nexa sdk
v0.0.9.7
Hub de modelos en el dispositivo | Documentación | Discordia | Blogs | X (Twitter)
NEXA SDK es un marco de inferencia local en el dispositivo para modelos ONNX y GGML, compatible con la generación de texto, generación de imágenes, modelos de lenguaje de visión (VLM), modelos de audio-lenguaje, capacidades de voz a texto (ASR) y texto a voz (TTS). Instalable a través del paquete Python o instalador ejecutable.
nexa run omniVLM y modelo de lenguaje de audio (parámetros 2.9B): nexa run omniaudionexa run qwen2audio , somos el primer kit de herramientas de código abierto que admite el modelo de lenguaje de audio con la biblioteca de tensor GGML.nexa embed <model_path> <prompt>nexa run -hf <hf_model_id> -mt COMPUTER_VISION o nexa run -ms <ms_model_id> -mt COMPUTER_VISIONnexa run -hf <hf_model_id> -mt NLP o nexa run -ms <ms_model_id> -mt NLPBienvenido a enviar sus solicitudes a través de problemas, enviamos semanalmente.
 instalador de macOS
instalador de macOS
 Instalador de Windows
Instalador de Windows
 Instalador de Linux
Instalador de Linux
curl -fsSL https://public-storage.nexa4ai.com/install.sh | sh Intente usar nexa-exe en su lugar:
nexa-exe < command > Hemos lanzado ruedas pre-construidas para varias versiones, plataformas y backends de Python para una instalación conveniente en nuestra página de índice.
pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cpu --extra-index-url https://pypi.org/simple --no-cache-dirPara la versión GPU que soporta el metal (macOS) :
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirPrueba el siguiente comando:
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
conda create -n nexasdk python=3.10
conda activate nexasdk
CMAKE_ARGS= " -DGGML_METAL=ON -DSD_METAL=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/metal --extra-index-url https://pypi.org/simple --no-cache-dirPara instalar con soporte CUDA, asegúrese de tener CUDA Toolkit 12.0 o más tarde instalado.
Para Linux :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara el símbolo del sistema de Windows :
set CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows Git Bash :
CMAKE_ARGS= " -DGGML_CUDA=ON -DSD_CUBLAS=ON " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dirSi encuentra el siguiente problema mientras se construye:
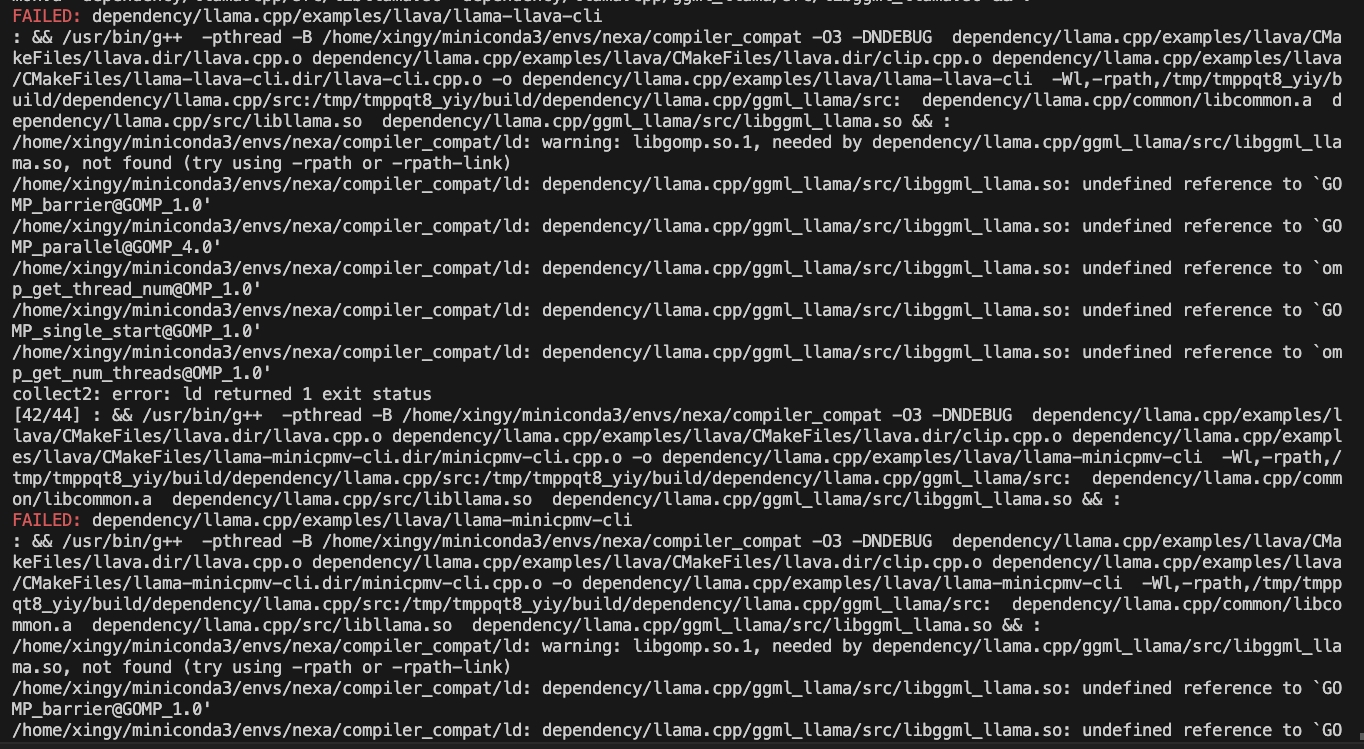
Prueba el siguiente comando:
CMAKE_ARGS= " -DCMAKE_CXX_FLAGS=-fopenmp " pip install nexaaiPara instalar con soporte ROCM, asegúrese de tener ROCM 6.2.1 o más tarde instalado.
Para Linux :
CMAKE_ARGS= " -DGGML_HIPBLAS=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/rocm621 --extra-index-url https://pypi.org/simple --no-cache-dirPara instalar con soporte de Vulkan, asegúrese de tener Vulkan SDK 1.3.261.1 o más tarde instalado.
Para Windows PowerShell :
$env :CMAKE_ARGS= " -DGGML_VULKAN=on " ; pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPara el símbolo del sistema de Windows :
set CMAKE_ARGS= " -DGGML_VULKAN=on " & pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirPara Windows Git Bash :
CMAKE_ARGS= " -DGGML_VULKAN=on " pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/vulkan --extra-index-url https://pypi.org/simple --no-cache-dirCómo clonar este repositorio
git clone --recursive https://github.com/NexaAI/nexa-sdk Si se olvida de usar --recursive , puede usar el siguiente comando para agregar submódulo
git submodule update --init --recursiveEntonces puede construir e instalar el paquete
pip install -e . A continuación se muestra nuestra diferenciación de otras herramientas similares:
| Característica | Nexa sdk | ollama | Óptimo | LM Studio |
|---|---|---|---|---|
| Soporte GGML | ✅ | ✅ | ✅ | |
| Soporte ONNX | ✅ | ✅ | ||
| Generación de texto | ✅ | ✅ | ✅ | ✅ |
| Generación de imágenes | ✅ | |||
| Modelos en idioma de visión | ✅ | ✅ | ✅ | ✅ |
| Modelos de audio-lenguaje | ✅ | |||
| Texto a voz | ✅ | ✅ | ||
| Capacidad del servidor | ✅ | ✅ | ✅ | ✅ |
| Interfaz de usuario | ✅ | ✅ | ||
| Instalación ejecutable | ✅ | ✅ | ✅ |
Nuestro centro de modelos en el dispositivo ofrece todo tipo de modelos cuantificados (texto, imagen, audio, multimodal) con filtros para RAM, tamaño de archivo, tareas, etc. para ayudarlo a explorar fácilmente los modelos con UI. Explore los modelos en el dispositivo en el Model Hub en el dispositivo
Ejemplos de modelos compatibles (lista completa en Model Hub):
| Modelo | Tipo | Formato | Dominio |
|---|---|---|---|
| omniaudio | Audiolm | Gguf | nexa run omniaudio |
| qwen2audio | Audiolm | Gguf | nexa run qwen2audio |
| Octopus-V2 | Llamada de función | Gguf | nexa run octopus-v2 |
| Octo-red | Texto | Gguf | nexa run octo-net |
| omnivlm | Multimodal | Gguf | nexa run omniVLM |
| nanolola | Multimodal | Gguf | nexa run nanollava |
| llava-phi3 | Multimodal | Gguf | nexa run llava-phi3 |
| Llava-llama3 | Multimodal | Gguf | nexa run llava-llama3 |
| Llava1.6-Mistral | Multimodal | Gguf | nexa run llava1.6-mistral |
| llava1.6-vicuna | Multimodal | Gguf | nexa run llava1.6-vicuna |
| Llama3.2 | Texto | Gguf | nexa run llama3.2 |
| Llama3-incensorado | Texto | Gguf | nexa run llama3-uncensored |
| gemma2 | Texto | Gguf | nexa run gemma2 |
| qwen2.5 | Texto | Gguf | nexa run qwen2.5 |
| Mathqwen | Texto | Gguf | nexa run mathqwen |
| Codeqwen | Texto | Gguf | nexa run codeqwen |
| mistral | Texto | Gguf/onnx | nexa run mistral |
| veloz de profundidad | Texto | Gguf | nexa run deepseek-coder |
| Phi3.5 | Texto | Gguf | nexa run phi3.5 |
| freenelm | Texto | Gguf | nexa run openelm |
| Estable-Difusión-V2-1 | Generación de imágenes | Gguf | nexa run sd2-1 |
| Estable-Difusión-3-Medio | Generación de imágenes | Gguf | nexa run sd3 |
| Flux.1-Schnell | Generación de imágenes | Gguf | nexa run flux |
| lcm-dreamshaper | Generación de imágenes | Gguf/onnx | nexa run lcm-dreamshaper |
| Whisper-Large-V3-Turbo | Voz a texto | PAPELERA | nexa run faster-whisper-large-turbo |
| susurro pequeño.en | Voz a texto | ONNX | nexa run whisper-tiny.en |
| mxbai-embbed-large-v1 | Incrustación | Gguf | nexa embed mxbai |
| text-v1.5 | Incrustación | Gguf | nexa embed nomic |
| All-Minilm-L12-V2 | Incrustación | Gguf | nexa embed all-MiniLM-L12-v2:fp16 |
| pizca de corteza | Texto a voz | Gguf | nexa run bark-small:fp16 |
Puede tirar, convertir (a .GUF), cuantizar y ejecutar Llama.cpp modelos de generación de texto admitidos de HF o MS con NEXA SDK.
Use nexa run -hf <hf-model-id> o nexa run -ms <ms-model-id> para ejecutar modelos con archivos .GUF proporcionados:
nexa run -hf Qwen/Qwen2.5-Coder-7B-Instruct-GGUFnexa run -ms Qwen/Qwen2.5-Coder-7B-Instruct-GGUFNota: se le pedirá que seleccione un solo archivo .GUF. Si su versión de cuantificación deseada tiene múltiples archivos divididos (como FP16-00001 de 00004), utilice la herramienta de conversión de NEXA (ver más abajo) para convertir y cuantizar el modelo localmente.
Instale el paquete NEXA Python e instale la herramienta de conversión de NEXA con pip install "nexaai[convert]" , luego Convertir modelos de Huggingface con nexa convert <hf-model-id> ::
nexa convert HuggingFaceTB/SmolLM2-135M-Instruct O puede convertir modelos de ModelsCope con nexa convert -ms <ms-model-id> :
nexa convert -ms Qwen/Qwen2.5-7B-InstructNota: Consulte nuestra tabla de clasificación para ver los puntos de referencia de rendimiento de diferentes versiones cuantificadas de los modelos de idiomas convencionales y los documentos de Huggingface para aprender sobre las opciones de cuantización.
? Puede ver modelos descargados y convertidos con nexa list
Nota
pip install nexaai con pip install "nexaai[onnx]" en comandos proporcionados.pip install nexaai con pip install "nexaai[eval]" en comandos proporcionados.pip install nexaai con pip install "nexaai[convert]" en los comandos proporcionados.--extra-index-url https://pypi.org/simple con --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple en los comandos proporcionados.Aquí hay una breve descripción de los principales comandos de CLI:
nexa run : Ejecutar inferencia para varias tareas utilizando modelos GGUF.nexa onnx : ejecute inferencia para varias tareas utilizando modelos ONNX.nexa convert : Convertir y cuantizar los modelos de Huggingface a los modelos GGUF.nexa server : ejecute el servicio de generación de texto NEXA AI.nexa eval : Ejecute las tareas de evaluación NEXA AI.nexa pull : tire de un modelo de oficial o concentrador.nexa remove : Retire un modelo de la máquina local.nexa clean : Limpie todos los archivos de modelo.nexa list : Enumere todos los modelos en la máquina local.nexa login : Iniciar sesión en NEXA API.nexa whoami : Mostrar información actual del usuario.nexa logout : Cerrar sesión de la API NEXA.Para obtener información detallada sobre los comandos y el uso de CLI, consulte el documento de referencia de la CLI.
Para iniciar un servidor local utilizando modelos en su computadora local, puede usar el comando nexa server . Para obtener información detallada sobre la configuración del servidor, los puntos finales de API y los ejemplos de uso, consulte el documento de referencia del servidor.
Swift SDK: proporciona una API Swifty, que permite a los desarrolladores de Swift integrar y usar fácilmente modelos LLAMA.CPP en sus proyectos.
Más documentos
Nos gustaría agradecer a los siguientes proyectos:


