nexa sdk
v0.0.9.7
Modell Hub | Dokumentation | Zwietracht | Blogs | X (Twitter)
NEXA SDK ist ein lokales Rahmen für OnNX- und GGML-Modelle für On-Device-Inferenz, die Textgenerierung, Bildgenerierung, Vision-Sprachmodelle (VLM), Audio-Sprachmodelle, Sprach-zu-Text (ASR) und Text-to-Speech-Funktionen (TTS) unterstützt. Installierbar über Python -Paket oder ausführbares Installationsprogramm.
nexa run omniVLM und Audiosprachmodell (2,9B -Parameter): nexa run omniaudionexa run qwen2audio , wir sind das erste Open-Source-Toolkit, das das Audiosprachenmodell mit der GGML-Tensor-Bibliothek unterstützt.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION oder nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP oder nexa run -ms <ms_model_id> -mt NLPWillkommen, um Ihre Anfragen durch Probleme einzureichen, wir versenden wöchentlich.
 MacOS Installer
MacOS Installer
 Windows Installer
Windows Installer
 Linux -Installationsprogramm
Linux -Installationsprogramm
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Versuchen Sie stattdessen mit nexa-exe :
nexa-exe < command > Wir haben vorgefertigte Räder für verschiedene Python-Versionen, Plattformen und Backends für eine bequeme Installation auf unserer Indexseite veröffentlicht.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirFür die GPU -Version , die Metal (macOS) unterstützt:
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirVersuchen Sie den folgenden Befehl:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirUm mit CUDA -Support zu installieren, stellen Sie sicher, dass CUDA Toolkit 12.0 oder später installiert ist.
Für Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirFür Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirFür die Windows -Eingabeaufforderung :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirFür Windows Git Bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirWenn Sie beim Erstellen auf das folgende Problem stoßen:
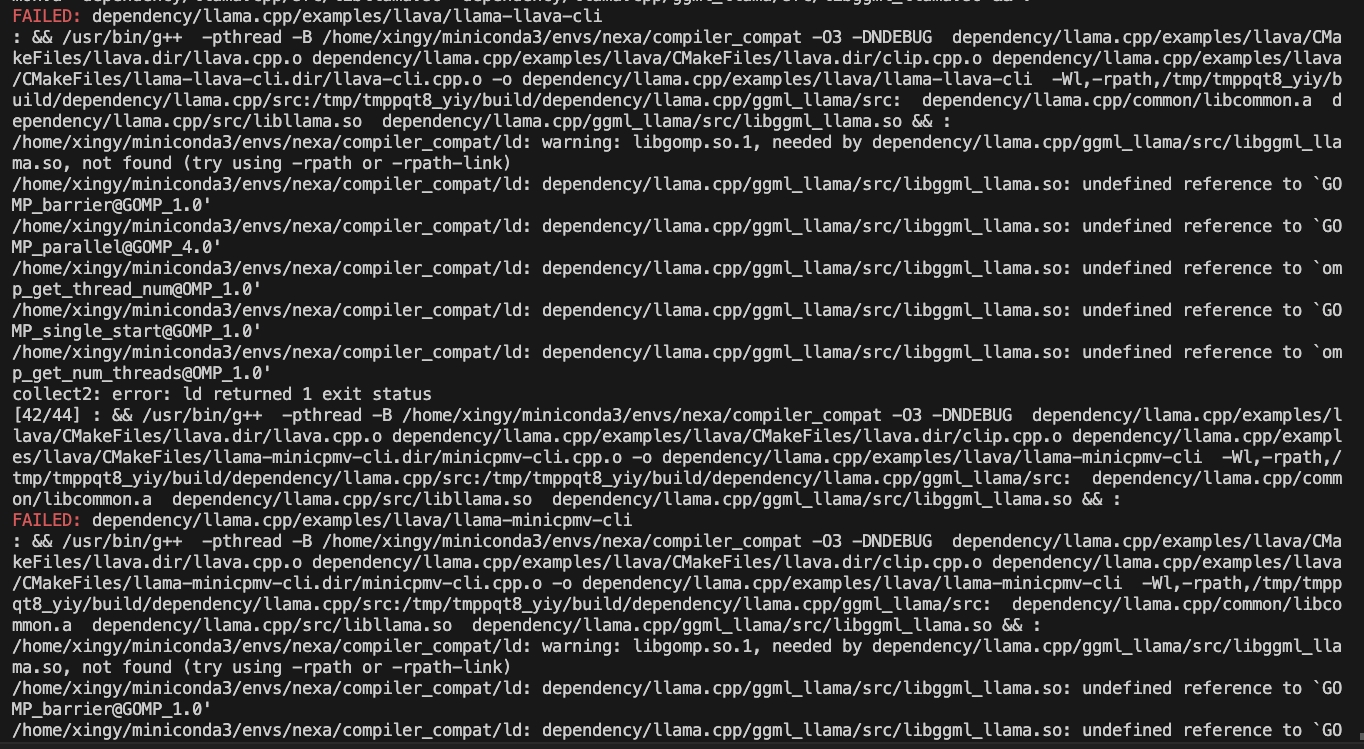
Versuchen Sie den folgenden Befehl:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiUm mit ROCM -Unterstützung zu installieren, stellen Sie sicher, dass Sie ROCM 6.2.1 oder später installiert haben.
Für Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirUm mit Vulkan Support zu installieren, stellen Sie sicher, dass Sie Vulkan SDK 1.3.261.1 oder höher installiert haben.
Für Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirFür die Windows -Eingabeaufforderung :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirFür Windows Git Bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirWie man dieses Repo klonen
git clone --recursive https://github.com/NexaAI/nexa-sdk Wenn Sie vergessen zu verwenden --recursive , können Sie den folgenden Befehl zum Hinzufügen von Submodule verwenden
git submodule update --init --recursiveDann können Sie das Paket erstellen und installieren
pip install -e . Im Folgenden finden Sie unsere Differenzierung von anderen ähnlichen Tools:
| Besonderheit | Nexa SDK | Ollama | Optimum | LM Studio |
|---|---|---|---|---|
| GGML -Unterstützung | ✅ | ✅ | ✅ | |
| Onnx -Unterstützung | ✅ | ✅ | ||
| Textgenerierung | ✅ | ✅ | ✅ | ✅ |
| Bildgenerierung | ✅ | |||
| Visionsprachel-Modelle | ✅ | ✅ | ✅ | ✅ |
| Audiosprachige Modelle | ✅ | |||
| Text-to-Speech | ✅ | ✅ | ||
| Serverfunktion | ✅ | ✅ | ✅ | ✅ |
| Benutzeroberfläche | ✅ | ✅ | ||
| Ausführbare Installation | ✅ | ✅ | ✅ |
Unser Hub mit On-Device Model Hub bietet alle Arten von quantisierten Modellen (Text, Bild, Audio, multimodal) mit Filtern für RAM, Dateigröße, Aufgaben usw., damit Sie die Modelle mit der Benutzeroberfläche problemlos erkunden können. Erforschen
Unterstützte Modellbeispiele (vollständige Liste bei Model Hub):
| Modell | Typ | Format | Befehl |
|---|---|---|---|
| Omniaudio | Audiolm | Gguf | nexa run omniaudio |
| Qwen2audio | Audiolm | Gguf | nexa run qwen2audio |
| Oktopus-V2 | Funktionsaufruf | Gguf | nexa run octopus-v2 |
| Okto-Netz | Text | Gguf | nexa run octo-net |
| Omnivlm | Multimodal | Gguf | nexa run omniVLM |
| Nanollava | Multimodal | Gguf | nexa run nanollava |
| llava-phi3 | Multimodal | Gguf | nexa run llava-phi3 |
| llava-llama3 | Multimodal | Gguf | nexa run llava-llama3 |
| Llava1.6-MISTRAL | Multimodal | Gguf | nexa run llava1.6-mistral |
| llava1.6-vicuna | Multimodal | Gguf | nexa run llava1.6-vicuna |
| Lama3.2 | Text | Gguf | nexa run llama3.2 |
| llama3-unbegründet | Text | Gguf | nexa run llama3-uncensored |
| Gemma2 | Text | Gguf | nexa run gemma2 |
| Qwen2.5 | Text | Gguf | nexa run qwen2.5 |
| Mathqwen | Text | Gguf | nexa run mathqwen |
| codesqwen | Text | Gguf | nexa run codeqwen |
| Mistral | Text | Gguf/onnx | nexa run mistral |
| Deepseek-Coder | Text | Gguf | nexa run deepseek-coder |
| Phi3.5 | Text | Gguf | nexa run phi3.5 |
| OpenElm | Text | Gguf | nexa run openelm |
| Stabile Diffusion-V2-1 | Bildgenerierung | Gguf | nexa run sd2-1 |
| Stabil-Diffusion-3-Medium | Bildgenerierung | Gguf | nexa run sd3 |
| Flux.1-SCHNELL | Bildgenerierung | Gguf | nexa run flux |
| LCM-Dreamshaper | Bildgenerierung | Gguf/onnx | nexa run lcm-dreamshaper |
| flüsterlarge-v3-turbo | Sprache zu Text | Mülleimer | nexa run faster-whisper-large-turbo |
| flüstertiny.en | Sprache zu Text | Onnx | nexa run whisper-tiny.en |
| MXBAI-EMBED-LARGE-V1 | Einbettung | Gguf | nexa embed mxbai |
| nomic-embed-text-v1.5 | Einbettung | Gguf | nexa embed nomic |
| All-Minilm-L12-V2 | Einbettung | Gguf | nexa embed all-MiniLM-L12-v2:fp16 |
| Rinde-Small | Text-to-Speech | Gguf | nexa run bark-small:fp16 |
Sie können (in .gguf) ziehen, konvertieren (in .gguf), quantisieren und rennen Sie Lama.CPP unterstützte Textgenerierungsmodelle von HF oder MS mit NEXA SDK.
Verwenden Sie nexa run -hf <hf-model-id> oder nexa run -ms <ms-model-id> um Modelle mit bereitgestellten .guf-Dateien auszuführen:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFHinweis: Sie werden aufgefordert, eine einzelne .guf -Datei auszuwählen. Wenn über Ihre gewünschte Quantisierungsversion mehrere geteilte Dateien (wie FP16-00001-of-00004) verfügt, verwenden Sie bitte das Konvertierungswerkzeug von NEXA (siehe unten), um das Modell lokal zu konvertieren und zu quantisieren.
Installieren Sie das Nexa Python-Paket und installieren Sie das NEXA-Konvertierungswerkzeug mit pip install "nexaai[convert]" und konvertieren Modelle von Huggingface mit nexa convert <hf-model-id> :
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct Oder Sie können Modelle aus ModelsCope mit nexa convert -ms <ms-model-id> konvertieren:
nexa convert -ms Qwen/Qwen2.5-7B-InstructHINWEIS: Überprüfen Sie unsere Rangliste auf Leistungsbenchmarks verschiedener quantisierter Versionen von Mainstream -Sprachmodellen und Umarmungsdokumenten, um mehr über Quantisierungsoptionen zu erfahren.
? Sie können heruntergeladene und konvertierte Modelle mit nexa list anzeigen
Notiz
pip install nexaai durch pip install "nexaai[onnx]" in bereitgestellten Befehlen.pip install nexaai durch pip install "nexaai[eval]" in bereitgestellten Befehlen.pip install nexaai durch pip install "nexaai[convert]" in bereitgestellten Befehlen.--extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple wir Ihnen, Tsinghua Open Source Mirror als zusätzliche Index --extra-index-url https://pypi.org/simple URL zu verwenden.Hier ist ein kurzer Überblick über die Haupt -CLI -Befehle:
nexa run : Rennen Sie die Inferenz für verschiedene Aufgaben mit GGUF -Modellen.nexa onnx : Führen Sie die Inferenz für verschiedene Aufgaben mit ONNX -Modellen aus.nexa convert : Konvertieren und Quantisieren von Huggingface -Modellen in GGUF -Modelle.nexa server : Führen Sie den NEXA AI -Textgenerierungsdienst aus.nexa eval : Führen Sie die NEXA -AI -Bewertungsaufgaben aus.nexa pull : Ziehen Sie ein Modell aus dem offiziellen oder Hub.nexa remove : Entfernen Sie ein Modell von der lokalen Maschine.nexa clean : Alle Modelldateien beseitigen.nexa list : Listen Sie alle Modelle in der lokalen Maschine auf.nexa login : Login bei Nexa API.nexa whoami : Aktuelle Benutzerinformationen anzeigen.nexa logout : Abmelden von der Nexa -API.Ausführliche Informationen zu CLI -Befehlen und -nutzung finden Sie im CLI -Referenzdokument.
Um einen lokalen Server zu starten, der Modelle auf Ihrem lokalen Computer verwendet, können Sie den Befehl nexa server verwenden. Ausführliche Informationen zu Server -Setup, API -Endpunkten und Verwendungsbeispielen finden Sie im Server -Referenzdokument.
SWIFT SDK: Bietet eine Swifty -API, mit der Swift -Entwickler lama.CPP -Modelle einfach in ihre Projekte integrieren und verwenden können.
Weitere Dokumente
Wir möchten uns bei den folgenden Projekten bedanken:


