nexa sdk
v0.0.9.7
Hub Model On-Device | Dokumentasi | Perselisihan | Blog | X (Twitter)
NEXA SDK adalah kerangka kerja inferensi di perangkat lokal untuk model ONNX dan GGML, pendukung pembuatan teks, pembuatan gambar, model visi-bahasa (VLM), model bahasa audio, kemampuan bicara-ke-teks (ASR), dan teks-ke-pidato (TTS). Diinstal melalui paket Python atau penginstal yang dapat dieksekusi.
nexa run omniVLM dan Model Bahasa Audio (Parameter 2.9B): nexa run omniaudionexa run qwen2audio , kami adalah perangkat open-source pertama yang mendukung model bahasa audio dengan GGML Tensor Library.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION atau nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP atau nexa run -ms <ms_model_id> -mt NLPSelamat datang untuk mengirimkan permintaan Anda melalui masalah, kami mengirim setiap minggu.
 Penginstal MacOS
Penginstal MacOS
 Penginstal Windows
Penginstal Windows
 Penginstal Linux
Penginstal Linux
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Coba gunakan nexa-exe sebagai gantinya:
nexa-exe < command > Kami telah merilis roda pra-dibangun untuk berbagai versi Python, platform, dan backends untuk instalasi yang nyaman di halaman indeks kami.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirUntuk versi GPU Metal Pendukung (MacOS) :
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirCoba perintah berikut:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirUntuk menginstal dengan dukungan CUDA, pastikan Anda memiliki CUDA Toolkit 12.0 atau yang lebih baru diinstal.
Untuk Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirUntuk Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirUntuk prompt perintah windows :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirUntuk Windows Git Bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirJika Anda menghadapi masalah berikut saat membangun:
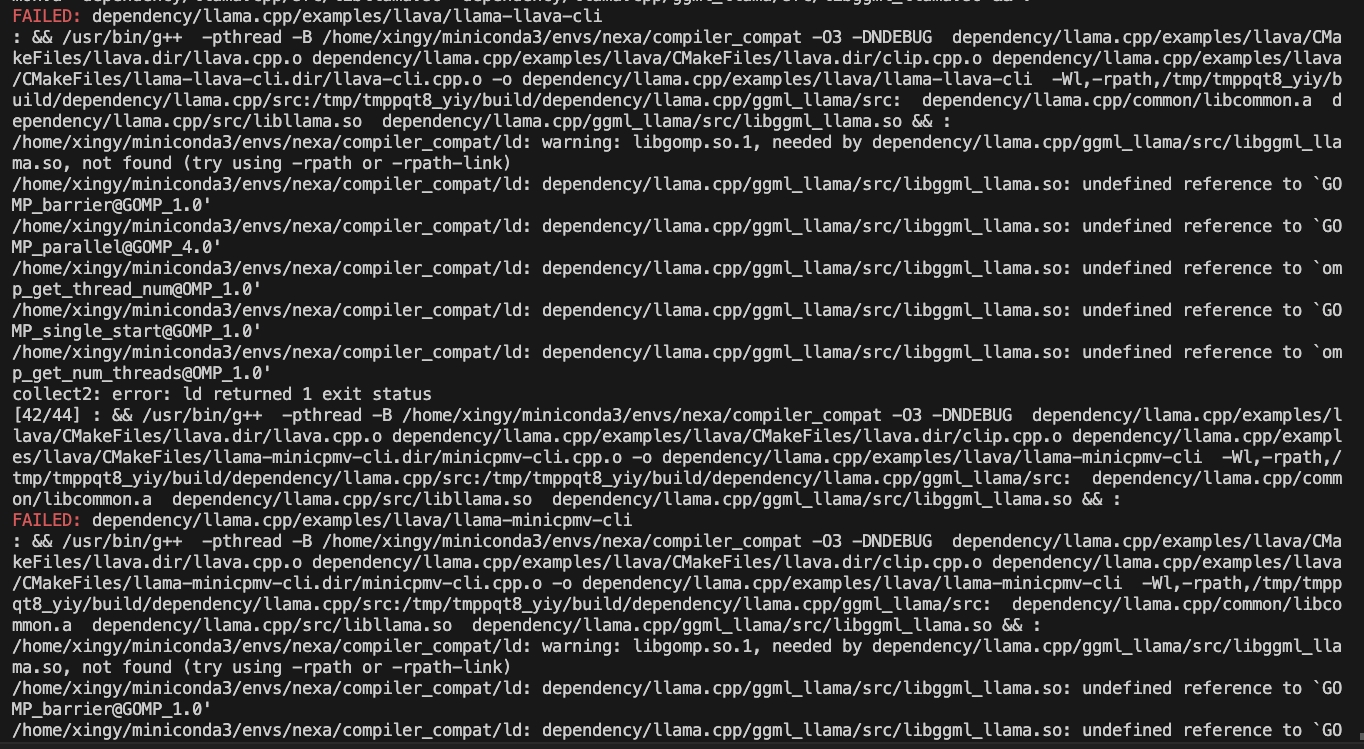
Coba perintah berikut:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiUntuk menginstal dengan dukungan ROCM, pastikan Anda memiliki ROCM 6.2.1 atau yang lebih baru diinstal.
Untuk Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirUntuk menginstal dengan Dukungan Vulkan, pastikan Anda memiliki Vulkan SDK 1.3.261.1 atau yang lebih baru diinstal.
Untuk Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirUntuk prompt perintah windows :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirUntuk Windows Git Bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirCara mengkloning repo ini
git clone --recursive https://github.com/NexaAI/nexa-sdk Jika Anda lupa menggunakan --recursive , Anda dapat menggunakan perintah di bawah ini untuk menambahkan submodule
git submodule update --init --recursiveMaka Anda dapat membangun dan menginstal paket
pip install -e . Di bawah ini adalah diferensiasi kami dari alat serupa lainnya:
| Fitur | NEXA SDK | Ollama | Optimal | LM Studio |
|---|---|---|---|---|
| Dukungan GGML | ✅ | ✅ | ✅ | |
| Dukungan ONNX | ✅ | ✅ | ||
| Pembuatan teks | ✅ | ✅ | ✅ | ✅ |
| Pembuatan gambar | ✅ | |||
| Model penglihatan-bahasa | ✅ | ✅ | ✅ | ✅ |
| Model bahasa audio | ✅ | |||
| Teks-ke-speech | ✅ | ✅ | ||
| Kemampuan server | ✅ | ✅ | ✅ | ✅ |
| Antarmuka pengguna | ✅ | ✅ | ||
| Instalasi yang dapat dieksekusi | ✅ | ✅ | ✅ |
Hub Model On-Device kami menawarkan semua jenis model terkuantisasi (teks, gambar, audio, multimodal) dengan filter untuk RAM, ukuran file, tugas, dll. Untuk membantu Anda mengeksplorasi model dengan UI. Jelajahi model on-perangkat di hub model on-device
Contoh model yang didukung (daftar lengkap di Model Hub):
| Model | Jenis | Format | Memerintah |
|---|---|---|---|
| Omniaudio | Audiolm | GGUF | nexa run omniaudio |
| Qwen2Audio | Audiolm | GGUF | nexa run qwen2audio |
| gurita-v2 | Panggilan fungsi | GGUF | nexa run octopus-v2 |
| octo-net | Teks | GGUF | nexa run octo-net |
| OMNIVLM | Multimodal | GGUF | nexa run omniVLM |
| Nanollava | Multimodal | GGUF | nexa run nanollava |
| llava-phi3 | Multimodal | GGUF | nexa run llava-phi3 |
| llava-llama3 | Multimodal | GGUF | nexa run llava-llama3 |
| llava1.6-mistral | Multimodal | GGUF | nexa run llava1.6-mistral |
| llava1.6-vicuna | Multimodal | GGUF | nexa run llava1.6-vicuna |
| llama3.2 | Teks | GGUF | nexa run llama3.2 |
| llama3-tidak dipenuhi | Teks | GGUF | nexa run llama3-uncensored |
| Gemma2 | Teks | GGUF | nexa run gemma2 |
| Qwen2.5 | Teks | GGUF | nexa run qwen2.5 |
| Mathqwen | Teks | GGUF | nexa run mathqwen |
| CodeQwen | Teks | GGUF | nexa run codeqwen |
| Mistral | Teks | GGUF/ONNX | nexa run mistral |
| Deepseek-Coder | Teks | GGUF | nexa run deepseek-coder |
| phi3.5 | Teks | GGUF | nexa run phi3.5 |
| Openelm | Teks | GGUF | nexa run openelm |
| stabil-difusi-V2-1 | Pembuatan gambar | GGUF | nexa run sd2-1 |
| stabil-difusi-3-menengah | Pembuatan gambar | GGUF | nexa run sd3 |
| Fluks.1-schnell | Pembuatan gambar | GGUF | nexa run flux |
| LCM-dreamshaper | Pembuatan gambar | GGUF/ONNX | nexa run lcm-dreamshaper |
| Whisper-Large-V3-Turbo | Pidato-ke-teks | Tempat sampah | nexa run faster-whisper-large-turbo |
| Whisper-Tiny.en | Pidato-ke-teks | Onnx | nexa run whisper-tiny.en |
| MXBAI-EMBED-LARGE-V1 | Menanamkan | GGUF | nexa embed mxbai |
| nomic-embed-text-v1.5 | Menanamkan | GGUF | nexa embed nomic |
| All-Minilm-L12-V2 | Menanamkan | GGUF | nexa embed all-MiniLM-L12-v2:fp16 |
| Bark-Small | Teks-ke-speech | GGUF | nexa run bark-small:fp16 |
Anda dapat menarik, mengonversi (ke .gguf), mengukur dan menjalankan model pembuatan teks yang didukung llama.cpp dari HF atau MS dengan NEXA SDK.
Gunakan nexa run -hf <hf-model-id> atau nexa run -ms <ms-model-id> Untuk menjalankan model dengan file .GGUF yang disediakan:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFCatatan: Anda akan diminta untuk memilih satu file .gguf. Jika versi kuantisasi yang Anda inginkan memiliki beberapa file split (seperti FP16-00001-of-00004), silakan gunakan alat konversi NEXA (lihat di bawah) untuk mengonversi dan mengukur model secara lokal.
Instal Paket Nexa Python, dan instal NEXA Conversion Tool dengan pip install "nexaai[convert]" , lalu mengonversi model dari Huggingface dengan nexa convert <hf-model-id> :
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct Atau Anda dapat mengonversi model dari ModelScope dengan nexa convert -ms <ms-model-id> :
nexa convert -ms Qwen/Qwen2.5-7B-InstructCatatan: Periksa papan peringkat kami untuk tolok ukur kinerja dari berbagai versi kuantisasi model bahasa utama dan dokumen pelukan untuk belajar tentang opsi kuantisasi.
? Anda dapat melihat model yang diunduh dan dikonversi dengan nexa list
Catatan
pip install nexaai dengan pip install "nexaai[onnx]" di perintah yang disediakan.pip install nexaai dengan pip install "nexaai[eval]" di perintah yang disediakan.pip install nexaai dengan pip install "nexaai[convert]" di perintah yang disediakan.--extra-index-url https://pypi.org/simple dengan --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple .Berikut gambaran singkat tentang perintah CLI utama:
nexa run : Jalankan inferensi untuk berbagai tugas menggunakan model GGUF.nexa onnx : Jalankan inferensi untuk berbagai tugas menggunakan model ONNX.nexa convert : Konversi dan kuantisasi model Huggingface menjadi model GGUF.nexa server : Jalankan layanan pembuatan teks NEXA AI.nexa eval : Jalankan tugas evaluasi NEXA AI.nexa pull : Tarik model dari resmi atau hub.nexa remove : Lepaskan model dari mesin lokal.nexa clean : Bersihkan semua file model.nexa list : Sebutkan semua model di mesin lokal.nexa login : Masuk ke NEXA API.nexa whoami : Tampilkan informasi pengguna saat ini.nexa logout : LOGOUT DARI NEXA API.Untuk informasi terperinci tentang perintah dan penggunaan CLI, silakan merujuk ke dokumen referensi CLI.
Untuk memulai server lokal menggunakan model di komputer lokal Anda, Anda dapat menggunakan perintah nexa server . Untuk informasi terperinci tentang pengaturan server, titik akhir API, dan contoh penggunaan, silakan merujuk ke dokumen referensi server.
Swift SDK: Menyediakan API Swifty, yang memungkinkan pengembang Swift untuk dengan mudah mengintegrasikan dan menggunakan model Llama.cpp dalam proyek mereka.
Lebih banyak dokumen
Kami ingin mengucapkan terima kasih kepada proyek -proyek berikut:


