nexa sdk
v0.0.9.7
デバイスモデルハブ|ドキュメント|不和|ブログ| X(Twitter)
NEXA SDKは、ONNXおよびGGMLモデルのローカルオンデバイス推論フレームワークであり、テキスト生成、画像生成、ビジョン言語モデル(VLM)、オーディオ言語モデル、音声からテキスト(ASR)、およびテキストツースピーチ(TTS)機能をサポートしています。 Pythonパッケージまたは実行可能なインストーラーを介してインストールできます。
nexa run omniVLMおよびAudio Languageモデル(2.9Bパラメーター): nexa run omniaudionexa run qwen2audio 、 GGMLテンソルライブラリでオーディオ言語モデルをサポートする最初のオープンソースツールキットです。nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISIONまたはnexa run -ms <ms_model_id> -mt COMPUTER_VISIONのGGUF形式で:HF <HF_MODEL_ID> -MT COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLPまたはnexa run -ms <ms_model_id> -mt NLPからGGUF形式でNLPモデルをプルと実行することをサポート問題を通じてリクエストを送信するためのように、毎週出荷します。
 MacOSインストーラー
MacOSインストーラー
 Windowsインストーラー
Windowsインストーラー
 Linuxインストーラー
Linuxインストーラー
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh代わりにnexa-exeを使用してみてください:
nexa-exe < command > インデックスページに便利なインストールのために、さまざまなPythonバージョン、プラットフォーム、バックエンド用の事前に構築されたホイールをリリースしました。
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dir金属(MacOS)をサポートするGPUバージョンの場合:
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dir次のコマンドを試してください。
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirCUDAサポートでインストールするには、CUDA Toolkit 12.0以降がインストールされていることを確認してください。
Linuxの場合:
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirWindows PowerShellの場合:
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirWindowsコマンドプロンプトの場合:
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirWindows git bashの場合:
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dir構築中に次の問題に遭遇した場合:
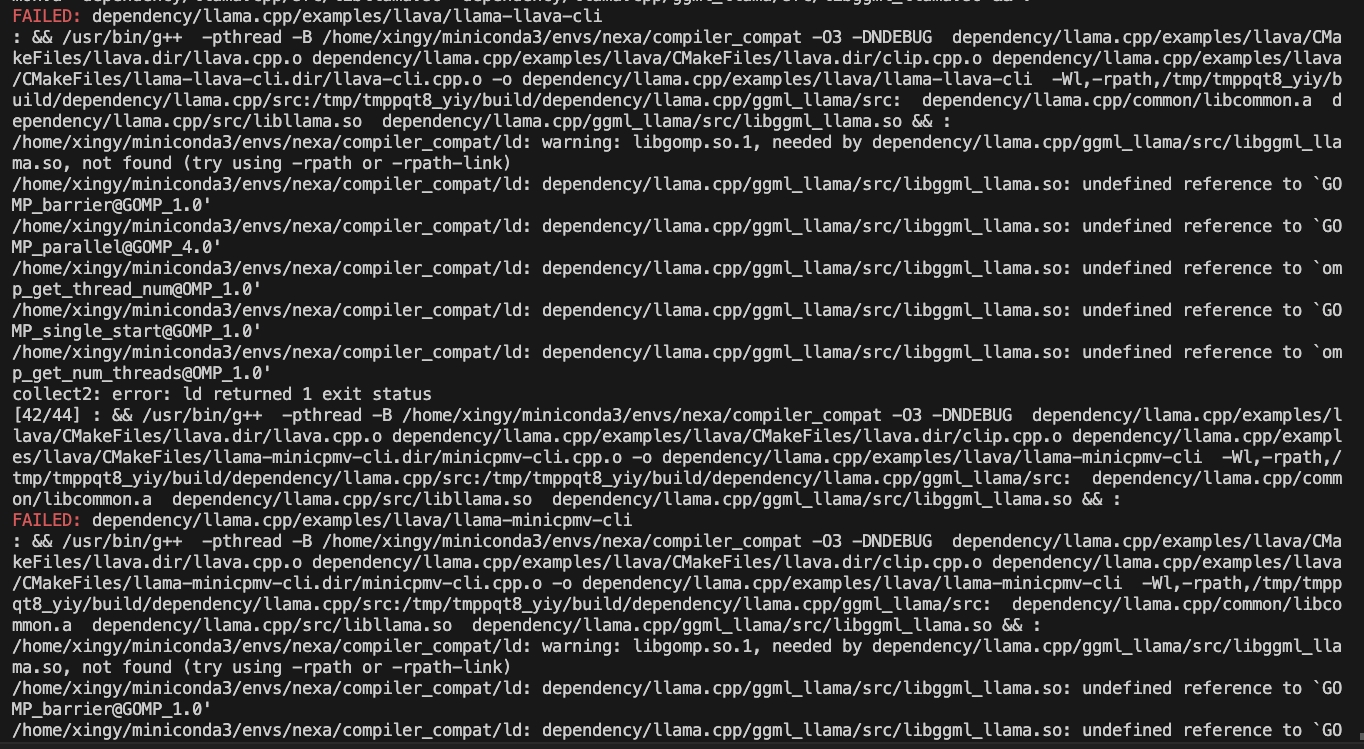
次のコマンドを試してください。
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiROCMサポートでインストールするには、ROCM 6.2.1以降がインストールされていることを確認してください。
Linuxの場合:
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirVulkanサポートでインストールするには、Vulkan SDK 1.3.261.1以降がインストールされていることを確認してください。
Windows PowerShellの場合:
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirWindowsコマンドプロンプトの場合:
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirWindows git bashの場合:
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirこのレポをクローンする方法
git clone --recursive https://github.com/NexaAI/nexa-sdk使用を忘れた場合--recursive 、以下のコマンドを使用してサブモジュールを追加できます
git submodule update --init --recursiveその後、パッケージを構築してインストールできます
pip install -e . 以下は、他の同様のツールとの差別化です。
| 特徴 | Nexa SDK | オラマ | 最適 | LMスタジオ |
|---|---|---|---|---|
| GGMLサポート | ✅ | ✅ | ✅ | |
| ONNXサポート | ✅ | ✅ | ||
| テキスト生成 | ✅ | ✅ | ✅ | ✅ |
| 画像生成 | ✅ | |||
| ビジョン言語モデル | ✅ | ✅ | ✅ | ✅ |
| オーディオ言語モデル | ✅ | |||
| テキストからスピーチ | ✅ | ✅ | ||
| サーバー機能 | ✅ | ✅ | ✅ | ✅ |
| ユーザーインターフェイス | ✅ | ✅ | ||
| 実行可能なインストール | ✅ | ✅ | ✅ |
当社のオンデバイスモデルハブは、RAM、ファイルサイズ、タスクなどのフィルターを備えたすべてのタイプの量子化モデル(テキスト、画像、オーディオ、マルチモーダル)を提供して、UIでモデルを簡単に探索できます。デバイスモデルハブでデバイス上のモデルを探索します
サポートされているモデルの例(モデルハブの完全なリスト):
| モデル | タイプ | 形式 | 指示 |
|---|---|---|---|
| オムニャウディオ | オーディオルム | gguf | nexa run omniaudio |
| qwen2audio | オーディオルム | gguf | nexa run qwen2audio |
| Octopus-V2 | 関数呼び出し | gguf | nexa run octopus-v2 |
| Octo-net | 文章 | gguf | nexa run octo-net |
| omnivlm | マルチモーダル | gguf | nexa run omniVLM |
| ナノラバ | マルチモーダル | gguf | nexa run nanollava |
| llava-phi3 | マルチモーダル | gguf | nexa run llava-phi3 |
| llava-llama3 | マルチモーダル | gguf | nexa run llava-llama3 |
| llava1.6-mistral | マルチモーダル | gguf | nexa run llava1.6-mistral |
| llava1.6-vicuna | マルチモーダル | gguf | nexa run llava1.6-vicuna |
| llama3.2 | 文章 | gguf | nexa run llama3.2 |
| llama3-encensored | 文章 | gguf | nexa run llama3-uncensored |
| gemma2 | 文章 | gguf | nexa run gemma2 |
| QWEN2.5 | 文章 | gguf | nexa run qwen2.5 |
| Mathqwen | 文章 | gguf | nexa run mathqwen |
| codeqwen | 文章 | gguf | nexa run codeqwen |
| ミストラル | 文章 | gguf/onnx | nexa run mistral |
| deepseek-coder | 文章 | gguf | nexa run deepseek-coder |
| PHI3.5 | 文章 | gguf | nexa run phi3.5 |
| Openelm | 文章 | gguf | nexa run openelm |
| stable-diffusion-v2-1 | 画像生成 | gguf | nexa run sd2-1 |
| stable diffusion-3-medium | 画像生成 | gguf | nexa run sd3 |
| Flux.1-schnell | 画像生成 | gguf | nexa run flux |
| LCM-DREAMSHAPER | 画像生成 | gguf/onnx | nexa run lcm-dreamshaper |
| ささやき声-V3ターボ | 音声からテキスト | ビン | nexa run faster-whisper-large-turbo |
| Whisper-Tiny.en | 音声からテキスト | onnx | nexa run whisper-tiny.en |
| mxbai-embed-large-v1 | 埋め込み | gguf | nexa embed mxbai |
| NOMIC-embed-Text-V1.5 | 埋め込み | gguf | nexa embed nomic |
| All-Minilm-L12-V2 | 埋め込み | gguf | nexa embed all-MiniLM-L12-v2:fp16 |
| barksmall | テキストからスピーチ | gguf | nexa run bark-small:fp16 |
NEXA SDKを使用して、HFまたはMSからサポートされているテキスト生成モデルを、llama.cppをQuantize、および実行することができます。
nexa run -hf <hf-model-id>またはnexa run -ms <ms-model-id>を使用して、提供された.ggufファイルでモデルを実行します。
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUF注:単一の.ggufファイルを選択するように求められます。目的の量子化バージョンに複数のスプリットファイル(FP16-00001-of-00004など)がある場合は、Nexaの変換ツール(以下を参照)を使用して、モデルをローカルに変換および量子化してください。
Nexa Pythonパッケージをインストールし、Nexa変換ツールをpip install "nexaai[convert]" 、 nexa convert <hf-model-id>でHuggingfaceからモデルを変換します。
nexa convert HuggingFaceTB/SmolLM2-135M-Instructまたは、 nexa convert -ms <ms-model-id>を使用してModelScopeからモデルを変換することができます。
nexa convert -ms Qwen/Qwen2.5-7B-Instruct注:メインストリーム言語モデルのさまざまな量子化されたバージョンのパフォーマンスベンチマークと、量子化オプションについて学習するために、ハグFaceドキュメントのパフォーマンスベンチマークを確認してください。
? nexa listでダウンロードされたモデルと変換されたモデルを表示できます
注記
pip install nexaai pip install "nexaai[onnx]"に置き換えます。pip install nexaaiをpip install "nexaai[eval]"に置き換えます。pip install nexaaiをpip install "nexaai[convert]"に置き換えます。--extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple --extra-index-url https://pypi.org/simple URLとして使用することをお勧めします。メインCLIコマンドの簡単な概要を次に示します。
nexa run :GGUFモデルを使用したさまざまなタスクの推論を実行します。nexa onnx :ONNXモデルを使用したさまざまなタスクの推論を実行します。nexa convert :HuggingfaceモデルをGGUFモデルに変換および量子化します。nexa server :NEXA AIテキスト生成サービスを実行します。nexa eval :Nexa AI評価タスクを実行します。nexa pull :公式またはハブからモデルをプルします。nexa remove :ローカルマシンからモデルを削除します。nexa clean :すべてのモデルファイルをクリーンアップします。nexa list :ローカルマシンのすべてのモデルをリストします。nexa login :Nexa APIにログインします。nexa whoami :現在のユーザー情報を表示します。nexa logout :Nexa APIからのログアウト。CLIコマンドと使用に関する詳細については、CLIリファレンスドキュメントを参照してください。
ローカルコンピューターでモデルを使用してローカルサーバーを起動するには、 nexa serverコマンドを使用できます。サーバーのセットアップ、APIエンドポイント、および使用例の詳細については、サーバーリファレンスドキュメントを参照してください。
Swift SDK: Swifty APIを提供し、Swift開発者がプロジェクトでLlama.cppモデルを簡単に統合および使用できるようにします。
より多くのドキュメント
次のプロジェクトに感謝します。


