัดออนไลน์ที่สอน BP แต่น่าเสียดายที่ส่วนใหญ่ไม่ได้นำเสนอสูตรในรูปแบบ vectorized/tensorized สูตร BP ของเลเยอร์ NN นั้นเรียบร้อยเหมือนสูตรการส่งผ่านไปข้างหน้า นี่คือวิธีที่ BP ถูกนำไปใช้และควรนำไปใช้ เพื่อทำความเข้าใจ BP โปรดอ่านเนื้อหาต่อไปนี้:
หากคุณเข้าใจ BP คุณควรตอบคำถามเหล่านี้:
Transformer เป็นสถาปัตยกรรมพื้นฐานของรุ่น Generative ขนาดใหญ่ที่มีอยู่ จำเป็นต้องเข้าใจทุกองค์ประกอบในหม้อแปลง โปรดอ่านวัสดุต่อไปนี้:
หากคุณเข้าใจหม้อแปลงคุณควรตอบคำถามเหล่านี้:
Einsum นั้นง่ายและมีประโยชน์ [บทช่วยสอนที่ยอดเยี่ยมสำหรับการใช้ Einsum/Einops]
ความเปิดกว้างเป็นสิ่งจำเป็นสำหรับหน่วยสืบราชการลับของมนุษย์เทียม (ICML 2024) [ความคิดเกี่ยวกับการบรรลุ AI Superhuman AI]
ระดับของ AGI สำหรับการดำเนินงานความคืบหน้าบนเส้นทางสู่ AGI
LLMS เป็นหม้อแปลง พวกเขาสามารถแบ่งออกเป็น encoder-only, encoder-decoder และสถาปัตยกรรมถอดรหัสเท่านั้นดังที่แสดงในต้นไม้วิวัฒนาการ LLM ด้านล่าง [แหล่งที่มาของภาพ] ตรวจสอบเอกสารสำคัญของ LLMS
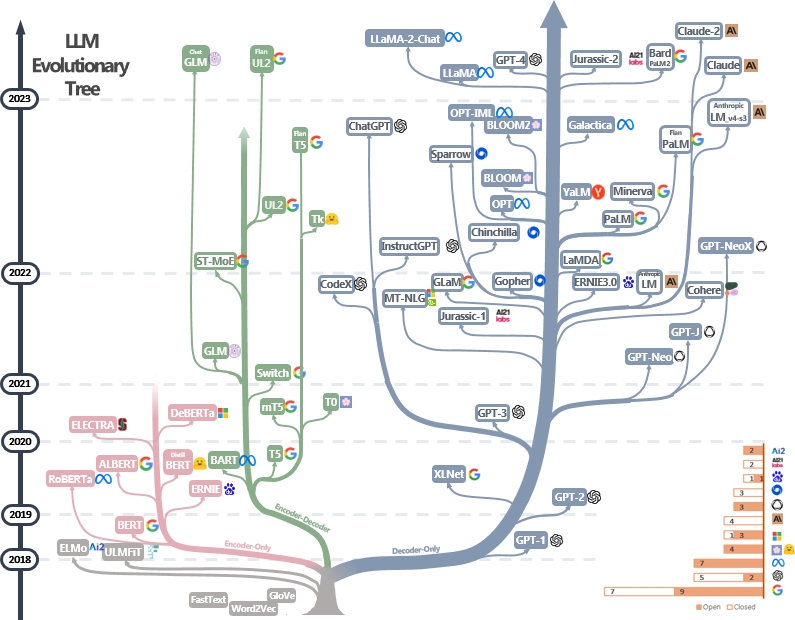
รุ่นเข้ารหัสอย่างเดียวสามารถใช้ในการแยกคุณสมบัติประโยค แต่ขาดพลังกำเนิด รุ่นเข้ารหัสและตัวถอดรหัสเท่านั้นใช้สำหรับการสร้างข้อความ โดยเฉพาะอย่างยิ่ง LLM ที่มีอยู่ส่วนใหญ่ชอบโครงสร้างตัวถอดรหัสเท่านั้นเนื่องจากพลังที่แข็งแกร่งขึ้น แบบจำลองการเข้ารหัสเครื่องประดับสามารถพิจารณาได้ว่าเป็นรุ่นถอดรหัสแบบเบาบางเท่านั้นและข้อมูลจะสลายตัวมากขึ้นจากตัวเข้ารหัสไปยังตัวถอดรหัส ตรวจสอบบทความนี้สำหรับรายละเอียดเพิ่มเติม
โดยทั่วไปแล้ว LLMs จะได้รับการปรับแต่งจากโทเค็นข้อความหลายล้านล้านโดยผู้เผยแพร่แบบจำลองเพื่อกำหนดโครงสร้างภาษาธรรมชาติภายใน นักพัฒนาโมเดลในปัจจุบันยังดำเนินการปรับแต่งการเรียนการสอนและการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ (RLHF) เพื่อสอนแบบจำลองเพื่อทำตามคำแนะนำของมนุษย์และสร้างคำตอบที่สอดคล้องกับความชอบของมนุษย์ จากนั้นผู้ใช้สามารถดาวน์โหลดโมเดลที่เผยแพร่และ finetune บนชุดข้อมูลส่วนบุคคลขนาดเล็ก (เช่นกล่องโต้ตอบภาพยนตร์) เนื่องจากข้อมูลจำนวนมากการเตรียมการต้องใช้ทรัพยากรการคำนวณขนาดใหญ่ (เช่น GPU มากกว่าพัน) ซึ่งบุคคลไม่สามารถสั่งซื้อได้ ในทางกลับกันการปรับจูนเป็นทรัพยากรที่หิวน้อยลงและสามารถทำได้ด้วย GPU สองสามตัว
วัสดุต่อไปนี้สามารถช่วยให้คุณเข้าใจกระบวนการปรับแต่งและปรับแต่ง:
บทเรียนเพิ่มเติมสามารถพบได้ที่นี่
เทคนิคการแจ้งเตือนสำหรับ LLMs เกี่ยวข้องกับการสร้างข้อความอินพุตในลักษณะที่เป็นแนวทางในการสร้างแบบจำลองเพื่อสร้างการตอบสนองหรือเอาต์พุตที่ต้องการ นี่คือแหล่งข้อมูลที่มีประโยชน์ที่จะช่วยให้คุณเขียนพรอมต์ได้ดีขึ้น:
เครื่องมือประเมินผลสำหรับแบบจำลองภาษาขนาดใหญ่ช่วยประเมินประสิทธิภาพความสามารถและข้อ จำกัด ของงานและชุดข้อมูลที่แตกต่างกัน นี่คือกลยุทธ์การประเมินทั่วไป:
ตัวชี้วัดการประเมินอัตโนมัติ : ตัวชี้วัดเหล่านี้ประเมินประสิทธิภาพของแบบจำลองโดยอัตโนมัติโดยไม่ต้องแทรกแซงมนุษย์ ตัวชี้วัดทั่วไป ได้แก่ :
การประเมินผลของมนุษย์ : การตัดสินของมนุษย์เป็นสิ่งจำเป็นสำหรับการประเมินคุณภาพของข้อความที่สร้างขึ้นอย่างครอบคลุม วิธีการประเมินผลของมนุษย์ทั่วไป ได้แก่ :
ชุดข้อมูลมาตรฐาน : ชุดข้อมูลมาตรฐานเปิดใช้งานการเปรียบเทียบแบบจำลองที่เป็นธรรมในงานและโดเมนที่แตกต่างกัน ตัวอย่าง ได้แก่ :
เครื่องมือวิเคราะห์แบบจำลอง: เครื่องมือสำหรับการวิเคราะห์พฤติกรรมและประสิทธิภาพของแบบจำลองรวมถึง:
รายการที่สมบูรณ์สามารถพบได้ที่นี่
กรอบการประเมินมาตรฐานสำหรับ LLM ที่มีอยู่รวมถึง:
การจัดการกับบริบทที่ยาวนานทำให้เกิดความท้าทายสำหรับแบบจำลองภาษาขนาดใหญ่เนื่องจากข้อ จำกัด ในหน่วยความจำและความสามารถในการประมวลผล เทคนิคที่มีอยู่รวมถึง:
รายการที่สมบูรณ์สามารถพบได้ที่นี่
วิธีการปรับแต่งพารามิเตอร์-ประสิทธิภาพ (PEFT) ช่วยให้การปรับตัวอย่างมีประสิทธิภาพของโมเดลที่ผ่านการฝึกอบรมขนาดใหญ่เข้ากับแอพพลิเคชั่นดาวน์สตรีมที่หลากหลายโดยการปรับค่าพารามิเตอร์รุ่น (พิเศษ) จำนวนเล็กน้อยแทนพารามิเตอร์ของโมเดลทั้งหมด:
สามารถพบงานได้มากขึ้นในคอลเล็กชั่นกระดาษ Peft ของ Huggingface และขอแนะนำให้ฝึกฝนกับ Huggingface Peft API
การรวมแบบจำลองหมายถึงการรวม LLM สองตัวขึ้นไปที่ได้รับการฝึกฝนเกี่ยวกับงานที่แตกต่างกันใน LLM เดียว เทคนิคนี้มีจุดมุ่งหมายเพื่อใช้ประโยชน์จากจุดแข็งและความรู้ของโมเดลที่แตกต่างกันเพื่อสร้างแบบจำลองที่แข็งแกร่งและมีความสามารถมากขึ้น ตัวอย่างเช่น LLM สำหรับการสร้างรหัสและ LLM อื่นสำหรับการแก้ปัญหาทางคณิตศาสตร์สามารถรวมเข้าด้วยกันเพื่อให้โมเดลที่ผสานมีความสามารถในการสร้างทั้งการสร้างรหัสและการแก้ปัญหาทางคณิตศาสตร์
การรวมแบบจำลองนั้นน่าสนใจเพราะสามารถทำได้อย่างมีประสิทธิภาพด้วยอัลกอริทึมที่ง่ายและราคาถูก (เช่นการรวมกันเชิงเส้นของน้ำหนักแบบจำลอง) นี่คือเอกสารตัวแทนและสื่อการอ่าน:
เอกสารเพิ่มเติมเกี่ยวกับการรวมแบบจำลองสามารถพบได้ที่นี่
การเร่งการถอดรหัส LLM เป็นสิ่งสำคัญสำหรับการปรับปรุงความเร็วและประสิทธิภาพการอนุมานโดยเฉพาะอย่างยิ่งในการใช้งานแบบเรียลไทม์หรือเวลาแฝง นี่คืองานตัวแทนบางอย่างในการเร่งกระบวนการถอดรหัส LLMS:
งานเพิ่มเติมเกี่ยวกับการเร่งการถอดรหัส LLM สามารถพบได้ผ่าน Link 1 และ Link 2
การแก้ไขความรู้มีวัตถุประสงค์เพื่อปรับเปลี่ยนพฤติกรรม LLMS อย่างมีประสิทธิภาพเช่นการลดอคติและแก้ไขความสัมพันธ์ที่เรียนรู้ มันมีหัวข้อมากมายเช่นการแปลความรู้และการไม่ได้รับ งานตัวแทนรวมถึง:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
ด้วยการได้รับการฝึกอบรมขนาดใหญ่ LLMS จะย่อยความรู้ระดับโลกและสามารถทำตามคำแนะนำการป้อนข้อมูลได้อย่างแม่นยำ ด้วยความสามารถที่น่าทึ่งเหล่านี้ LLM สามารถเล่นเป็นตัวแทนที่เป็นไปได้ที่จะแก้ปัญหาที่ซับซ้อน (และร่วมมือกัน) อย่างอิสระหรือจำลองการปฏิสัมพันธ์ของมนุษย์ นี่คือเอกสารตัวแทนของตัวแทน LLM:
สามารถดูรายการเอกสารแพลตฟอร์มและเครื่องมือประเมินผลได้ที่นี่
LLMS เผชิญกับความท้าทายที่เปิดกว้างหลายประการที่นักวิจัยและนักพัฒนากำลังทำงานอย่างแข็งขัน ความท้าทายเหล่านี้รวมถึง:
รายการที่สมบูรณ์สามารถพบได้ที่นี่
แบบจำลองการแพร่กระจายมีจุดมุ่งหมายเพื่อประมาณการกระจายความน่าจะเป็นของโดเมนข้อมูลที่กำหนดและให้วิธีการสร้างตัวอย่างจากการแจกแจงโดยประมาณ เป้าหมายของพวกเขาคล้ายกับรุ่นที่ได้รับความนิยมอื่น ๆ เช่น vae, gans และการไหลเป็นมาตรฐาน
การทำงานของแบบจำลองการแพร่กระจายนั้นมีสองกระบวนการ:
ตรวจสอบบล็อกที่ยอดเยี่ยมนี้และบทเรียนเบื้องต้นเพิ่มเติมสามารถพบได้ที่นี่ โมเดลการแพร่สามารถใช้ในการสร้างภาพเสียงวิดีโอและอื่น ๆ และมีฟิลด์ย่อยมากมายที่เกี่ยวข้องกับโมเดลการแพร่กระจายดังที่แสดงด้านล่าง [แหล่งที่มาของภาพ]:
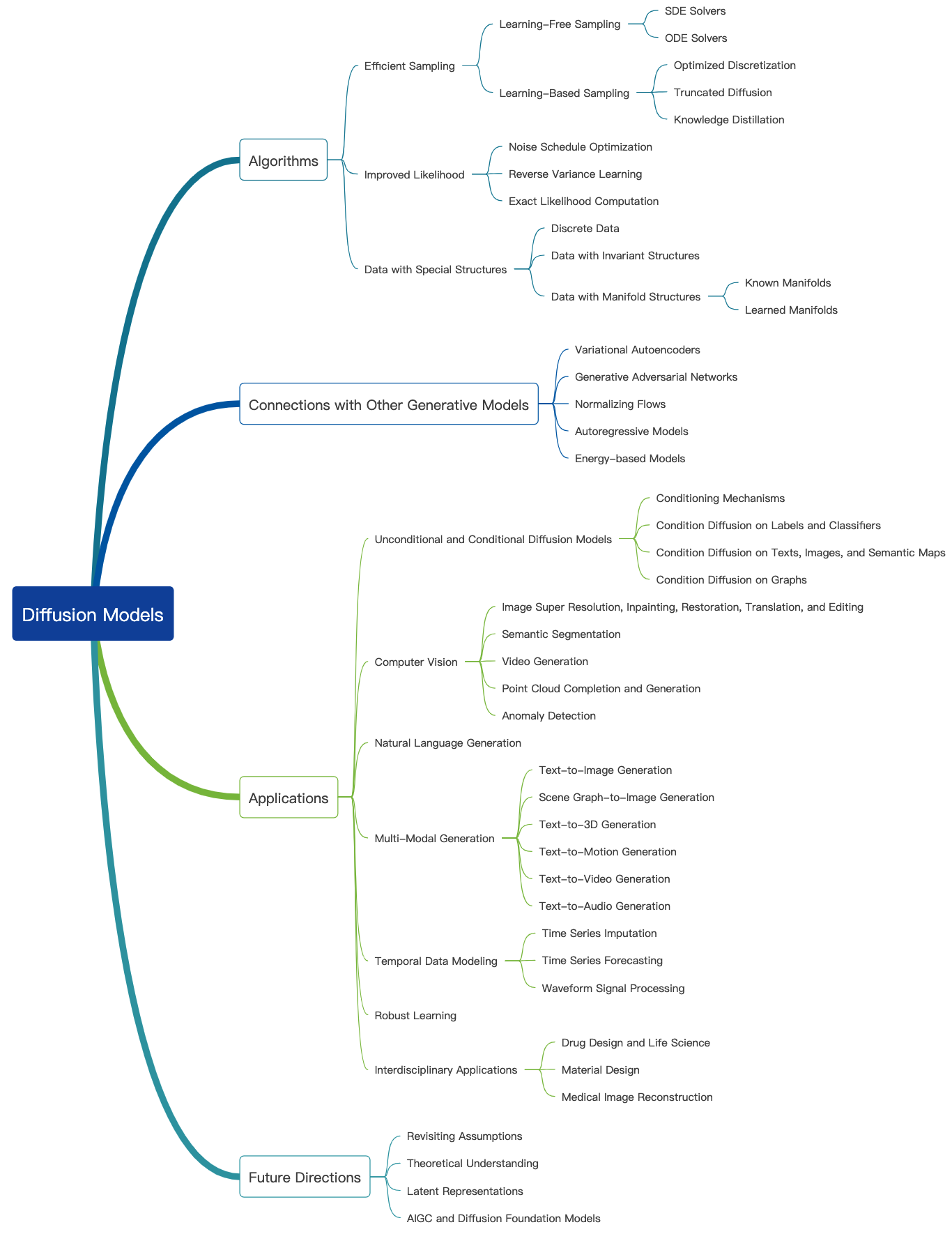
นี่คือเอกสารตัวแทนของแบบจำลองการแพร่กระจายสำหรับการสร้างภาพ:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
นี่คือเอกสารตัวแทนของแบบจำลองการแพร่กระจายสำหรับการสร้างวิดีโอ:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
นี่คือเอกสารตัวแทนของแบบจำลองการแพร่กระจายสำหรับการสร้างเสียง:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
เช่นเดียวกับรุ่นที่มีขนาดใหญ่อื่น ๆ แบบจำลองการแพร่กระจายยังได้รับการปรับแต่งเกี่ยวกับข้อมูลเว็บจำนวนมาก (เช่นชุดข้อมูล LAION-5B) และใช้ทรัพยากรการคำนวณจำนวนมาก ผู้ใช้สามารถดาวน์โหลดน้ำหนักที่ปล่อยออกมาสามารถปรับแต่งโมเดลบนชุดข้อมูลส่วนบุคคลได้อีก
นี่คือเอกสารตัวแทนบางส่วนของการปรับแต่งแบบจำลองการแพร่กระจายอย่างมีประสิทธิภาพ:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
ขอแนะนำอย่างยิ่งให้ฝึกซ้อมกับ Huggingface diffusers API
ที่นี่เราพูดถึงการประเมินแบบจำลองการแพร่กระจายสำหรับการสร้างภาพ ตัวชี้วัดคุณภาพของภาพที่มีอยู่จำนวนมากสามารถใช้งานได้
ตัวชี้วัดคุณภาพและเครื่องมือการคำนวณคุณภาพเพิ่มเติมสามารถพบได้ที่นี่
แบบจำลองการแพร่กระจายต้องใช้หลายขั้นตอนไปข้างหน้าเพื่อสร้างข้อมูลซึ่งมีราคาแพง นี่คือเอกสารตัวแทนของแบบจำลองการแพร่กระจายสำหรับการสร้างที่มีประสิทธิภาพ:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
นี่คือเอกสารตัวแทนของการแก้ไขความรู้สำหรับแบบจำลองการแพร่กระจาย:
เอกสารเพิ่มเติมสามารถพบได้ที่นี่
นี่คือเอกสารสำรวจบางส่วนที่พูดถึงความท้าทายที่ต้องเผชิญกับรูปแบบการแพร่กระจาย
LMM ทั่วไปถูกสร้างขึ้นโดยการเชื่อมต่อและปรับแต่งแบบจำลอง Unimodal ที่มีอยู่ก่อนหน้านี้ บางคนยังได้รับการปรับสภาพตั้งแต่เริ่มต้น ตรวจสอบว่า LMMs พัฒนาอย่างไรในภาพด้านล่าง [แหล่งที่มาของภาพ]
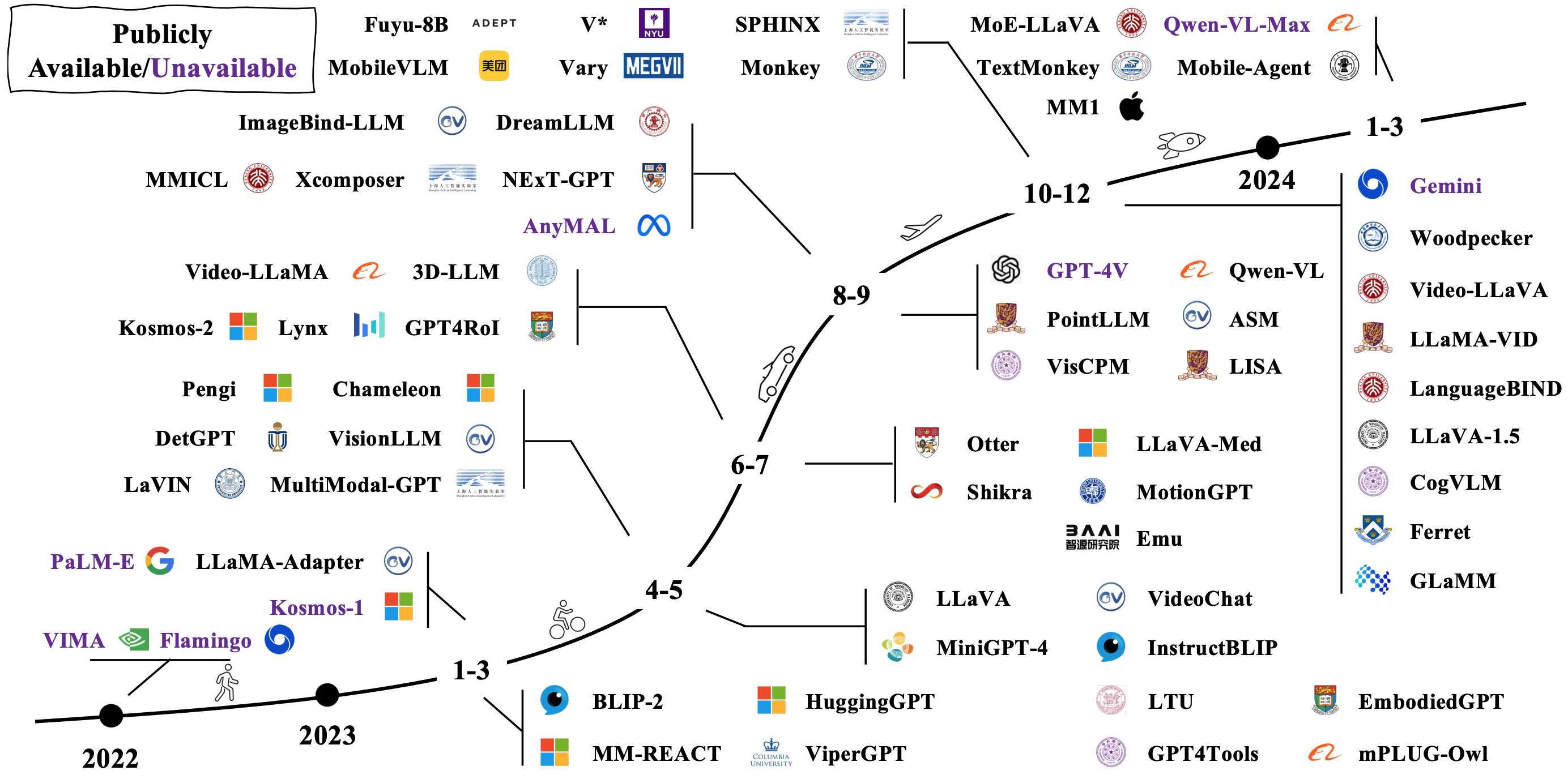
มีวิธีการที่แตกต่างกันในการสื่อสาร LMMs สถาปัตยกรรมตัวแทน ได้แก่ :
เอกสารเพิ่มเติมสามารถพบได้ผ่าน Link 1 และ Link 2
โดยการรวม LMMs เข้ากับหุ่นยนต์นักวิจัยมุ่งมั่นที่จะพัฒนาระบบ AI ที่สามารถรับรู้เหตุผลเกี่ยวกับและดำเนินการกับโลกในวิธีที่เป็นธรรมชาติและใช้งานง่ายมากขึ้นด้วยการใช้งานที่มีศักยภาพซึ่งครอบคลุมหุ่นยนต์ผู้ช่วยเสมือนยานพาหนะอิสระและอื่น ๆ นี่คืองานตัวแทนบางส่วนของการตระหนักถึง AI embodied ด้วย LMMs:
เอกสารเพิ่มเติมสามารถพบได้ผ่าน Link 1 และ Link 2
นี่คือเครื่องจำลองและชุดข้อมูลยอดนิยมเพื่อประเมินประสิทธิภาพ LMMS สำหรับ AI embodied:
แหล่งข้อมูลเพิ่มเติมสามารถพบได้ที่นี่
นี่คือเอกสารสำรวจบางส่วนที่พูดถึงความท้าทายแบบเปิดสำหรับ AI embodied AI ที่เปิดใช้งาน LMM:
นักวิจัยกำลังพยายามสำรวจรุ่นใหม่นอกเหนือจากหม้อแปลง ความพยายามรวมถึงพารามิเตอร์แบบจำลองการจัดโครงสร้างโดยปริยายและกำหนดสถาปัตยกรรมโมเดลใหม่
นี่คือบทช่วยสอนที่ยอดเยี่ยมสำหรับแบบจำลองพื้นที่ของรัฐ


