nexa sdk
v0.0.9.7
On-Device Model Hub | Документация | Раздор | Блоги | X (Twitter)
NEXA SDK -это локальная структура вывода на устройствах для моделей ONNX и GGML, поддерживающая генерацию текста, генерацию изображений, модели зрения на зрение (VLM), аудиоязычные модели, способности речи к тексту (ASR) и текстовые (TTS). Установка через пакет Python или исполняемый установщик.
nexa run omniVLM и модель аудио -языка (параметры 2.9b): nexa run omniaudionexa run qwen2audio , мы являемся первым инструментом с открытым исходным кодом, который поддерживает модель аудио языка с библиотекой GGML Tensor.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION или nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP или nexa run -ms <ms_model_id> -mt NLPДобро пожаловать, чтобы отправить ваши запросы через проблемы, мы отправляем еженедельно.
 Установщик macOS
Установщик macOS
 Установщик Windows
Установщик Windows
 Linux установщик
Linux установщик
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Попробуйте использовать nexa-exe вместо этого:
nexa-exe < command > Мы выпустили предварительно построенные колеса для различных версий, платформ и бэкэндов Python для удобной установки на нашей странице индекса.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirДля версии GPU поддерживает металл (macOS) :
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirПопробуйте следующую команду:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirЧтобы установить с поддержкой CUDA, убедитесь, что у вас установлен Cuda Toolkit 12.0 или более поздний цвет.
Для Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirДля Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirДля командной строки Windows :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirДля Windows git bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirЕсли вы столкнетесь с следующей проблемой во время строительства:
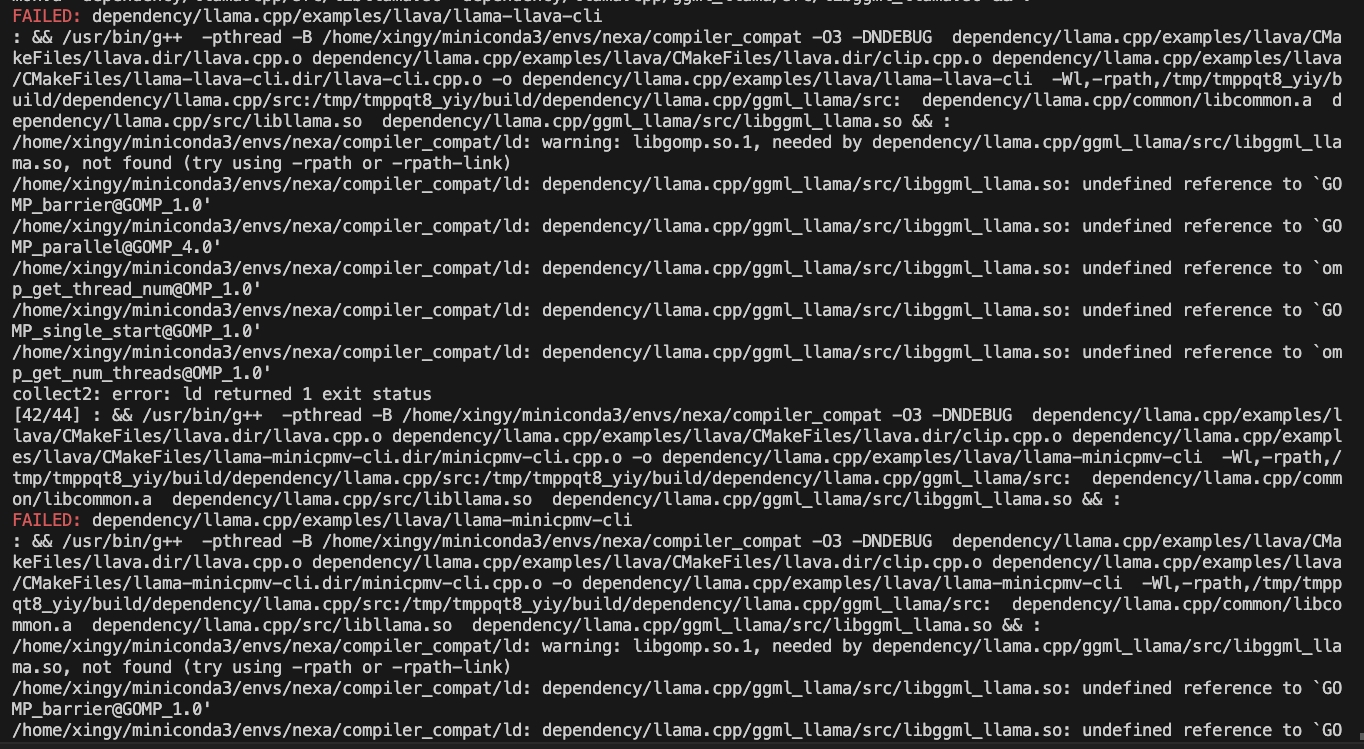
Попробуйте следующую команду:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiЧтобы установить с поддержкой ROCM, убедитесь, что у вас установлен ROCM 6.2.1 или позже.
Для Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirЧтобы установить с поддержкой Vulkan, убедитесь, что у вас установлен Vulkan SDK 1.3.261.1 или позже.
Для Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirДля командной строки Windows :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirДля Windows git bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirКак клонировать это репо
git clone --recursive https://github.com/NexaAI/nexa-sdk Если вы забудете использовать --recursive
git submodule update --init --recursiveЗатем вы можете построить и установить пакет
pip install -e . Ниже приведена наша дифференциация от других подобных инструментов:
| Особенность | Nexa Sdk | Оллама | Оптимальный | LM Studio |
|---|---|---|---|---|
| Поддержка GGML | ✅ | ✅ | ✅ | |
| Поддержка ONNX | ✅ | ✅ | ||
| Генерация текста | ✅ | ✅ | ✅ | ✅ |
| Генерация изображений | ✅ | |||
| Модели на языке зрения | ✅ | ✅ | ✅ | ✅ |
| Аудиоязычные модели | ✅ | |||
| Текст в речь | ✅ | ✅ | ||
| Возможность сервера | ✅ | ✅ | ✅ | ✅ |
| Пользовательский интерфейс | ✅ | ✅ | ||
| Исполняемая установка | ✅ | ✅ | ✅ |
Наш модельный концентратор в конструкции предлагает все типы квантованных моделей (текст, изображение, аудио, мультимодальное) с фильтрами для ОЗУ, размера файла, задач и т. Д., Чтобы помочь вам легко исследовать модели с пользовательским интерфейсом. Исследуйте модели на устройствах в модельном концентраторе On-Device
Поддерживаемые примеры модели (полный список в модели Hub):
| Модель | Тип | Формат | Командование |
|---|---|---|---|
| Omniaudio | Аудиолм | Gguf | nexa run omniaudio |
| QWEN2Audio | Аудиолм | Gguf | nexa run qwen2audio |
| Осьминог-В2 | Функциональный вызов | Gguf | nexa run octopus-v2 |
| Octo-Net | Текст | Gguf | nexa run octo-net |
| Omnivlm | Мультимодальный | Gguf | nexa run omniVLM |
| Наноллава | Мультимодальный | Gguf | nexa run nanollava |
| llava-phi3 | Мультимодальный | Gguf | nexa run llava-phi3 |
| Llava-Llama3 | Мультимодальный | Gguf | nexa run llava-llama3 |
| Llava1.6-Mistral | Мультимодальный | Gguf | nexa run llava1.6-mistral |
| Llava1.6-Vicuna | Мультимодальный | Gguf | nexa run llava1.6-vicuna |
| Llama3.2 | Текст | Gguf | nexa run llama3.2 |
| Llama3-Uncensored | Текст | Gguf | nexa run llama3-uncensored |
| Gemma2 | Текст | Gguf | nexa run gemma2 |
| QWEN2.5 | Текст | Gguf | nexa run qwen2.5 |
| MathQwen | Текст | Gguf | nexa run mathqwen |
| CodeQwen | Текст | Gguf | nexa run codeqwen |
| Мистраль | Текст | Gguf/onnx | nexa run mistral |
| DeepSeek-Coder | Текст | Gguf | nexa run deepseek-coder |
| PHI3.5 | Текст | Gguf | nexa run phi3.5 |
| Openelm | Текст | Gguf | nexa run openelm |
| Стабильная диффузия-V2-1 | Генерация изображений | Gguf | nexa run sd2-1 |
| Стабильная диффузия-3-медиам | Генерация изображений | Gguf | nexa run sd3 |
| Flux.1-Schnell | Генерация изображений | Gguf | nexa run flux |
| LCM-Dreamshaper | Генерация изображений | Gguf/onnx | nexa run lcm-dreamshaper |
| Whisper-Large-V3-Turbo | Речи к тексту | Бин | nexa run faster-whisper-large-turbo |
| Whisper-Nyance.en | Речи к тексту | Onnx | nexa run whisper-tiny.en |
| Mxbai-Embed-Large-V1 | Внедрение | Gguf | nexa embed mxbai |
| Номинальный-текст-текст-V1.5 | Внедрение | Gguf | nexa embed nomic |
| All-Minilm-L12-V2 | Внедрение | Gguf | nexa embed all-MiniLM-L12-v2:fp16 |
| Кора-мал | Текст в речь | Gguf | nexa run bark-small:fp16 |
Вы можете вытащить, преобразовать (в .gguf), квантовать и запустить Llama.cpp, поддерживаемые моделями генерации текста из HF или MS с помощью NEXA SDK.
Используйте nexa run -hf <hf-model-id> или nexa run -ms <ms-model-id> для запуска моделей с предоставленными файлами .gguf:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFПримечание. Вам будет предложено выбрать один файл .gguf. Если ваша желаемая версия квантования имеет несколько разделенных файлов (например, FP16-00001-of-00004), используйте инструмент преобразования NEXA (см. Ниже), чтобы преобразовать и квантовать модель локально.
Установите пакет Nexa Python и установите инструмент преобразования Nexa с помощью pip install "nexaai[convert]" , а затем преобразуйте модели из HuggingFace с nexa convert <hf-model-id> :
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct Или вы можете преобразовать модели из моделей с nexa convert -ms <ms-model-id> :
nexa convert -ms Qwen/Qwen2.5-7B-InstructПРИМЕЧАНИЕ. Проверьте нашу таблицу лидеров на предмет показателей производительности различных квантованных версий моделей основного языка и документов Huggingface, чтобы узнать о вариантах квантования.
? Вы можете просмотреть загруженные и конвертированные модели со nexa list
Примечание
pip install nexaai на pip install "nexaai[onnx]" в предоставленные команды.pip install nexaai на pip install "nexaai[eval]" в предоставленные команды.pip install nexaai на pip install "nexaai[convert]" в предоставленные команды.--extra-index-url https://pypi.org/simple с --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple в предоставлении.Вот краткий обзор главных команд CLI:
nexa run : Запустите вывод для различных задач с использованием моделей GGUF.nexa onnx : Запустите вывод для различных задач с использованием моделей ONNX.nexa convert : преобразовать и квантовать модели HuggingFace в модели GGUF.nexa server : запустите службу генерации текста Nexa AI.nexa eval : Запустите задачи оценки NEXA AI.nexa pull : вытащите модель из официального или хаба.nexa remove : удалите модель с локальной машины.nexa clean : очистите все файлы модели.nexa list : Перечислите все модели на локальной машине.nexa login : Войдите в Nexa API.nexa whoami : Показать текущую информацию пользователя.nexa logout : Vogout From Nexa API.Для получения подробной информации о командах CLI и использовании, пожалуйста, обратитесь к справочному документу CLI.
Чтобы запустить локальный сервер, используя модели на вашем локальном компьютере, вы можете использовать команду nexa server . Для получения подробной информации о настройке сервера, конечных точках API и примерах использования, пожалуйста, обратитесь к справочному документу сервера.
Swift SDK: предоставляет Swifty API, позволяющий разработчикам Swift легко интегрировать и использовать модели llama.cpp в свои проекты.
Больше документов
Мы хотели бы поблагодарить следующие проекты:


