nexa sdk
v0.0.9.7
Hub de modelo no dispositivo | Documentação | Discord | Blogs | X (Twitter)
O Nexa SDK é uma estrutura local de inferência no dispositivo para modelos ONNX e GGML, suportando geração de texto, geração de imagens, modelos de linguagem de visão (VLM), modelos de linguagem de áudio, texto para texto (ASR) e capacidades de texto para falar (TTS). Instalável via pacote python ou instalador executável.
nexa run omniVLM e Modelo de Linguagem de Áudio (parâmetros 2.9b): nexa run omniaudionexa run qwen2audio , somos o primeiro kit de ferramentas de código aberto a oferecer suporte ao modelo de idioma de áudio com a biblioteca GGML Tensor.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION ou nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP ou nexa run -ms <ms_model_id> -mt NLPBem -vindo a enviar seus pedidos por meio de problemas, enviamos semanalmente.
 instalador de macos
instalador de macos
 Instalador do Windows
Instalador do Windows
 Instalador Linux
Instalador Linux
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Tente usar nexa-exe em vez disso:
nexa-exe < command > Lançamos rodas pré-construídas para várias versões, plataformas e backnds do Python para instalação conveniente em nossa página de índice.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirPara a versão GPU que suporta Metal (MacOS) :
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirExperimente o seguinte comando:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirPara instalar com o suporte do CUDA, verifique se você possui o CUDA Toolkit 12.0 ou posteriormente instalado.
Para Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara o prompt de comando do Windows :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows Git Bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirSe você encontrar a questão a seguir durante a criação:
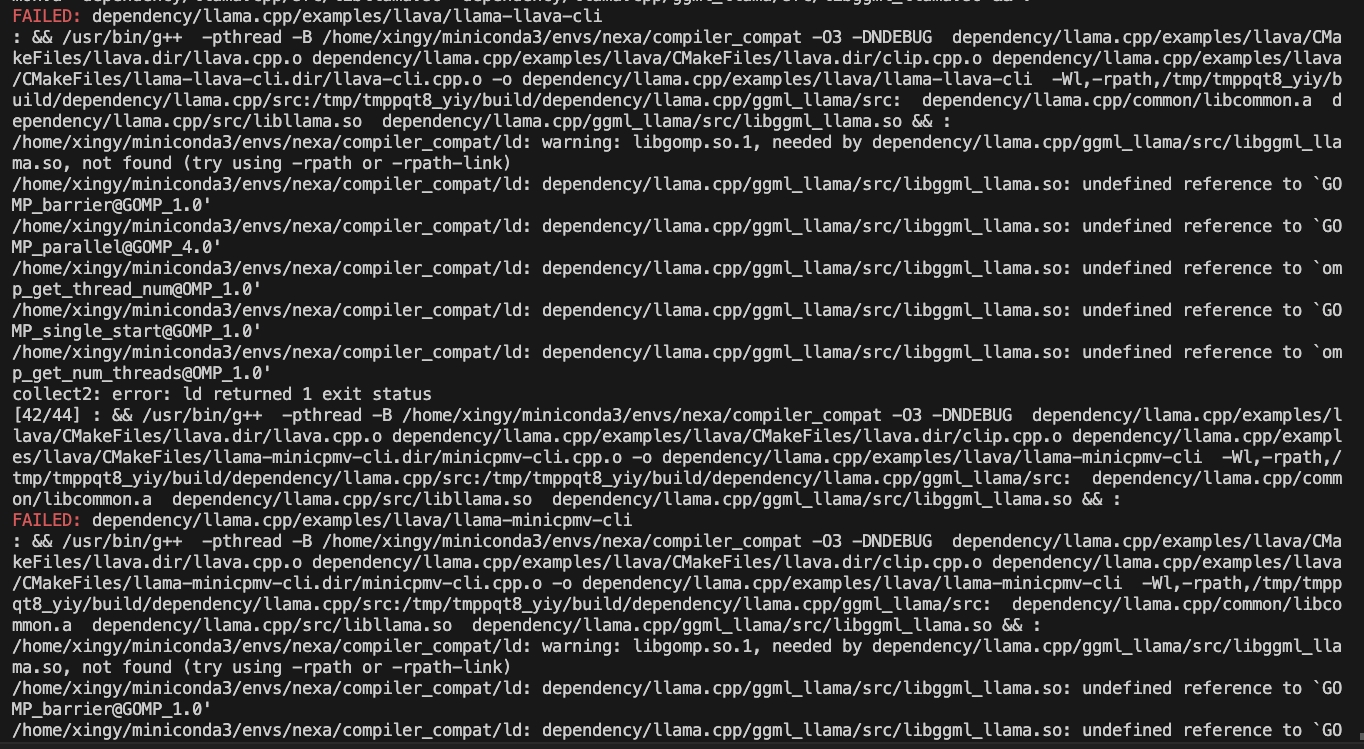
Experimente o seguinte comando:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiPara instalar com o suporte do ROCM, verifique se você possui o ROCM 6.2.1 ou posteriormente instalado.
Para Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirPara instalar com o suporte da Vulkan, verifique se você possui o Vulkan SDK 1.3.261.1 ou posteriormente instalado.
Para Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPara o prompt de comando do Windows :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows Git Bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirComo clonar este repo
git clone --recursive https://github.com/NexaAI/nexa-sdk Se você esquecer de usar --recursive , poderá usar o comando abaixo para adicionar submodule
git submodule update --init --recursiveEntão você pode construir e instalar o pacote
pip install -e . Abaixo está a nossa diferenciação de outras ferramentas semelhantes:
| Recurso | Nexa SDK | Ollama | Ideal | LM Studio |
|---|---|---|---|---|
| Suporte GGML | ✅ | ✅ | ✅ | |
| Suporte onnx | ✅ | ✅ | ||
| Geração de texto | ✅ | ✅ | ✅ | ✅ |
| Geração de imagens | ✅ | |||
| Modelos de linguagem de visão | ✅ | ✅ | ✅ | ✅ |
| Modelos de linguagem de áudio | ✅ | |||
| Texto para fala | ✅ | ✅ | ||
| Capacidade do servidor | ✅ | ✅ | ✅ | ✅ |
| Interface do usuário | ✅ | ✅ | ||
| Instalação executável | ✅ | ✅ | ✅ |
Nosso Hub de modelo no dispositivo oferece todos os tipos de modelos quantizados (texto, imagem, áudio, multimodal) com filtros para RAM, tamanho do arquivo, tarefas etc. para ajudá-lo a explorar facilmente modelos com a interface do usuário. Explore os modelos no dispositivo no hub de modelo no dispositivo
Exemplos de modelo suportados (lista completa no Model Hub):
| Modelo | Tipo | Formatar | Comando |
|---|---|---|---|
| Omniaudio | Audiolm | GGUF | nexa run omniaudio |
| Qwen2audio | Audiolm | GGUF | nexa run qwen2audio |
| Octopus-V2 | Chamada de função | GGUF | nexa run octopus-v2 |
| OCTO-NET | Texto | GGUF | nexa run octo-net |
| omnivlm | Multimodal | GGUF | nexa run omniVLM |
| nanollava | Multimodal | GGUF | nexa run nanollava |
| llava-phi3 | Multimodal | GGUF | nexa run llava-phi3 |
| llava-llama3 | Multimodal | GGUF | nexa run llava-llama3 |
| LLAVA1.6-MISTRAL | Multimodal | GGUF | nexa run llava1.6-mistral |
| llava1.6-vicuna | Multimodal | GGUF | nexa run llava1.6-vicuna |
| llama3.2 | Texto | GGUF | nexa run llama3.2 |
| LLAMA3-INCENSORADO | Texto | GGUF | nexa run llama3-uncensored |
| Gemma2 | Texto | GGUF | nexa run gemma2 |
| Qwen2.5 | Texto | GGUF | nexa run qwen2.5 |
| Mathqwen | Texto | GGUF | nexa run mathqwen |
| Codeqwen | Texto | GGUF | nexa run codeqwen |
| mistral | Texto | GGUF/ONNX | nexa run mistral |
| Deepseek-Coder | Texto | GGUF | nexa run deepseek-coder |
| phi3.5 | Texto | GGUF | nexa run phi3.5 |
| OpenElm | Texto | GGUF | nexa run openelm |
| estável difusão-v2-1 | Geração de imagens | GGUF | nexa run sd2-1 |
| estável difusão-3-medium | Geração de imagens | GGUF | nexa run sd3 |
| Flux.1-Schnell | Geração de imagens | GGUF | nexa run flux |
| lcm-dreamshaper | Geração de imagens | GGUF/ONNX | nexa run lcm-dreamshaper |
| Whisper-Large-V3-Turbo | Fala para texto | BIN | nexa run faster-whisper-large-turbo |
| sussurro | Fala para texto | ONNX | nexa run whisper-tiny.en |
| MXBAI-EMBED-LARGE-V1 | Incorporação | GGUF | nexa embed mxbai |
| NOMIC-EMBED-TEXT-V1.5 | Incorporação | GGUF | nexa embed nomic |
| Minilm-L12-V2 | Incorporação | GGUF | nexa embed all-MiniLM-L12-v2:fp16 |
| Bark-small | Texto para fala | GGUF | nexa run bark-small:fp16 |
Você pode puxar, converter (para .gguf), quantizar e executar modelos de geração de texto suportados por LLAMA.CPP da HF ou MS com Nexa SDK.
Use nexa run -hf <hf-model-id> ou nexa run -ms <ms-model-id> para executar modelos com arquivos .gguf fornecidos:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFNota: Você será solicitado a selecionar um único arquivo .gguf. Se a versão de quantização desejada tiver vários arquivos divididos (como FP16-00001-de-00004), use a ferramenta de conversão da Nexa (veja abaixo) para converter e quantizar o modelo localmente.
Instale o pacote Nexa Python e instale a ferramenta de conversão Nexa com pip install "nexaai[convert]" e converta modelos do huggingface com nexa convert <hf-model-id> :
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct Ou você pode converter modelos do ModelCope com nexa convert -ms <ms-model-id> :
nexa convert -ms Qwen/Qwen2.5-7B-InstructNOTA: Verifique nossa tabela de classificação para obter benchmarks de desempenho de diferentes versões quantizadas dos modelos de idiomas e documentos do HuggingFace para aprender sobre as opções de quantização.
? Você pode visualizar modelos baixados e convertidos com nexa list
Observação
pip install nexaai por pip install "nexaai[onnx]" nos comandos fornecidos.pip install nexaai pelo pip install "nexaai[eval]" nos comandos fornecidos.pip install nexaai pelo pip install "nexaai[convert]" nos comandos fornecidos.--extra-index-url https://pypi.org/simple com --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple em ingestion.tuna.tsinghua.edu.cnple.simple.Aqui está uma breve visão geral dos principais comandos da CLI:
nexa run : Execute a inferência por várias tarefas usando os modelos GGUF.nexa onnx : Execute a inferência por várias tarefas usando modelos ONNX.nexa convert : converta e quantize os modelos Huggingface em modelos GGUF.nexa server : execute o serviço de geração de texto nexa ai.nexa eval : Execute as tarefas de avaliação da NEXA AI.nexa pull : puxe um modelo do oficial ou hub.nexa remove : Remova um modelo da máquina local.nexa clean : Limpe todos os arquivos do modelo.nexa list : liste todos os modelos na máquina local.nexa login : Faça login na API Nexa.nexa whoami : mostre informações atuais do usuário.nexa logout : logout da API Nexa.Para obter informações detalhadas sobre comandos e uso da CLI, consulte o documento de referência da CLI.
Para iniciar um servidor local usando modelos no seu computador local, você pode usar o comando nexa server . Para obter informações detalhadas sobre configuração do servidor, terminais da API e exemplos de uso, consulte o documento de referência do servidor.
Swift SDK: fornece uma API rápida, permitindo que os desenvolvedores SWIFT integrem e usem facilmente os modelos LLAMA.CPP em seus projetos.
Mais documentos
Gostaríamos de agradecer aos seguintes projetos:


