nexa sdk
v0.0.9.7
Hub de modèle sur périphérique | Documentation | Discorde | Blogs | X (Twitter)
NEXA SDK est un cadre d'inférence local sur les appareils pour les modèles ONNX et GGML, prenant en charge la génération de texte, la génération d'images, les modèles de vision (VLM), les modèles audio-language, les capacités de parole en texte (ASR) et de texte à dispection (TTS). Installable via le package Python ou le programme d'installation exécutable.
nexa run omniVLM et Modèle de langage audio (paramètres 2.9b): nexa run omniaudionexa run qwen2audio , nous sommes la première boîte à outils open source pour prendre en charge le modèle de langage audio avec la bibliothèque de tenseur GGML.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION ou nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP ou nexa run -ms <ms_model_id> -mt NLPBienvenue pour soumettre vos demandes par le biais de problèmes, nous expédions chaque semaine.
 installateur de macOS
installateur de macOS
 Windows Installation
Windows Installation
 Installateur Linux
Installateur Linux
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Essayez d'utiliser nexa-exe à la place:
nexa-exe < command > Nous avons publié des roues pré-construites pour diverses versions, plates-formes et backends Python pour une installation pratique sur notre page d'index.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirPour la version GPU, support du métal (macOS) :
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirEssayez la commande suivante:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirPour installer avec le support CUDA, assurez-vous que la boîte à outils CUDA 12.0 ou ultérieurement installée.
Pour Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPour Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPour l'invite de commande Windows :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPour Windows Git Bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirSi vous rencontrez le problème suivant pendant la construction:
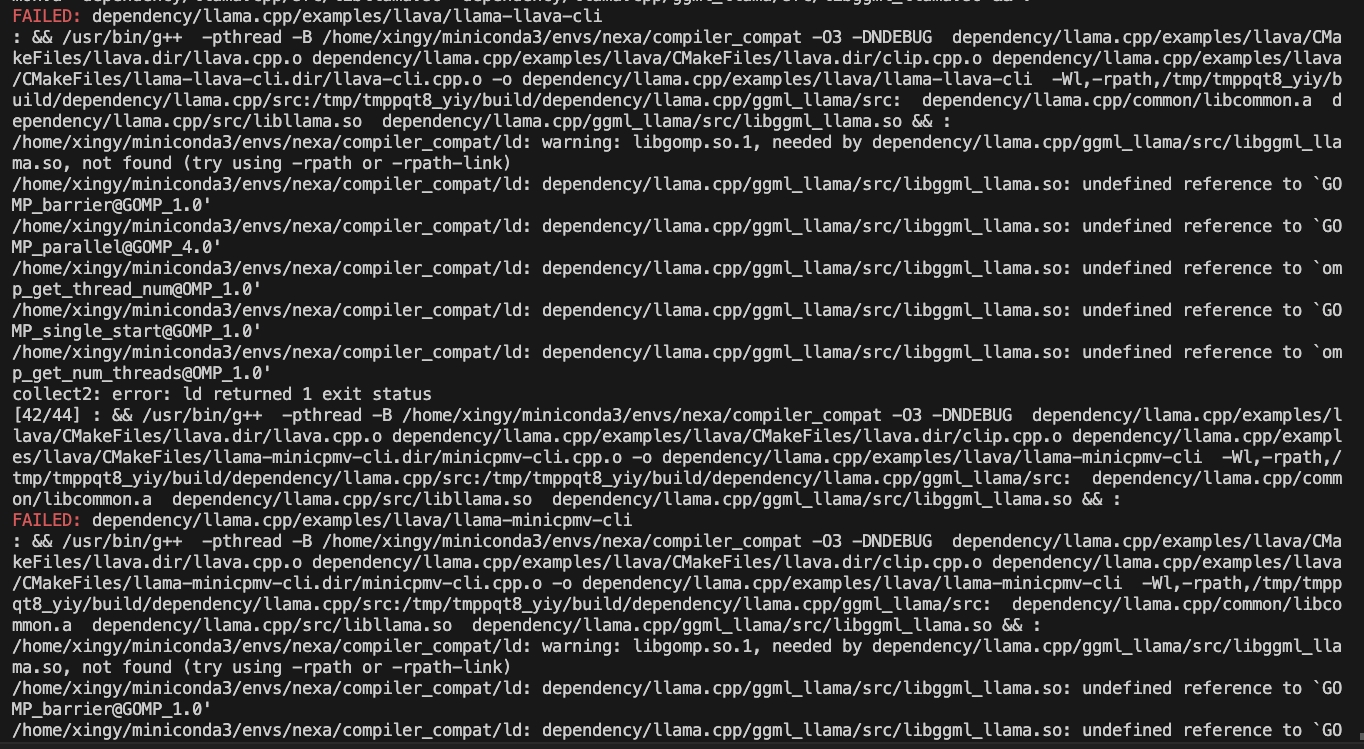
Essayez la commande suivante:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiPour installer avec la prise en charge ROCM, assurez-vous que ROCM 6.2.1 ou ultérieurement installé.
Pour Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirPour installer avec le support Vulkan, assurez-vous que le SDK Vulkan 1.3.261.1 ou installé ultérieur.
Pour Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPour l'invite de commande Windows :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPour Windows Git Bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirComment cloner ce repo
git clone --recursive https://github.com/NexaAI/nexa-sdk Si vous oubliez d'utiliser --recursive , vous pouvez utiliser la commande ci-dessous pour ajouter le sous-module
git submodule update --init --recursiveEnsuite, vous pouvez créer et installer le package
pip install -e . Vous trouverez ci-dessous notre différenciation des autres outils similaires:
| Fonctionnalité | SDK NEXA | ollla | Optimum | Studio LM |
|---|---|---|---|---|
| Support GGML | ✅ | ✅ | ✅ | |
| Assistance ONNX | ✅ | ✅ | ||
| Génération de texte | ✅ | ✅ | ✅ | ✅ |
| Génération d'images | ✅ | |||
| Modèles de langue de vision | ✅ | ✅ | ✅ | ✅ |
| Modèles de langue audio | ✅ | |||
| Texte vocal | ✅ | ✅ | ||
| Capacité du serveur | ✅ | ✅ | ✅ | ✅ |
| Interface utilisateur | ✅ | ✅ | ||
| Installation exécutable | ✅ | ✅ | ✅ |
Notre hub de modèles à disque propose tous les types de modèles quantifiés (texte, image, audio, multimodal) avec des filtres pour la RAM, la taille du fichier, les tâches, etc. pour vous aider à explorer facilement des modèles avec une interface utilisateur. Explorez les modèles sur les appareils sur Hub sur le modèle sur les appareils
Exemples de modèle pris en charge (liste complète sur Model Hub):
| Modèle | Taper | Format | Commande |
|---|---|---|---|
| omnidudio | Audiolm | Gguf | nexa run omniaudio |
| Qwen2Audio | Audiolm | Gguf | nexa run qwen2audio |
| Octopus-V2 | Appel de fonction | Gguf | nexa run octopus-v2 |
| octo-net | Texte | Gguf | nexa run octo-net |
| omnivlm | Multimodal | Gguf | nexa run omniVLM |
| nanollava | Multimodal | Gguf | nexa run nanollava |
| llava-phi3 | Multimodal | Gguf | nexa run llava-phi3 |
| llavallama3 | Multimodal | Gguf | nexa run llava-llama3 |
| llava1.6-mistral | Multimodal | Gguf | nexa run llava1.6-mistral |
| llava1.6-vicuna | Multimodal | Gguf | nexa run llava1.6-vicuna |
| lama3.2 | Texte | Gguf | nexa run llama3.2 |
| LLAMA3-ancré | Texte | Gguf | nexa run llama3-uncensored |
| gemma2 | Texte | Gguf | nexa run gemma2 |
| qwen2.5 | Texte | Gguf | nexa run qwen2.5 |
| mathqwen | Texte | Gguf | nexa run mathqwen |
| codeqwen | Texte | Gguf | nexa run codeqwen |
| mistral | Texte | GGUF / ONNX | nexa run mistral |
| coder en profondeur | Texte | Gguf | nexa run deepseek-coder |
| phi3.5 | Texte | Gguf | nexa run phi3.5 |
| ouvrir | Texte | Gguf | nexa run openelm |
| stable-diffusion-v2-1 | Génération d'images | Gguf | nexa run sd2-1 |
| stable-diffusion-3-médium | Génération d'images | Gguf | nexa run sd3 |
| Flux.1-Schnell | Génération d'images | Gguf | nexa run flux |
| lcm-dreamhaper | Génération d'images | GGUF / ONNX | nexa run lcm-dreamshaper |
| chuchotement-v3-turbo | Discours à texte | Bac | nexa run faster-whisper-large-turbo |
| whisper-tiny.en | Discours à texte | Onnx | nexa run whisper-tiny.en |
| MXBAI-EMBED-LANG-V1 | Intégration | Gguf | nexa embed mxbai |
| Nomic-Embed-Text-V1.5 | Intégration | Gguf | nexa embed nomic |
| All-Minilm-L12-V2 | Intégration | Gguf | nexa embed all-MiniLM-L12-v2:fp16 |
| écorce | Texte vocal | Gguf | nexa run bark-small:fp16 |
Vous pouvez extraire, convertir (en .gguf), quantifier et exécuter les modèles de génération de texte pris en charge Llama.cpp à partir de HF ou MS avec SDK NEXA.
Utilisez nexa run -hf <hf-model-id> ou nexa run -ms <ms-model-id> Pour exécuter des modèles avec des fichiers .gguf fournis:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFRemarque: vous serez invité à sélectionner un seul fichier .gguf. Si votre version de quantification souhaitée dispose de plusieurs fichiers fendus (comme FP16-00001-OF-00004), veuillez utiliser l'outil de conversion de NEXA (voir ci-dessous) pour convertir et quantifier le modèle localement.
Installez le package NEXA Python et installez l'outil de conversion NEXA avec pip install "nexaai[convert]" , puis convertissant les modèles à partir de HuggingFace avec nexa convert <hf-model-id> :
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct Ou vous pouvez convertir des modèles à partir de modèles avec nexa convert -ms <ms-model-id> :
nexa convert -ms Qwen/Qwen2.5-7B-InstructRemarque: Vérifiez notre classement pour les références de performances de différentes versions quantifiées des modèles de langage traditionnel et des documents de câlins pour en savoir plus sur les options de quantification.
? Vous pouvez afficher des modèles téléchargés et convertis avec nexa list
Note
pip install nexaai par pip install "nexaai[onnx]" dans les commandes fournies.pip install nexaai par pip install "nexaai[eval]" dans les commandes fournies.pip install nexaai par pip install "nexaai[convert]" dans les commandes fournies.--extra-index-url https://pypi.org/simple par --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple dans les commandes fournies.Voici un bref aperçu des principales commandes CLI:
nexa run : exécutez l'inférence pour diverses tâches à l'aide de modèles GGUF.nexa onnx : exécutez l'inférence pour diverses tâches à l'aide de modèles ONNX.nexa convert : Convertit et quantifiez les modèles HuggingFace en modèles GGUF.nexa server : Exécutez le service de génération de texte NEXA AI.nexa eval : Exécutez les tâches d'évaluation NEXA AI.nexa pull : Tirez un modèle d'officiel ou de centre.nexa remove : Retirez un modèle de la machine locale.nexa clean : Nettoyez tous les fichiers du modèle.nexa list : LISTER TOUS les modèles dans la machine locale.nexa login : Connectez-vous à l'API NEXA.nexa whoami : Afficher les informations actuelles de l'utilisateur.nexa logout : Connexion à partir de l'API NEXA.Pour des informations détaillées sur les commandes et l'utilisation CLI, veuillez vous référer au document de référence CLI.
Pour démarrer un serveur local à l'aide de modèles sur votre ordinateur local, vous pouvez utiliser la commande nexa server . Pour des informations détaillées sur la configuration du serveur, les points de terminaison de l'API et les exemples d'utilisation, veuillez vous référer au document de référence du serveur.
SWIFT SDK: fournit une API Swifty, permettant aux développeurs Swift d'intégrer facilement et d'utiliser les modèles LLAMA.CPP dans leurs projets.
Plus de documents
Nous tenons à remercier les projets suivants:


